Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Meta info.
- Authors: Zixiang Chen, Yihe Deng, Huizhuo Yuan et al.
- Paper: https://arxiv.org/pdf/2401.01335.pdf
- Affiliation: UCLA
TL; DR
human-annotated data를 더 만들지 않더라도 weak LLM이 self-improve할 수 있다. base-LLM(zephyr-7b-sft-full) 의 반복적인 self-improvement를 진행한 모델(SPIN)이 DPO+GPT-4 preference data 학습한 모델(zephyr-7b-beta)보다 나은 성능 달성 가능

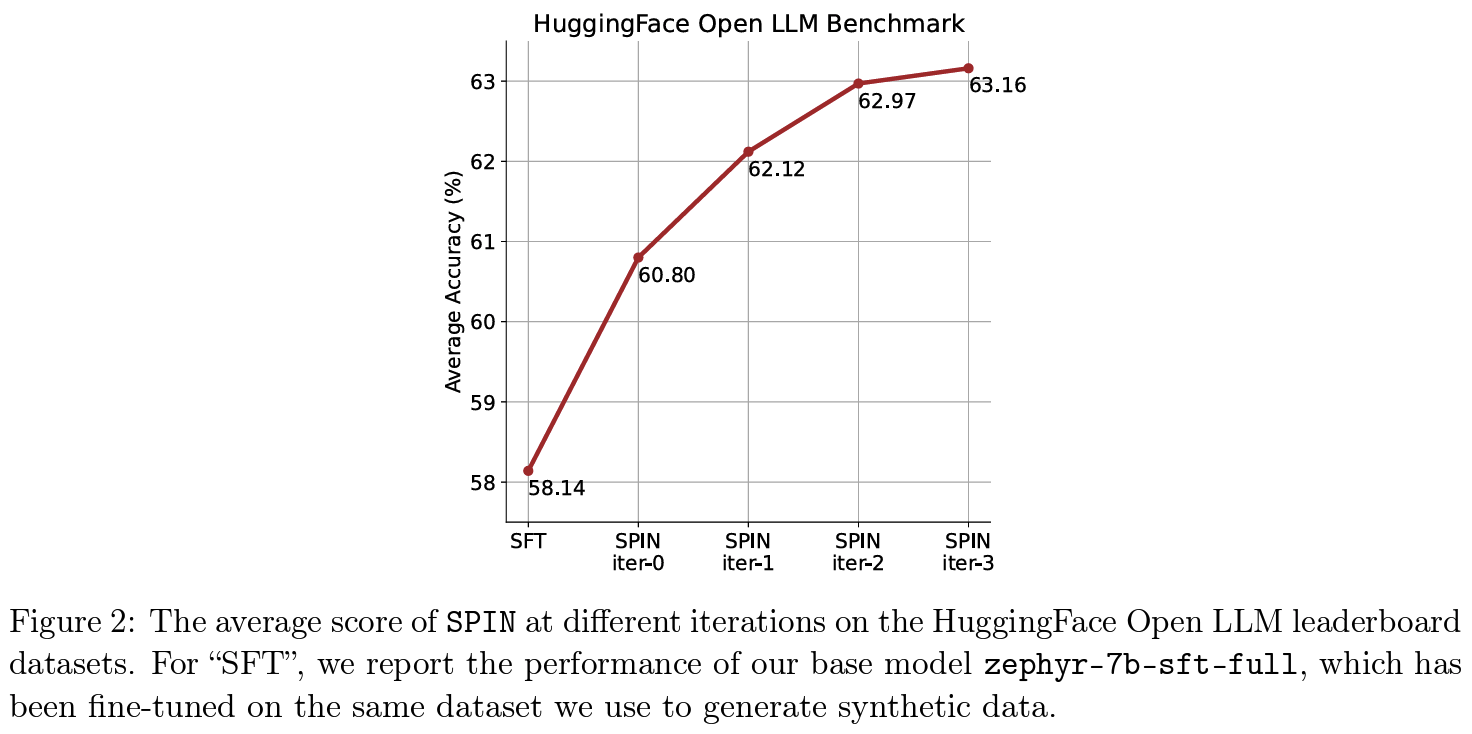
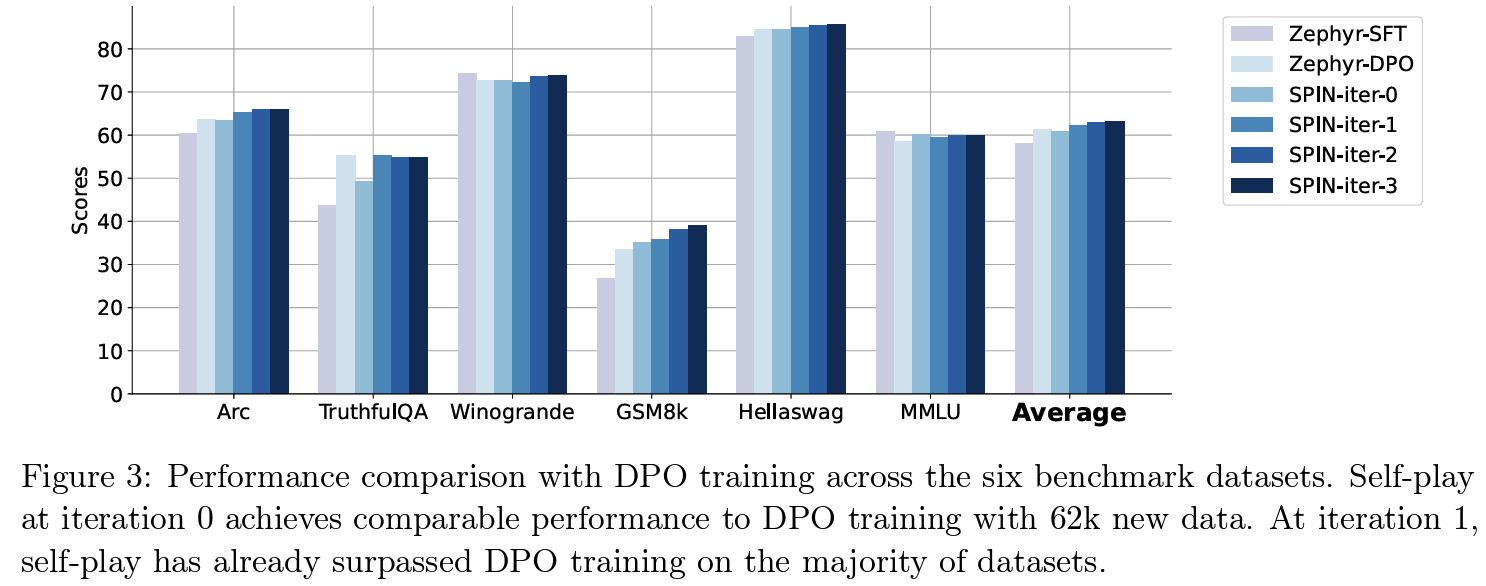
Suggestions
- supervised fine-tuned LLM이
- 이전 iteration에서 자체적으로 학습 데이터 생성하고
- human-labeled 데이터에서 얻은 response와 자체 생성 response를 경쟁시켜
- policy 개선
- 이 policy가 target data distribution과 align될 때 training objective에 global optimal 달성
Personal note. 방식 자체가 전반적으로 GAN이랑 유사한듯.