GPT-4 Technical Report
Meta info.
- Authors: OpenAI
- Paper: https://cdn.openai.com/papers/gpt-4.pdf
- Affiliation: OpenAI
TL; DR
GPT-4, a large multimodal model with human-level performance on certain difficult professional and academic benchmarks. It outperforms existing LLMs on almost NLP tasks, and exceeds the vast majority of reported SOTA methods (often including task-specific fine-tuning).

Suggestions
- multi-modal input: GPT-4 takes images & text as input, then produces text as output. (pic1)
- stability to train GPT-4: OpenAI has developed infrastructure and optimization methods that exhibit highly predictable behavior across multiple scales, which enables reliable prediction of GPT-4 performance. (Azure for supporting infrastructure design & management)
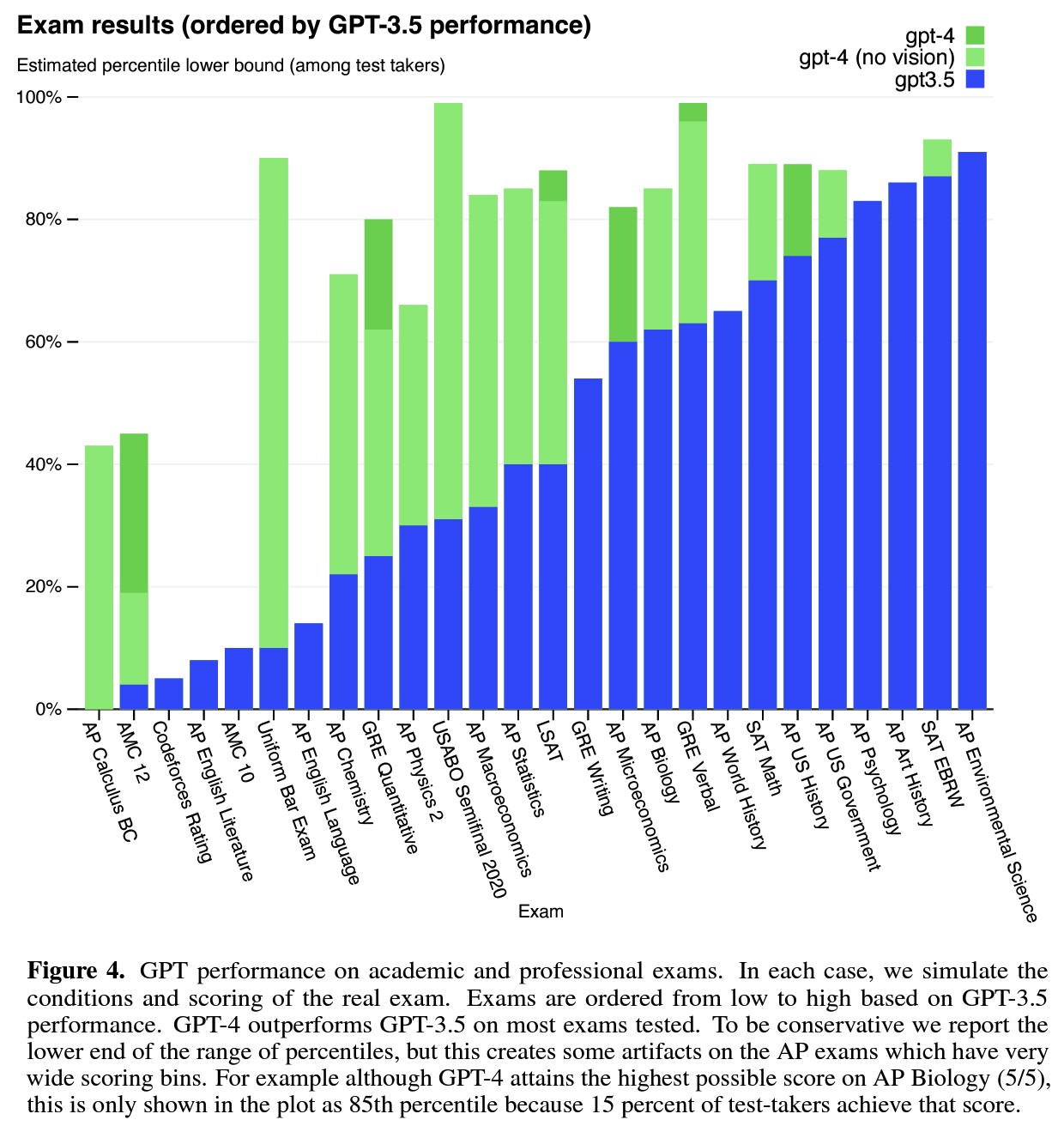
- significant improvements on various benchmarks: GPT-4 shows significant improvements on various benchmarks and outperforms existing LLMs by a considerable margin, even surpassing the SOTA models that have been fine-tuned for specific tasks. (pic2)
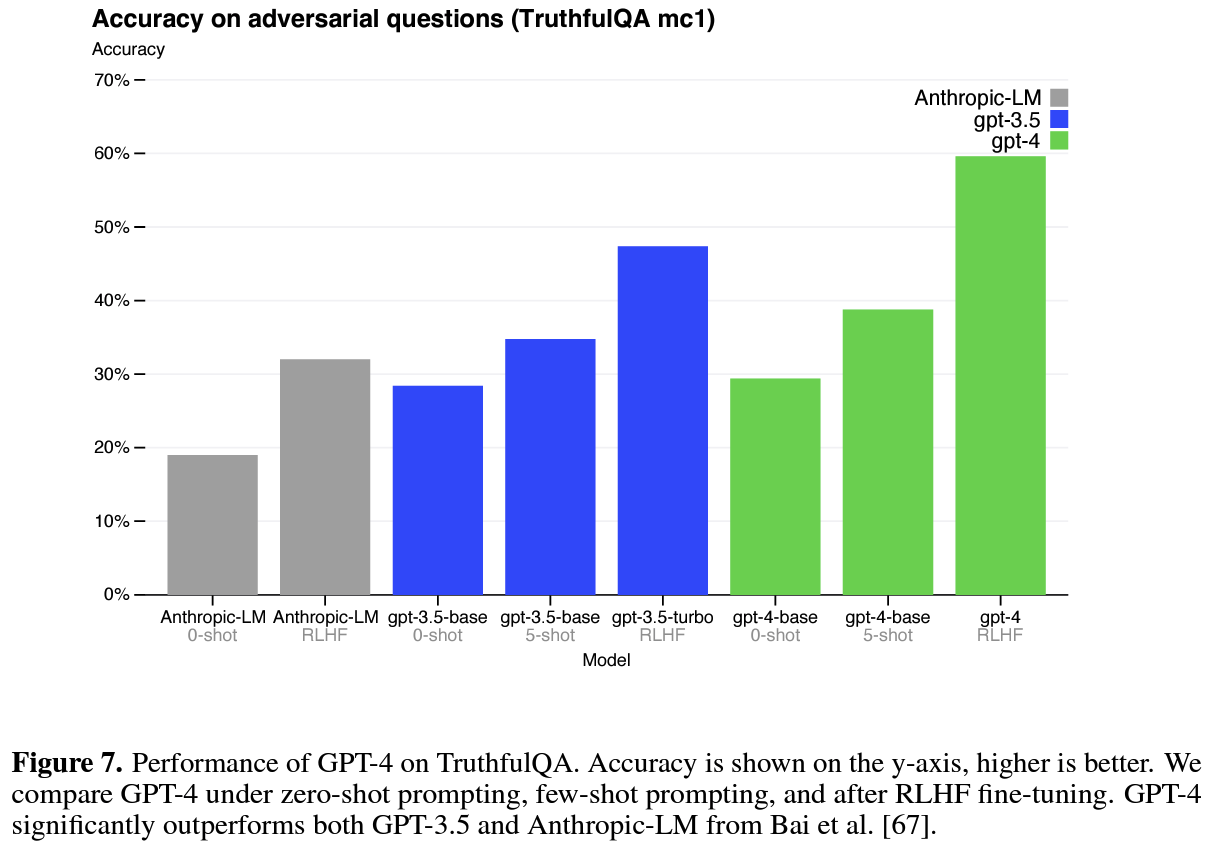
