Selective Attention Improves Transformer
Meta info.
- Authors: Yaniv Leviathan, Matan Kalman, Yossi Matias
- Paper: https://arxiv.org/pdf/2410.02703
- Affiliation: Google Research
- Published: October 3, 2024
TL; DR
attention 연산에서 파라미터 변경 없이, 생성된 token이 다른 token이 더이상 필요 없다고 결정할 수 있도록 처리, 미래 시점에서는 해당 token이 불필요하다고 판단했던 token들에 대한 attention을 줄이는 방법으로 효과적으로 메모리 사용량과 계산 비용을 줄인다.


Suggestion
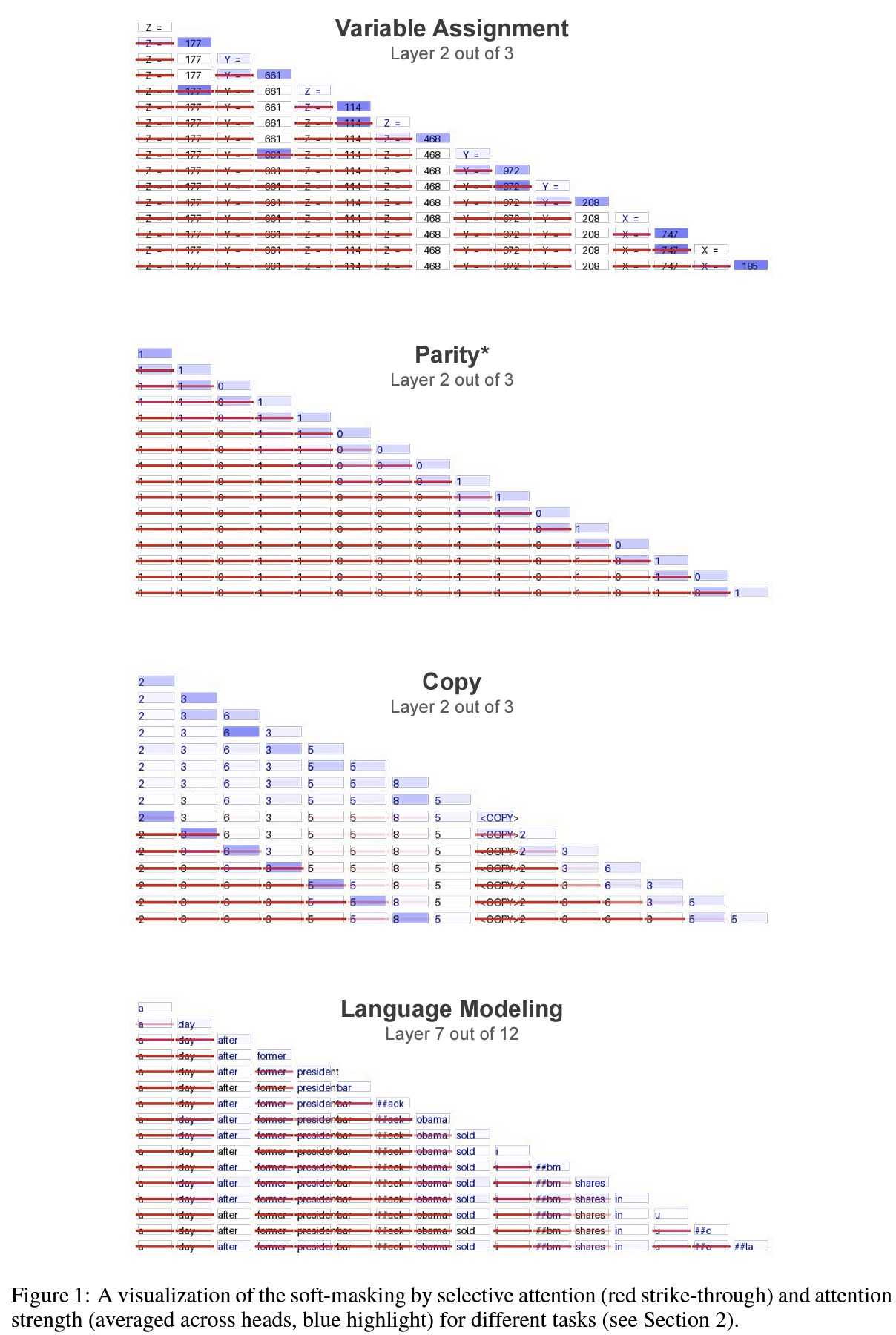
Selective Attention
- Selection Function: text sequence에서 각 token pair에 대한 호환성 점수 계산, NxN soft-masked matrix S 생성
- 호환성 점수: 특정 token x_i가 다른 token x_j를 얼마나 masking해야 하는가?
