Reverse Thinking Makes LLMs Stronger Reasoners
Meta info.
- Authors: Justin Chih-Yao Chen, Zifeng Wang, Hamid Palangi, Rujun Han, Sayna Ebrahimi, Long Le, Vincent Perot, Swaroop Mishra, Mohit Bansal, Chen-Yu Lee, Tomas Pfister
- Paper: https://arxiv.org/pdf/2411.19865
- Affiliation: Google Cloud AI Research, Google DeepMind, UNCChapel Hill
- Published: November 29, 2024
TL; DR
LLM이 '역발상'을 학습하도록 훈련하면 상식, 수학, 논리적 추론같은 task 성능 향상에 큰 도움. x10만큼의 forward training(standard finetuning)보다 성능이 뛰어나다고 주장.
Suggestion
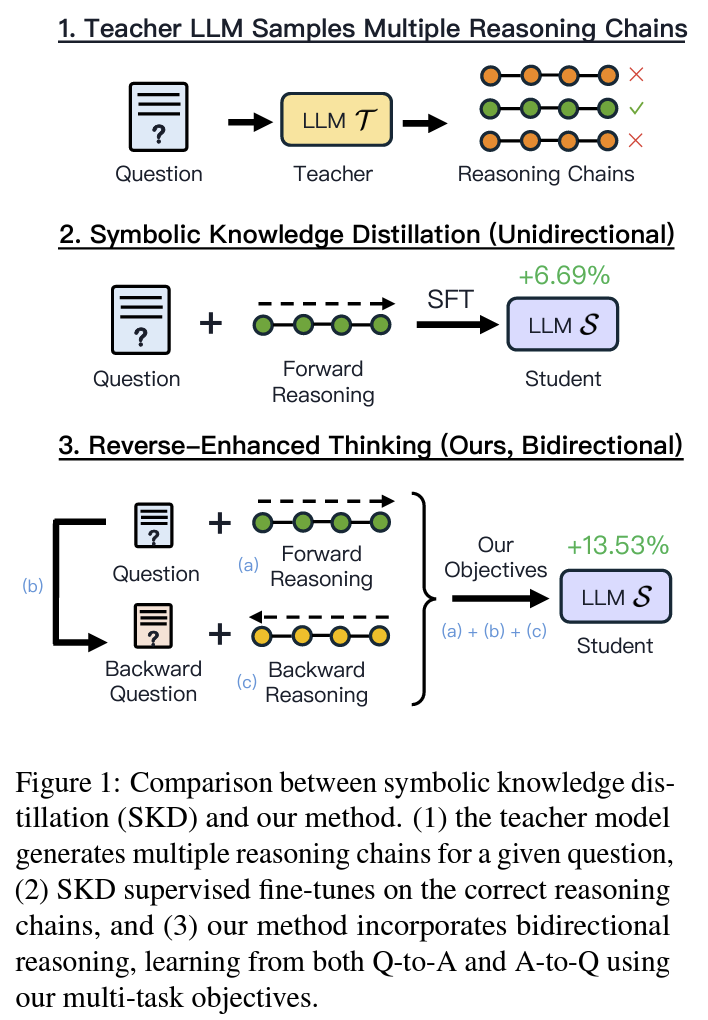
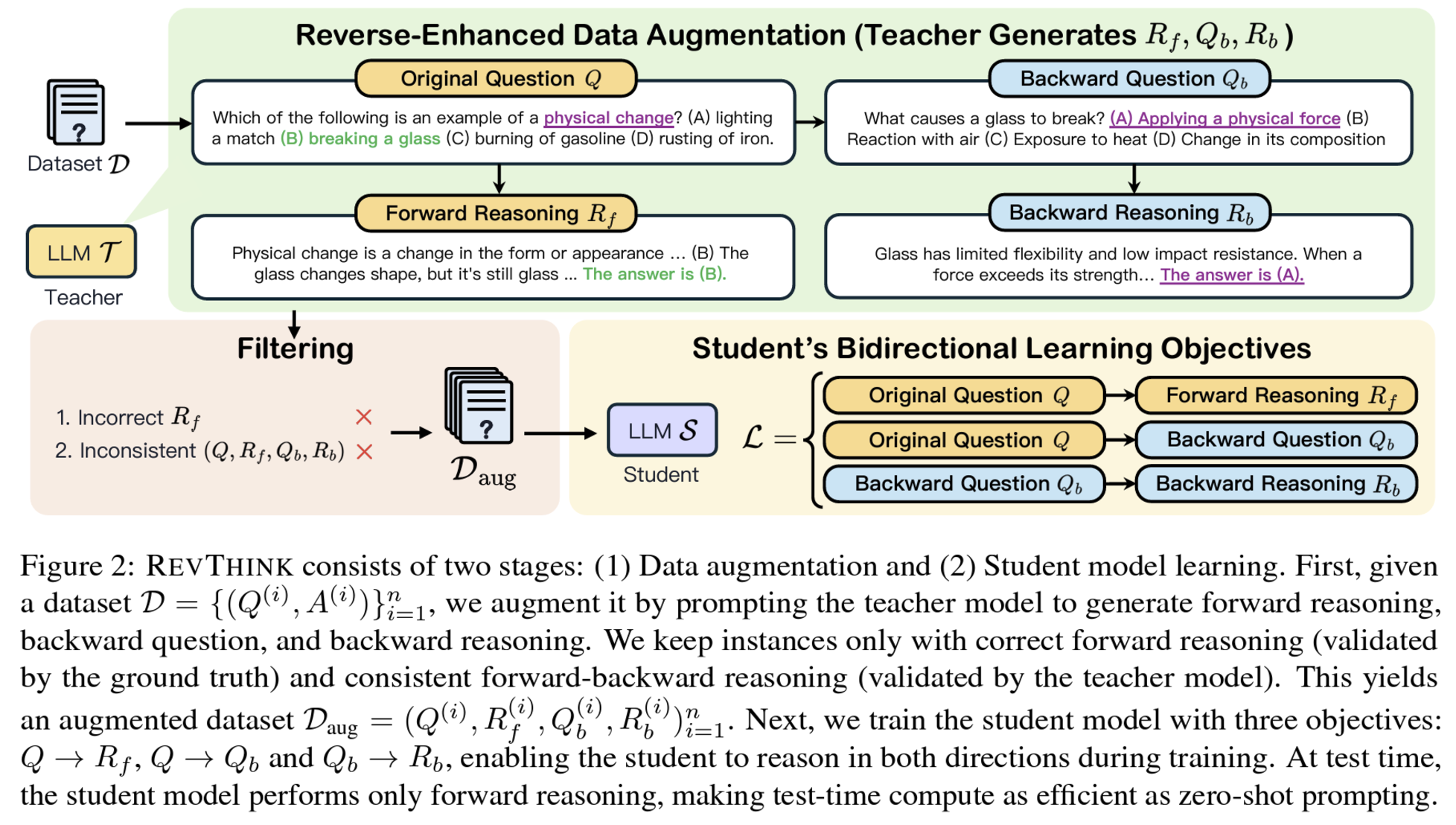
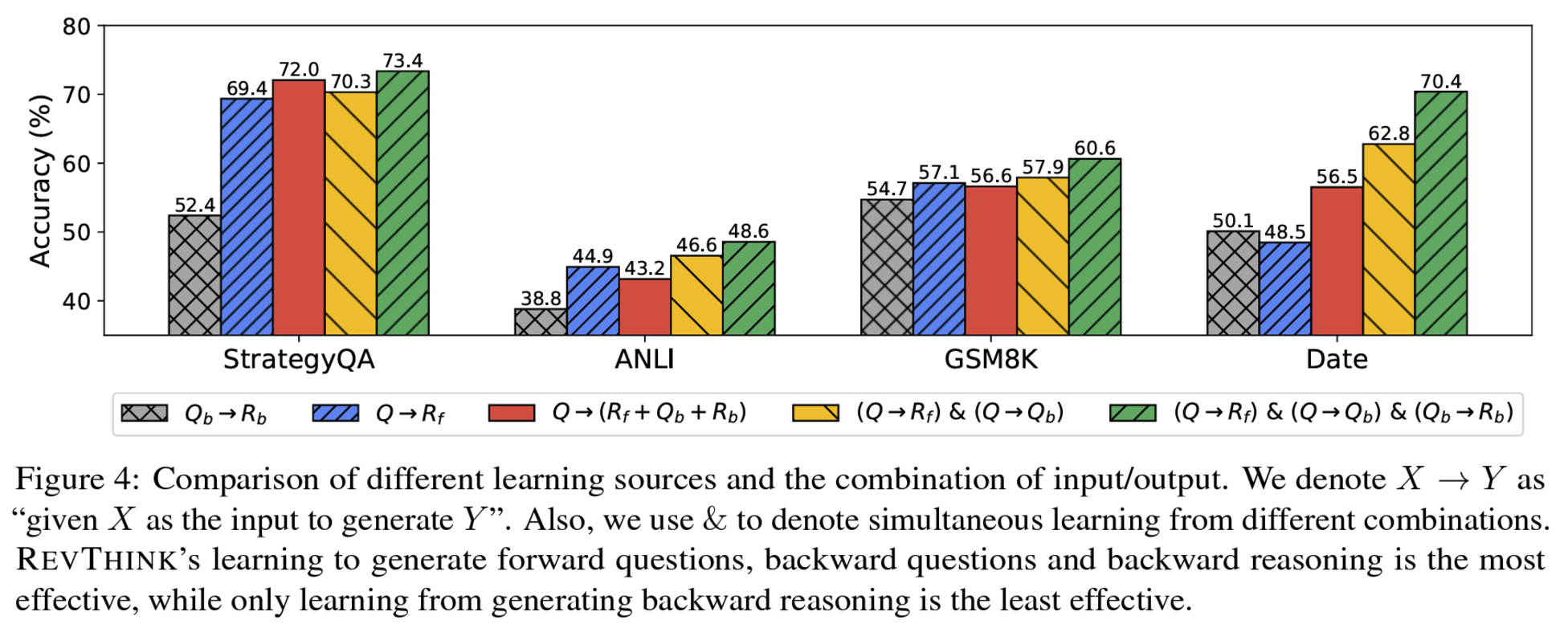
