Pandora’s Box or Aladdin’s Lamp: A Comprehensive Analysis Revealing the Role of RAG Noise in Large Language Models
Meta info.
- Authors: Jinyang Wu, Feihu Che, Chuyuan Zhang, Jianhua Tao, Shuai Zhang, Pengpeng Shao
- Paper: https://arxiv.org/pdf/2408.13533
- Affiliation: Tsinghua Univ.
- Published: August 24, 2024
TL; DR
LLM의 RAG 상황에서 다양한 Noise를 구분하고 분석. 유익한 Noise의 경우 모델 성능이 향상된다는 것을 확인. 벤치마크 NoiserBench를 제시하여 LLM의 Noise 대응 평가 및 유익한 noise는 활용하고 해로운 noise는 줄이는 방법 제시.


Problem States
일반적으로 RAG에서 가정하는 Noise가 정말 모두 유해한가? 유해한 noise와 유익한 noise를 구분할 수 있을까?
Suggestion
- 언어적 관점에서 7-type의 Noise 정의
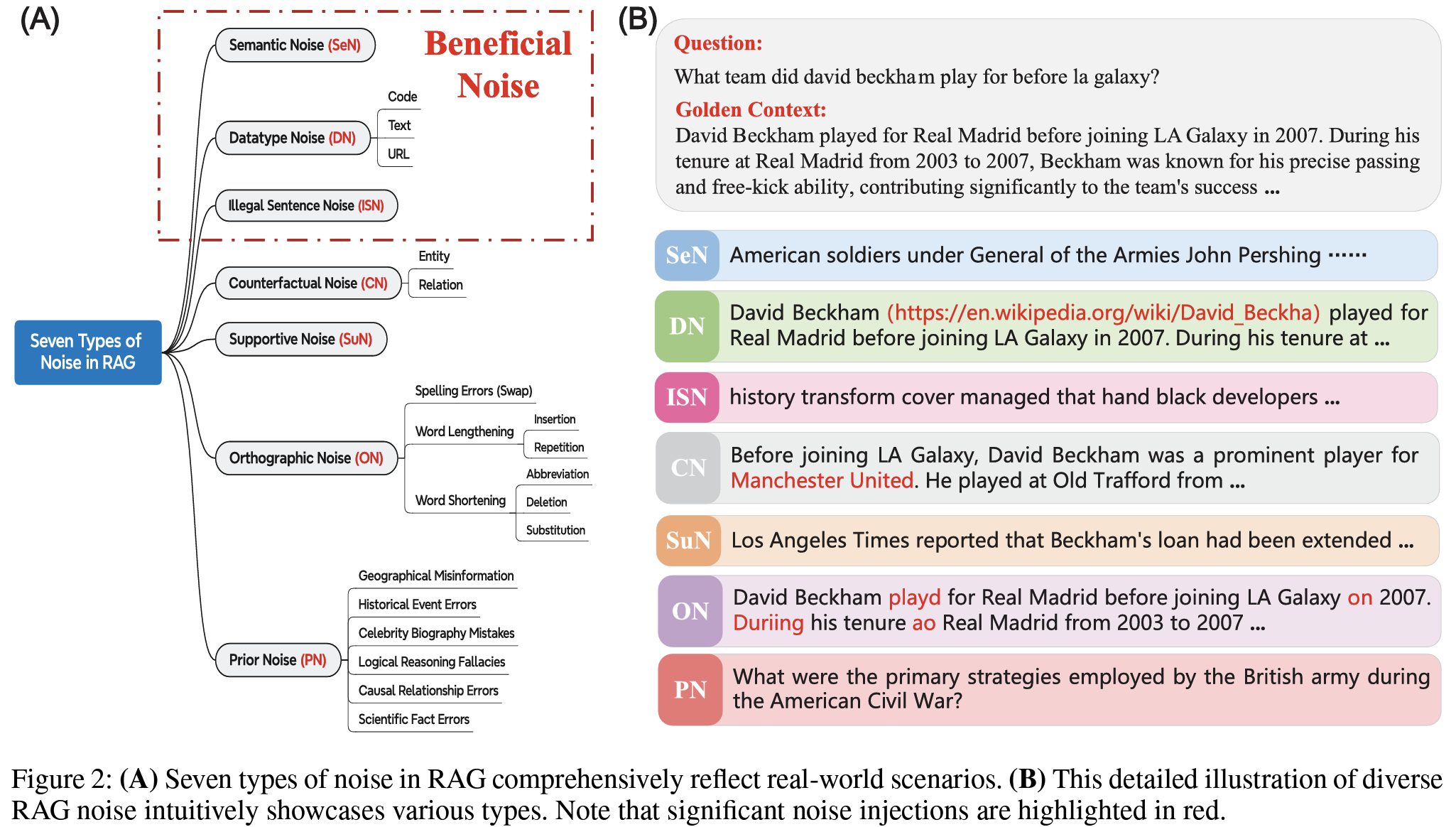
Figure 2- 유익한 Noise: Semantic Noise (SeN), Datatype Noise (DN), Illegal Sentence Noise (ISN)
