Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM’s Reasoning Capability
Meta info.
- Authors: Zicheng Lin, Tian Liang, Jiahao Xu, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, Zhaopeng Tu
- Paper: https://arxiv.org/pdf/2411.19943
- Affiliation: Tencent AI, Tsinghua Univ.
- Published: November 29, 2024
TL; DR
오류 추론이 발생하는 과정에 중요 역할(원인)을 하는 토큰 (critical token)을 식별하여 이 토큰을 모델 추론 개선에 적용(cDPO)하는 방법론 제안


Background
critical token의 심각성
- critical token: LLM이 잘못된 추론 경로를 따르도록 유도하는 토큰
- e.g.
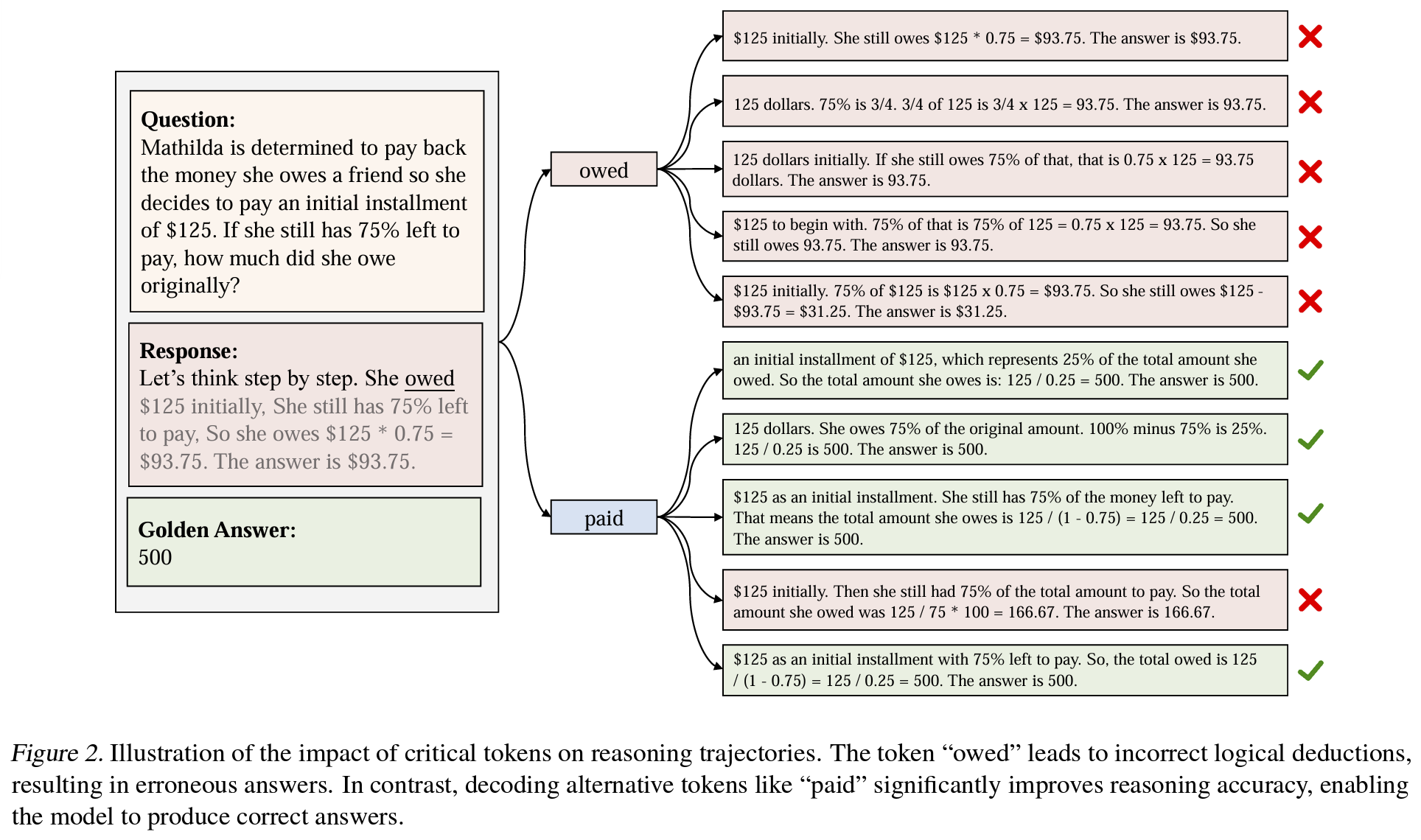
Figure 2의 “owed” → “paid” 변경 - experiment: GSM8K를 Llama-3-8b로 추론 수행, critical token 식별
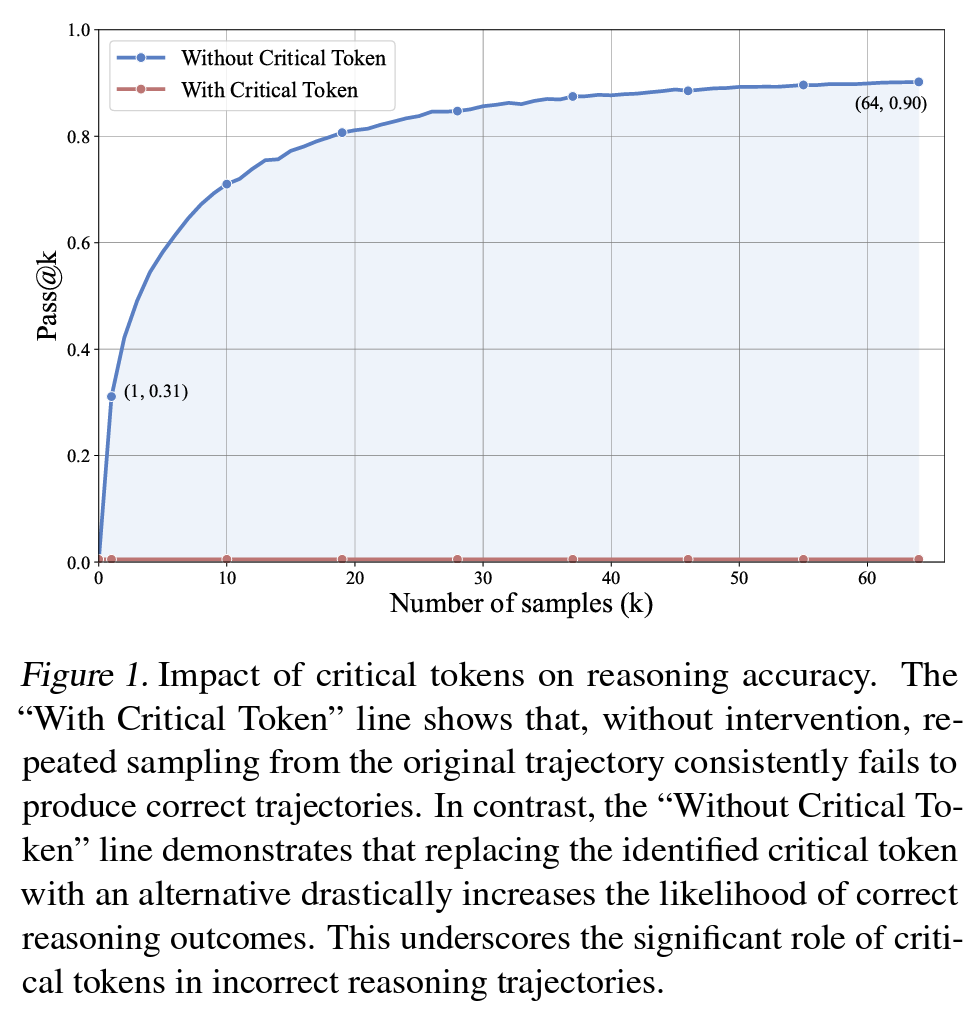
1) w/ critical token (token score by resampling): 틀린 reasoning에 있는 각 토큰에 대해 64회 리샘플링. 점수가 0점인 첫 토큰은 지속적으로 잘못된 결과 > critical token으로 지정
2) w/o critical token (alternative token으로 decoding 강제): 해당 token을 대체 토큰으로 강제 변경하도록 생성 제약 적용 후 동일하게 resampling → pass@k 측정
Figure 1
- e.g.