- Effect on RLHF: Model capabilities are not significantly affected by RLHF on exams(actually degrades performance w/o additional efforts), while making progress on benchmarks like TruthfulQA. It suggests that post-training does not substantially alter base model capability but allows user to steer the model closer towards the desired behavior. (pic3)
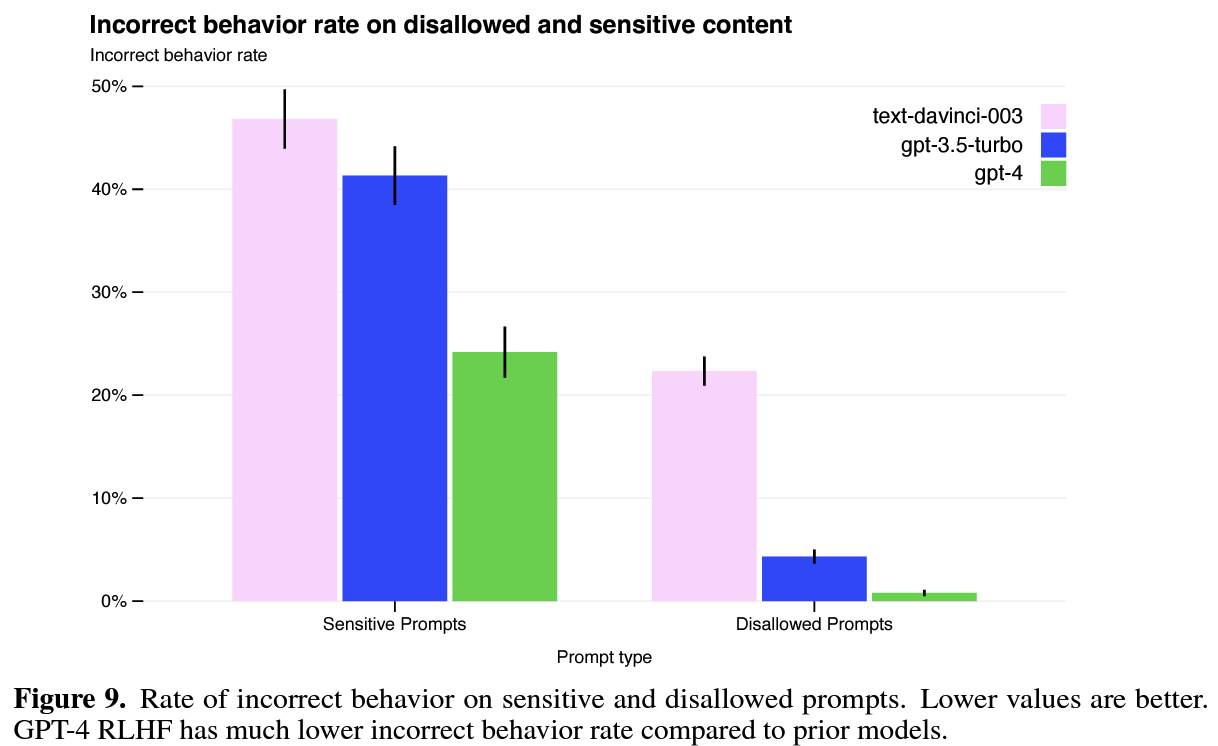
- safety properties: OpenAI focused on decreasing the model’s tendency to respond to requests for harmful/incorrect output by 82% compared to GPT-3.5, even recruited external experts to qualitatively probe, adversarially test, and generally provide feedback on the GPT-4. (pic4)