Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Meta info.
- Authors: Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, Azalia Mirhoseini
- Paper: https://openreview.net/pdf?id=0xUEBQV54B
- Affiliation: Google DeepMind, Stanford Univ., Univ. of Oxford
- Published: July 31, 2024
TL; DR
Repeated Sampling이 LLM 성능에서 coverage 측면의 효용이 매우 크고, 자동 verification이 가능한 경우 정확도까지 크게 향상시킨다.
Suggestion
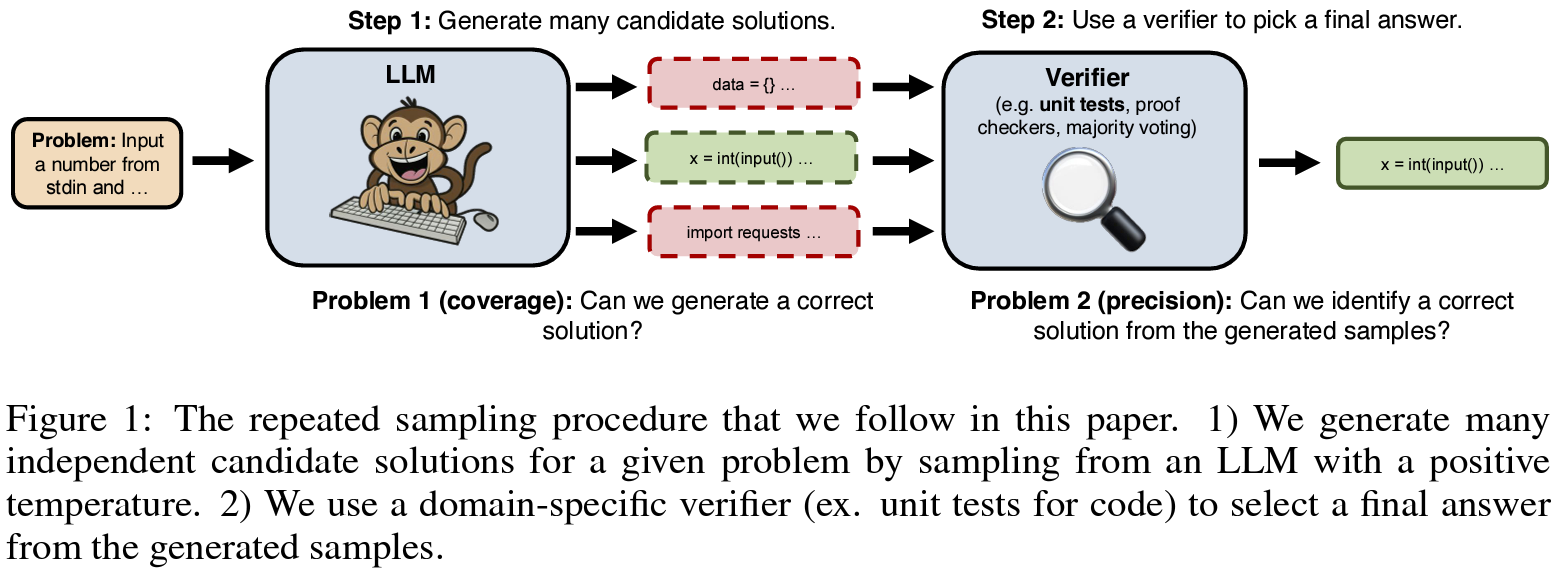
자원만 충분하다면 가능한한 많은 시행에서 답을 찾자(rapeated sampling)
