Theory, Analysis, and Best Practices for Sigmoid Self-Attention
Meta info.
- Authors: Jason Ramapuram, Federico Danieli, Eeshan Dhekane, Floris Weers, Dan Busbridge, Pierre Ablin, Tatiana Likhomanenko, Jagrit Digani, Zijin Gu, Amitis Shidani, Russ Webb
- Paper: https://arxiv.org/pdf/2409.04431
- Affiliation: Apple Inc.
- Published: September 6, 2024
- Code: https://github.com/apple/ml-sigmoid-attention
TL; DR
Softmax를 Sigmoid와 상수 bias (sequence length기반)로 대체하는 등의 방식으로 attention 연산 속도를 18%가량 향상시킨 FLASHSIGMOID 제안


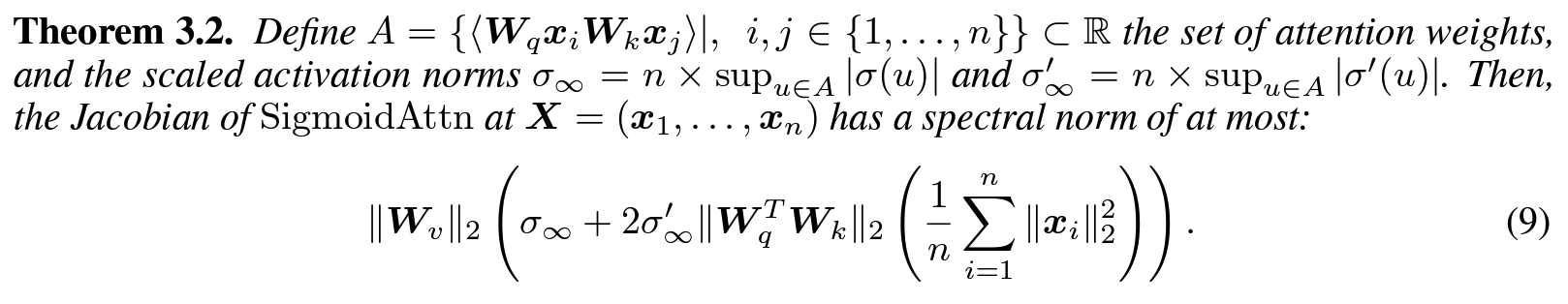
Problem States
- RQ1: sigmoid attention이 범용 seq2seq approximator로 쓸 수 있나? > ANS1: Yes (
Theorem 3.1) - RQ2: sigmoid를 써도 여전히 강건하고 optimize하기 용이한가? > ANS2: Yes (
Theorem 3.2)- (직관) sigmoid att이 softmax의 정규화 상수를 포함하지 않으므로 (local Lipschitz 상수로 계산해보니 저자들이 도출한 범위가) 입력 x_i의 average squared-norm에 의존 (softmax att은 largest squared-norm에 의존!)
Suggestion
