 Latent Preference Modeling
Latent Preference Modeling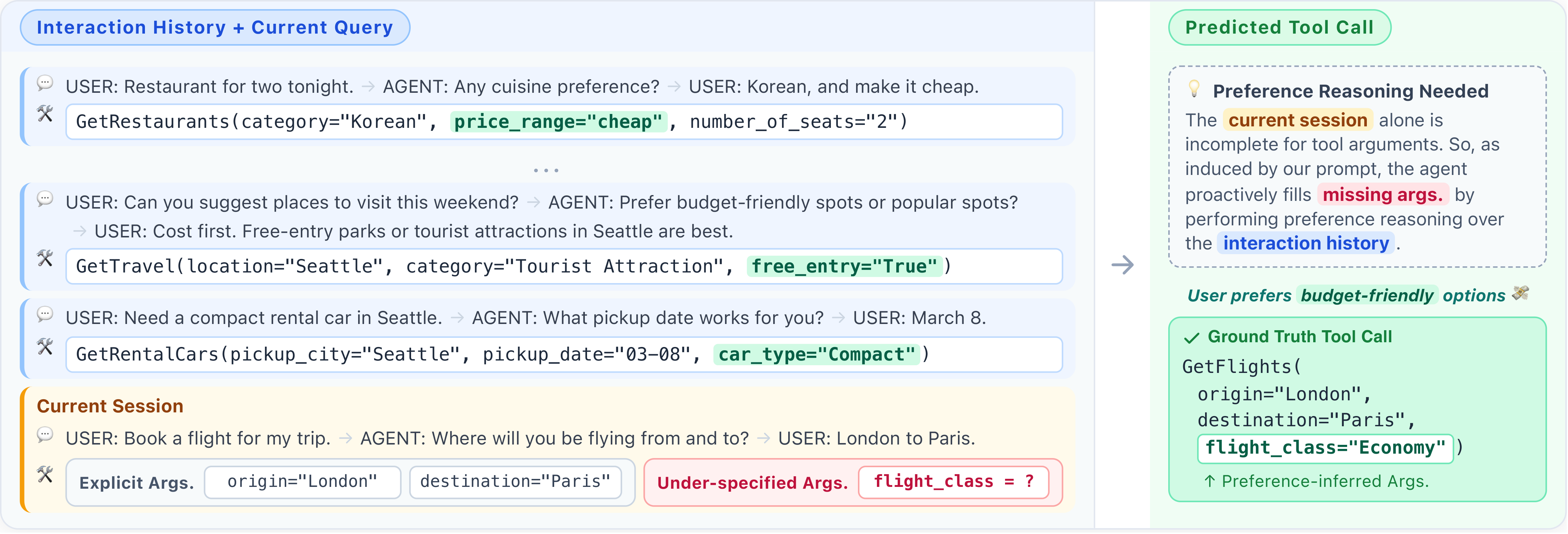
Abstract
Users frequently omit essential details when interacting with LLM-based agents, creating under-specified requests for tool use. Addressing this requires agents to reason about latent preferences—implicit, persistent constraints that recur across a user's behavior over multiple sessions. We introduce MPT, a benchmark of 265 multi-session dialogues covering three challenges: Preference Recall, Preference Induction, and Preference Transfer. We further propose PRefine, a test-time memory method that represents user preferences as evolving hypotheses through a generate–verify–refine loop. PRefine consistently improves tool-calling accuracy across eight LLMs and three evaluation metrics while retrieving only 1.24% of the memory tokens used by full-history prompting at inference time. Our results emphasize that effective personalization in agentic systems requires understanding the reasoning behind user choices, not merely recording the choices themselves.
Overview
Motivation
Personalized tool-using agents must often act on under-specified requests. When a user says "book me a flight to Seoul," the agent still has to decide airline, cabin class, departure window, and more. These missing details are not random: they reflect stable patterns in a user's behavior—budget sensitivity, preferred travel styles, dietary habits—that persist across sessions and generalize across domains. Existing benchmarks, however, assume preferences are either declared upfront or trivially retrievable from a single past turn, leaving the realistic setting of latent preference inference unaddressed.
Research Focus
We study personalization as latent preference modeling for tool calling: given a stream of prior sessions, infer the implicit constraints that explain a user's choices, and apply them to fill in arguments for a new, under-specified request. We target three concrete capabilities—recalling a preference seen before, inducing one from indirect evidence, and transferring one across domains—and evaluate whether agents can do this without ballooning the memory or context they carry.