- 하나의 문제에 대해 여러 개의 샘플 답변을 생성하고(샘플 생성)
- 이 중에서 가장 적절한 답변을 선택(검증)
- unit test, execution, majority vote, reward model, …
Effects
정확하고 효율적인 검증법 수반이 필수적
- Experimental Setup:
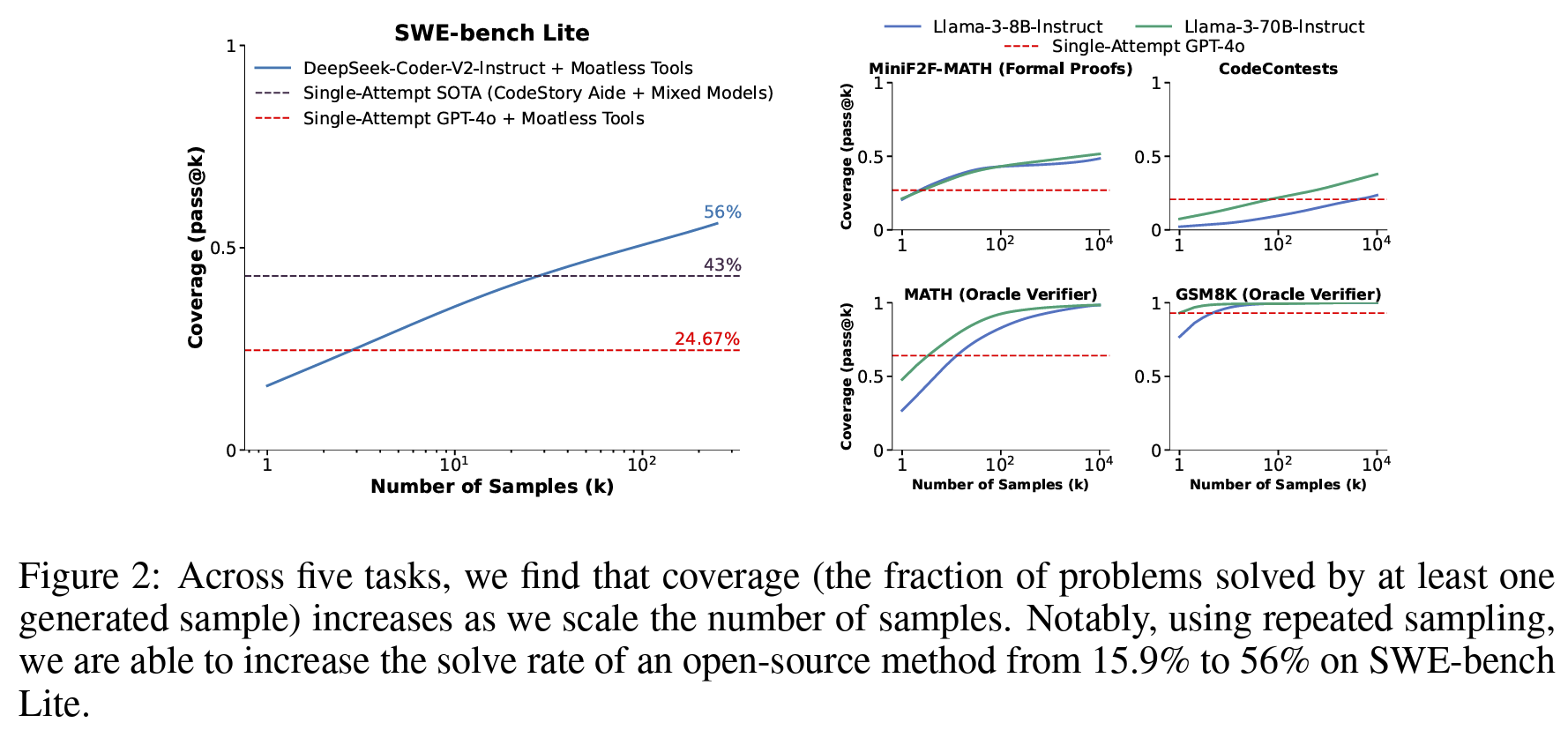
- Task: 수리추론(GSM8K, MATH), 증명(MiniF2F-MATH), 