hardware-aware한 구현의 FlashAttention 2 확장판 FlashSigmoid 제안
- Tiling: FLASHATTENTION series와 유사하게 block 단위 attention 수행에서 divide-and-conquer approach 적용
- Kernel Fusion: memory access를 최소화하기 위해 계산 단계를 단일 GPU 커널로 구현
- Activation Recomputation: partition funct. 계산 없애고 tanh 사용. **sigmoid(x) = 0.5 * (1 + tanh(0.5 * x))**
Effects:
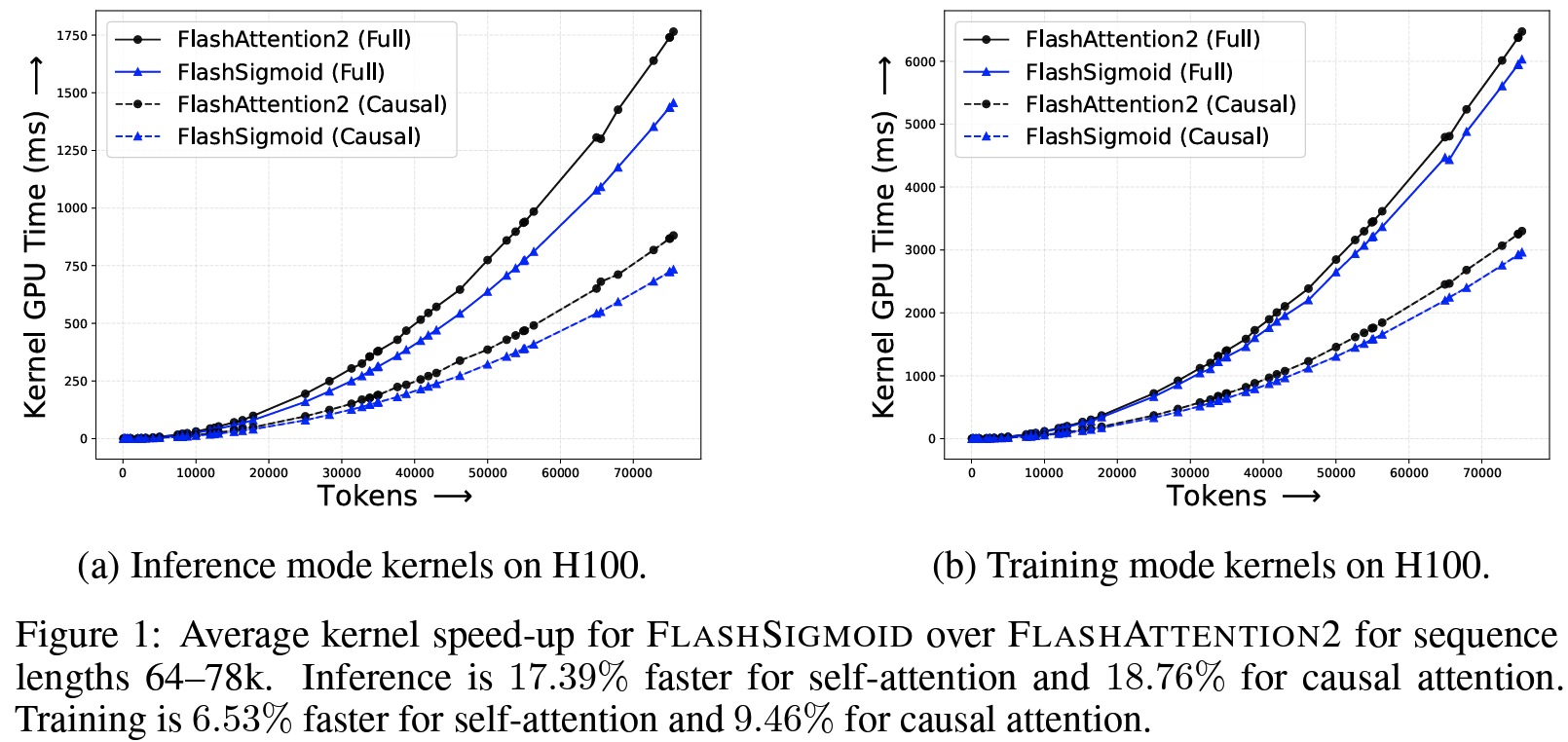
- Results: H100기준 causal attention시 inference는 평균 18.76%, training(forward + backward)은 평균 9.46% 개선
