SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
Meta info.
- Authors: Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, Jing Gao
- Paper: https://arxiv.org/pdf/2405.20974
- Affiliation: Purdue Univ., UIUC
- Published: June 5, 2024
- Code: https://github.com/xu1868/SaySelf
TL; DR
자기 반성적(?) 근거와 다중 추론 chain으로 LLM에서 신뢰도 보정 오류를 30% 줄인다


Problem States
LLM hallucination 관련, 생성결과의 신뢰도 추정치가 없는데, 기존의 prompt를 건들거나 training하는 방식의 신뢰도 추정은 간접적 혹은 차선책으로 보여짐. (pic1 )
Suggestions
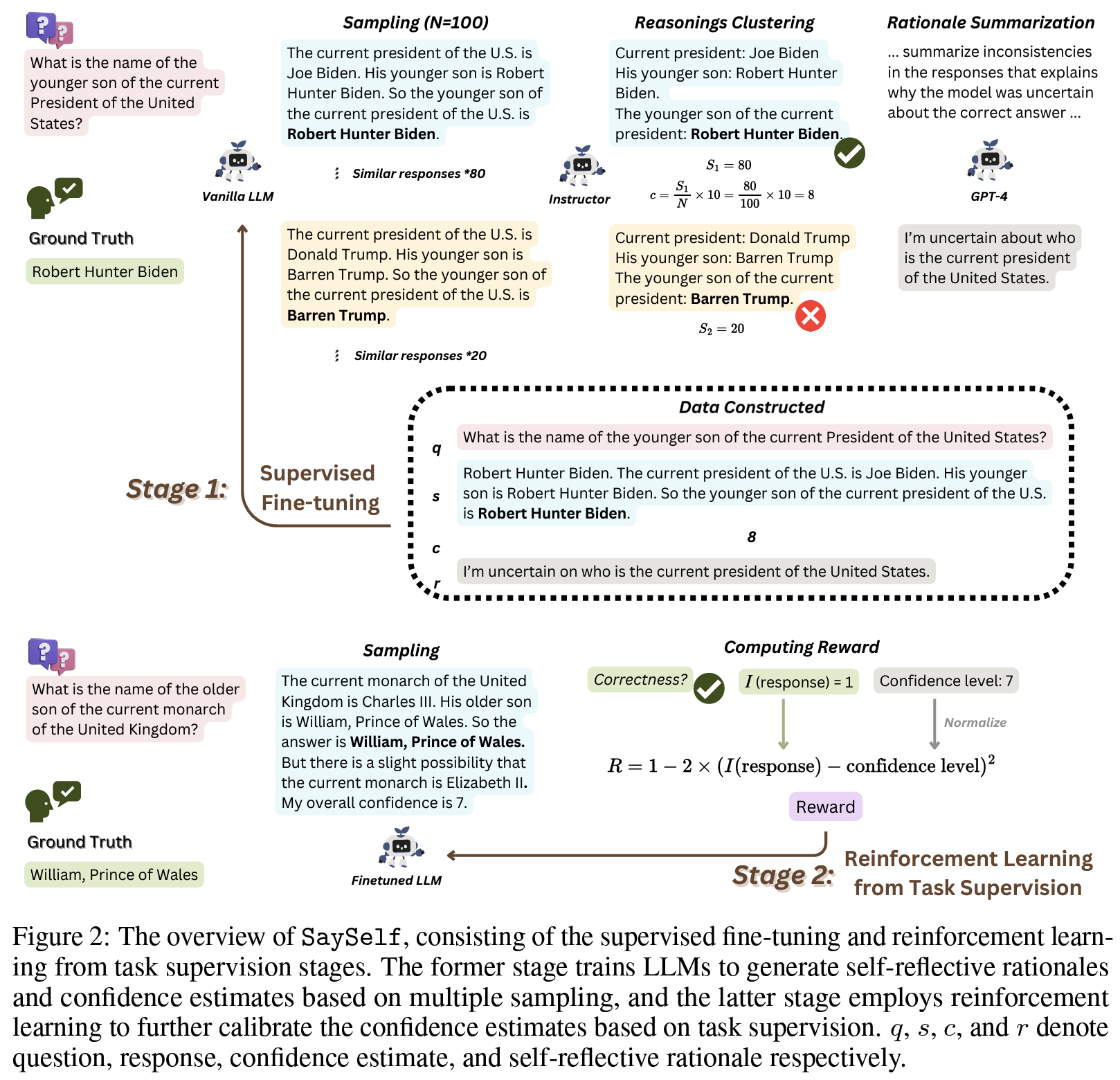
SaySelf - LLM 신뢰도 추정치 제공 및 자기반성적 추론 (근거) 직접 생성(pic2)
- (stage 1) finetuning: construct supervised dataset (구성: q, 추론 chain 포함 a, 자기 반성적(?) 근거, 10점 척도의 신뢰도 추정치)
- HotpotQA의 90K 질문으로 다회 프롬프팅 → 생성물 clustering (사전 정의된 크기 s만큼)→ cluster에서 1개 응답 선택
- 신뢰도 추정치: 선택된 응답과 gold answer랑 비교해서 c 결정 (c=round(s/N*10) 휴리스틱하게 정의됨)
- 자기반성적 근거: GPT4에게 응답의 불일치성을 분석 및 요약하게 해서 1인칭 시점에서 내용 정리시킴
- (stage 2) reinforcement learning (from stage 1 task supervision): finetuning만으로는 정답에는 낮은, 오답에는 높은 신뢰도를 보이는 경우 존재하기 때문에 신뢰도 추정치 보정 시도
- 모델prompt 요청사항: a, 자기 성찰적 근거, 신뢰 수준 c 생성
- PPO활용, reward function 정의 (
pic3)