Benchmark: MPT
MPT (Multi-session Personalized Tool calling) comprises 265 multi-session dialogues spanning 2,020 sessions (avg. ~7.6 sessions per dialogue), built to test three evaluation axes: Preference Recall (reuse a preference demonstrated earlier), Preference Induction (derive a latent rule from indirect cues), and Preference Transfer (apply a learned preference to an unseen domain). Each dialogue is grounded in a realistic tool-calling schema covering travel, dining, and lifestyle domains.

Method: PRefine
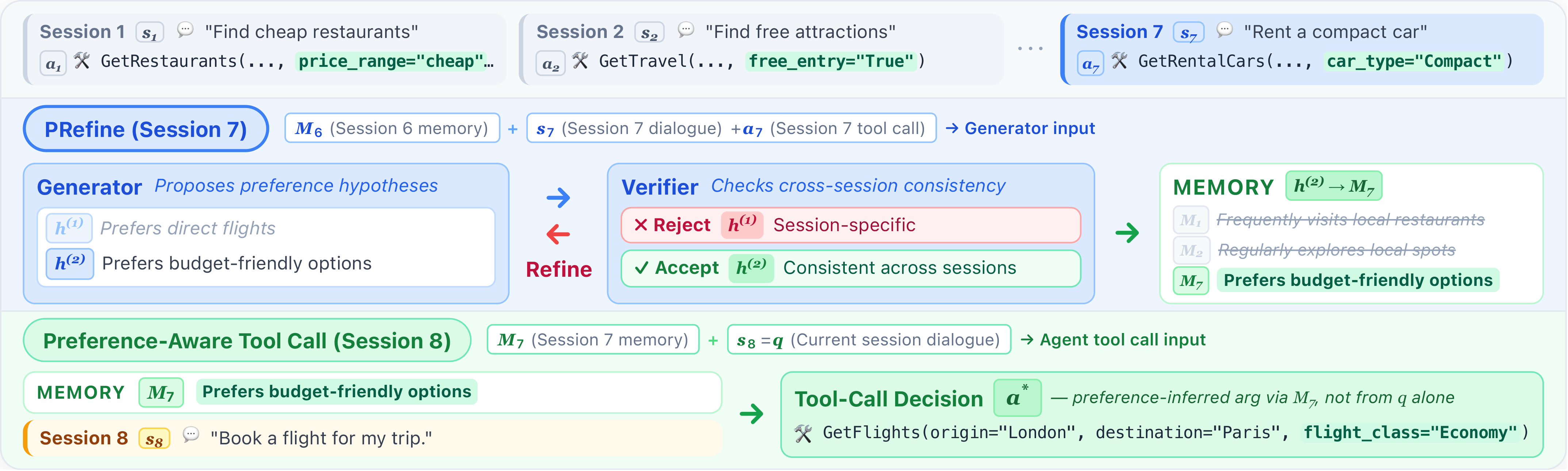
PRefine treats latent preferences as revisable hypotheses rather than static facts. After each session, it (1) generates candidate preference hypotheses from the current dialogue and prior memory, (2) verifies them against four criteria—Evidence Support, Abstraction Quality, Actionability, and Temporal Consistency—and (3) refines weak hypotheses based on verifier feedback. Memory stays schema-agnostic: abstract constraints are stored first, and schema-grounding is deferred to inference time, so the same memory transfers to evolving tool interfaces.
