RAGGED: Towards Informed Design of Retrieval Augmented Generation Systems
Meta info.
- Authors: Jennifer Hsia, Afreen Shaikh, Zhiruo Wang, Graham Neubig
- Paper: https://arxiv.org/pdf/2403.09040.pdf
- Affiliation: CMU
- Published: March 14, 2024
- Code: https://github.com/neulab/ragged
TL; DR
RAG의 다양한 setting 아래의 최적 대한 분석 (retriever type, reader model(=Generator), context selection등을 모두 고려)

Suggestions
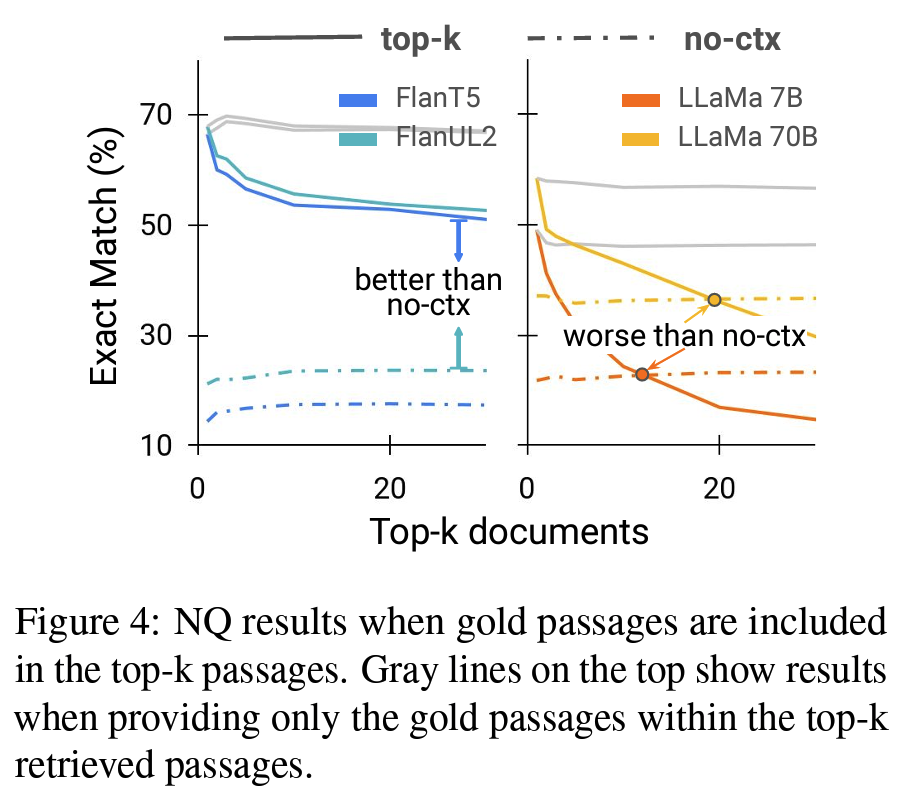
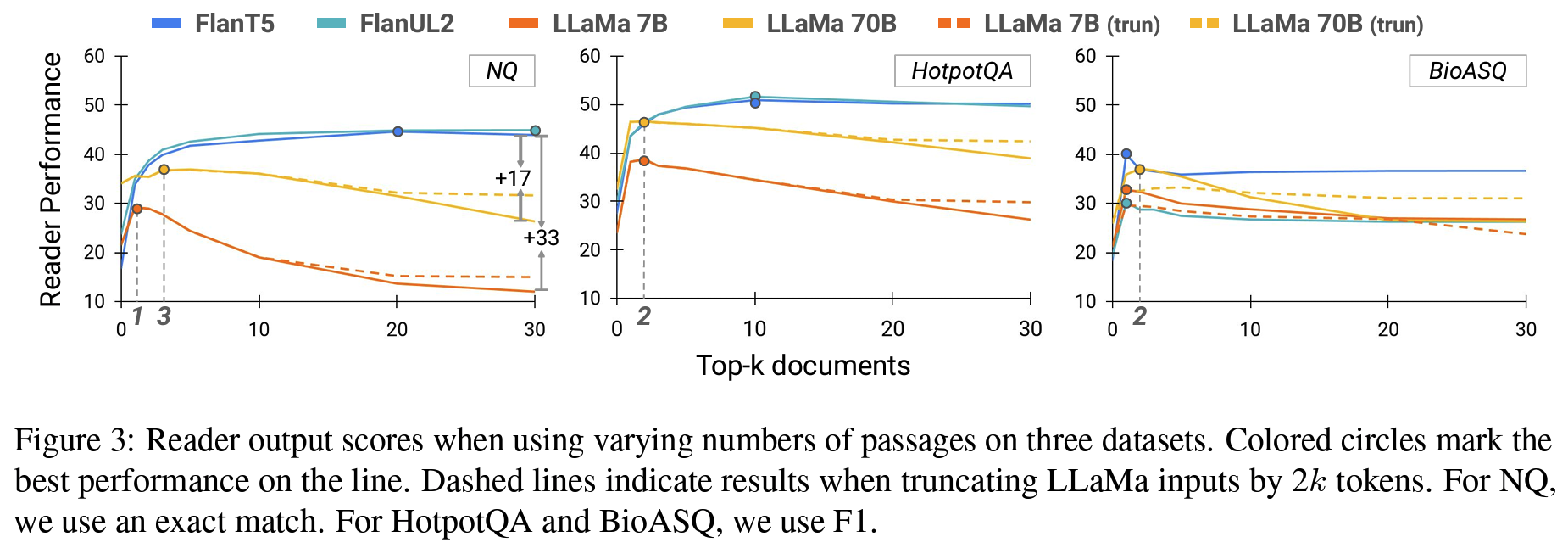
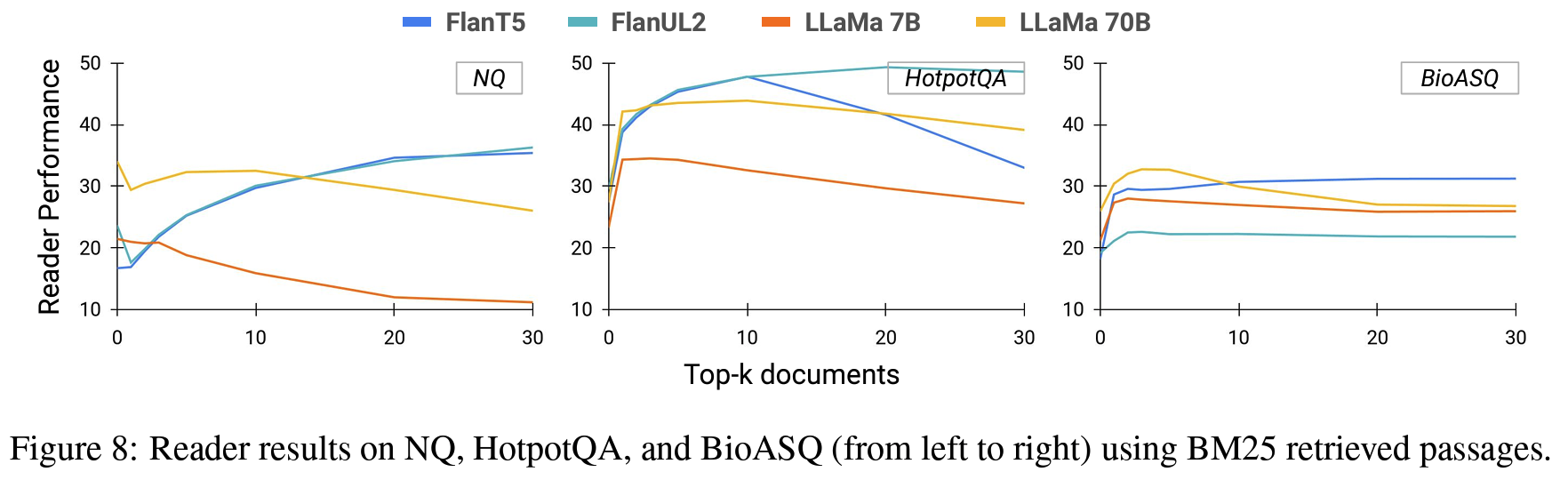
- Context 개수: (더 많은 context가 더 좋다는 통념은 깨진지 오래지만 모쪼록) LM과 task에 따라 그 수준이 달라진다. en-decoder model은 최대 30개, decoder-only는 5개 미만에서 최적.
- Reader model의 중요성: retriever-reader 사이 페어링의 중요성 강조. (ODQA) reader의 능력이 잠재적으로 부족한 내부 지식과 관련 external context을 구분하는 건 reader의 역량. LLaMA > FALN. decoder-only가 noisy documents에 더 취약한 동시에(+문서 개수가 늘어날수록 더욱) 한편으로는 ICL-setting처럼 새로운 지식에 대한 적응력은 우수.
- gold passage 포함여부: 모델 사이즈가 작을 때 negative passage로 이점을 얻는 경향. negative context가 answer로는 다소 모자라지만 related 하긴 한 경우에 더 유의하다고도 언급.
Personal note.
(실험을 FLAN, LLaMA로만 해서 일반화할 수 있을지는,,?)