코딩(CodeContest), 실제 GitHub 이슈 해결(SWE-bench Lite)
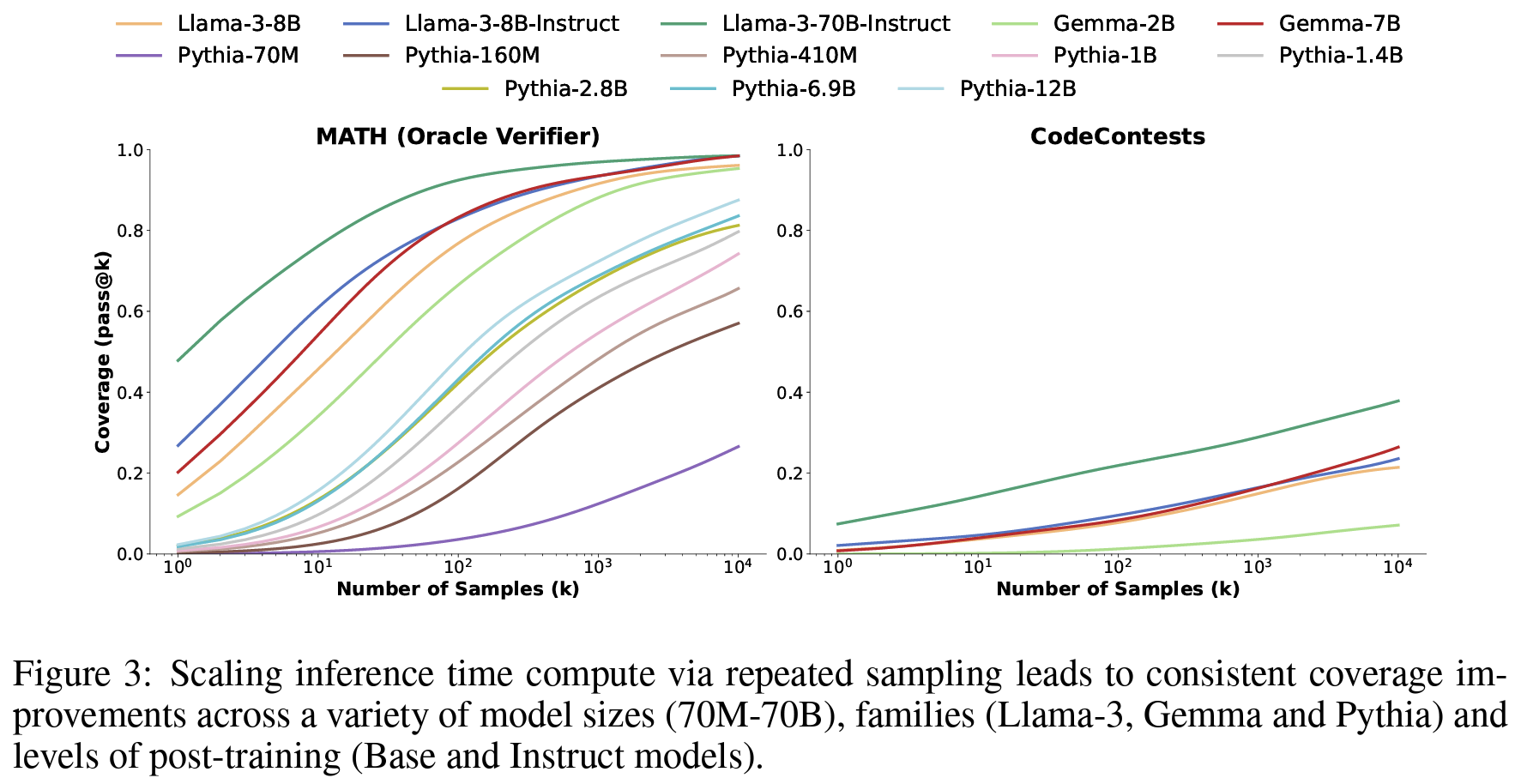
- Target Model: 70M-70B의 Llama, Gemma, Pythia
- Results:
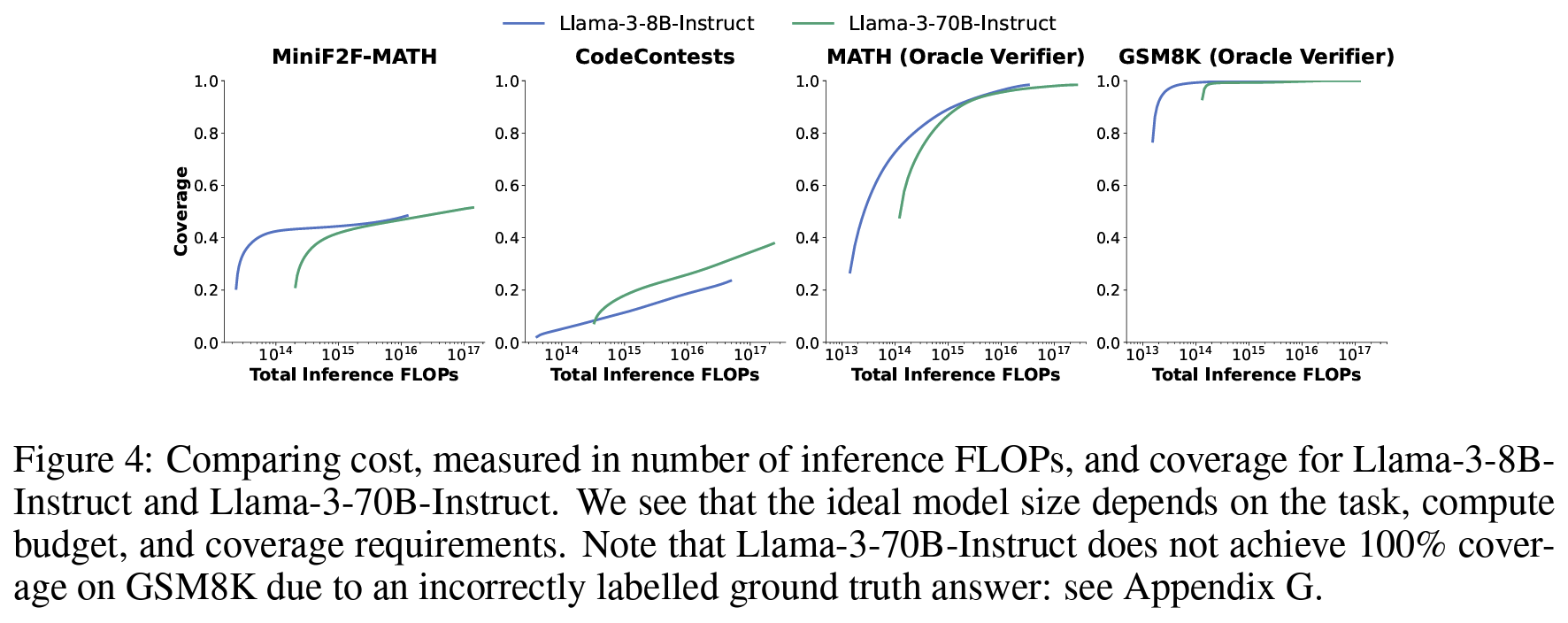
- 때에 따라서는 작은 모델로 더 많이 시행하고 답을 추려내는게, 큰 모델 쓰는 것보다 낫다.