Problem States
critical token을 식별해서 바꾸는 게 성능에 크게 기여하긴 하는데, 그 식별비용이 너무 크고 확장성이 낮음.
- Research Question: critical token을 자동으로 찾을 수는 없나?
Suggestions
critical token을 contrastive estimation으로 자동식별해서 다른 token으로 대체하자 = cDPO
- critical token 자동 식별: positive/negative (reasoning) trajectory 비교
- contrastive estimation
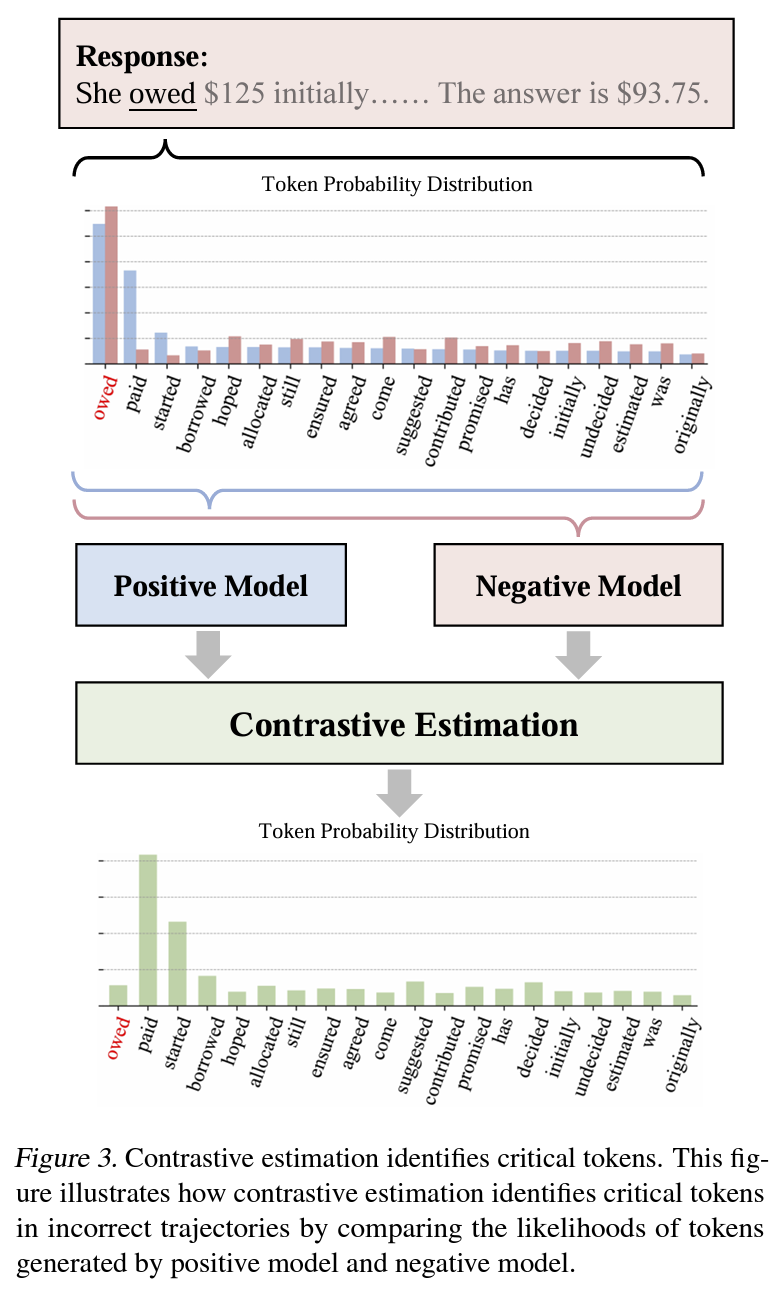
Eq. (1): positive model과 negative model 각각의 trajectory token level distribution 비교Figure 3
- contrastive estimation
- cDPO: alignment learning중에 (1) critical token을 식별 (2) token-level reward modeling