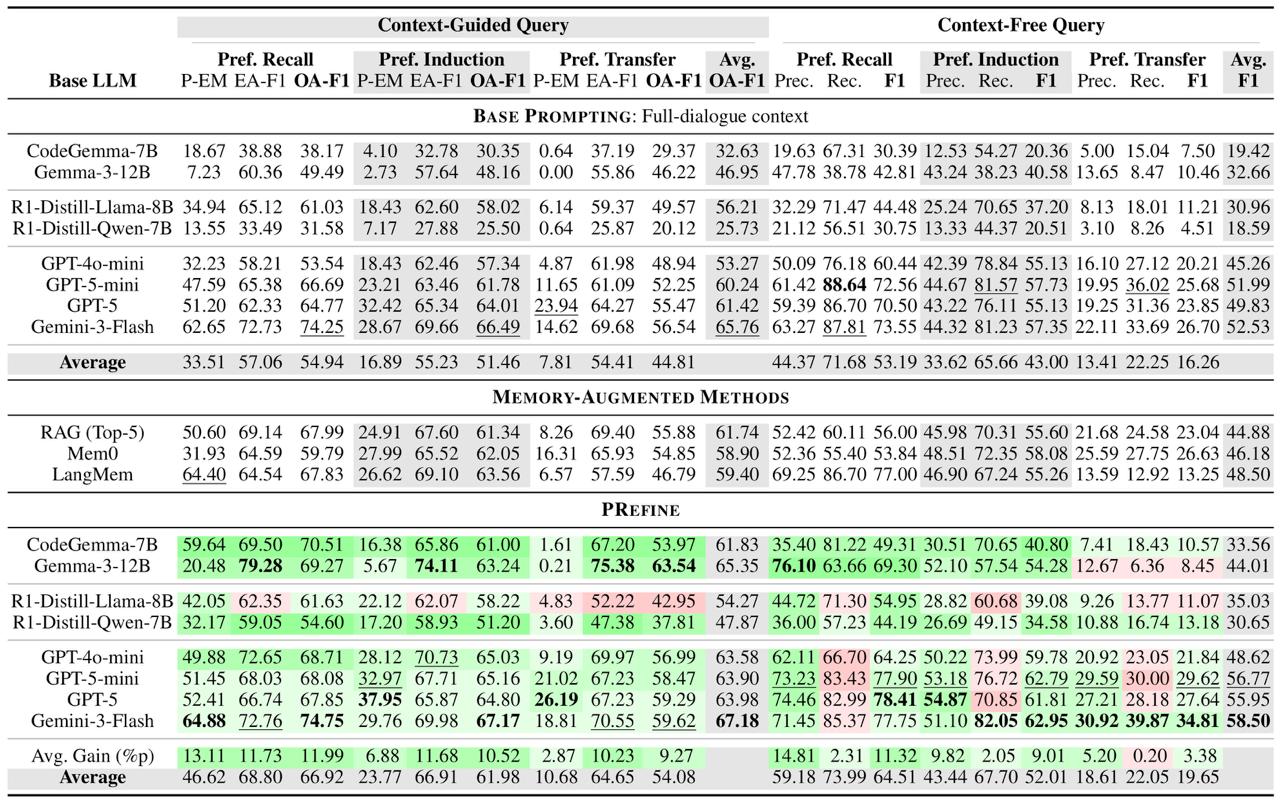
Main Results
We evaluate eight LLMs with Preference Exact Match (P-EM, exact match on preference-relevant arguments) on each axis, under both context-guided and context-free queries. Baselines are competitive on Preference Recall, where direct reuse suffices, but drop substantially on Induction and Transfer, which require genuine preference abstraction. PRefine improves P-EM on Preference Recall by +13.11 points on average across the eight LLMs, and yields consistent—if smaller—gains on Induction and Transfer (see the table below).
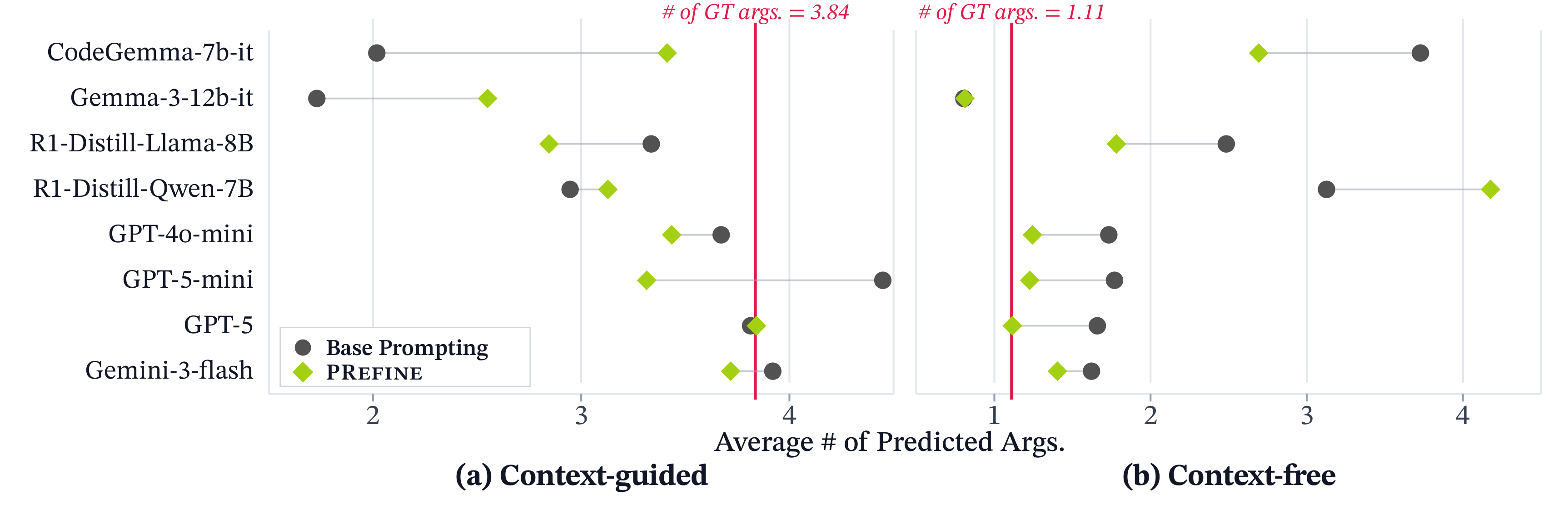
Efficiency & Analysis
PRefine matches or exceeds full-history prompting accuracy while keeping memory compact: at inference time it retrieves only 1.24% of the memory tokens used by full-history prompting, and memory size grows sub-linearly as sessions accumulate. It also calibrates how many arguments a model predicts, cutting the mean absolute deviation from the ground-truth argument count by about 28%.