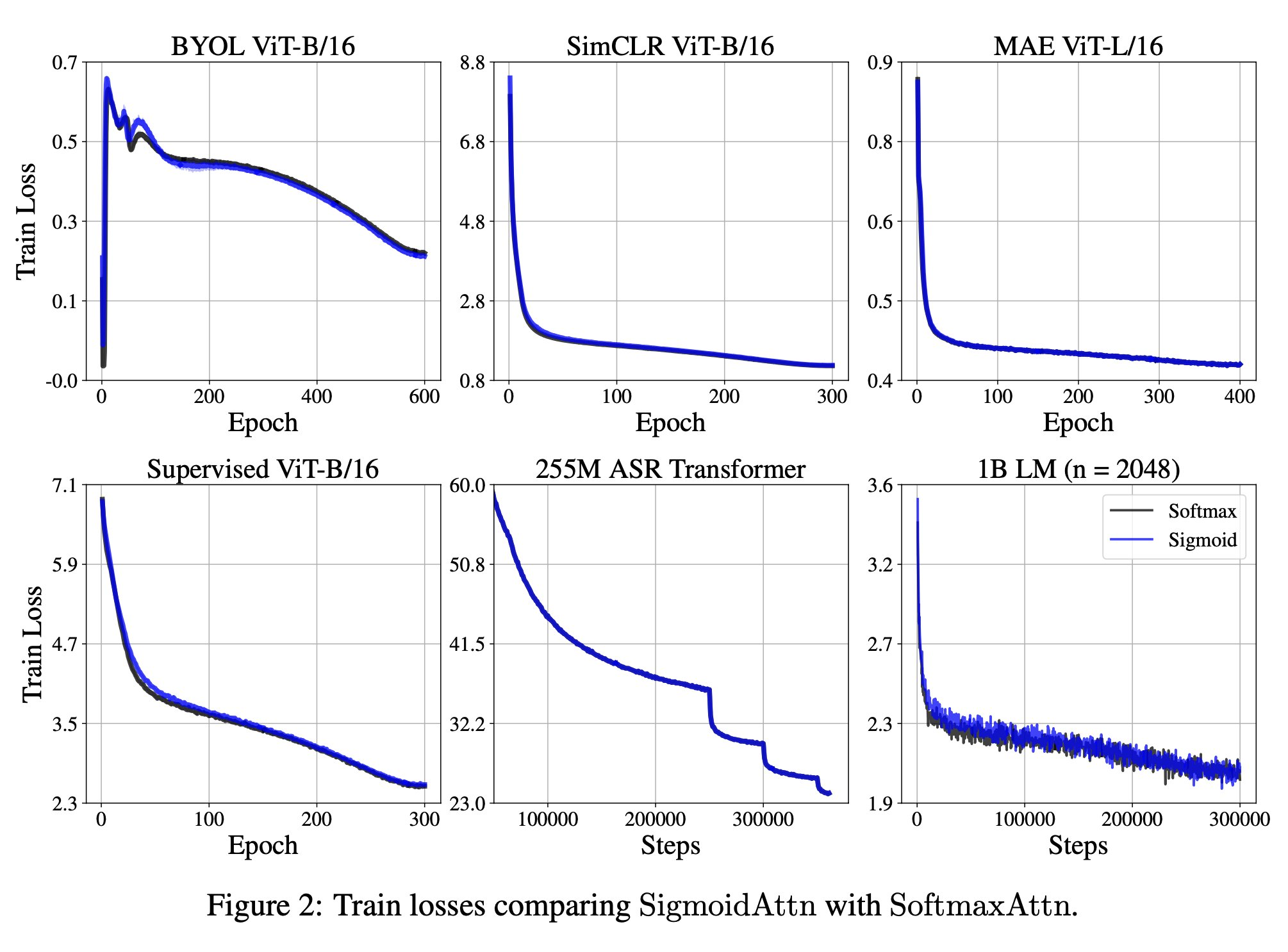
Figure 1- 저자들이 테스트한 갖은 종류와 task에서 모두 동등한 수준의 성능 확인: supervised image classification using vision transformers / self-supervised image representation learning with SimCLR, BYOL, Masked AutoEncoder / automatic speech recognition(ASR) / language modeling
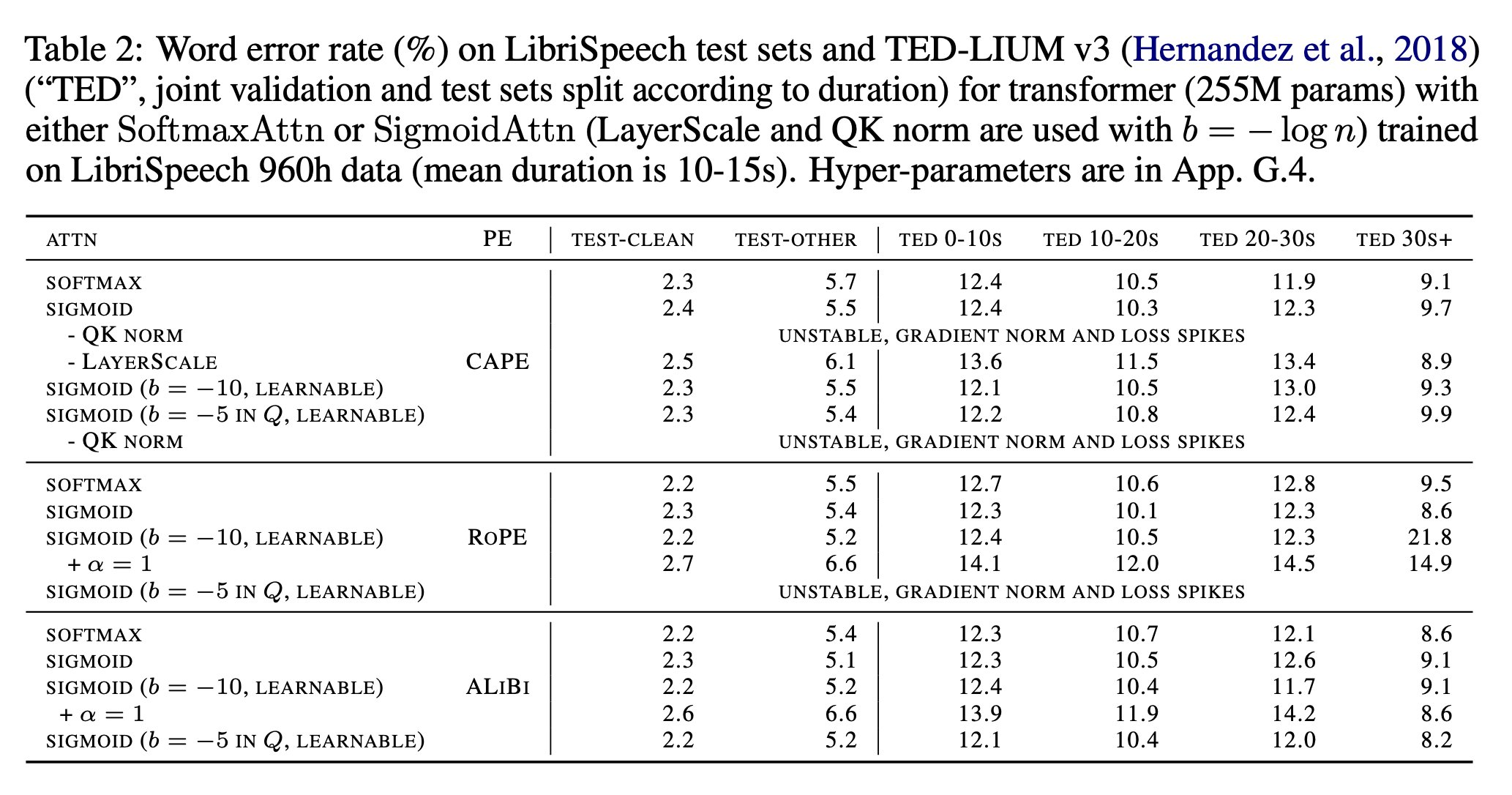
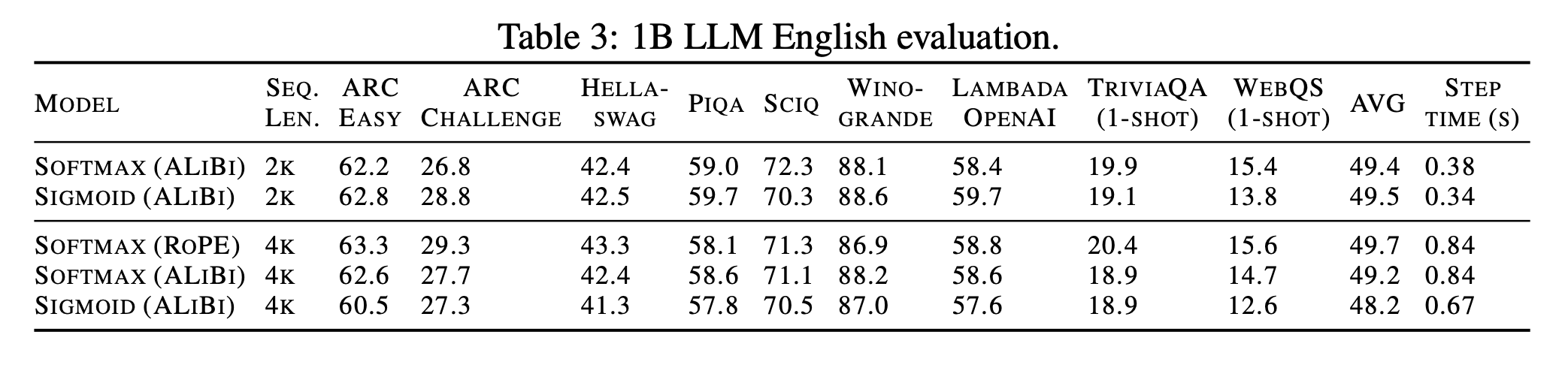
Figure 2Table 2 - 다만 language modeling에서 1B 모델이 seq length 2048일땐 성능이 유효하다가 4096으로 늘리면 격차 발생됐다고(향후 연구 필요하다고 주장)