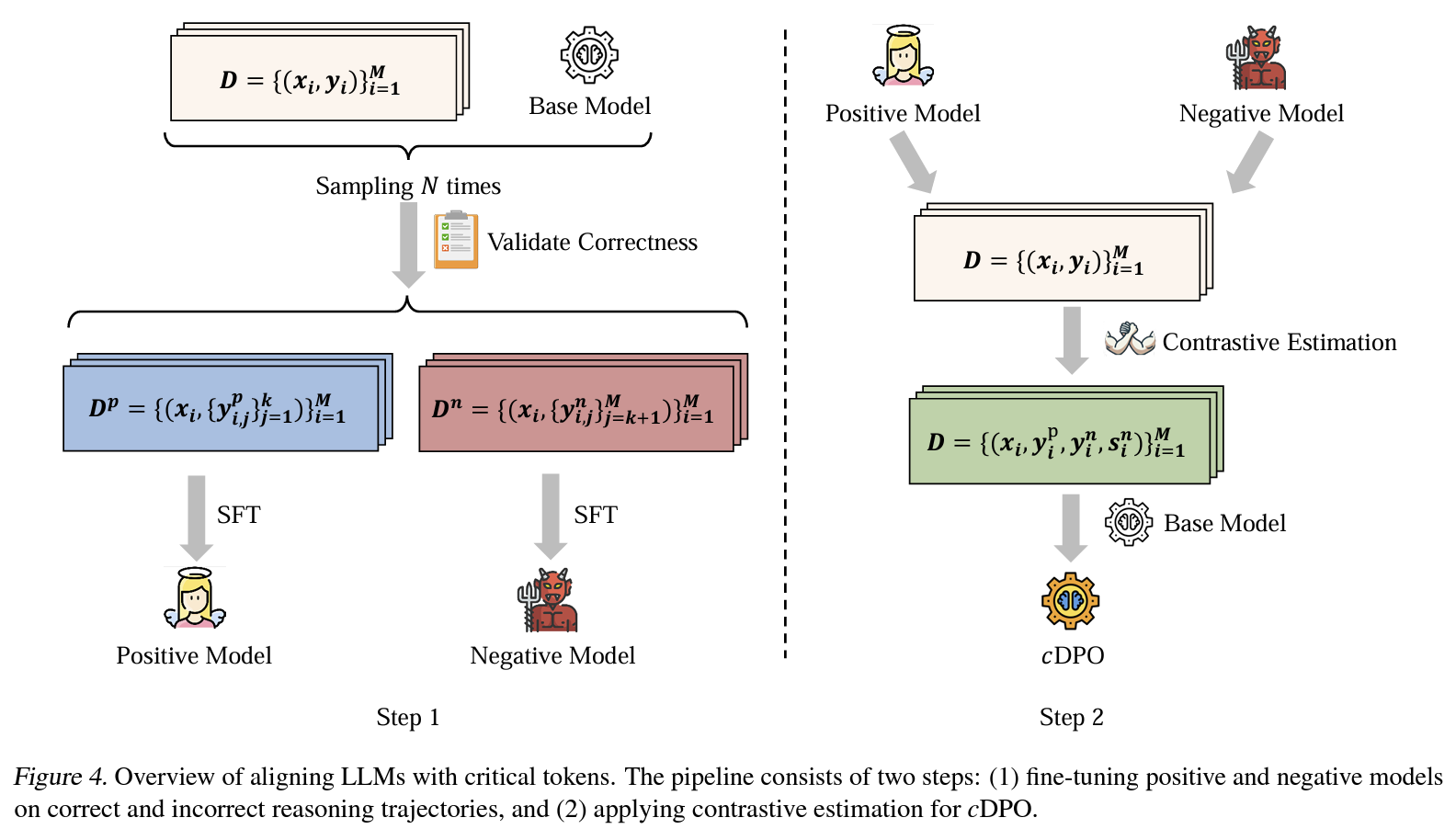
1)
Figure 4 step1incorrect/correct trajectory 구성: positive model에 대해 무작위 선택, negative model에 대해 상위 n% 선택 (다양한 error 중 확실한거 선택하기 위함인듯) → 각 trajectory별 model SFT 학습 2)Figure 4 step2token level DPO 수행 1. 설계: incorrect trajectory의 토큰만 점수화 (DPO tuning에서 critical token만 문제고 다른 token은 문제 없을 수 있으므로 정확한 penalty 주도록 처리해야하는데, 그렇다고 이미 잘 생성된 token 들에 (과하게) 점수를 주면 token distribution에 악영향 우려) 2. token-level preference dataset 생성: 프롬프트마다 각 trajectory pair 구성,Eq. (1)계산하여 critical token 자동 labeling 3. reward modeling: token-level로 DPO 확장Eq. (4, 5)
