Inference Scaling for Long-Context Retrieval Augmented Generation
Meta info.
- Authors: Zhenrui Yue, Honglei Zhuang, Aijun Bai, Kai Hui, Rolf Jagerman, Hansi Zeng, Zhen Qin, Dong Wang, Xuanhui Wang, Michael Bendersky
- Paper: https://arxiv.org/pdf/2410.04343
- Affiliation: Google DeepMind
- Published: October 6, 2024
TL; DR
LM의 RAG inference 성능 향상을 위한 scaling 전략을 제안하고, 유효 컨텍스트 길이의 규모와 RAG 성능 간에 선형적인 관계가 있음을 확인

Background
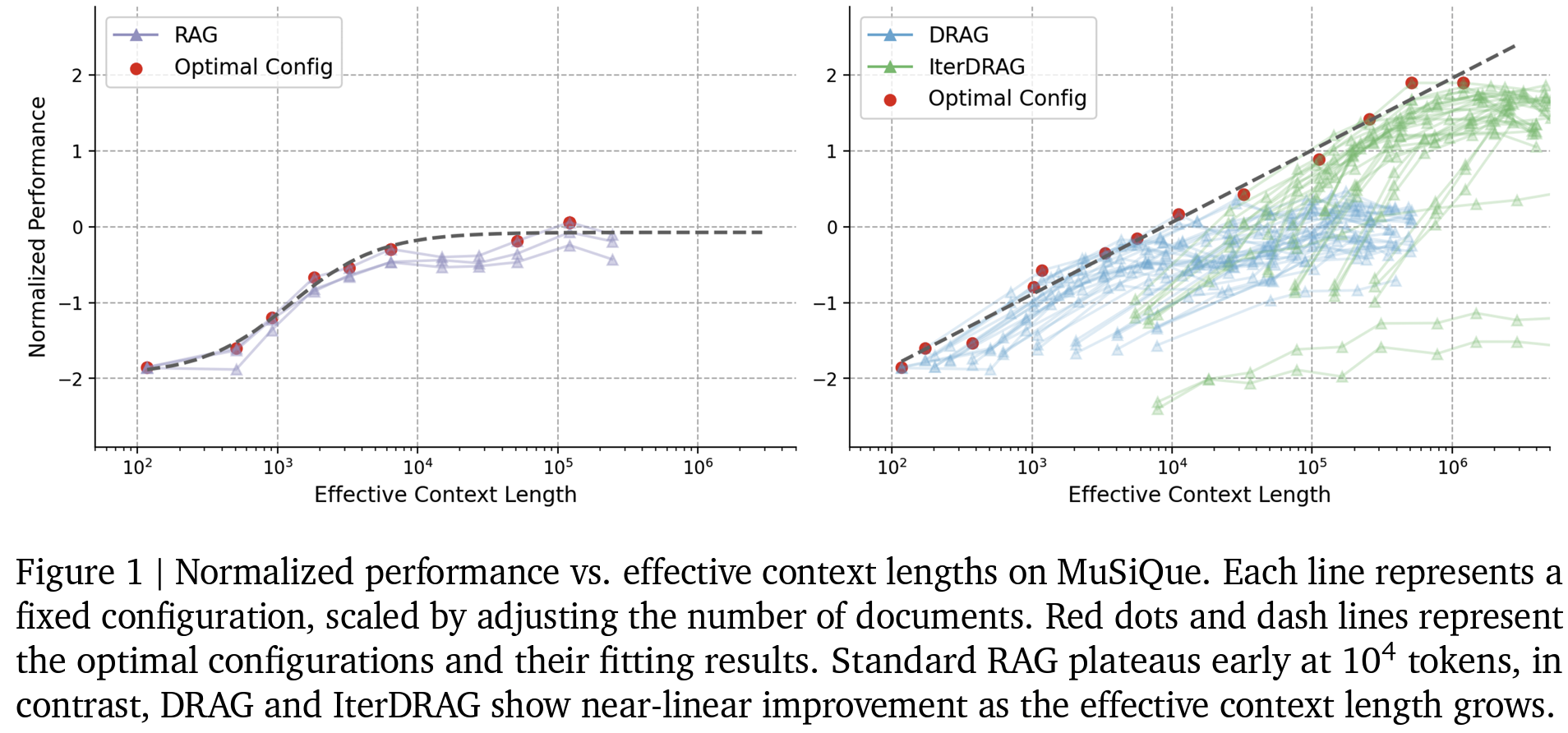
모델이 받아들일 수 있는 길이가 길다고 좋은 성능을 보장하지는 않는다.