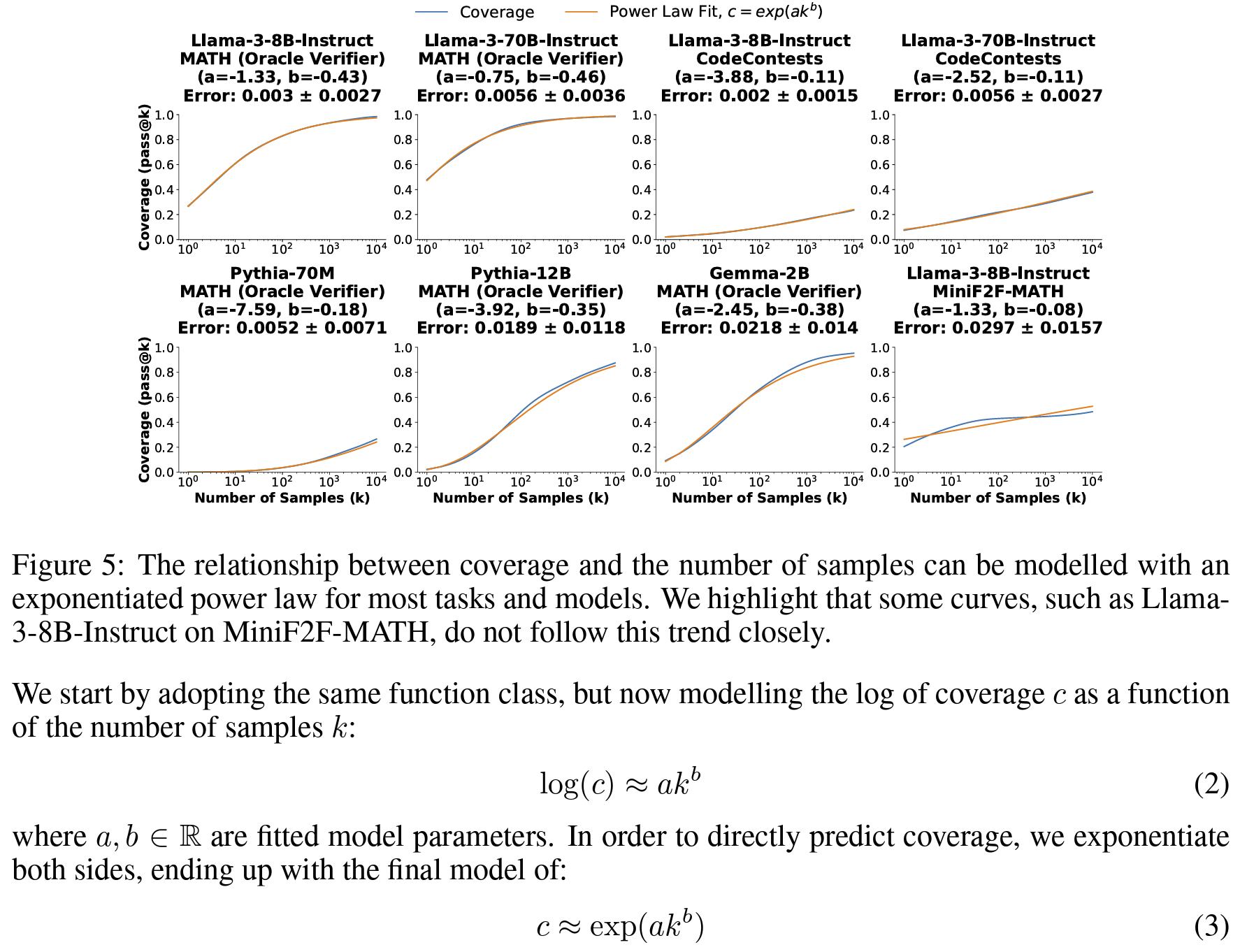
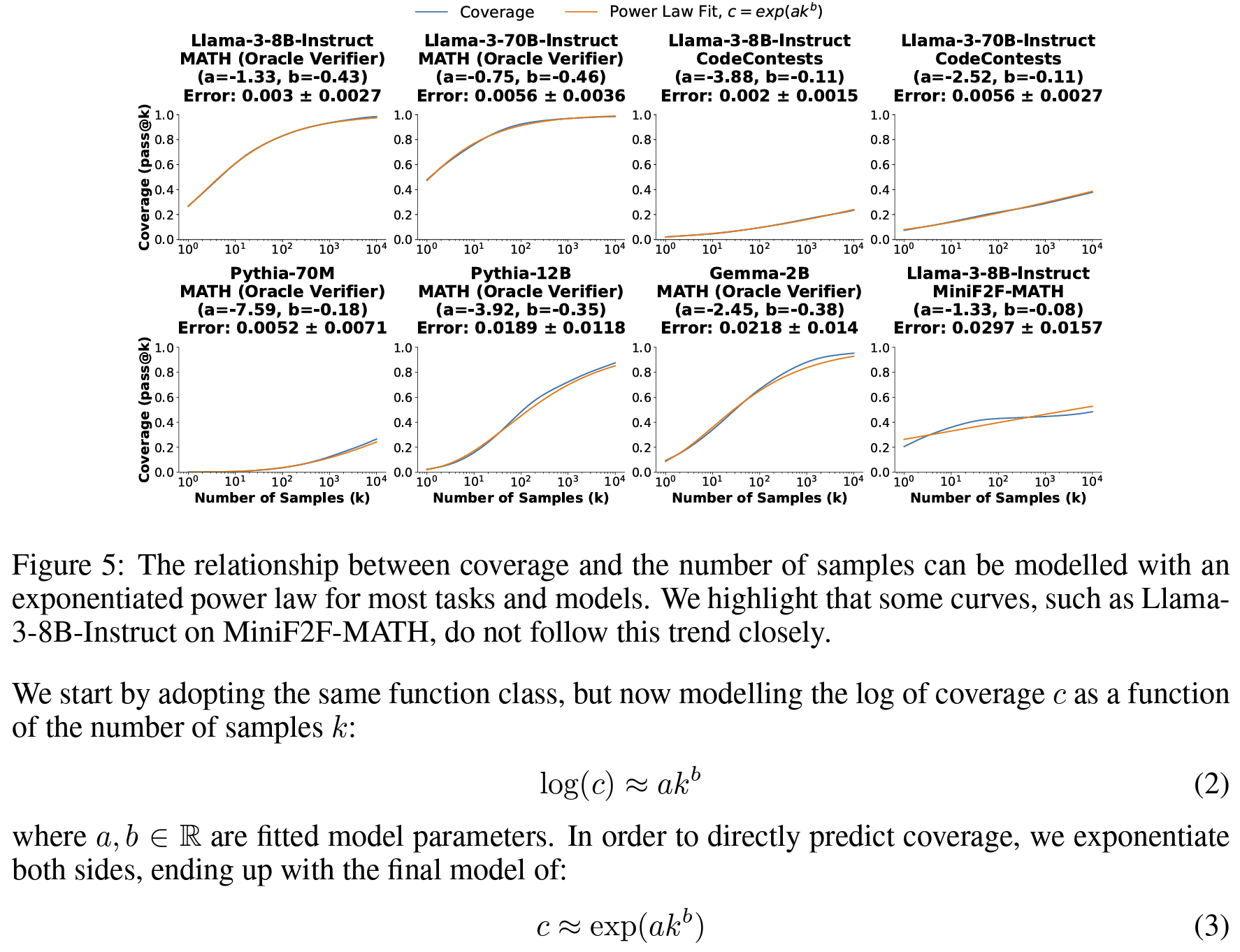
- 커버리지와 샘플 수 사이 power law 제시(
Figure 5) - 자동검증 가능한 경우 (논문에서 수리추론 외의 task)
- 샘플 수 증가에 따라 단일 시도로 해결못했던 문제 해결
- 더 크고 강한 모델의 단일 시도보다 높은 성능 달성
- 즉, 정밀도가 시행횟수에 비례해서 증가
- e.g. DeepSeek-Coder-V2-Instruct 단일시도 성능 15.9% > 250회 시행시 성능56% 증가 (+43%p)
- 자동검증 툴 부재한 수리추론의 경우,
- 샘플 수 증가에 따라 커버리지는 늘긴 하는데
- 정밀도 측면에서 majority vote나 reward model 사용하는건 도달 성능 상한이 있는듯
Personal note. 반복시행에서 맞는 답을 어떻게 찾아내느냐가 문제라는 굉장히 당연한 이야기를 하고 있는데 제대로 답변을 뽑아낼 수만 있다면 작은 모델로 시행횟수를 늘리는 편이 나을 수 있다는 걸 실험으로 보여서 수식화까지 진행한 점이 논리적인 설득력을 높인 것 같아요.