Direct Multi-Turn Preference Optimization for Language Agents
Meta info.
- Authors: Wentao Shi, Mengqi Yuan, Junkang Wu, Qifan Wang, Fuli Feng
- Paper: https://arxiv.org/pdf/2406.14868
- Affiliation: Meta AI, USTC
- Published: June 21, 2024
TL; DR
Multi-turn 에서 RL Objectives를 직접 optimize하는 손실함수의 Direct Multi-Turn Preference Optimization (DMPO) 제안





Problem States
ETO에서 DPO loss는 Single-turn 단위 선호에 대한 강화학습이므로, multi-turn agent task (trajectory가 있는 경우)에는 적합하지 않다.
- ETO :실패 trajectory 모아서 contrastive하게 학습하는 방식으로 optimize하게 하는, ReAct 방식으로 trajectory 작성
- Research Question: multi-turn agent task를 위한 optimization 개발
Suggestions
DMPO
- multi-turn 에서의 최적화를 위해 (1) BT 모델의 partition function Z(probability 정규화)가 현재 상태 s로부터 독립이 되어야 함 + (2) 선호/비선호 trajectories 간 길이 격차의 영향 중화로 편향 줄여야 함
- state-action occupancy (SAOM) 적용: RL Objectives(
Eq 1)에서 Policy Constraints(Eq 3)을 SAOM constraints(Eq 10)로 대체하여 compounding error 완화- problem:
Eq 3에서 Z(s)는 현재 상태 s에 종속된 상태로 정규화→ 단일 턴에서만 유효한 접근 - solution:
Eq 10에서 SAOM constraints(d^{π∗}(s, a))로 Z는 s에서 독립적으로 계산 가능 →Eq 11
- problem:
- BT 모델에 길이 정규화 도입: 선호 trajectories와 비선호 trajectories간 길이 불일치 완화 → 편향 문제 해결
Eq 2을 multi-turn으로 확장하면Eq 12- problem: 선호 trajectory 길이 T^w와 비선호 trajectory 길이 T^l이 불일치 (길이가 길수록 reward 합이 커지는 편향 발생 > 격차 확대 > 모델 성능 저하 )
- solution:
Eq 13처럼 정규화 (T^w(선호trajectory 길이)가 더 긴 경우, T^w에 붙은 정규화 term이 T^l에 붙은 term 대비 작은 값이 되는 식으로 보정)
- state-action occupancy (SAOM) 적용: RL Objectives(
- 최종
Eq 16를 maximize:Eq 13에는 Z의 partition function이Eq 11의 reward function으로 대체되면서 없어짐.- discount function ϕ(t, T): 다양한 단계에서 s-a pair의 가중치 재조정(초기 단계의 s-a pair에 더 높은 가중치)
Effects
- Experimental Setup:
- datasets: WebShop, ScienceWorld, ALFWorld (MDP로 설명가능)
- backbone: Llama-2-7B-Chat, Llama-2-7B-Chat
- Results:
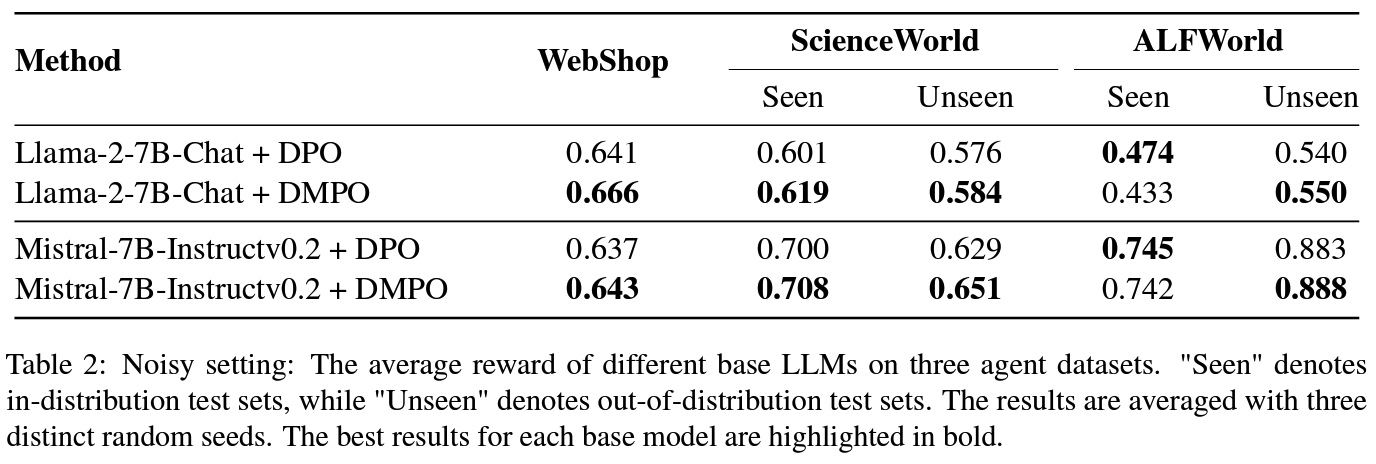
- (RQ1) noisy setting: DMPO의 강건성 + 효율성 확인 »
Table 2DPO 성능 상회- noisy trajectory를 비선호 trajectory로 대체 실험: 초기에 gold preference에 가중치를 높여서 우선시하고 나중 단계에서 발생되는 노이즈 있는 경우에 대한 가중치 낮추는 등 노이즈의 영향을 완화하고 모델에 향상된 일반화 성능 확인
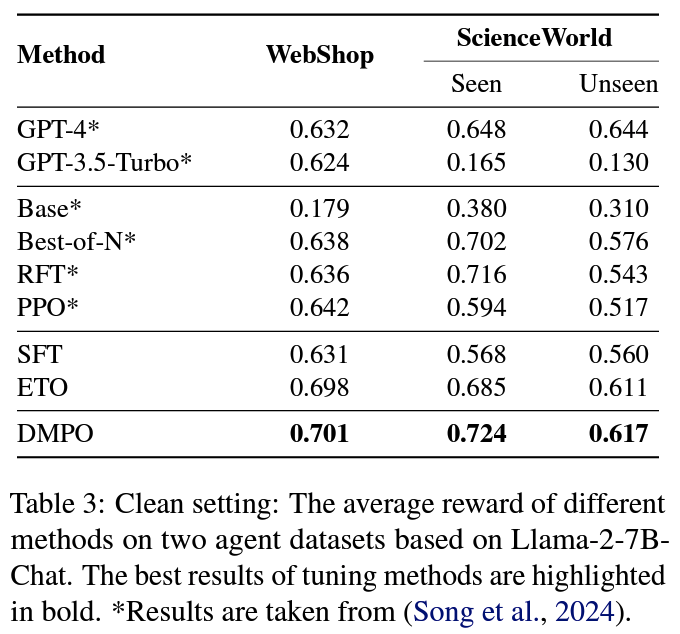
- (RQ2) clean setting: DMPO의 우수성 확인
- baseline preference tuning 방식 대비 우수한 성능 확인
- (RQ1) noisy setting: DMPO의 강건성 + 효율성 확인 »
Personal note. ETO paper 내용을 전면으로 받아들이면서 시작하고 있어서 확인 필요해보임. target benchmark들이 ReAct 기반으로 접근하는 것으로 보이는데, 실제 multi-turn setting 과 얼마나 align되는지가 향후 연구방향 잡는데 주요한듯