- LC-LLM이더라도 여전히 그 긴 context를 충분히 활용하지 못하고 있음.
- retrieved context개수가 일정 수준 이상이면 성능 향상되지 못하고 심지어는 저하되는 문제 보고
Problem States
LC-LLM이 RAG system에서 컨텍스트 정보를 효과적으로 획득하고(추가하고) 활용하는 scaling 방법이 있는가?
- 단순히 input 길이 확장하는 것 이상으로 RAG 추론을 위해 필요한 전략 탐구의 필요성
- Research Question
- 최적 구성시, inference computation의 scaling은 RAG 성능에 어떤 이점이 있는가?
- RAG 성능과 inference parameters간의 관계를 모델링하여, 주어진 예산에 대한 최적의 테스트 시간 compute allocation을 예측할 수 있을까?
- inference parameters: 검색 문서 개수(k), context에 demonstration 수(m), 생성 반복횟수(n) 등
Suggestions
- Inference Scaling Strategies for RAG
- DRAG(Demonstration-Based RAG): RAG demonstration을 충분히 제공하여 ICL style로 배울 수 있도록 설계
- IterDRAG(Iterative Demonstration-Based RAG): 질문을 하위질문으로 분해→검색→ 생성을 반복하는 multi-hop query의 inference chain 설계
- Inference scaling laws: RAG Performance와 Inference Computation Scale 사이 상관관계 정량화
- 유효 context 길이(effective input context length to the LLM)의 중요성
- LLM이 최종 답변을 출력하기 전까지 모든 반복 과정에 걸쳐 입력된 토큰의 총 수
- 길이 확장의 이점과 계산 비용 증가 사이 trade-off: 주어진 계산 예산 내에서 컨텍스트 정보를 얼마나 효율적으로 활용할 수 있는지 포착
- vanilla RAG는 1회 호출이 기본: 유효 context 길이 = prompt 길이 (최대 LLM input length)
- 제안 방식 등 iterative하게 호출하는 경우: 유효 context 길이 (무한히) 확장 가능
- Computation allocation model: constraints 하에서 RAG에 대한 최적의 inference parameters 예측 (5.1절)
- inference parameters 조합에 따라 RAG 성능 및 scaling inference computation scale 확인 → 최적 할당 가능
- 유효 context 길이(effective input context length to the LLM)의 중요성
Effects
- Experimental setup:
- datasets: multi-hop, knowledge intensive QA 및 single-hop QA등..
