LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
Meta info.
- Authors: Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, Dongmei Zhang
- Paper: https://arxiv.org/pdf/2403.12968
- Affiliation: Microsoft Research, Tsinghua Univ.
- Published: March 19, 2024
- Code: https://github.com/microsoft/LLMLingua
- References: project site
TL; DR
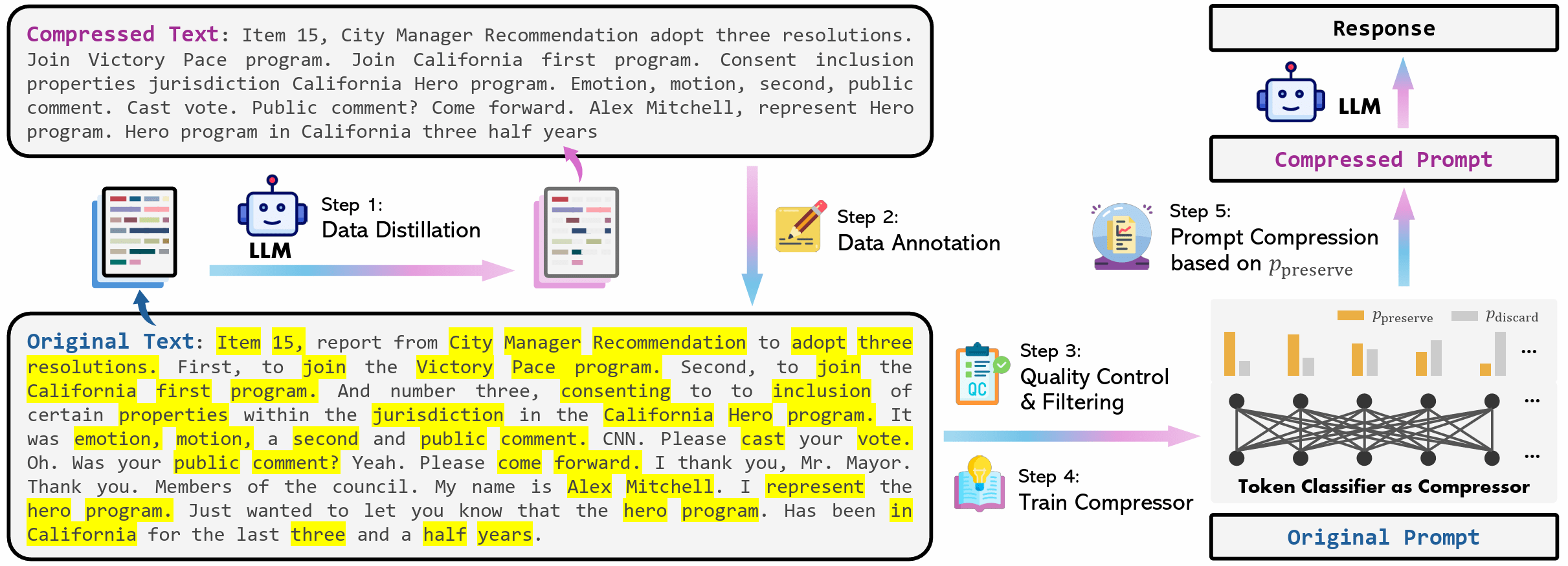
prompt compression을 token classification으로 formulate, encoder-based compressor 학습 제안 (Data Distillation)