Distillation 방식으로 역방향 추론 학습하는 REVTHINK 프레임워크 제안
- data augmentation: 교사 모델의 fs prompting을 통해 (1) forward reasoning(CoT), (2) backward 질문, (3) backward reasoning(CoT)을 생성하여 데이터 증강
- training objective: 정확한 forward reasoning (vanilla knowledge distillation) + backward 질문 생성 + 앞서 생성한 질문에 대한 정확한 backward reasoning
- test time inference: 학생 모델은 forward reasoning만 수행.
Effects
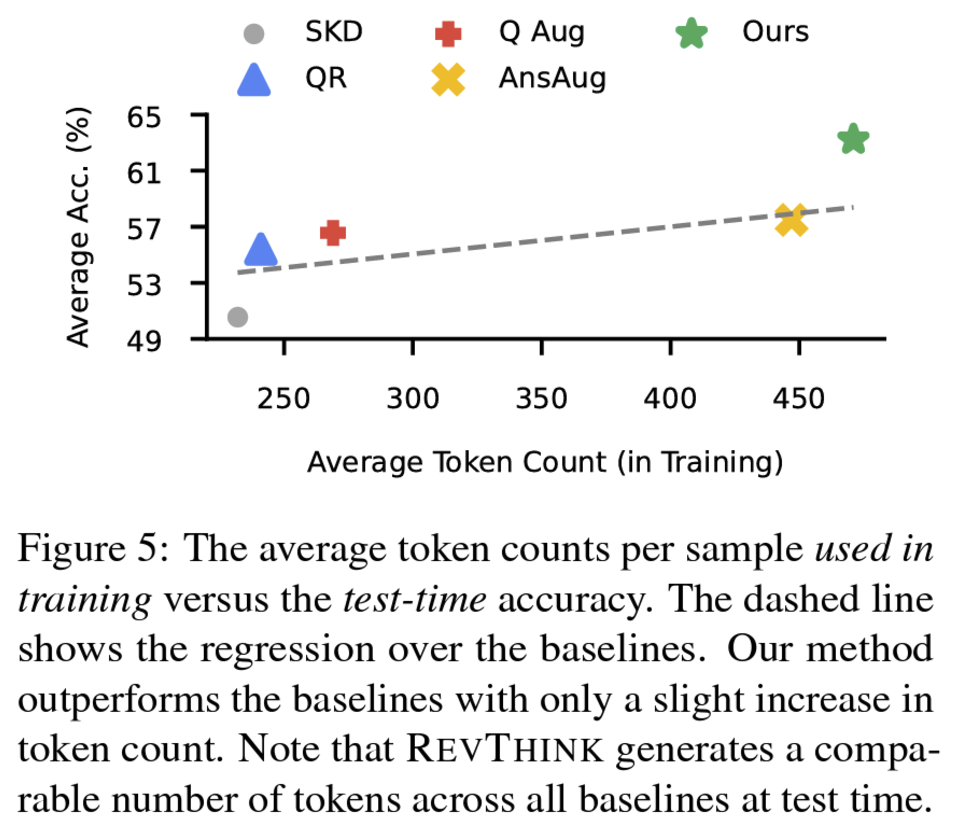
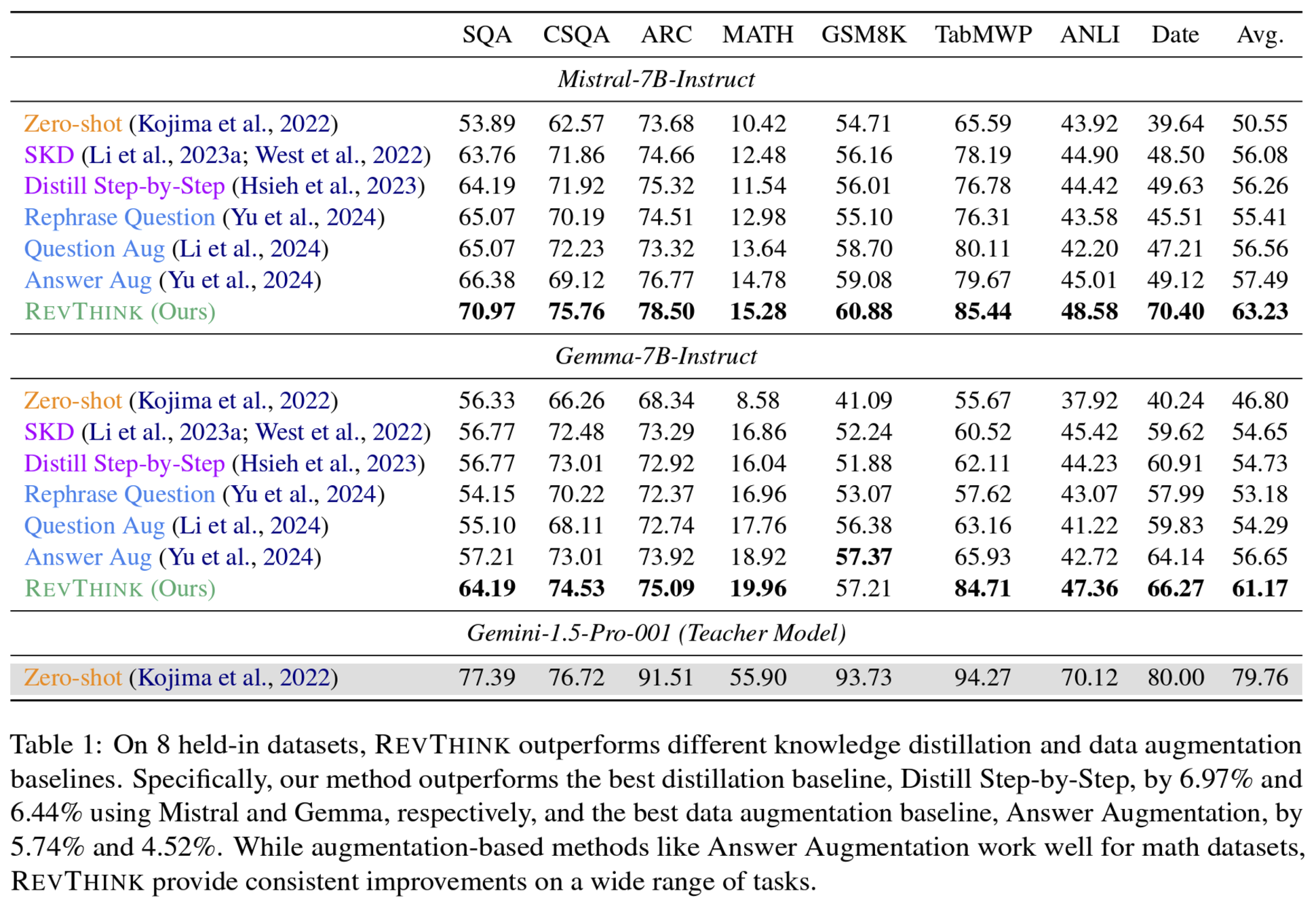
- 학생 모델의 zs 성능보다 평균 13.53% 향상, standard KD(forward inference only) 보다 6.84% 향상
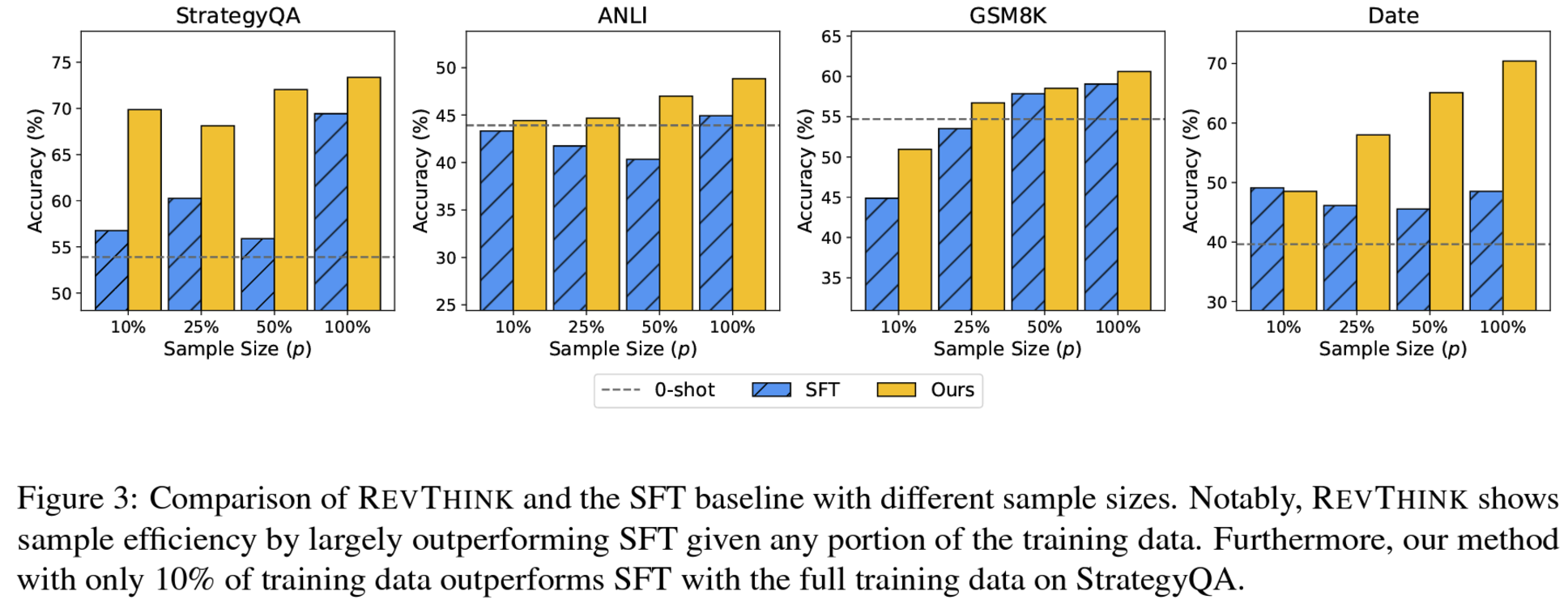
- forward reasoning 데이터셋 10%만 사용, 10배 더 많은 forward reasoning으로 vanilla finetuning 방법보다 성능 좋았음
Personal note. 깔끔한 방법으로 효과적인 결과. 역발상 예시를 들면 “사과 2개랑 배 3개가 있다면 과일 총 몇 개 있나요?” 같은 산수문제에 대해 forward 는 2+3=5 같은 구조라면 backward는 “5개 과일에서 배 3개 있다면 사과는 몇 개 있나요?” 같이 추론시키는 경우. 만약 forward reasoning에서 5가 아니라 6으로 잘못 추론됐다면 bacakward reasoning에서 수정될 여지..