- Bamboogle, HotpotQA, MuSiQue, 2WikiMultiHopQA
- backbone: Gemini 1.5 Flash
- zs-QA, ms-QA, vanilla RAG, DRAG, IterDRAG 비교
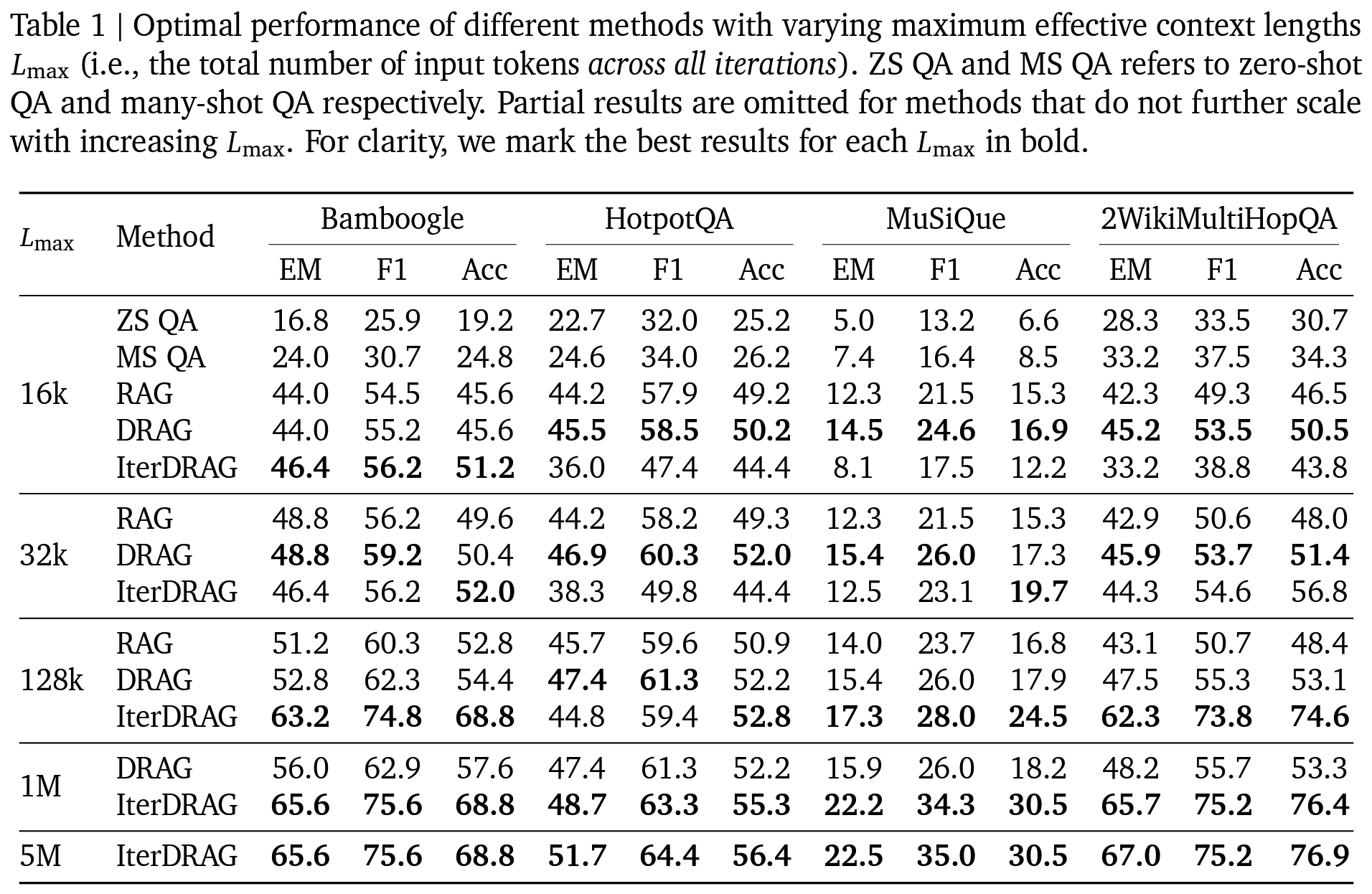
- 유효 context length: 16k, 32k, 128k, 1M, 5M 등
- datasets: multi-hop, knowledge intensive QA 및 single-hop QA등..
