Benchmarking Large Language Models in Retrieval-Augmented Generation
Meta info.
- Authors: Jiawei Chen, Hongyu Lin, Xianpei Han, Le Sun
- Paper: https://arxiv.org/pdf/2309.01431.pdf
- Affiliation: ISCAS
- Published: December 20, 2023
Suggestions
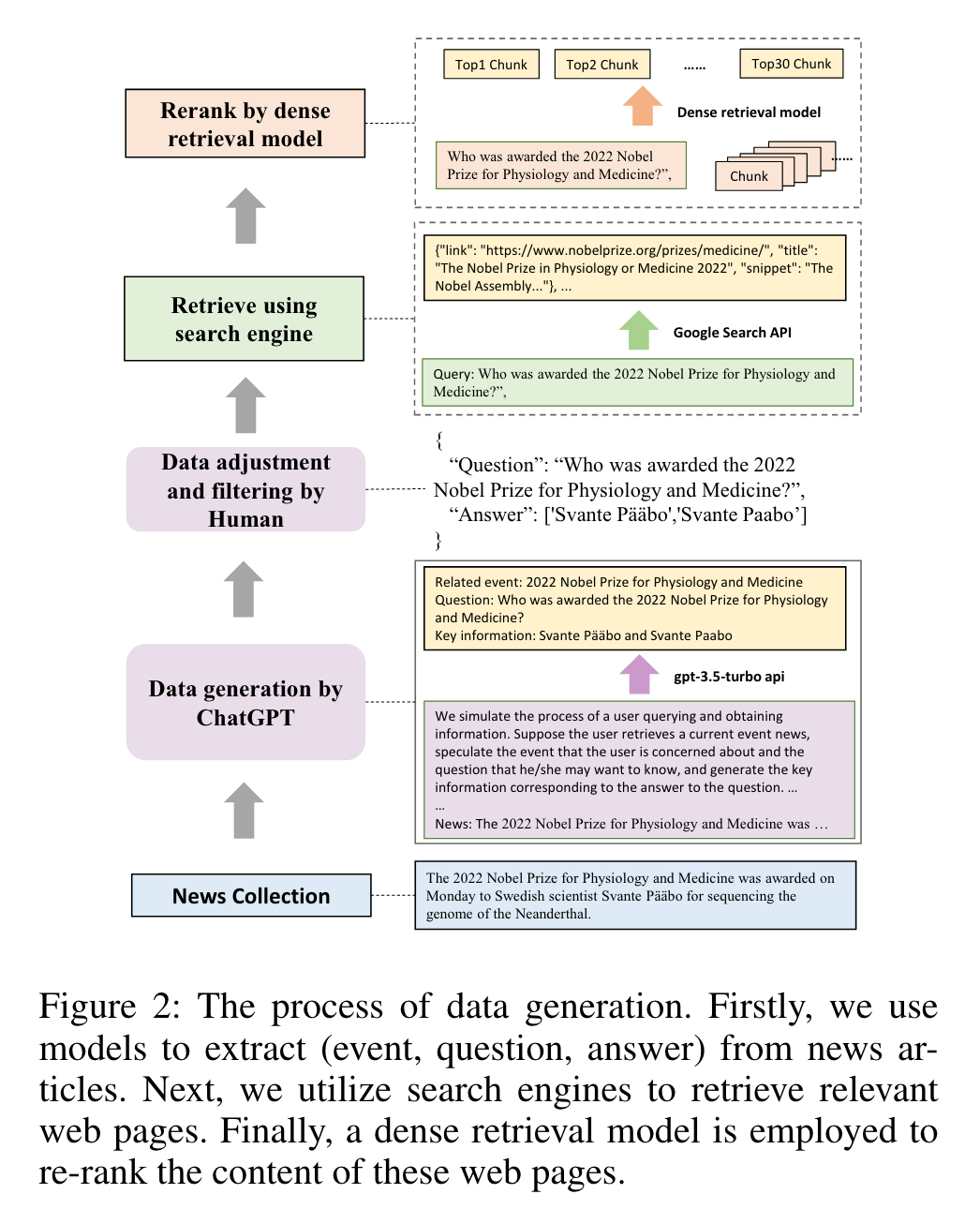
- RGB (Retrieval-Augmented Generation Benchmark)
- 최신의 news article을 수집하고,
- ChatGPT로부터 (events, questions, answers)을 생성시킴
- search engine으로 관련 web page 긁어와
- dense retrieval model로 top-k 텍스트 chuck 추출
- 위 4가지 test bed로 평가 진행
- Dataset Construction
- 수집한 뉴스 데이터 기반으로 event, question, answer를 구성 (ChatGPT 활용)
- 검색엔진으로 relevant web page 크롤링
- dense retrieval model이 문서 re-ranking
- Evaluation Design:
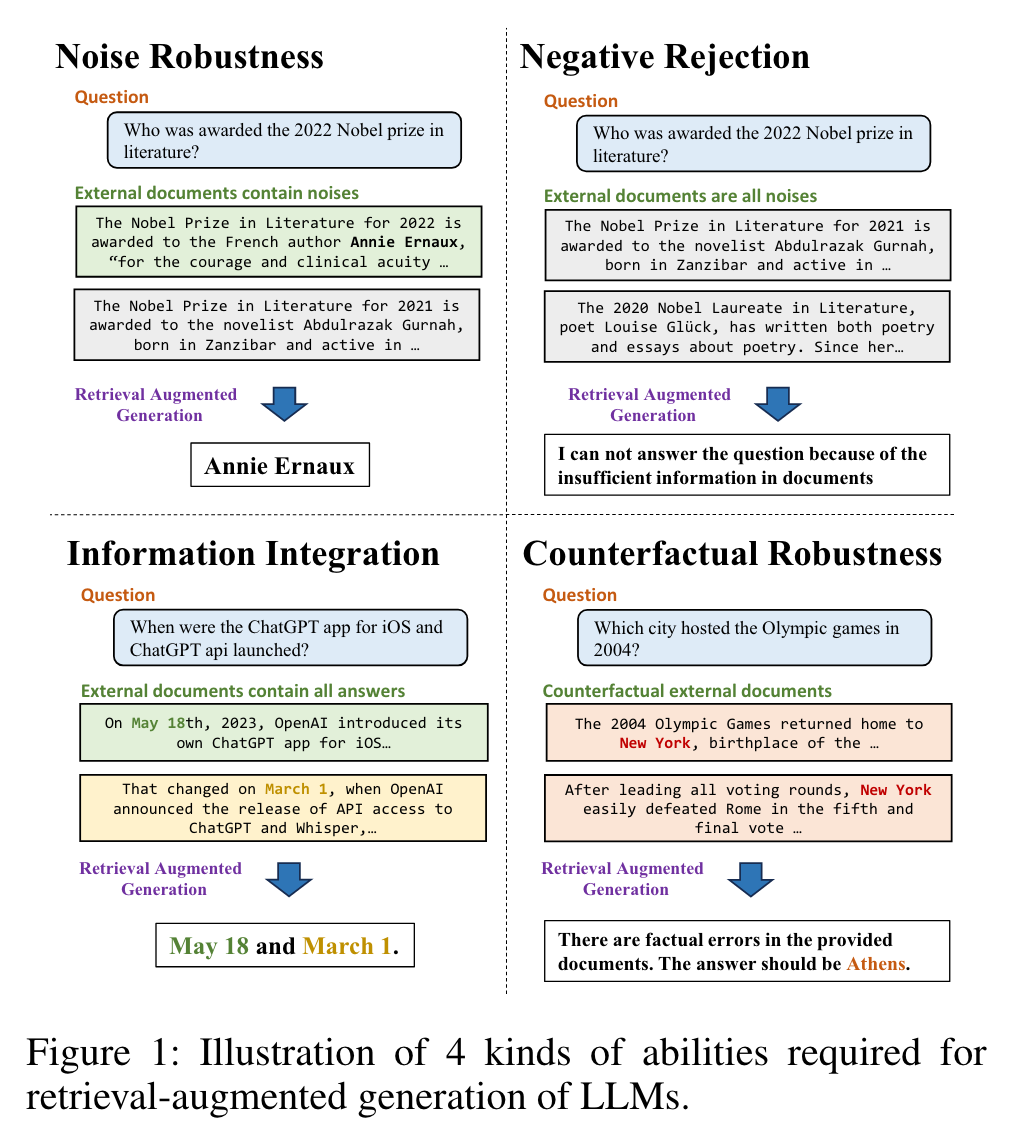
- RAG에서 등장할 수 있는 challenge 및 사용되는 4가지 testbed
- Noise Robustness: noisy document와 함께 retrieve되더라도 답변을 잘 하는지
- Negative Rejection: 유용한 information이 담긴 문서가 아예 retrieve되지 않을 경우 대답을 거절할 수 있는지
- Information Integration: 여러 문서로부터 정보를 integrate해 답변할 수 있는지
