Making Large Language Models A Better Foundation For Dense Retrieval
Meta info.
- Authors: Chaofan Li, Zheng Liu, Shitao Xiao, Yingxia Shao
- Paper: https://arxiv.org/pdf/2312.15503v1.pdf
- Affiliation: Beijing Academy
TL; DR
Dense Retrieval을 위해 LLM adaptation (2-step template 적용)
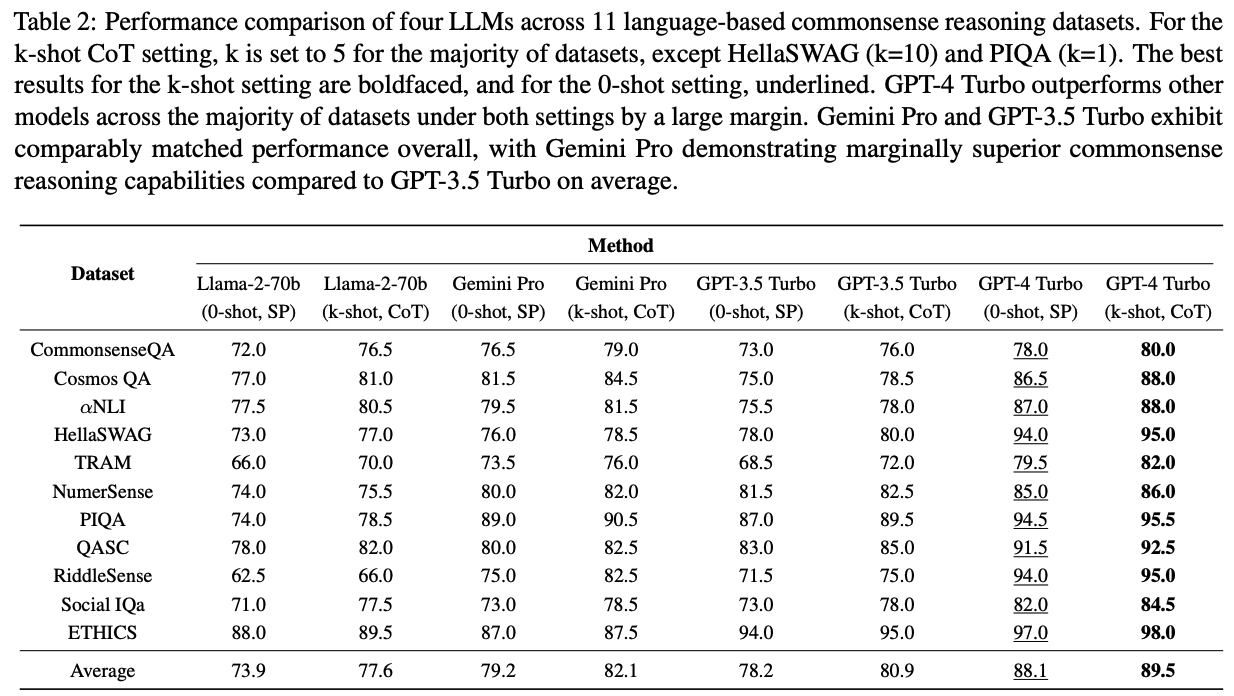
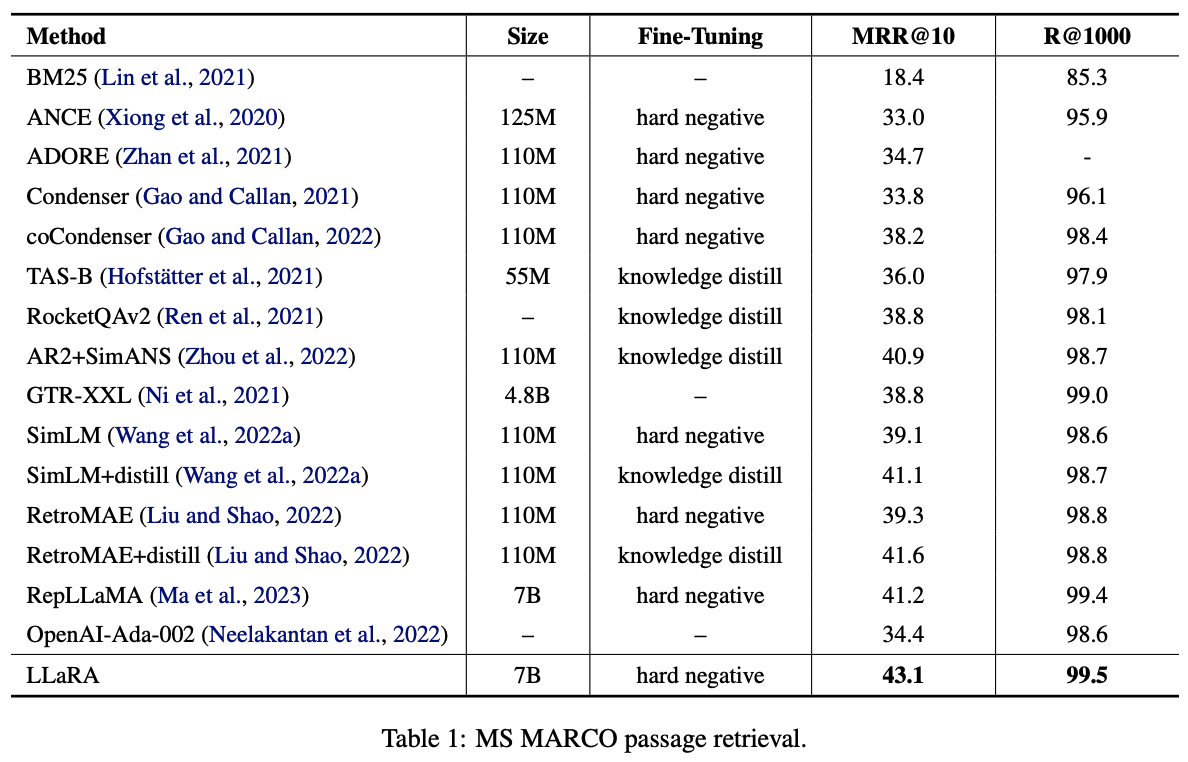
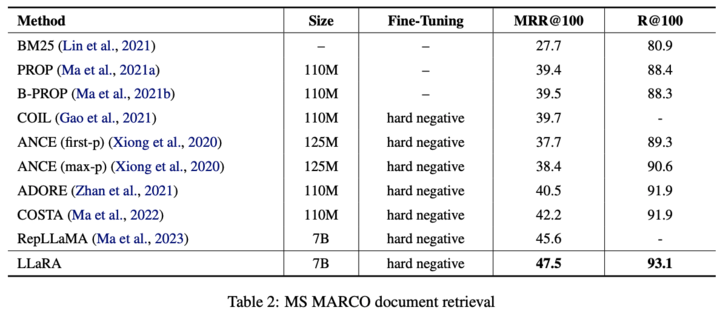
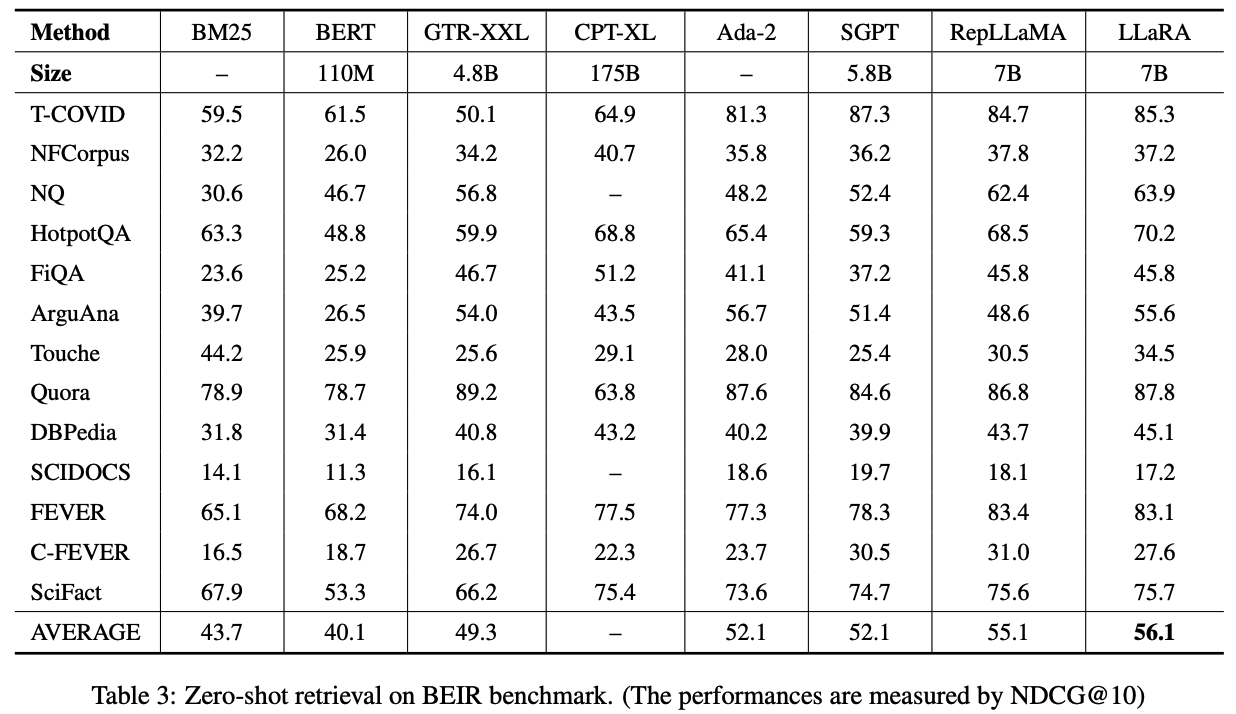

Suggestions
- EBAE(Embedding-based Auto Encoding) : LLM(LLaMA2-7B) embedding으로 input 문장 token 재구성(?) (predict token for input itself) > similarity search
- EBAR (Embedding-based Auto Regression) : 앞선 학습 후 LLM embedding으로 NSP > question answering
- Decoder 형태인 LLM은 sentence representation이 next token prediction에 초점이 맞춰져있다.
- 첫번째 그림과 같이 further training을 좀 더 하면, sentence representation이 더 global sementic을 담기 때문에 IR에서 월등한 성능을 보인다.
Personal note. llama-2-7b를 further training 가능한데 (여기서는 10k step 수행) 이런 류의 setting으로 LLM을 좀 더 활용하는 방식의 연구를 해봐야 할 듯