MoEE: Your Mixture-of-Experts LLM Is Secretly an Embedding Model For Free
Meta info.
- Authors: Ziyue Li, Tianyi Zhou
- Paper: https://arxiv.org/pdf/2410.10814
- Affiliation: University of Maryland
- Published: October 14, 2024
- Code: https://github.com/tianyi-lab/MoE-Embedding
TL; DR
MoE LLM의 router weight를 활용하면 별도 추가 학습 없이 decoder-style LLM에서도 괜찮은 representation (embedding) 뽑을 수 있다.

Problem States
decoder 위주의 최신 LLM으로 (별도 finetuning없이는) embedding까지 잘만들진 못하더라
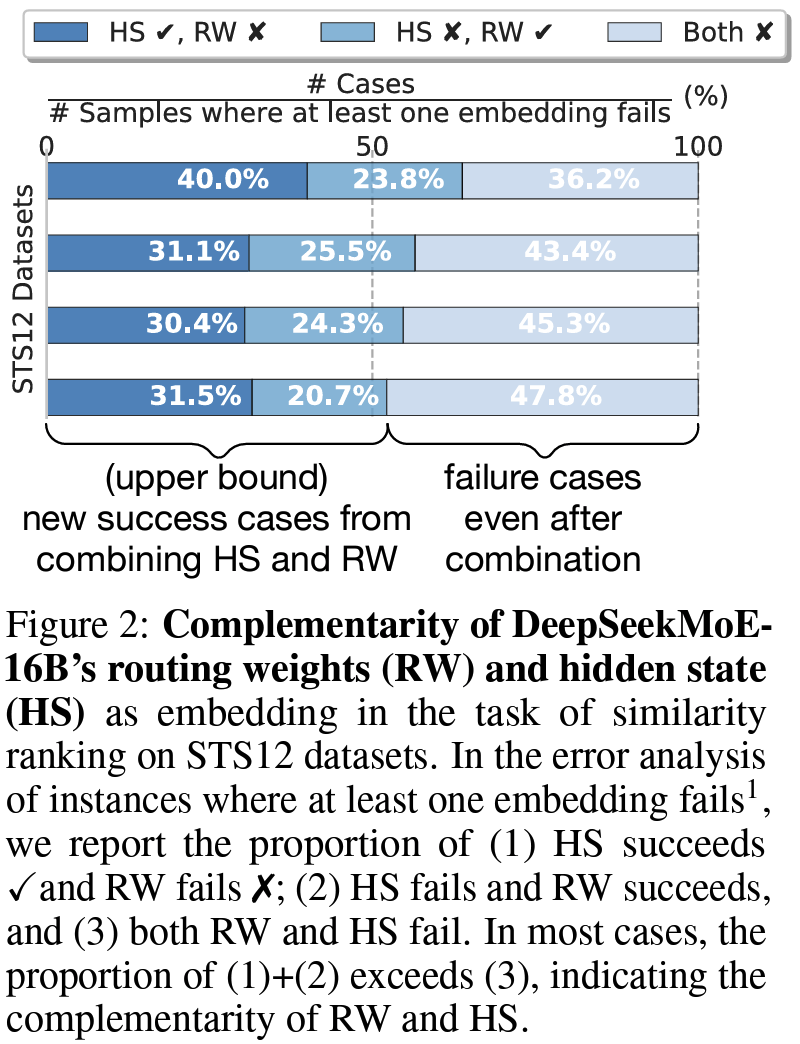
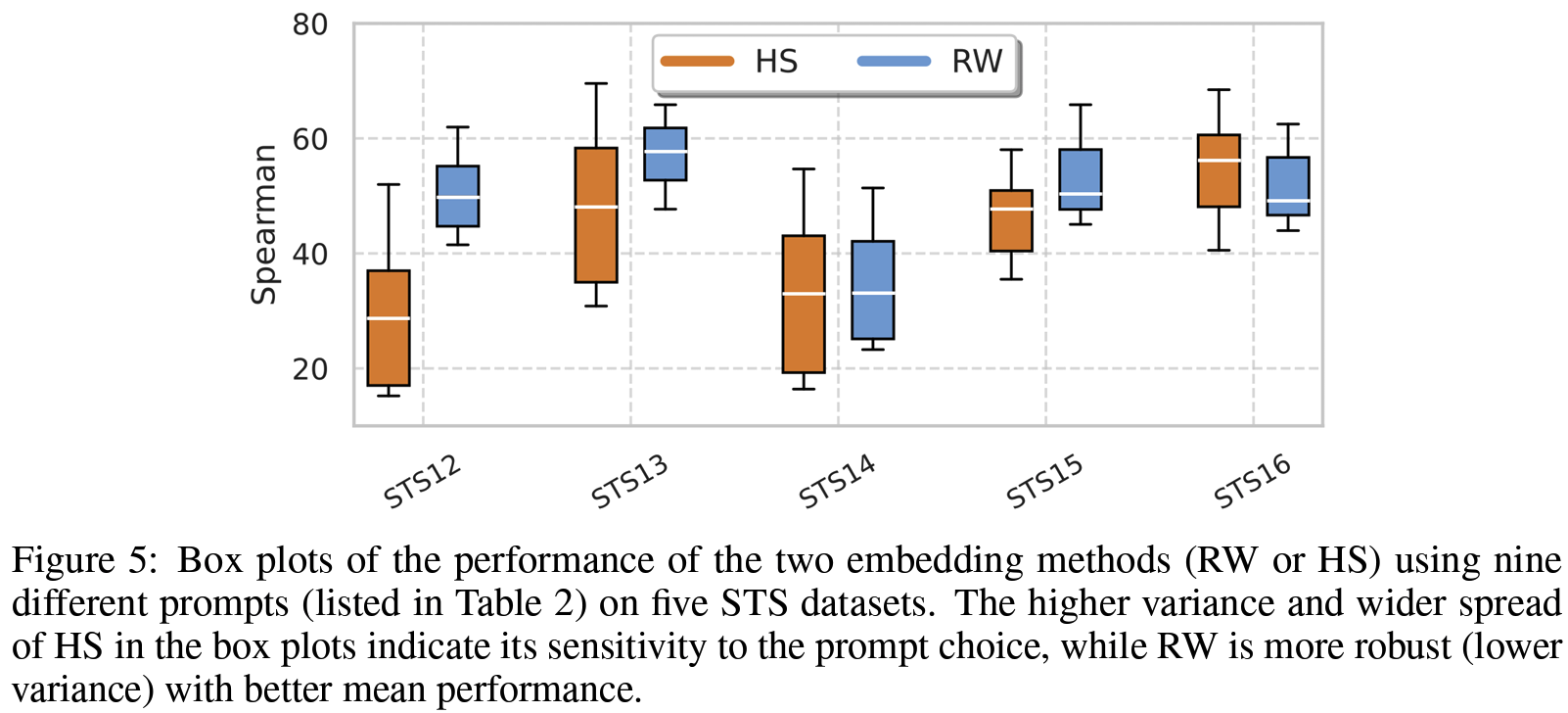
- Research Question: MoE-style LLM의 router weight (RW)를 써보면 어떨까?