- Semantic Noise (SeN): query와 의미적으로 관련성이 낮은 내용 (주제에서 벗어나거나 의도된 의미에서 벗어난 경우)
- Datatype Noise (DN): 웹상에서 서로 다른 데이터 유형이 혼합된 경우 (e.g.Wikipedia에서 링크와 텍스트가 혼합된 경우)
- Illegal Sentence Noise (ISN): 문법적으로 옳지 않은 문장 (e.g. history transform cover managed that hand black)
- 유해한 Noise:Counterfactual Noise (CN), Supportive Noise (SuN), Orthographic Noise (ON), Prior Noise (PN)
- Counterfactual Noise (CN): 사실과 다른 정보. 가짜 뉴스, 오래된 정보
- Supportive Noise (SuN): 주장과 의미적으로 관련성이 높지만 답변 정보는 없는 문서
- Orthographic Noise (ON): 철자 오류, 단어 길이 변경과 같은 오류
- Prior Noise (PN): 잘못된 가정이나 전제에 기반한 질문 (e.g. query: 구글이 2017년에 Alphabet으로 구조조정 당시 CEO는 누구? - 구조 조정은 2015년에 발생)
- 유익한 Noise: Semantic Noise (SeN), Datatype Noise (DN), Illegal Sentence Noise (ISN)
- NoiserBench 제안
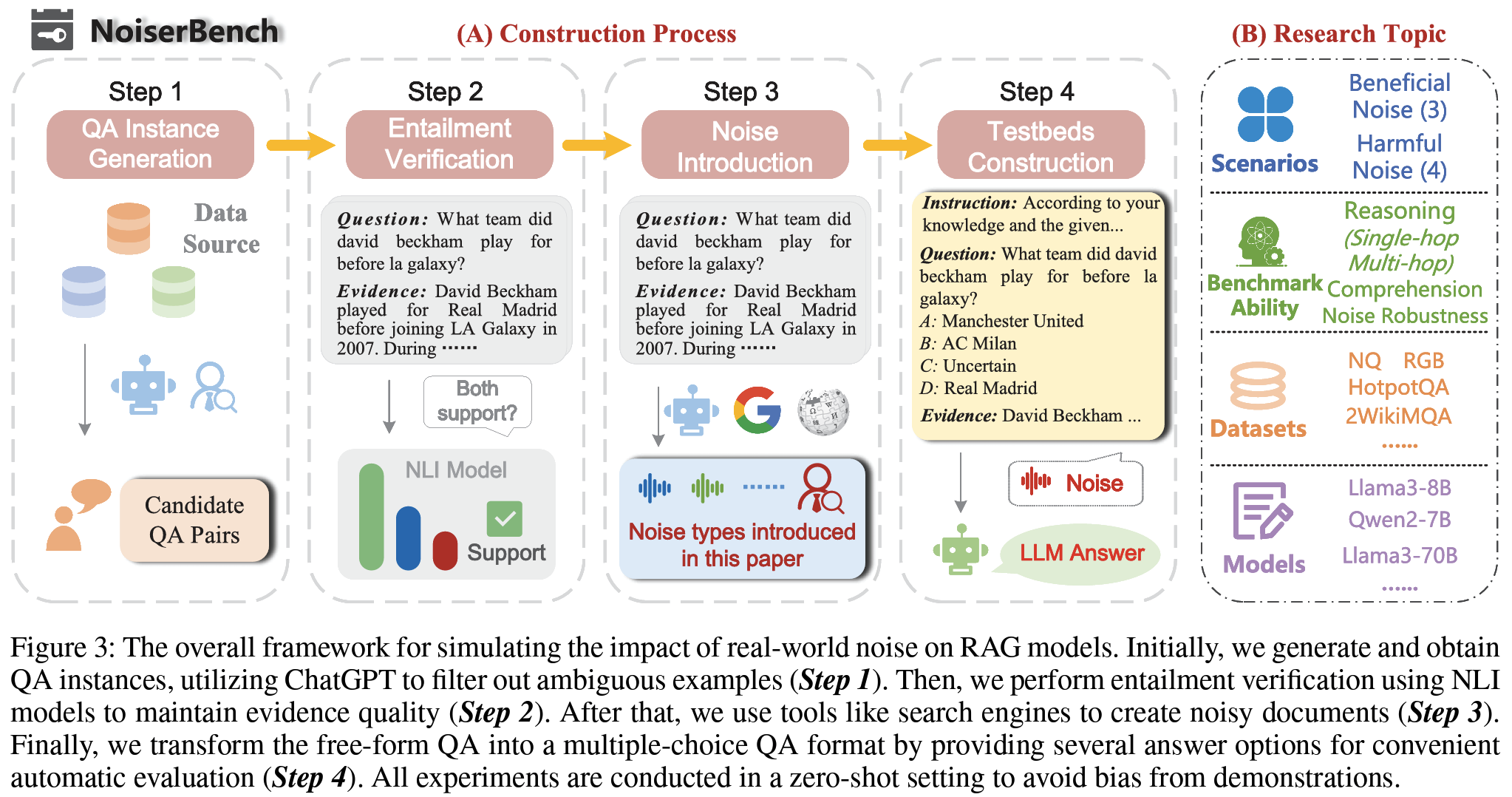
Figure 3- QA Instance Generation: ChatGPT로 모호한 예시 거르면서 QA pair 생성/수집 (PN 제외하고 기존 방법론이 있다는데 자세히 확인해봐야할듯? )
- Entailment Verification: NLI model bart-large-mnli-407M로 evidence가entailment인지 확인
- Noise Introduction: Google 검색 엔진 등 외부 툴로 각 type에 해당하는 Noise 생성. 가령 CN은 Google 검색 결과에서 entity-relation 추출하고 이와 반대되는 response 생성 후 ChatGPT로 evidence 생성. SuN이나 SeN은 wikipedia dump를 source로 해서 모델 활용하여 검색 or 관련성 필터링 등 진행. ISN은 모델 vocab에서 임의 단어 조합 후 의미 없는 문장 구성. 실제 횡설수설하는 느낌으로 모방 하는 등
Figure 4 - Testbeds Construction: free form QA를 객관식으로 변형하는 등, seed dataset으로 구축.