- 높을수록 x_j를 강하게 masking 해야 한다 = 미래에 x_i attention 연산시 x_j token을 masking 하겠다
- masking: 가릴 정보. text sequence에서 불필요하다고 판단되는 정보 등
- 방법: bilinear form등 다양하게 계산 가능하겠지만, 논문에서는 기존 attention head 중 하나의 출력을 재사용하는 것을 제안 (계산 효율)
- 직관: token이 다른 token의 내용을 attend한 후, 해당 token을 masking하려고 했다는 관찰에서 착안. 즉, 이미 attention 연산이 됐다면 token간 관계 파악을 마친 후이기 때문에 이 정보를 활용해서 masking을 효율적으로 해봤다고.
- 호환성 점수: 특정 token x_i가 다른 token x_j를 얼마나 masking해야 하는가?
- Constraints: S에 대해
- 음수는 0으로 (ReLU) → attend 안 함
- 첫번째 column을 0으로 →
token을 masking 안 함 - 대각선도 0으로 → 스스로를 masking 않도록
- Accumulation: S의 정보를 새 matrix F에 누적 →이전 모든 token의 masking을 고려
- F = Accumulate(Constrain(S))를 softmax 적용 전 attention logit에서 뺌.
- decoder 모델 대상으로 하여 이 selective attention 이 과거 token의 attention 연산에 영향을 끼치지 않기 때문