- RW가 hidden states(HS)랑 다른 정보를 담고 있지 않을까?
- RW: reasoning 에 역할
- HS: 최종 예측 결과에 집중
- RW가 hidden states(HS)랑 다른 정보를 담고 있지 않을까?
Suggestion
(일반적으로 쓰는) HS 방식에 RW 잘 섞어 써보자
- MoE Routing Weights for Embedding: 모든 Layer의 RW를 concatenation한 embedding을 활용하자.
- Mixture-of-Experts Embedding(MoEE)
- Concatenation-based Combination : MoEE(concat)
- Hidden States Embedding과 MoE RW Embedding concat
- Weighted Sum Integration : MoEE(sum)
- weighted sum ofcos. similarity: STS처럼 2문장 pair에서 HS Embed.간 유사도와 RW Embed.간 유사도 가중합
- Concatenation-based Combination : MoEE(concat)
Effects:
- Experiments
- MoE Backbone Models: 모든 모델들이 token마다 routing 하지만, MoEE에서는 last token의 RW만 사용 (경험적 선택)
DeepSeekMoE-16B(Daietal., 2024): 28 layers, with 64 experts per layerQwen1.5-MoE-A2.7B(Team, 2024): 24 layers, each containing 60 expertsOLMoE-1B-7B(Muennighoffetal., 2024a): 16 layers, with 64 experts per layer
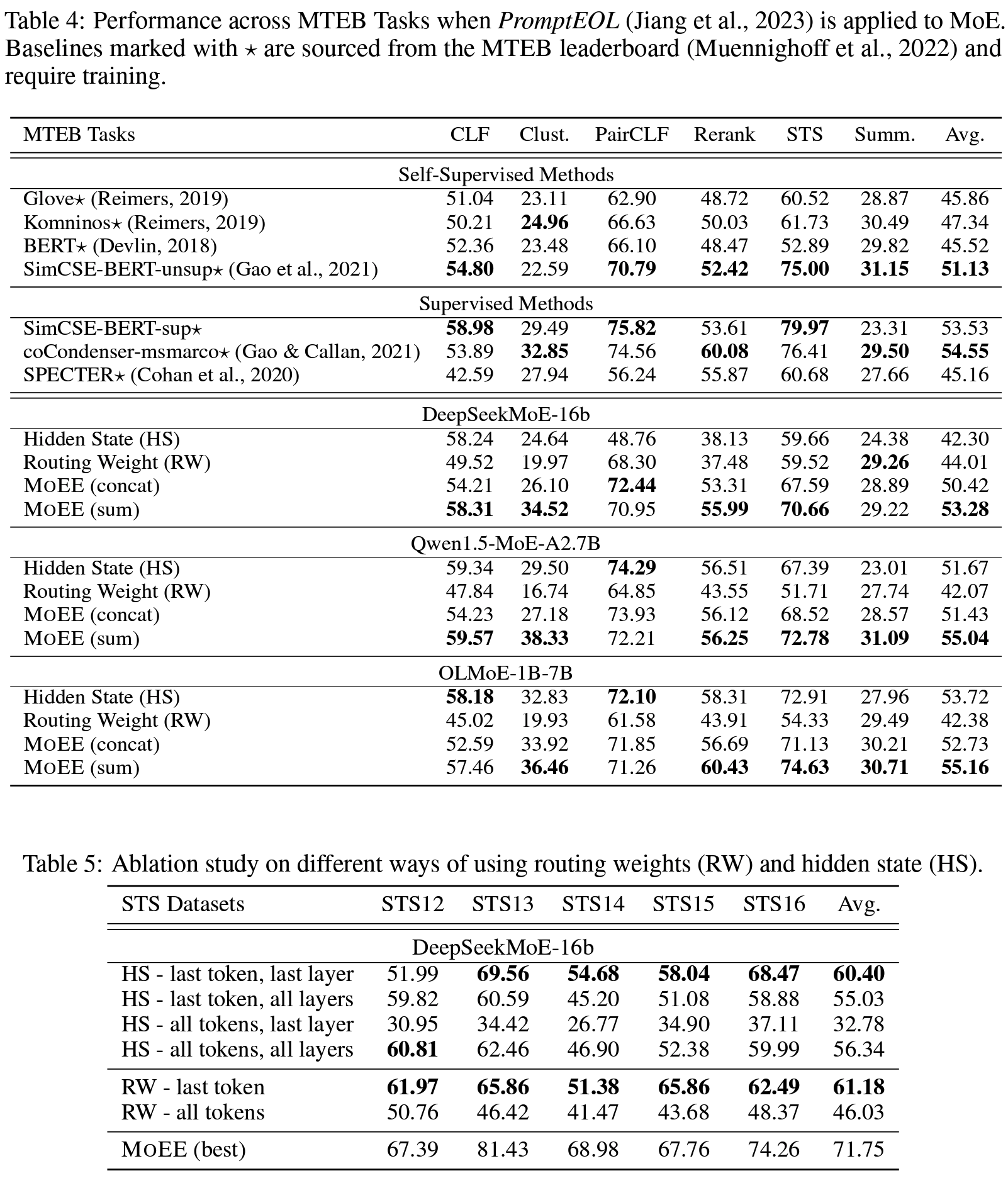
- Baseline: HS-only, RW-only, 기존 further training 된 decoder-style SOTA모델
- PromptEOL 쓰거나 안 쓴 경우까지 포함
- MoE Backbone Models: 모든 모델들이 token마다 routing 하지만, MoEE에서는 last token의 RW만 사용 (경험적 선택)
- Results:
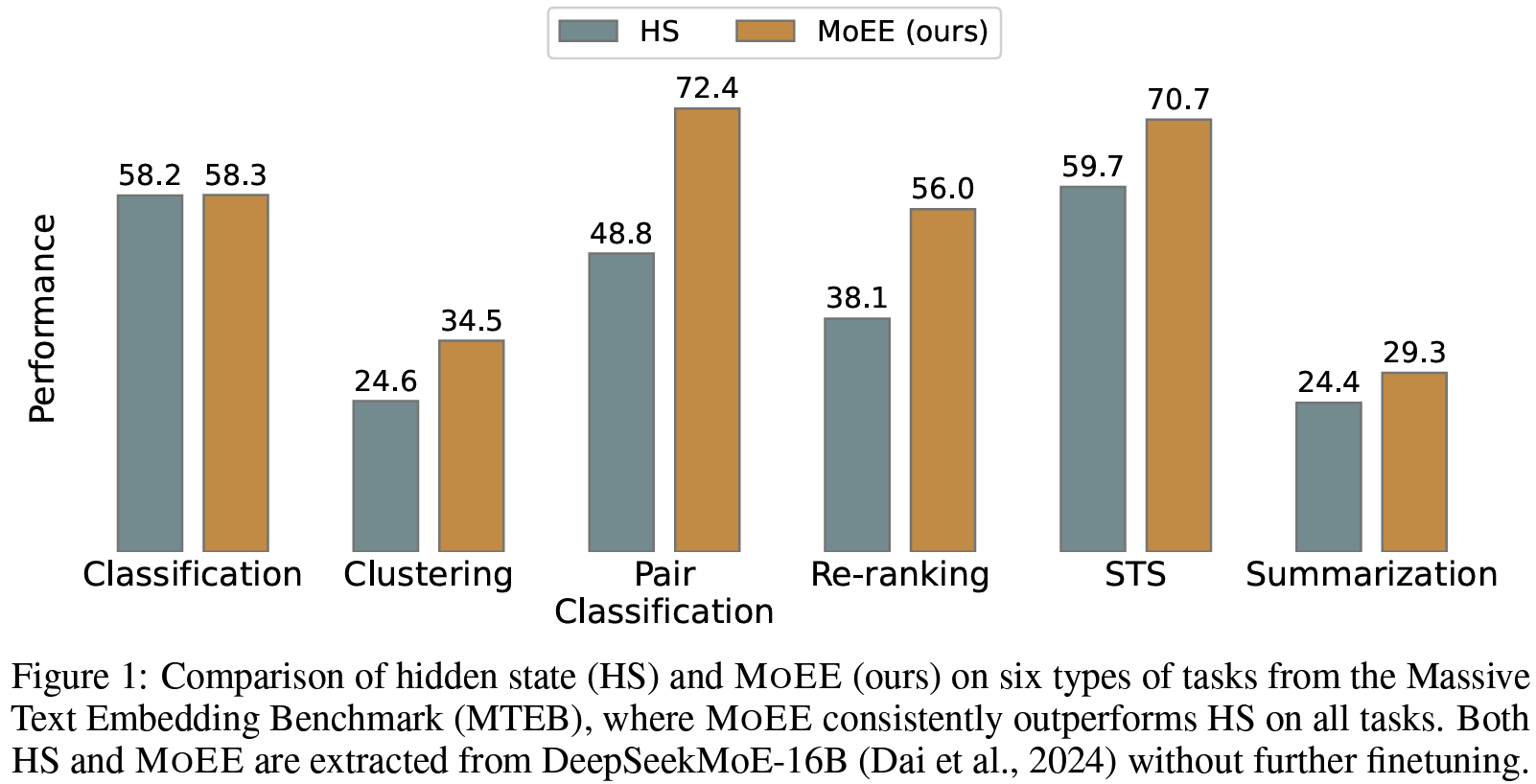