- Results
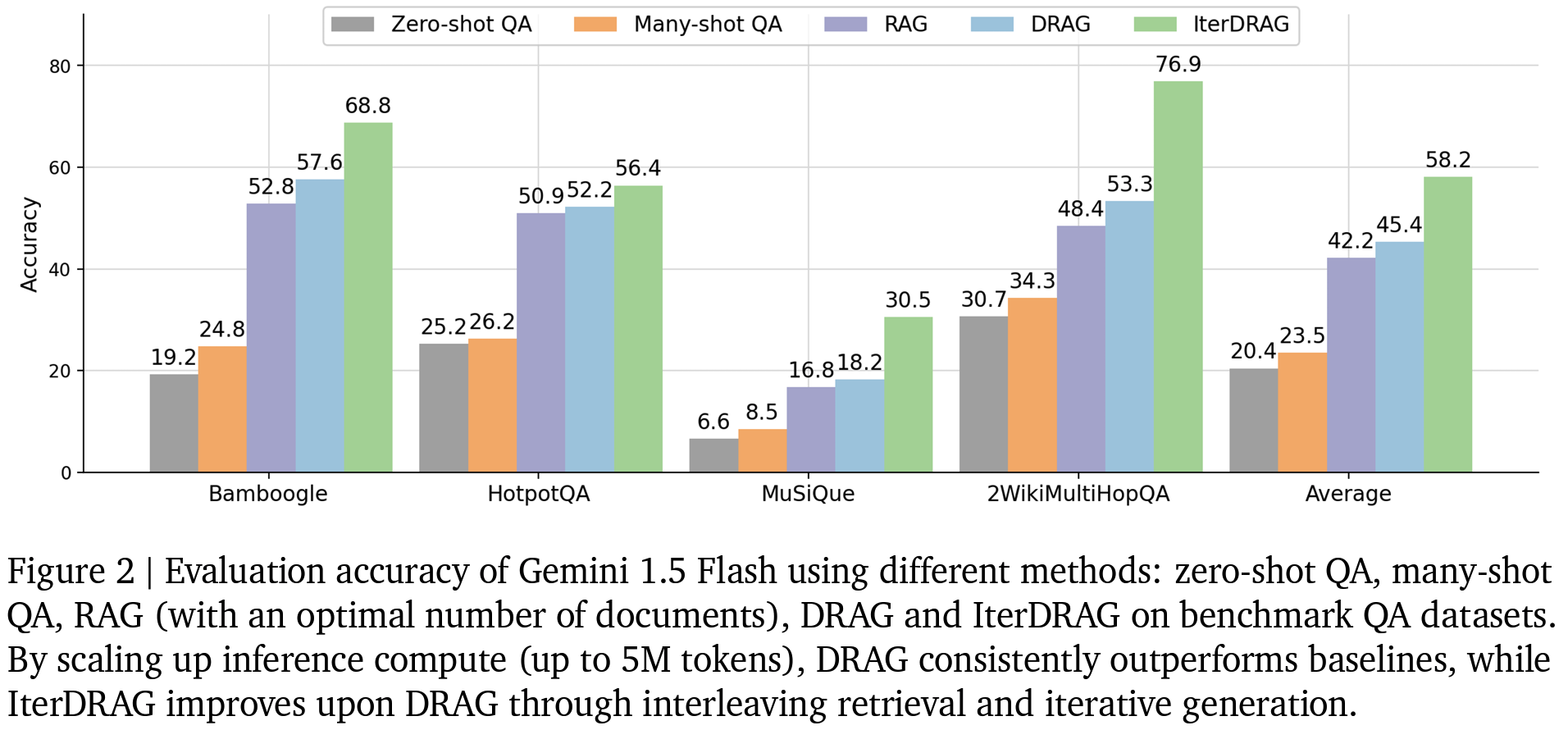
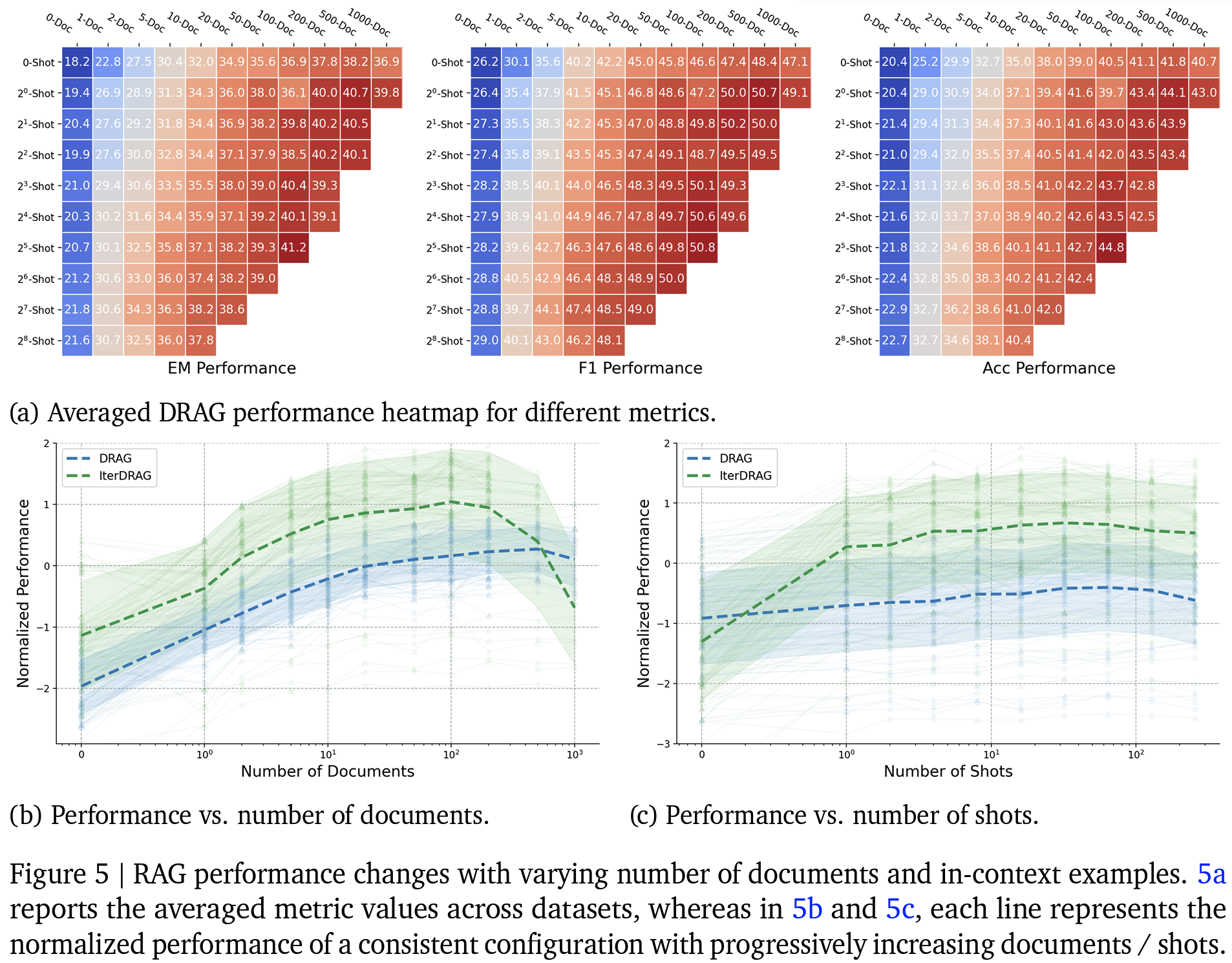
- DRAG, IterDRAG 두 제안 방식이 SOTA
- vanilla RAG 대비 DRAG, IterDRAG 전략이 QA 벤치마크에서 최대 58.9% 성능 향상