Effects
- experimental setup:
- backbone: llama-3-8B/70B, deepseek-math-7b-base
- dataset: GSM8K, MATH
- baseline: positive만 학습한 SFT, 혹은 ~PO series(DPO, TDPO, RPO, …)
- results
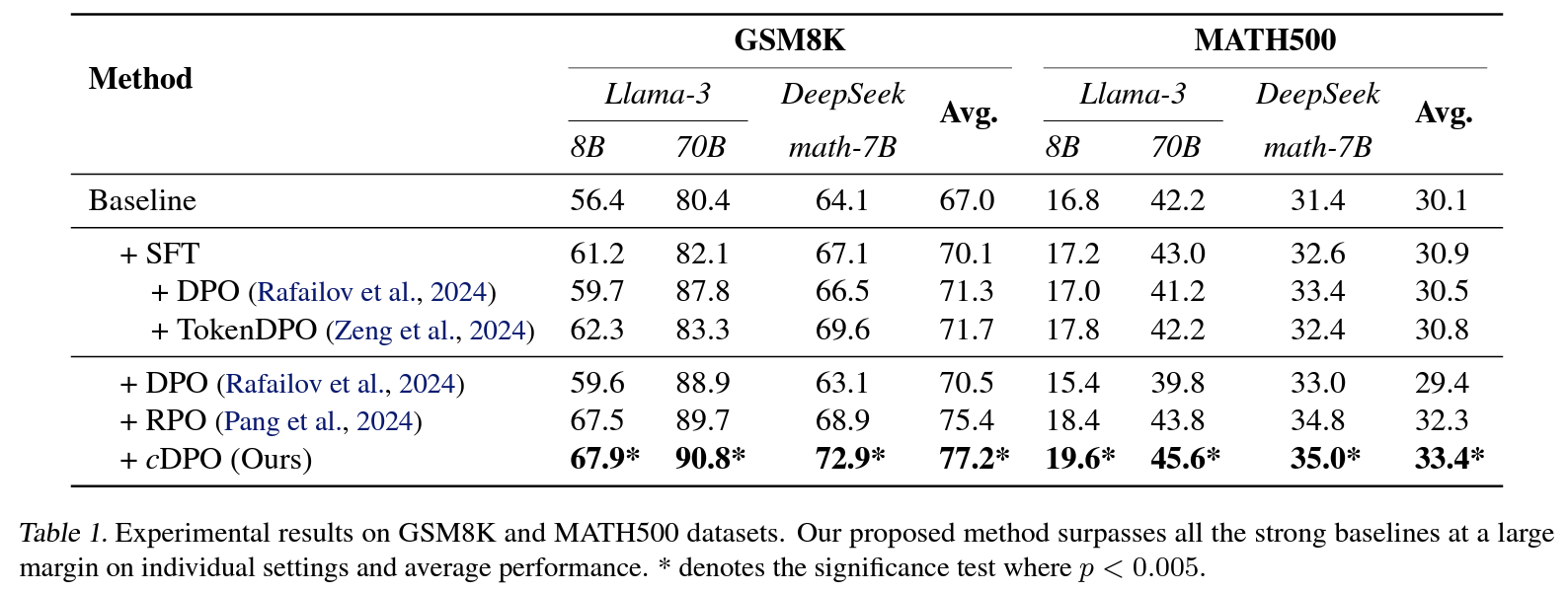
Table 1: 확인한 모든 벤치마크에서 p<.005로 SOTAFigure 5: contrastive estimation으로 식별한 critical token을 바꾸면 일관되게 성능 향상
Personal note. 추론 실패를 유도하는 주요 시작이 되는 토큰을 식별해서 수정하면 성능이 개선된다는 이전 연구는 있었는데, 이걸 자동 식별해서 token level로 DPO 하겠다는 첫 시도라고 하네요. 실험으로 확인한 건 수리추론에 한정하고 있는데, 컨셉이 단순해서 다양한 downstream task에 쉽게 적용 가능할 것 같습니다.