- Counterfactual Robustness: 문서에 factual error가 있을 경우 이를 알아차릴 수 있는지 (단, instruction에 발생 가능성 언급)
- RAG에서 등장할 수 있는 challenge 및 사용되는 4가지 testbed
Effects
- Metric
- Accuracy: noise robustness, information integration에서 exact match로 정답 잘 생성했는지
- Rejection Rate: negative rejection에서 답변 잘 거절했는지
- Error detection rate: counterfactual robustness에서 오류있다고 잘 감지했는지
- Error correction rate: 오류를 감지하고 이를 정답으로 잘 교정하는지
-
- LM이 instruction을 잘 따르지 못할 수도 있기 때문에 ChatGPT로 답변에 대한 추가적인 평가도 진행
- Results
- 문서가 길어지면 question의 핵심 정보와 answer간 거리가 멀어져 에러율 증가
- Noisy 문서를 늘리면 RAG 성능은 떨어지고(The Power of Noise: Redefining Retrieval for RAG Systems 논문과 유사한 결과), 모른다고 답변은 잘 못 함
- 복잡한 문제에 대해서 여러 문서로부터 정보를 추출하고 통합하여 답을 내는 데는 아직 어려움
- 모델은 internal knowledge를 갖고있음에도 external information에 의거해 답변함
- Factual error를 잘 구분 못 함
Personal note. RAG를 면밀히 평가할 수 있는 벤치마크를 제시함에 의의가 있고, 필요한 ability를 4가지로 유형화해 각각의 측면을 분석한 것이 인상적이다. 그럼에도 아직 개선시켜야 할 한계가 많고, 특히 관련 정보가 없거나 틀린 정보가 있을 때 이를 감지하고 개선시킬 수 있는 방향에 대해선 prompt를 주는 것 이외에도 고민이 필요해보임