- Single-hop(1-step reasoning): NQ, RGB
- Multi-hop(Explicit multi-step reasoning): HotpotQA, 2WikiMQA, Bamboogle
- Multi-hop(Implicit multi-step reasoning): StrategyQA, TempQA
- Mixed-hop: PriorQA
Effects
유익한 Noise는 LLM 성능과 reasoning, confidence를 향상시킨다. (유해한 경우는 성능 하락)
- Experimental Setup:
- Backbone: 8개 LLM (Llama3-Instruct (8B, 70B), Qwen2-7B-Instruct, Mistral (7B, 8x7B), Vicuna-13B-v1.5, Llama2-13B, Baichuan2-13B)
- Metric: Accuracy
- Result:
- 유익한 Noise는 보다 명확한 reasoning, 표준화된 출력 형식, golden context에 대한 높은 신뢰도 등 모델 성능 향상에 기여
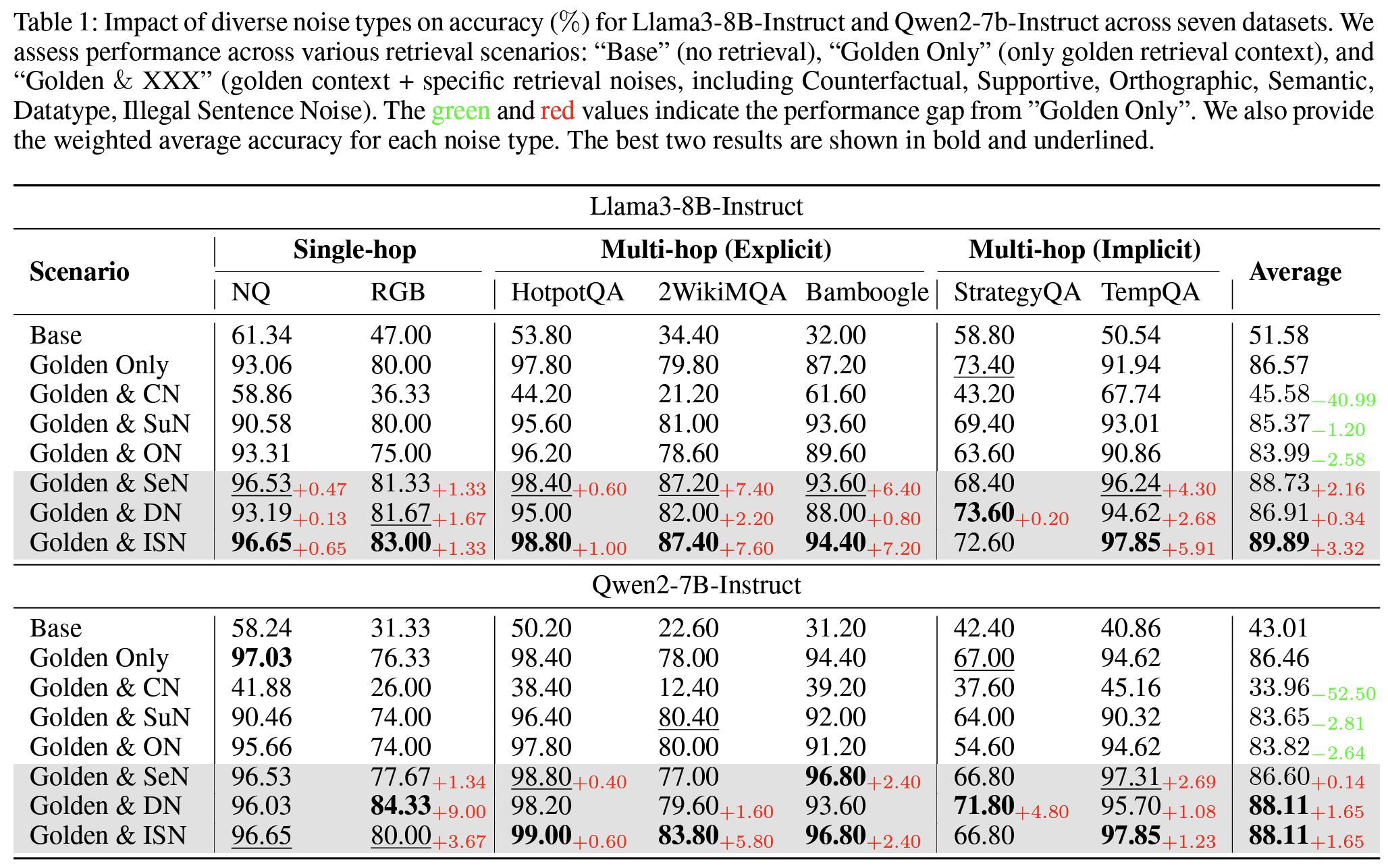
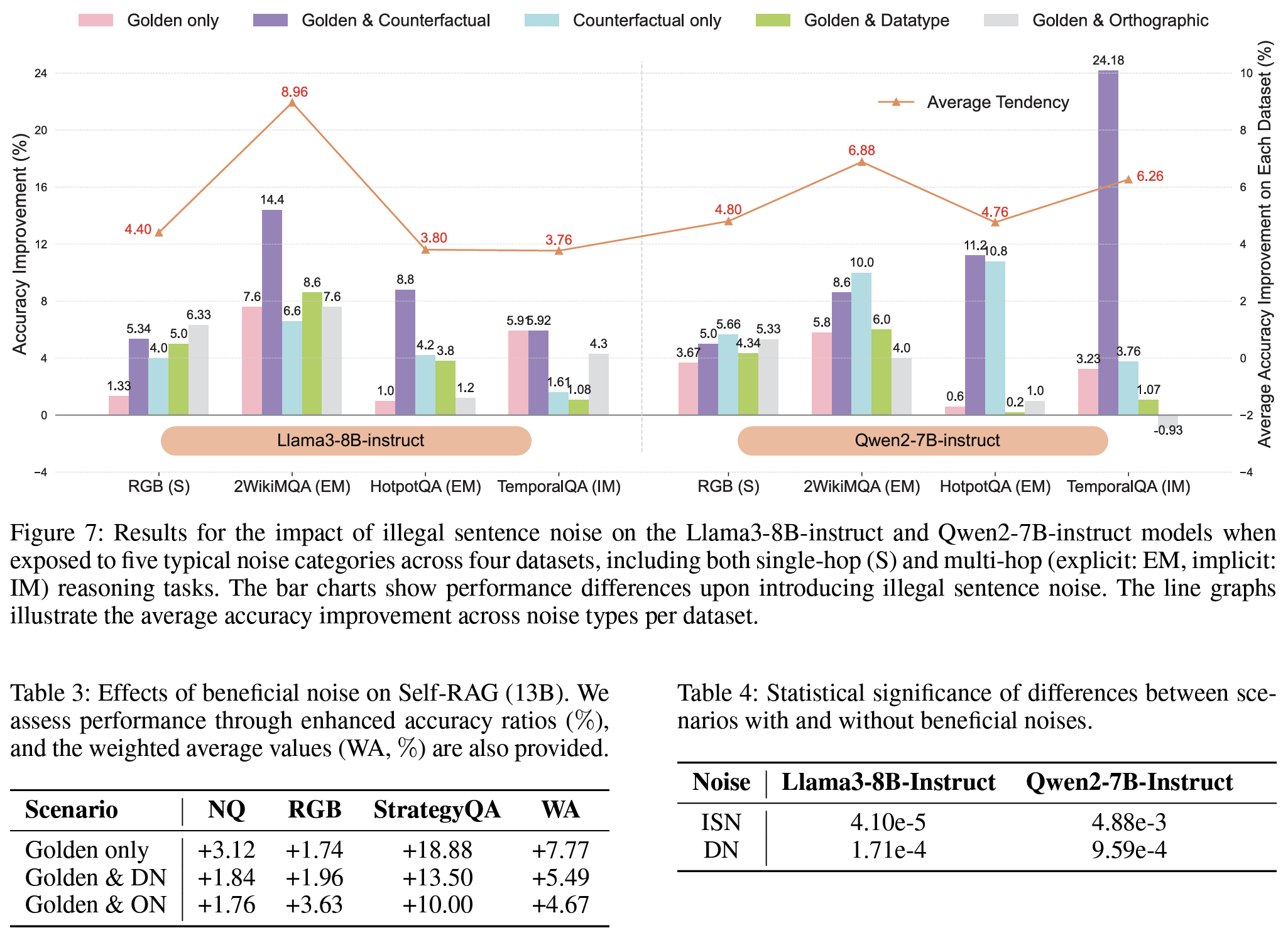
Table 1: Llama3-8B-Instruct / Qwen2-7b-Instruct로 7개 데이터셋에서 각 Noise type이 정확도에 미치는 영향 확인. 특히 ISN의 경우 모델 성능 크게 향상Table 4: 통계적 유의성 검증을 위해 Wilcoxon signed-rank test로 확인Table 5: Llama3-8B-instruct에서 유익한 Noise가 있고 없을 때 응답 차이Figure 7: 대부분 ISN 추가되면 성능 향상되고, CN이 있는 환경에서 ISN이 추가되면 더욱 정확도 향상
- 유익한 Noise는 보다 명확한 reasoning, 표준화된 출력 형식, golden context에 대한 높은 신뢰도 등 모델 성능 향상에 기여