Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement
Meta info.
- Authors: Simon Yu, Liangyu Chen, Sara Ahmadian, Marzieh Fadaee
- Paper: https://arxiv.org/pdf/2409.11378
- Affiliation: Google Research, Noirtheastern Univ., Stanford Univ., cohere
- Published: September 17, 2024
TL; DR
instance level로 괜찮은 데이터만 골라 학습하기보다, k-means clustering 활용한 Diversity-Centric Data Selection이 LLM finetuning의 효율성과 성능 향상에 유의하다.
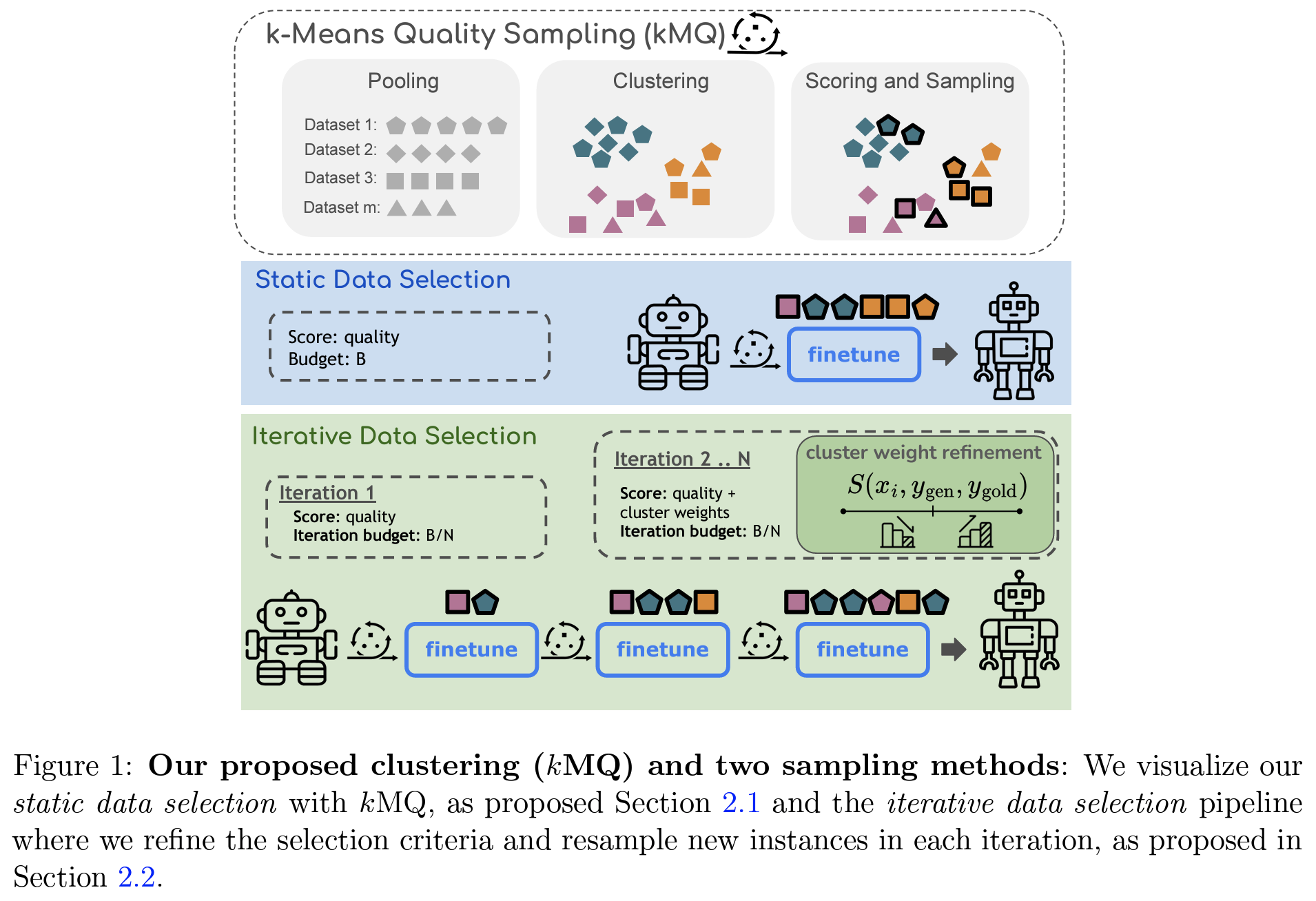


Problem States
LLM finetuning에 어떤 데이터셋(의 subset)이 최적인지에 따라 Finetuning의 효과가 갈리지 않을까?
