Word Translation Without Parallel Data
Meta info.
- Authors: Alexis Conneau, Guillaume Lample, Marc'Aurelio Ranzato, Ludovic Denoyer, Hervé Jégou
- Paper: https://openreview.net/forum?id=H196sainb
- Affiliation: Meta AI
- Code: https://github.com/facebookresearch/MUSE
- Conference: ICLR2018
TL; DR
(token) Embedding Alignment 를 통한 x-lingual translation 성능 향상
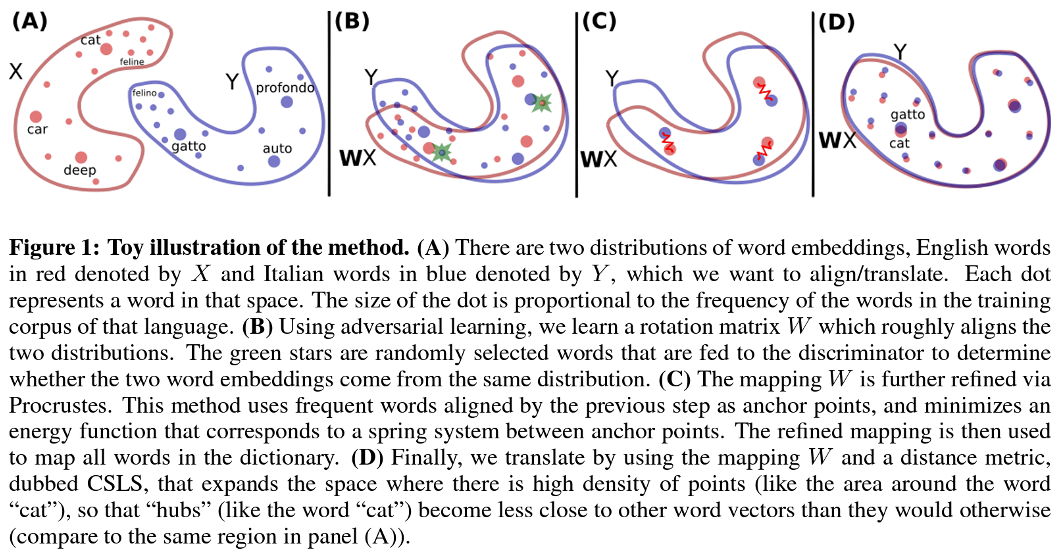
Suggestions
- Initialization: fastText (monolingual) word embedding
- Step 1. Adversarial Learning
- Discriminator: source – target 구분
- Mapper: source – target 구분 못하게
- Step 2. Procrustes Refinement
- Frequent words를 anchor로 두고 Frobenius norm minimize source – target
- Step 3. Cross-Domain Similarity Local Scaling (CSLS)
- Hubness : certain points tend to be the nearest neighbors of many other points
- Cosine similarity measure 의 변형: considering the average similarity of each word to its nearest neighbors