Effects
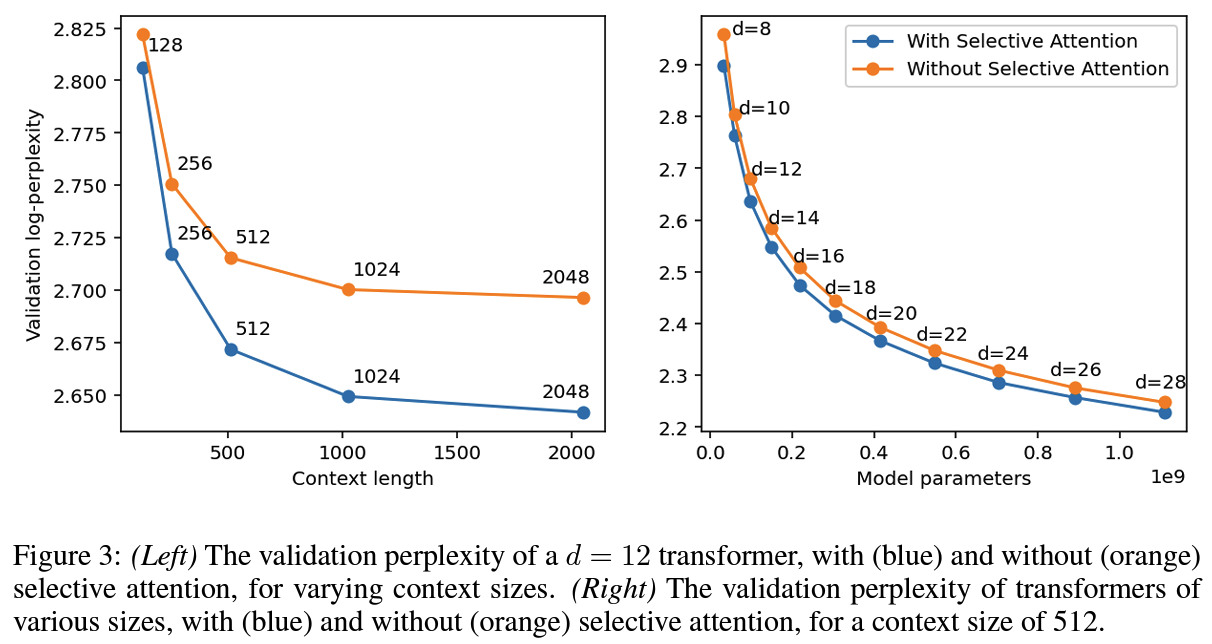
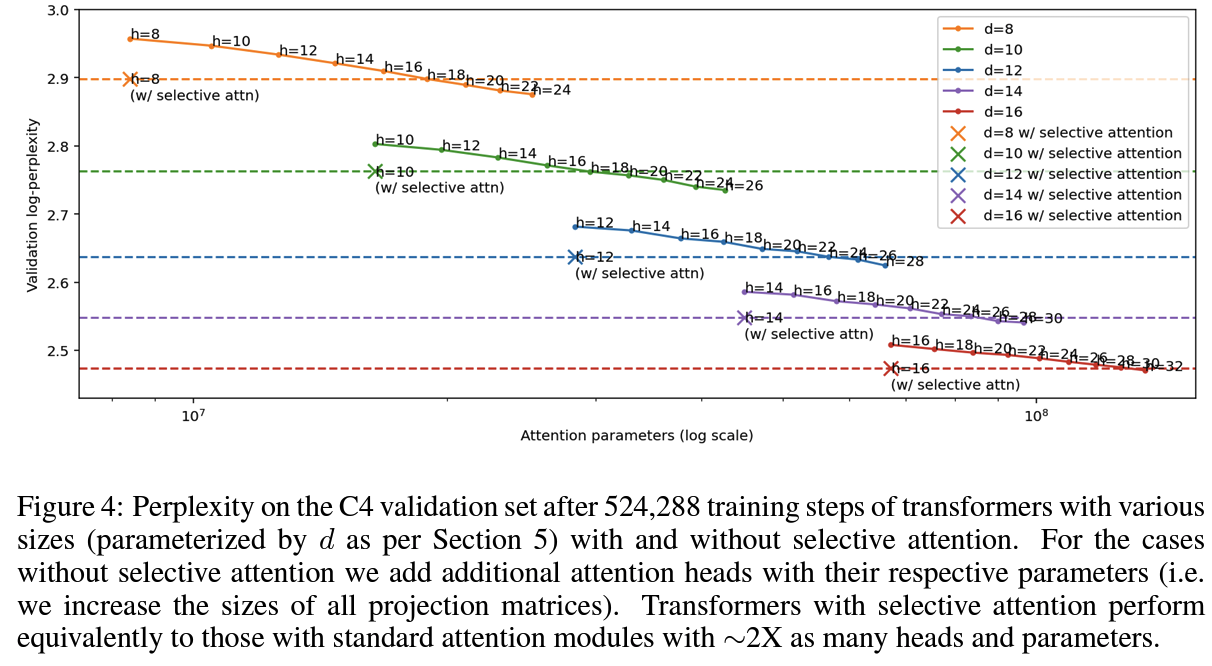
PPL 기준 모델 사이즈 혹은 context length에 관계 없이 더 나은 성능 + 추론 효율 증대
- General Quality: C4 에서 Language Modeling 실험, PPL 측정
- selective attention transformers는 attention에서 약 2배 많은 head와 param가 있는 standard attention transformer와 동일하게 수행가능
- downstream tasks로 HellaSwag에 대해 모든 모델 사이즈에 대한 성능 향상 확인
- Inference Efficiency:
- context length가 512, 1,024, 2,048인 d = 12 transformers에 대해 selective attention 적용시 명시적 성능 손실 없이 attention 모듈의 메모리 요구사항을 각 x5, x7, x8 줄이면서 baseline의 PPL유지
Personal note. 흥미로운데 논문에 언급 된 것처럼 encoder 적용하면 어떻게 될지 궁금하고 inference에서는 이득이지만 딱히 training 효율이 향상되는건 아닌 점도 향후 연구로 주목할만 한 것 같습니다. 다른 task나 finetuning에서 어떻게 될지도 향후 연구 방향이 될 것 같다고..