Scaling Transformer to 1M tokens and beyond with RMT
Meta info.
- Authors: Aydar Bulatov, Yuri Kuratov, Mikhail S. Burtsev
- Paper: https://arxiv.org/abs/2304.11062
- Published: April 19, 2023
- Code: https://github.com/booydar/t5-experiments/tree/scaling-report
TL; DR
RMT(Recurrent Memory Transformer) retains information across up to 2 million tokens!

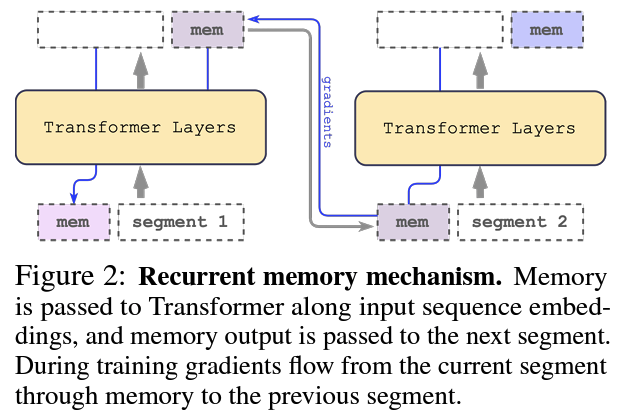
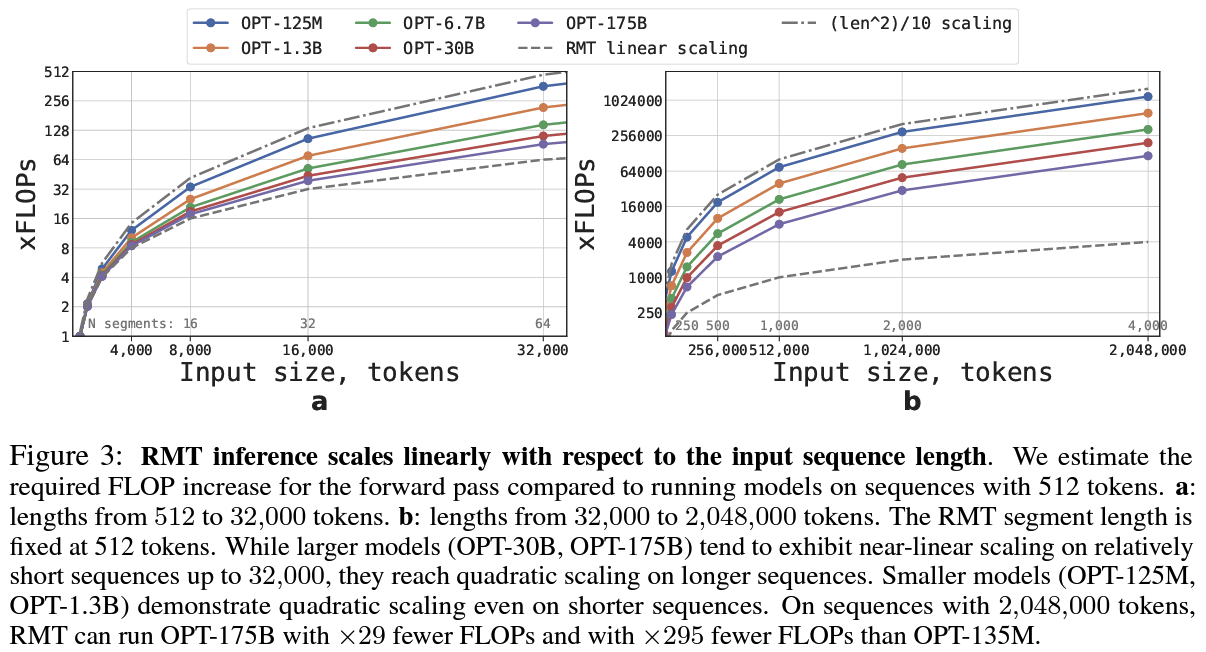
Suggestions
- RMT, which can retain information across up to 2 × 10^6 tokens, significantly exceeding the largest input size reported for transformer models
- It enables pre-trained BERT models to store task-specific information and has potential use cases in language modeling and other tasks
- The ability to effectively utilize memory for up to 4,096 segments with a total length of 2,048,000 tokens has significant implications for the development of future transformer models.