ReALM: Reference Resolution As Language Modeling
Meta info.
- Authors: Joel Ruben Antony Moniz, Soundarya Krishnan et al.
- Paper: https://arxiv.org/pdf/2403.20329
- Affiliation: Apple Inc.
- Published: March 29, 2024
TL; DR
Pipeline style로 reference resolution에 대해 finetune된 작은 모델(ReALM)로 해결 시도
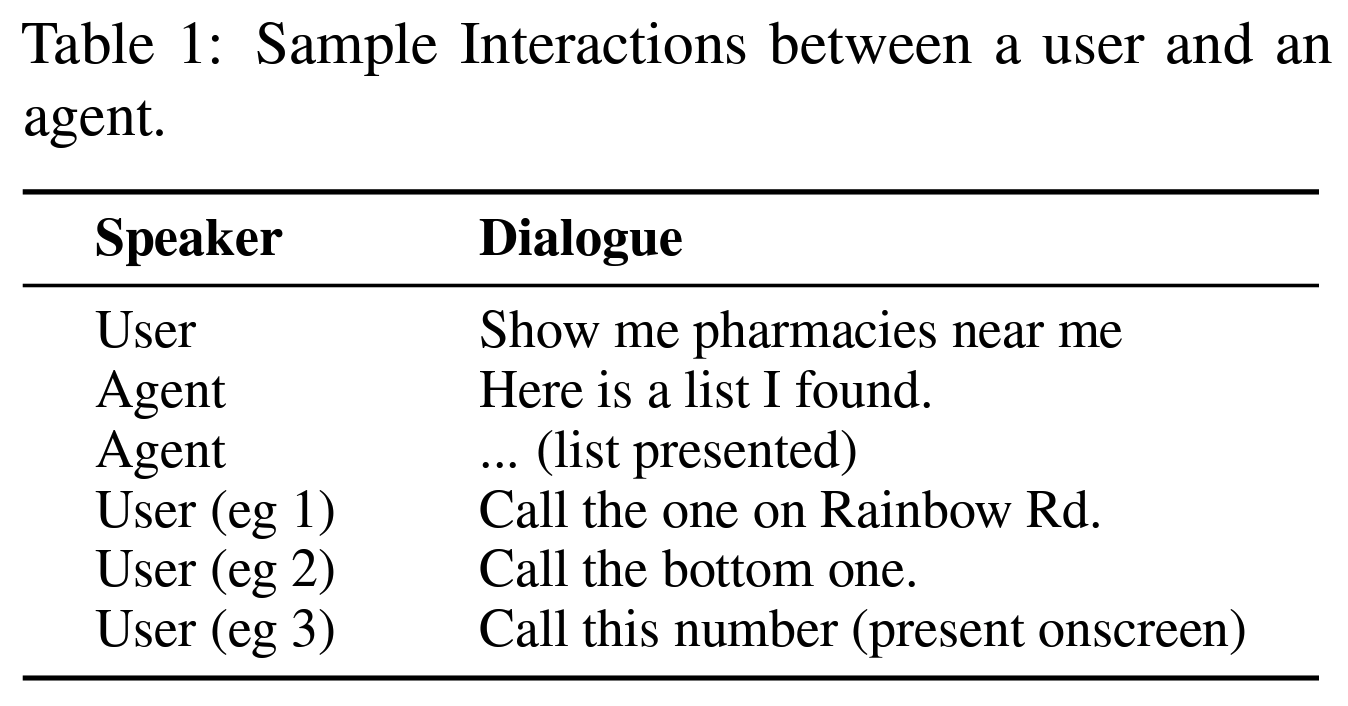
Problem States
spoken language에서 자연스럽게 발생되는 referencing에 대한 ambiguity를 e2e LLM들이 제대로 대처하지 못함.
- 대화내에서 존재하는 referencing은 물론이고,
- on-screen에서 혹은 device interaction setting에서 존재하는 background entity(대화에서 언급되지는 않았지만 존재하는, 예를 들면 재생중인 음악이나 울리고 있는 알람 등) 에 대한 referencing을 모두 해결할 필요성에 대해 역설.
Suggestion
Pipeline style로 reference resolution에 대해 finetune된 작은 모델(ReALM)로 해결 시도
- on-device setting에서의 이점이나 해석가능성 혹은 모듈화 이점 강조
- conversational 에서든 on-screen 에서든 모두 적용 가능한 일관적 방식 제안
- parsed entities와 그 위치로 screen 재구성: 화면 내용을 시각적으로 표현하는 purely textual representation 생성
- conversational references(Conv): entity type별, entity별 propreties를 모두 encoding
(굉장히 소모적이지 아니한지,,? ) - on-screen references(Screen): (이전대화 등에서) 화면상 text에서 entity를 extract 할 수 있다고 가정 (해당 entity의 type, bounding boxes + non-entity text elements를 모두 사용 가능), 화면상 존재하는 모든 entities를 sorting해서 식별해둠
(마찬가지로 굉장히 소모적인듯)
- conversational references(Conv): entity type별, entity별 propreties를 모두 encoding