Problem States
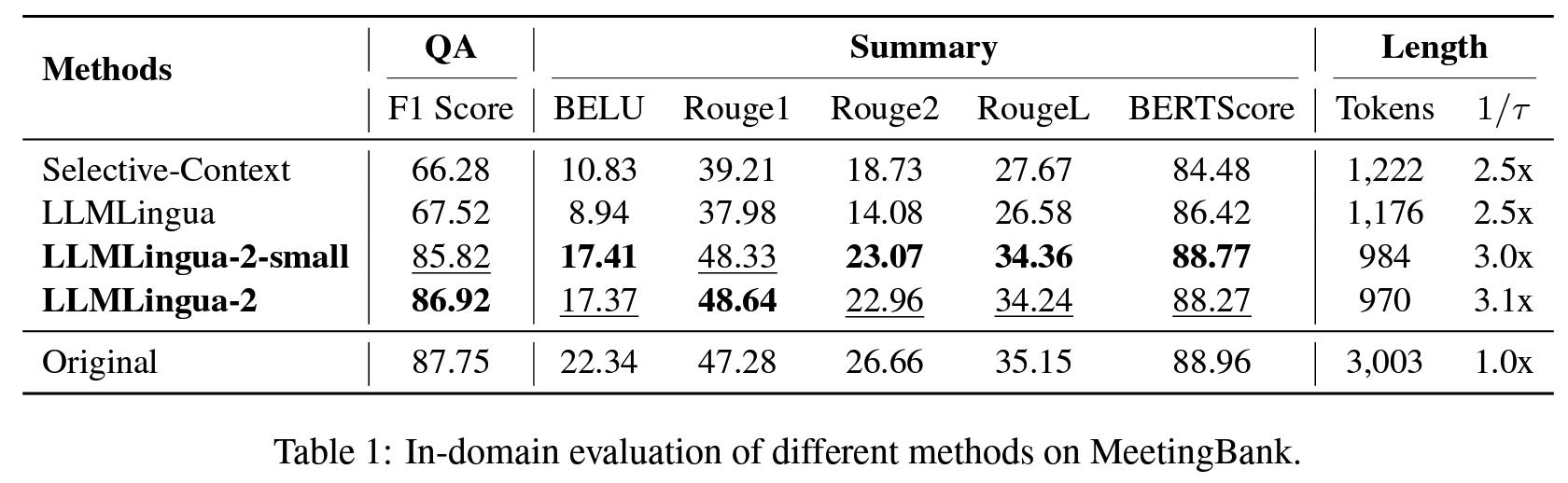
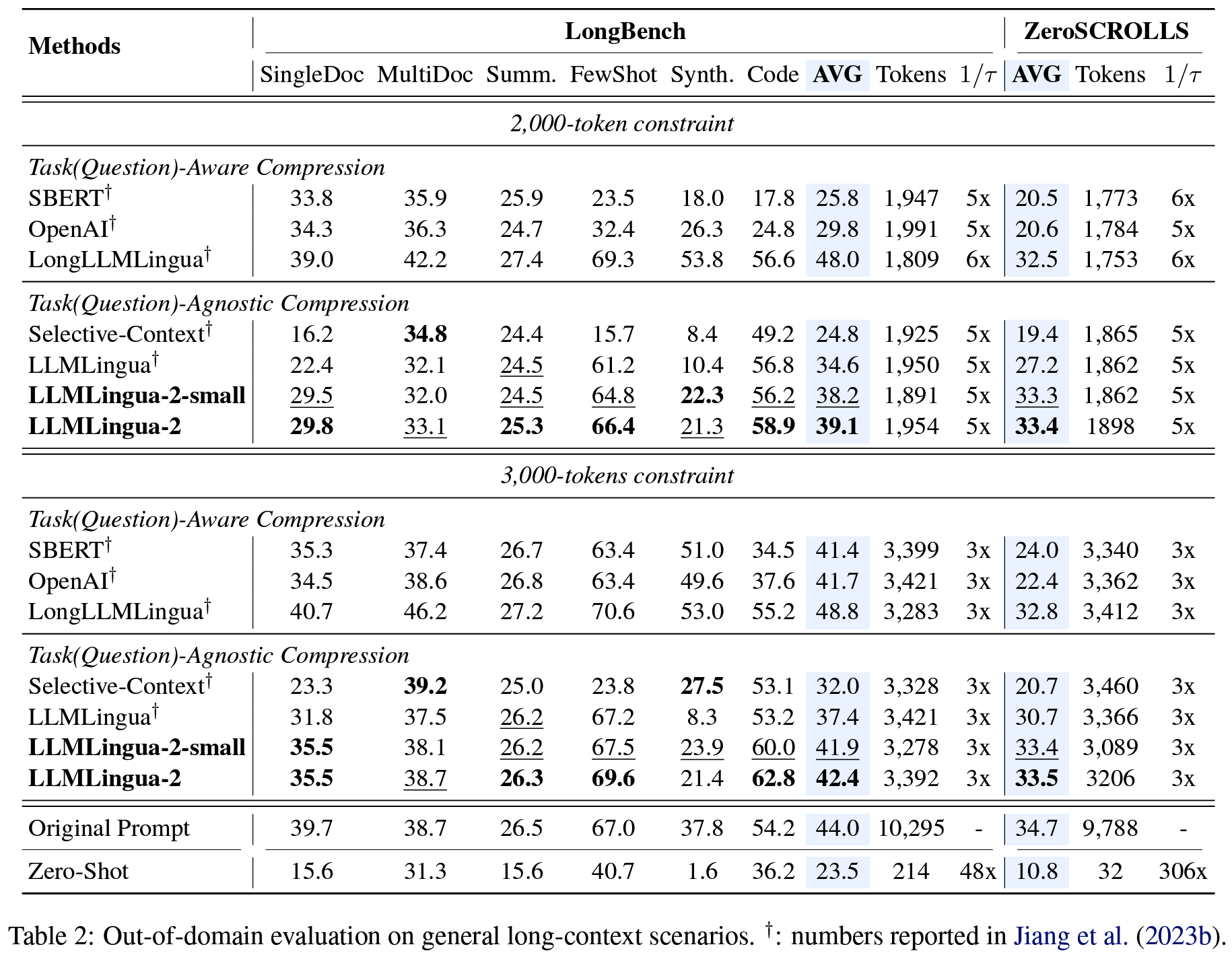
PPL(entropy)를 기반했던 기존 LLMLingua방식이 최적은 아니므로, prompt compression의 objective에 부합하지 않는 것을 문제로 인식
Suggestions
prompt compression을 token classification으로 formulate, encoder-based compressor 학습 제안 (Data Distillation)
- sLLM튜닝+PPL 측정기반 방식 대신 LLM에 프롬프트로 압축을 명시적으로 지시, 그 결과를 token단위 labeling
- BERT 등 encoder 기반 모델로 bidirectional context-aware compression 달성: 원본 prompt의 token을 버릴지, 유지할지 결정