- 기존 연구는 instance level을 검토했지만, 이는 set level에서의 diversity를 해칠 수 있음.
Suggestions
k-Means Clustering을 활용한 데이터 선택법 <- iterative refinement적용
- k-Means Quality(kMQ) : k-Means clustering 기반으로 각 클러스터에 할당된 budget 내에서 quality 점수에 따라서 가중 확률 기반 sampling
- iterative refinement(data selection) (
algorithm 1): epoch마다 cluster의 중요도와 샘플링 가중치 재조정하여 고품질 데이터 샘플링- 모델이 잘 학습하는 클러스터의 가중치를 높이고, 일반화하기 어려운 클러스터의 가중치를 줄임 (
pic3)
- 모델이 잘 학습하는 클러스터의 가중치를 높이고, 일반화하기 어려운 클러스터의 가중치를 줄임 (
Effects
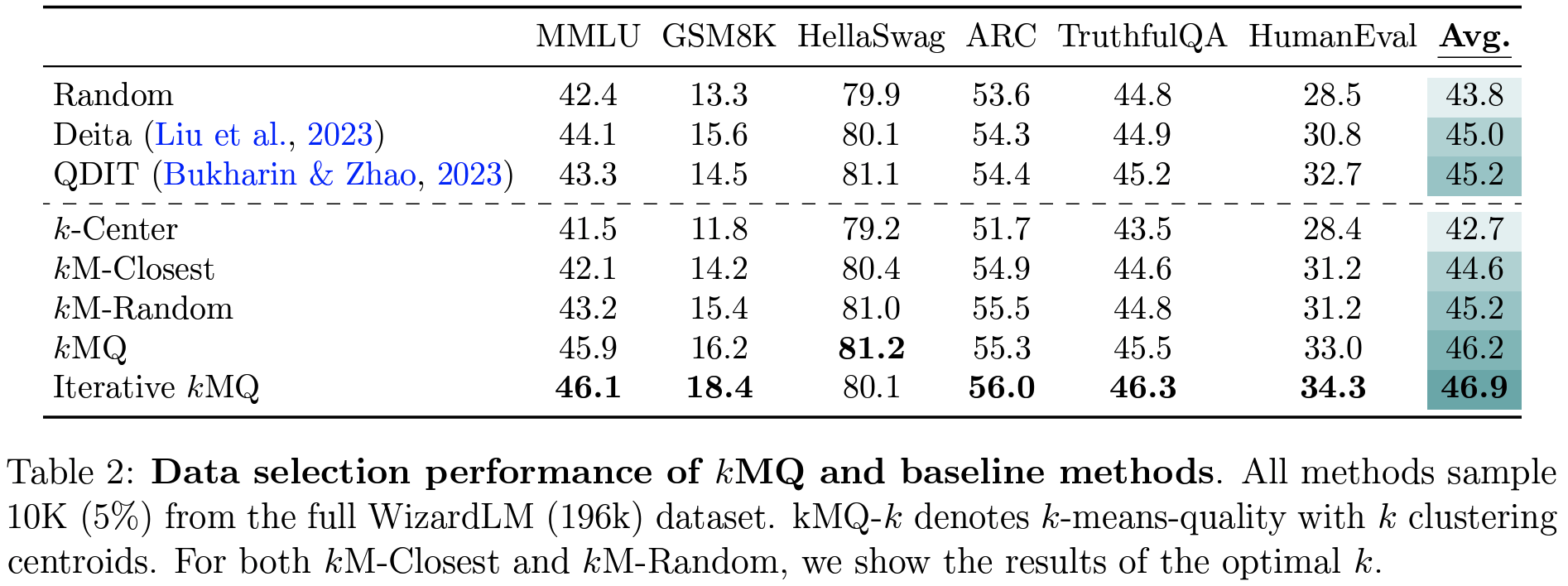
- 다양한 task(NL reasoning
HellaSwag, world knowledgeMMLU, code gen.Humman Eval, math reasoningGSM8K) 에서 일관된 성능 향상- Random samling dataset보다 최대 7%, 기존 SOTA보다 3.8% 향상