- IterDRAG의 경우 CoT대비 일관적으로 우수한 성능 확인 가능
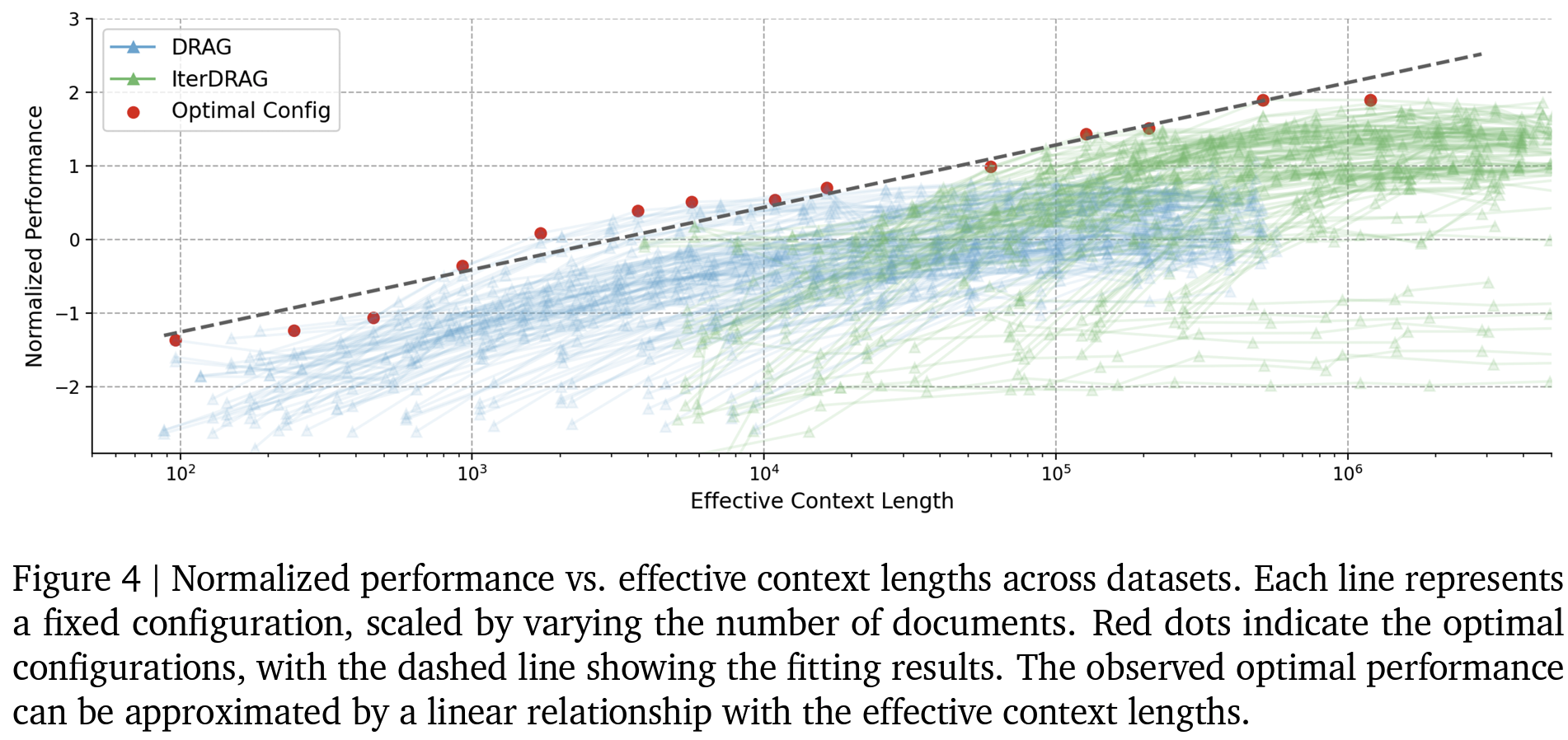
- Computation allocation model은 unseen domain으로 일반화할 때 96.6%의 최적 성능
- 단순 문서 길이 늘리는 것보다 최적 할당 시 추론 연산이 증가함에 따라 (= 제안하는 computation allocation model로 계산한 유효 context 길이가 증가함에 따라) RAG 성능이 거의 선형적으로 확장
- 1M 토큰을 초과하면 성능 이득이 감소 → LC-LLM의 한계인듯..
- 검색이 잘못되거나 추론 과정이 불완전한 경우 오류 발생
- DRAG, IterDRAG 두 제안 방식이 SOTA