Weak-to-strong Generalization: Eliciting Strong Capabilities with Weak Supervision
Meta info.
- Authors: Collin Buruns, Pavel Izmailov, et al.
- Paper: https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
- Affiliation: OpenAI
- References: OpenAI Blog
TL; DR
Naively finetune strong pretrained models on labels generated by a weak model consistently perform better than their weak supervisors.
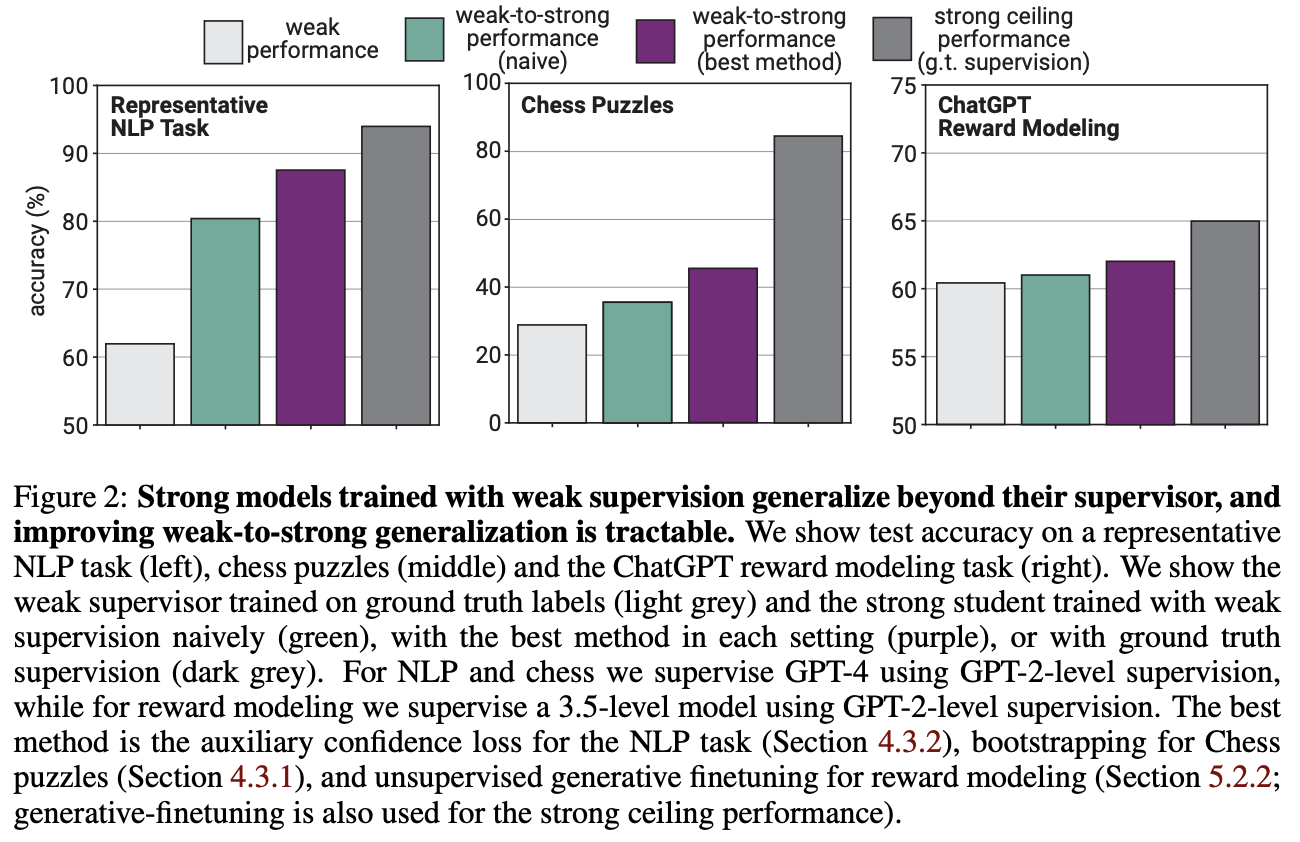
Suggestions
- “학습 데이터 품질이 모델 성능의 주요 요인인가?” 에 대해, 아닐 수도 있다고 주장.
- 이미 잘 구축된 큰 모델이라면 상대적으로 질 나쁜 데이터로도 좋은 성능을 낼 수 있다.
Personal note. “초지능 VS 인간” 에 대한 고민을 할 수 있는 논문
- 덜 똑똑한 인간이 더 똑똑한 AI 를 관리하는 상황 => 작은 LLM 모델로 큰 LLM 모델을 감독하는 방법을 고안하고 실험
- Human feedback이 자원적으로 어려운데 LLM도 잘하기 때문에 RLAIF 하는 추세에서, 오히려 자원때문이 아니라 그냥(두번째 bulleted list의 이유로) RLAIF가 적합하다는 역발상(?)이 좋았던 것 같음