Deductive Closure Training of Language Models for Coherence, Accuracy, and Updatability
Meta info.
- Authors: Afra Feyza Akyürek, Ekin Akyürek, Leshem Choshen, Derry Wijaya and Jacob Andreas
- Paper: https://arxiv.org/abs/2401.08574
- Affiliation: Boston Univ., MIT
- Code: https://github.com/lingo-mit/deductive-closure
- References: https://lingo-mit.github.io/deductive-closure/
TL; DR
standard LM training에 특정 text를 생성하도록 학습시킨다고 해서 그 text의 implies(함의)에 해당하는 text들의 probability가 높아지는 것은 아님. factuality 측면에서 관련 fact set (text)에도 높은 확률을 assign하기 위한 방법으로 DCT 도입
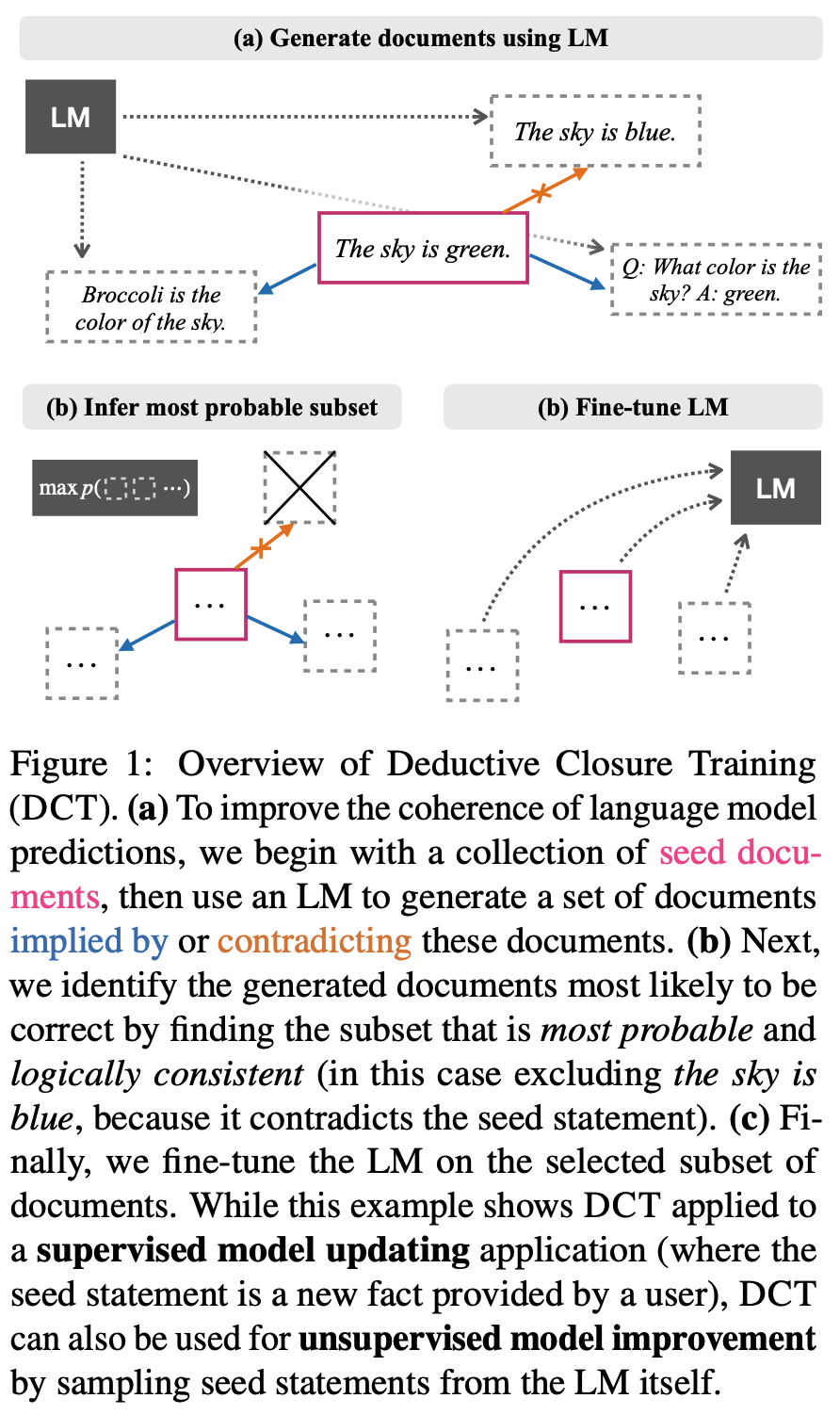

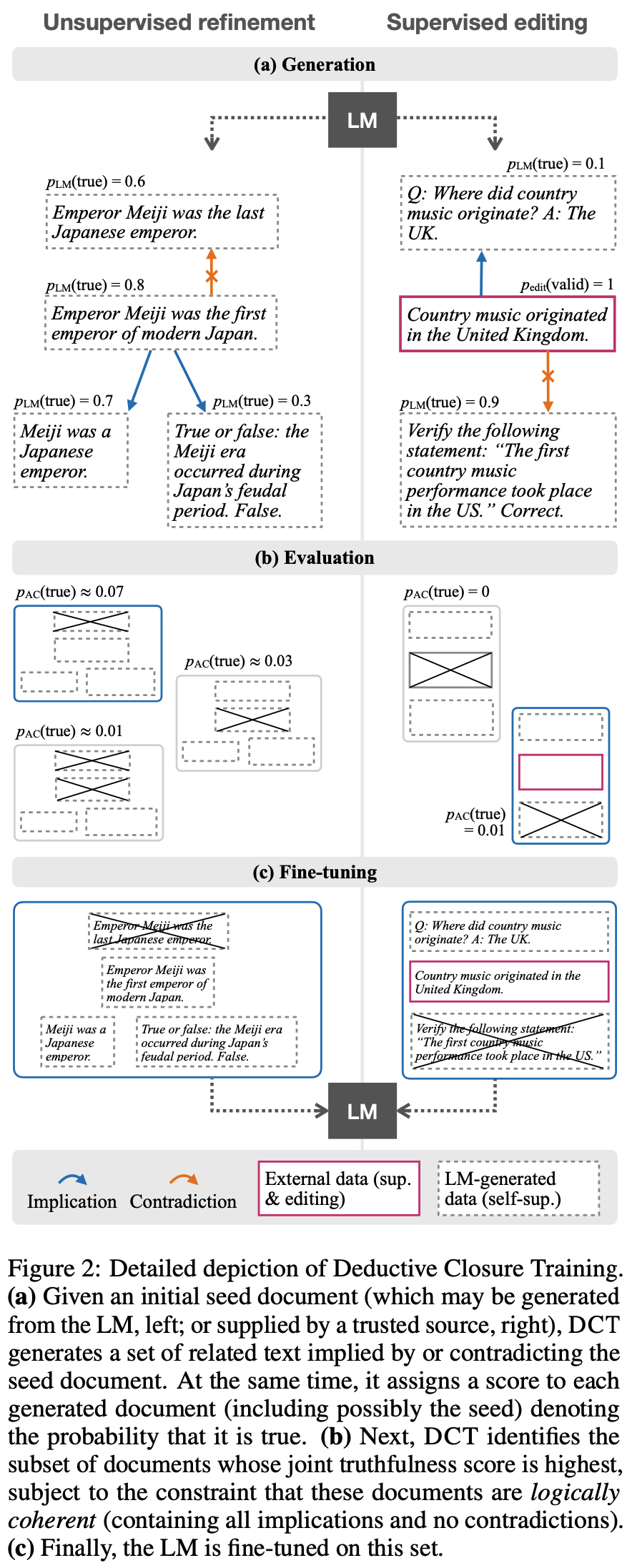
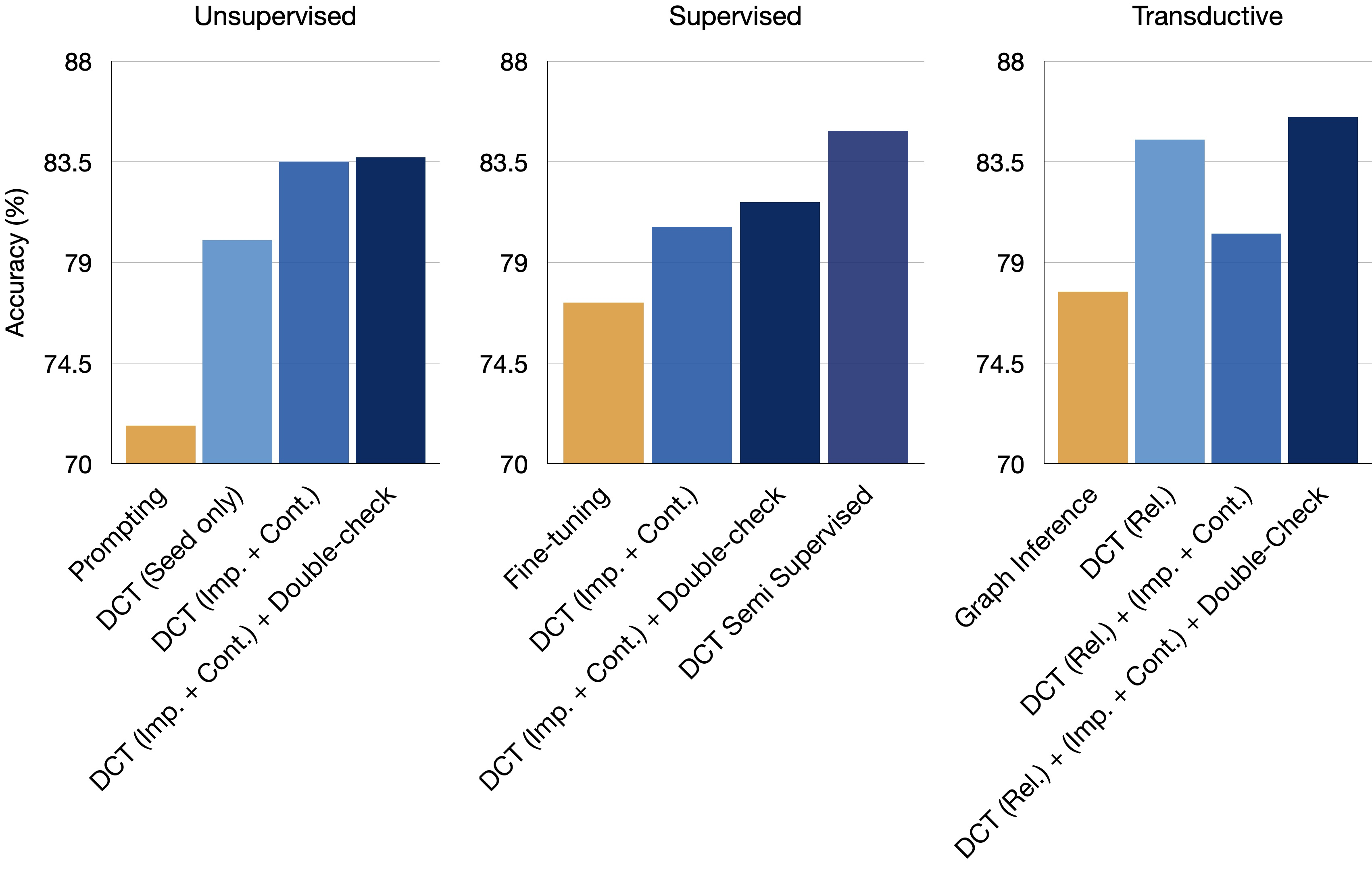
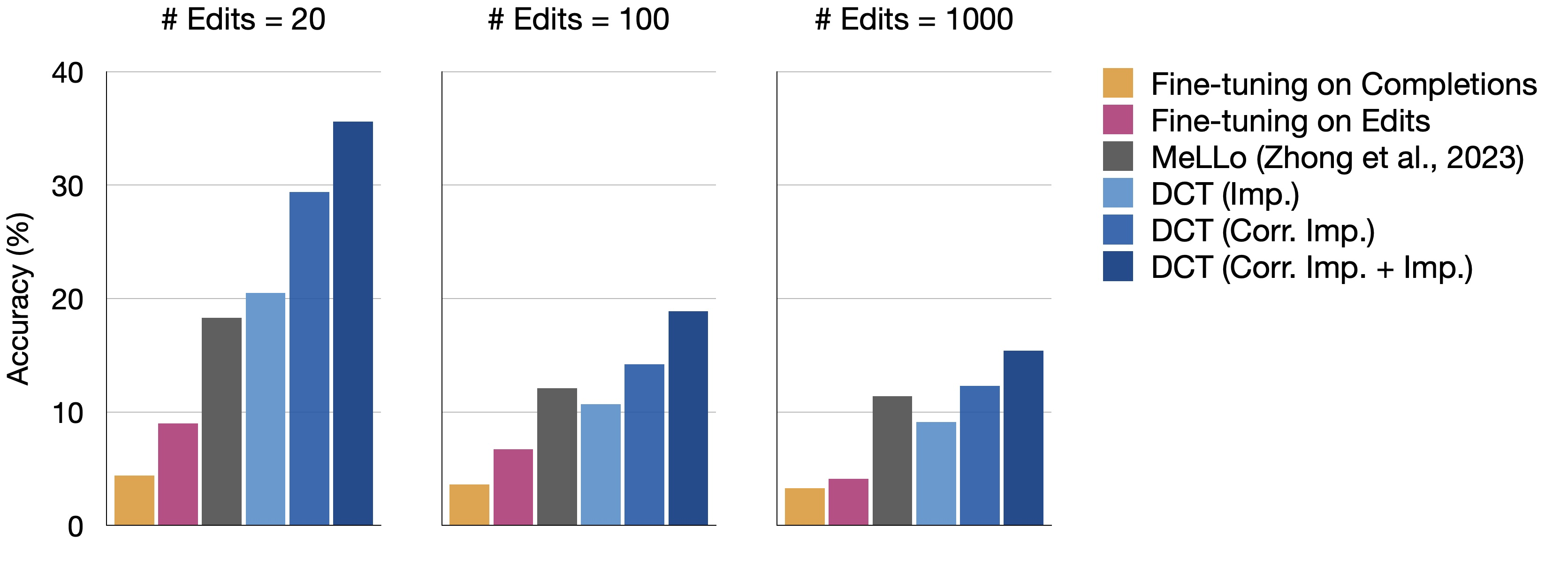
Problem States