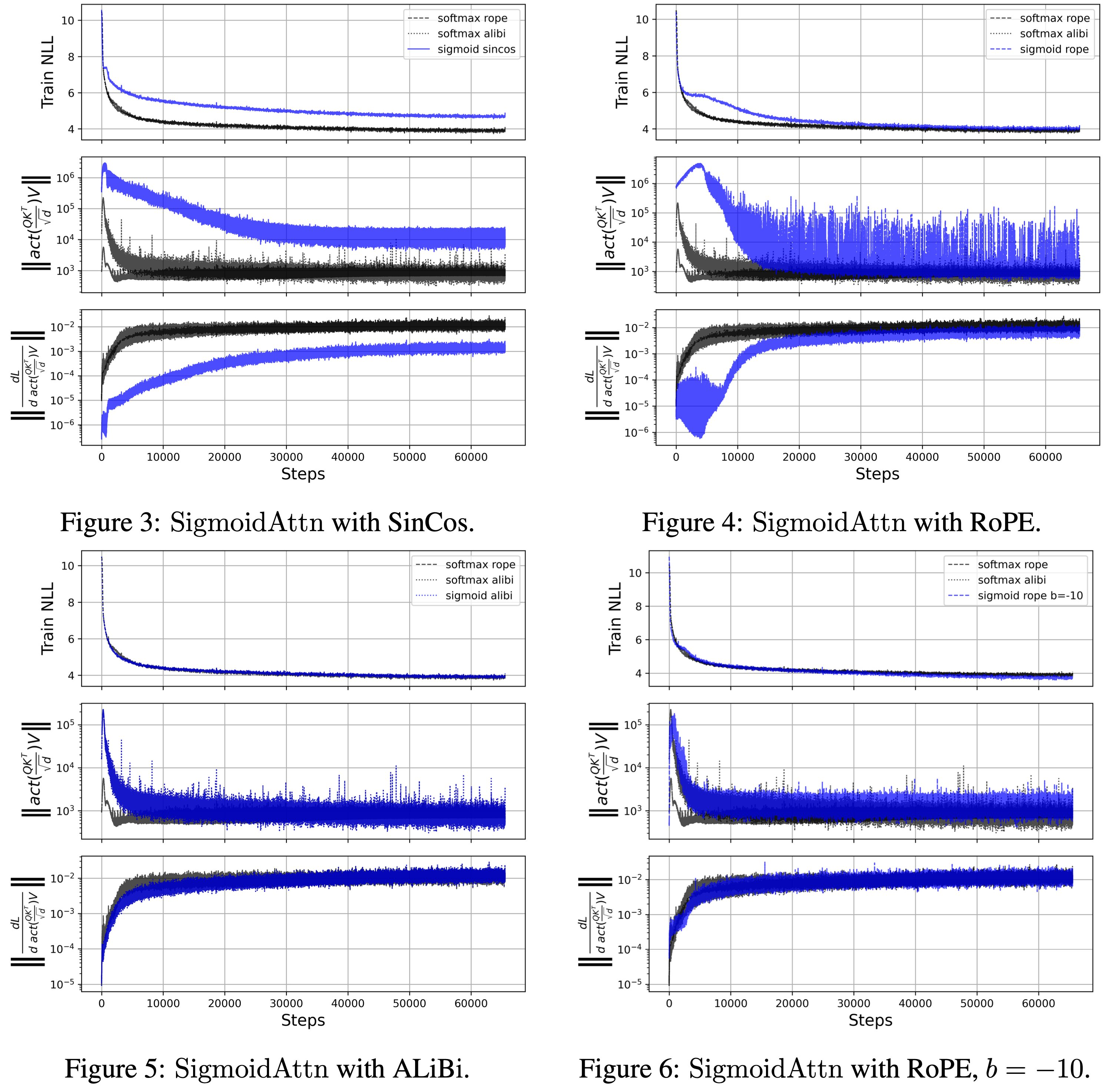
Table 3 - ablation: 초기에 Frobenius norm이 큰 게 softmax 대비 성능 하락을 야기시킬 수 있는 문제가 되는 것으로 보여, sigmoid(x - b)의 bias term b를 ln(seq_len)으로 했더니 해결
Figure 3~6
- 저자들이 테스트한 갖은 종류와 task에서 모두 동등한 수준의 성능 확인: supervised image classification using vision transformers / self-supervised image representation learning with SimCLR, BYOL, Masked AutoEncoder / automatic speech recognition(ASR) / language modeling