- optimal k 선택에 silhouette score 적용
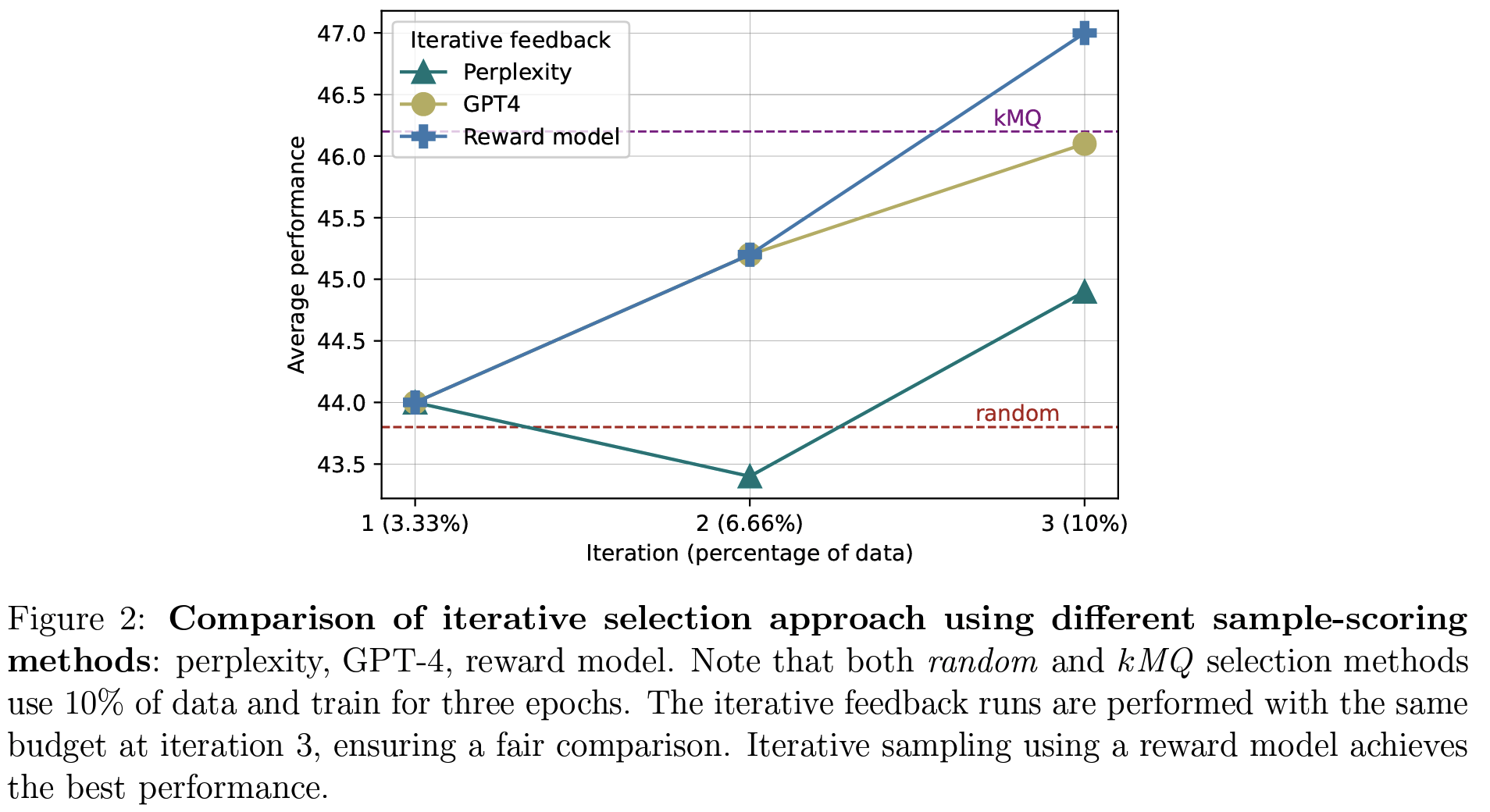
- early training에서의 refinement가 유용하다고. : 모델이 (학습되고 있는) 현재 상태에서 가장 필요로 하는 데이터를 제공한다는 의미 → 학습 효율성 증대 및 성능 향상에 기여
- 3-epoch에서 (kMQ와 동등한 수준) GPT4 score 낸것만큼의 효과가 있으므로, 효율성 측면에서는 탁월하다고 보여짐.
- 여전히 reward model 만든 것 보다야 못한 수준 (그럼에도 불구하고 베이스라인 대비 효과적이라고 보여짐)
Personal note. 생각보다 너무 별 이야기가 없어서 (revisit k-means clustering for fine-tuning data selection) 김빠지기는 하는데 🤔 결론적으로 기존의 데이터 포인트 걸러내는 방법론들 보다야 단순 k-means clustering 쓰는게 다양성을 포괄하는 셋을 만들 수 있고,그게 단순 포인트별 품질이 높은것만 모은 것보다 효율적이라는 이야기네요.