What Language Model Architecture and Pretraining Objective Work Best for Zero-Shot Generalization?
Meta info.
- Authors: Wang, Roberts
- Paper: https://arxiv.org/abs/2204.05832
- Affiliation: BigScience, Google Research, HuggingFace
TL; DR
Causal decoder-only models trained on an autoregressive language modeling objective(standard FLM objective) exhibit the strongest zero-shot generalization w/o any finetuning or adaptation. However, after multitask finetuning, encoder-decoder model pretrained with MLM objective significantly better.
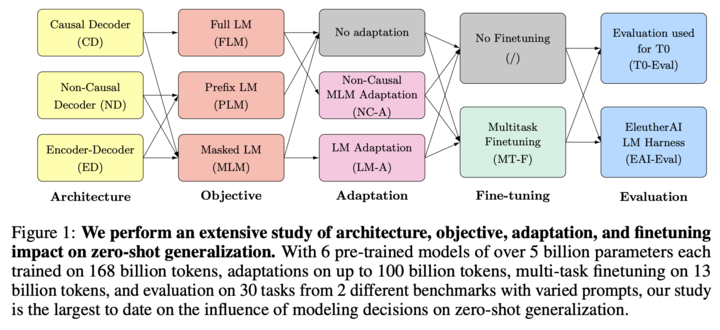

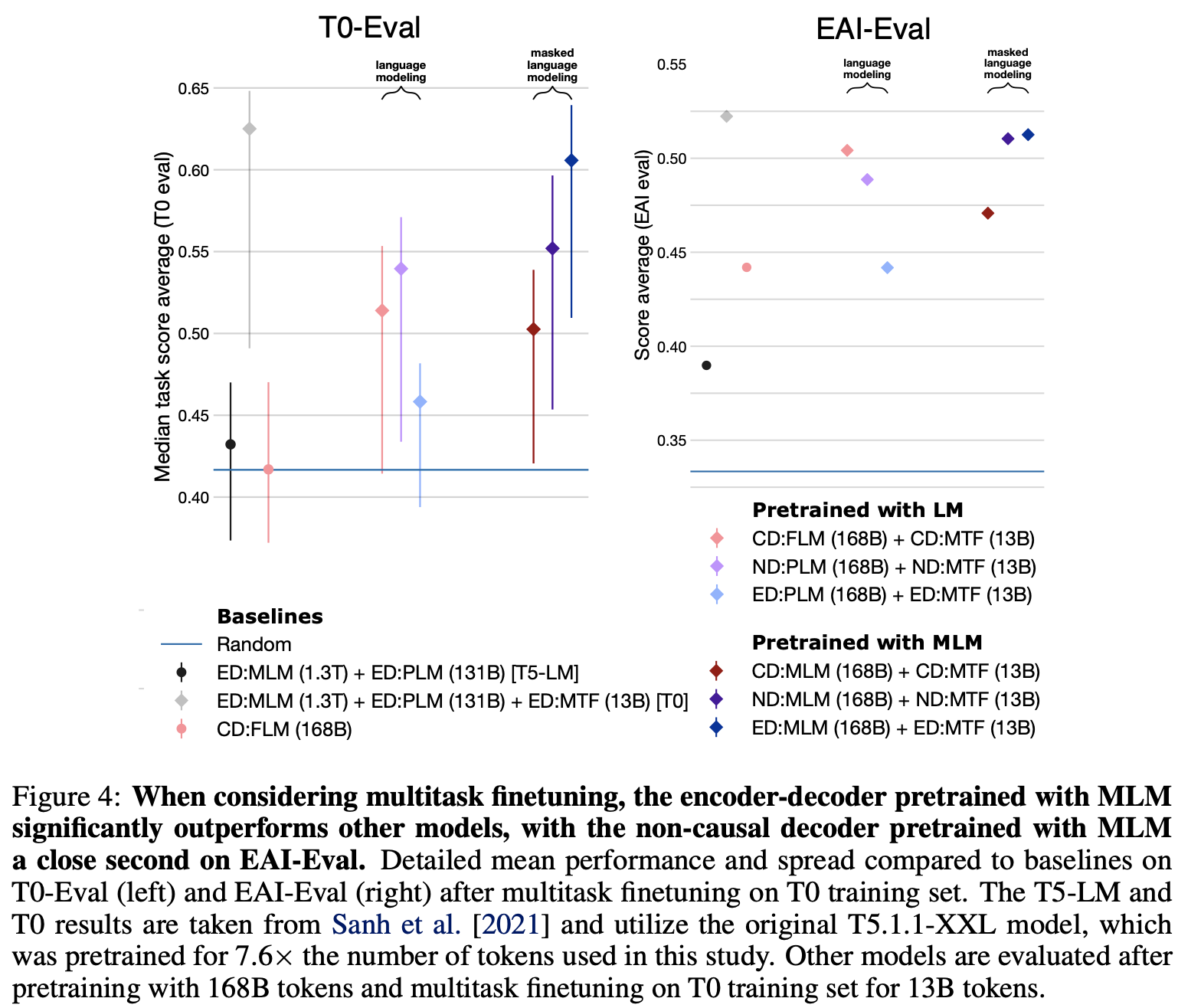
Suggestions
a study about understanding the interplay between architecture, objective, multi-task fine-tuning, and zero-shot generalization.
- A large-scale systematic study of architecture + pretraining objective combination focusing on zero-shot generalization.
- Multi-task finetuning impacts architecture + pretraining objective combination. (TL; DR)
- Decoder-only models can be efficiently adapted from one architecture/objective prior to the other.
Personal note. 오늘 발표했던 T0논문 관련 후속연구로, 현재 진행되는 연구들이 취하고 있는 주류 관행이 맞는 접근이라는 걸 확인한 논문입니다.