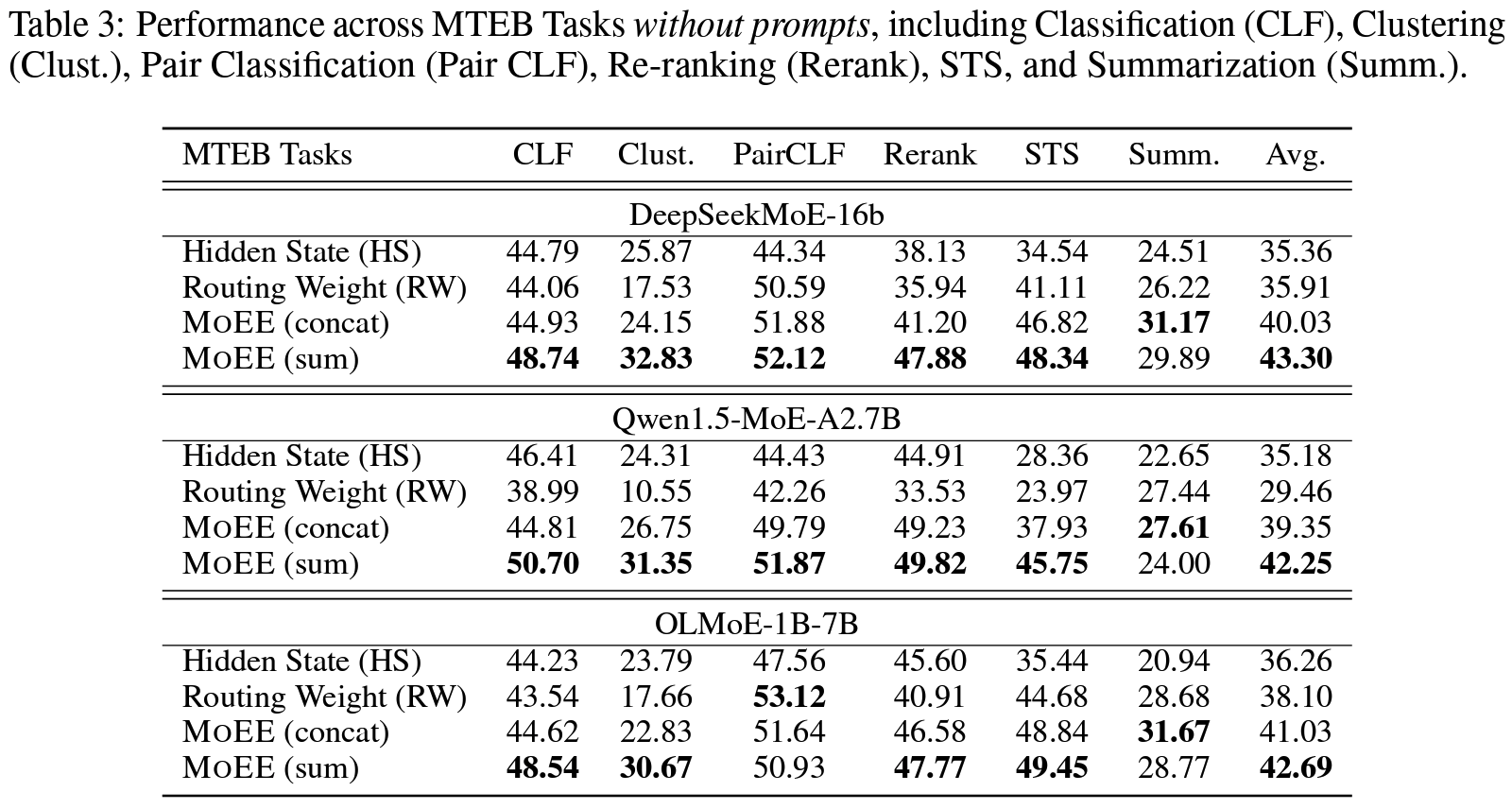
Table 3- STS: HS-only, RW-only 대비 우수
DeepSeekMoE-16BPromptEOL 안 쓴 MOEE(sum): STS12 46.41, STSBenchmark 44.36 (HS-only보다 25.51, 13.75)Qwen1.5-MoE-A2.7BPromptEOL 쓴 MOEE(sum): 65.54, 75.57 (상동 task, HS-only대비 9.49, 8.15)OLMoE-1B-7BPromptEOL 쓴 MOEE(sum): 68.84, 75.58 (상동 task, HS-only대비 3.33, 4.07)
- Classification: sentiment extraction, emotion classification, toxic conversations classification
- MoEE가 -only 들보다야 향상되었지만, HS-only와 차이는 다른 task만큼 극적이진 않음.
- 아마 HS가 최종 분류 예측에 더 적합하기 때문으로 추측
- MoEE가 -only 들보다야 향상되었지만, HS-only와 차이는 다른 task만큼 극적이진 않음.
- Pair Classification: TwitterURLCorpus, TwitterSemEval2015
- PromptEOL 쓸 때 MoEE가 모두에서 -only 대비 상당히 성능 향상
- Clustering: 20 News groups Clustering, Medrxiv ClusteringS2S
- PromptEOL 안 쓴 MoEE(sum)이 최고 성능
- PromptEOL 쓴 MoEE 역시 모든 모델에서 큰 성능 향상
- Reranking: AskUbuntu, SciDocsRR, StackOverflow
- PromptEOL 쓸 때 MoEE가 모두에서 -only 대비 상당히 성능 향상
- STS: HS-only, RW-only 대비 우수
Personal note. 결과적으로 PromptEOL 의존도가 좀 높은거 같긴 한데, 쓴 게 좋고 나쁜 경우가 살짝 혼재돼있긴 하지만 (모델이 학습 어떻게 됐느냐에 따라 다를듯) 제안한 HS+RW 방식은 유효해 보입니다. SimCSE 같은 모델 결과를 가져오긴 했지만 (Tab 4) 딱 비교되진 않아서 이게 기존 bi-directional 한 접근 대비 최선이다! 는 아닐 것 같습니다. 그래도 살펴볼만한 괜찮은 초기 연구일듯 합니다 🙂