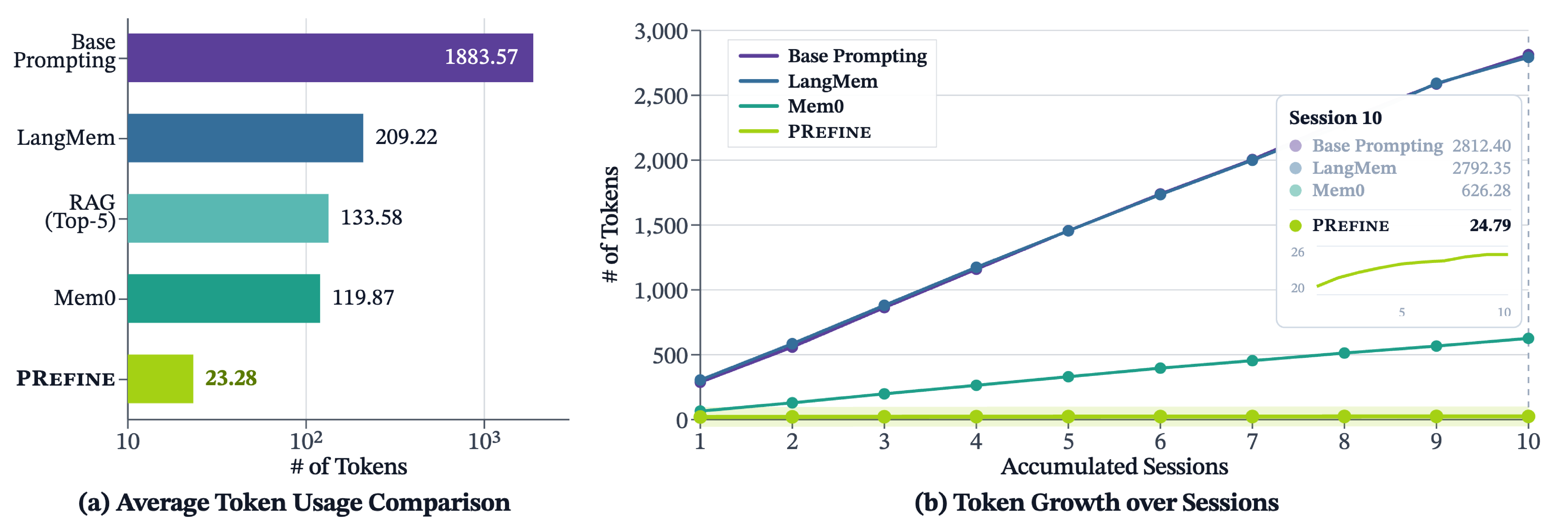
Key Findings
Personalization in agentic tool use is not a memorization problem—it is a reasoning problem about why users make the choices they do. Treating preferences as evolving hypotheses rather than static records lets PRefine recover latent rules, transfer them across domains, and keep memory small enough to be practical under realistic multi-session use.
BibTeX
@article{yoon2026latent,
title = {Latent Preference Modeling for Cross-Session Personalized Tool Calling},
author = {Yoon, Yejin and Kim, Minseo and Kim, Taeuk},
journal = {arXiv preprint arXiv:2604.17886},
year = {2026}
}