Self-Rewarding Language Models
Meta info.
- Authors: Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, Jason Weston
- Paper: https://arxiv.org/pdf/2401.10020.pdf
- Affiliation: Meta AI, NYU
TL; DR
반복적인 DPO 훈련으로 사람이 설계한 reward model이 아닌, LLM-as-a-Judge mechanism을 사용, LM이 자율적으로 instruction following & reward modeling > refine 반복.
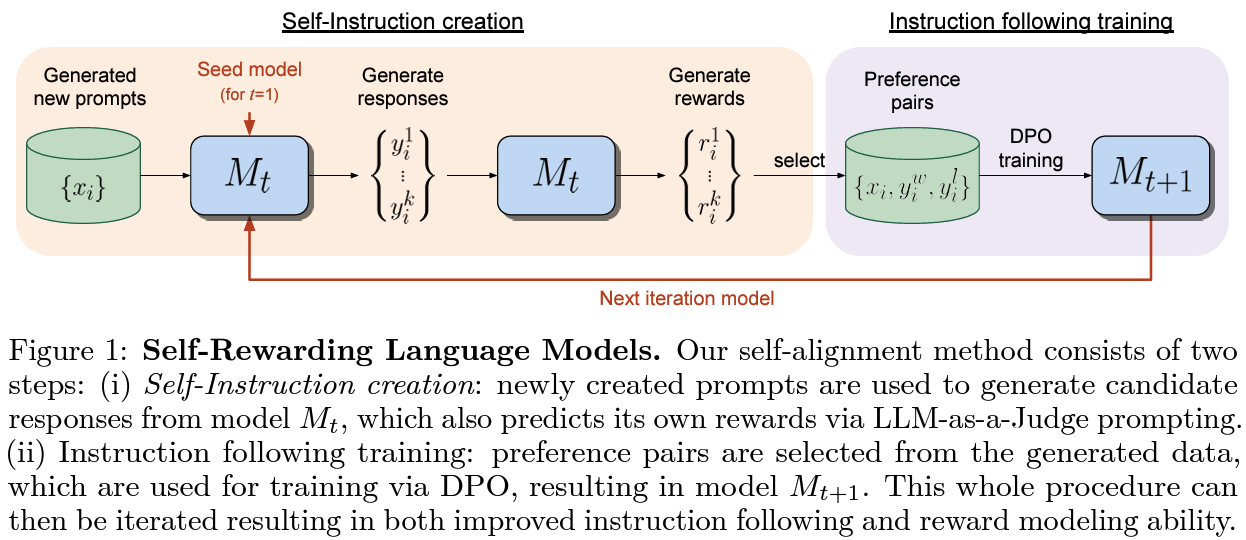


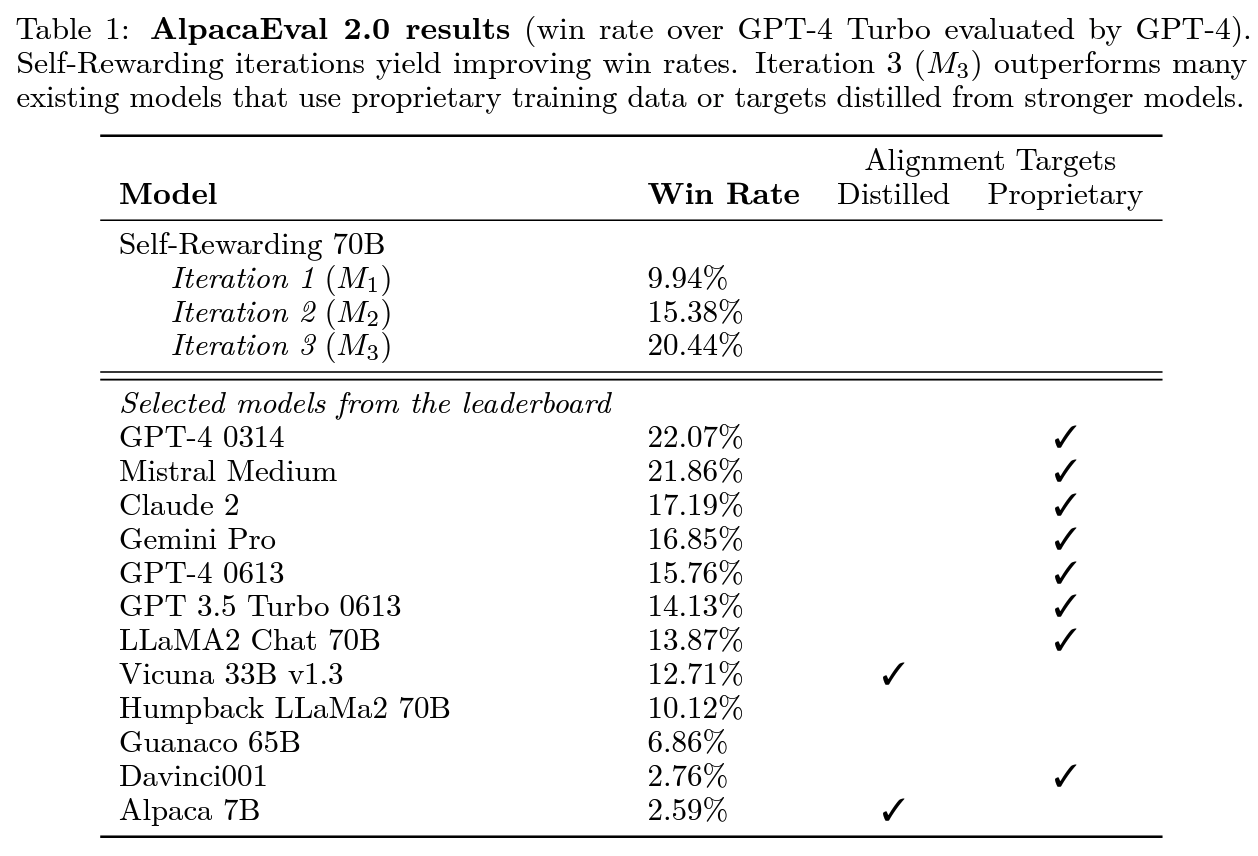
Effects
Llama2 70B를 3회 iteration으로 AlpacaEval 2.0의 Claude2, Gemini Pro, GPT-4-0613을 앞지름.