standard LM training에 특정 text를 생성하도록 학습시킨다고 해서 그 text의 implies(함의)에 해당하는 text들의 probability가 높아지는 것은 아님.
Suggestion
factuality 측면에서 관련 fact set (text)에도 높은 확률을 assign하기 위한 방법으로 DCT 도입
- Deductive Closure Training (DCT; 연역적 폐쇄 훈련)으로 LM에 self-supervised 절차를 도입하여 LM이 자기가 생성하는 text 의 함의(내지는 모순)를 식별. (이하 절차: pic1)
- LM이 seed text에 대해 implication text와 모순적인(contradicting) text 생성
- 논리적으로 일관된 subset 식별 (LM prob 기반, pic3)
- 그 subset을 LM에 distill(finetuning)
- 활용 (pic2)
- supervised editing: 신뢰할 수 있는 데이터로 LM의 knowledge 갱신(편집) (pic2 right)
- unsupervised refinement: LM 합성 데이터만으로 accuracy 향상을 위해 unsupervised fine-tuning (pic2 left)
Effect
- fact verification: CREAK 벤치마크에서 SOTA (pic4)
- model updating (edit) → QA: MQUaKE에서 SOTA (pic5)
- LM 성능의 질적 향상을 위해서도 자체적인 실험 도입하여 DST의 우수성 확인
- 논리적으로 일관된 사실 주장에 높은 확률을 할당하도록