Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Meta info.
- Authors: Zhiyuan Liang, Dongwen Tang, Yuhao Zhou, Xuanlei Zhao, Mingjia Shi, Wangbo Zhao, Zekai Li, Peihao Wang, Konstantin Schürholt, Damian Borth, Michael M. Bronstein, Yang You, Zhangyang Wang, Kai Wang
- Paper: https://arxiv.org/pdf/2506.16406
- Affiliation: NUS, Oxford Univ., UT Austin, Univ. SG
- Published: June 19, 2025
TL; DR
prompt를 input으로, LoRA-tuend 파라미터를 output으로 하여 SFT하는 모델 DnD 제안. DnD를 한 번 학습 해두면 task마다 추가 학습 없이도 task-specific LoRA weight를 만들 수 있다.



Background
LoRA-tuning도 어쨌든 비용이 크다.
- PEFT를 쓰면 low-rank matrices 훈련으로 FFT 없이도 LLM tuning 가능 > 여전히 per-task fine-tuning 필요
- RPG, COND P-DIFF, ORAL 등 다른 hyper-network들은 보통 task ID 같은 심플한 condition을 사용
- 자연어 프롬프트의 다양한 변형을 처리하거나 새로운 작업에 대한 일반화 한계
Problem States
label이나 finetuning 없이 raw prompt에서 per-task LoRA weight(BA)를 직접 생성할 수 있을까?
Suggestions
DnD
- 자연어 프롬프트를 condition으로 LoRA 가중치를 직접 생성 (prompt-to-weight)
- 기존 LoRA-tuning: 데이터 > gradient > weight
- 제안 DnD 방식: 데이터(prompt) > weight
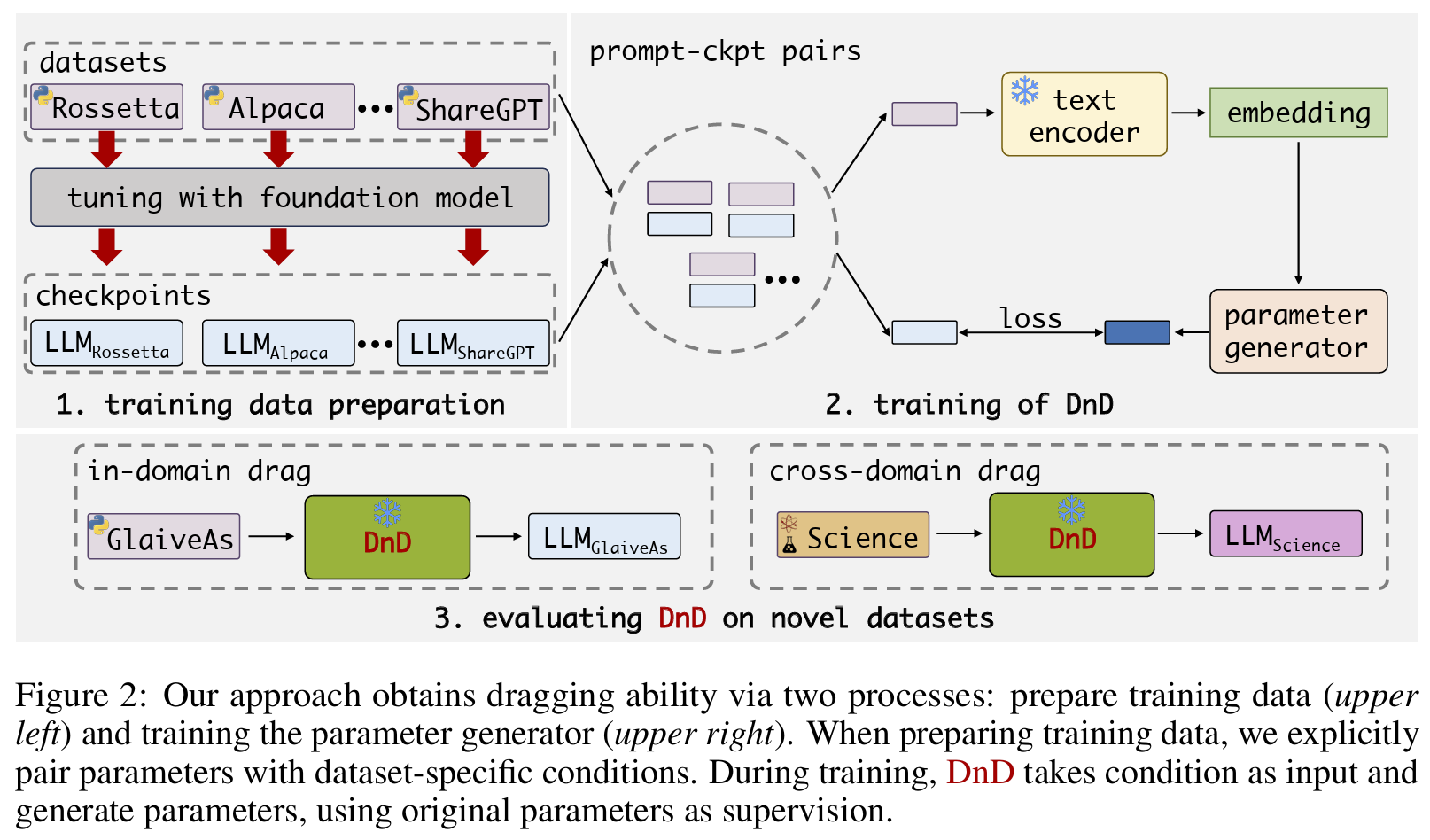
- {prompt, LoRA-tuned weight (ckpt)} pair를 parameter generator가 **MSE loss로 학습 (회귀문제로 접근)
- 다양한 데이터셋 (e.g., ARC, BoolQ, gsm8K)으로 LLM을 LoRA-tuning하여 ckpt 수집
- 각 weight와 mapping할 condition prompts 구축: 다양한 task별 모델에 입력으로 들어가는 query들 **(답은 ❌)
- LoRA tuning시 사용한 input 텍스트들 일부 샘플링 (batch 단위)
- 랜덤 pair 구축: 1개의 ckpt, 1개의 prompt pair를 random mapping
- text encoder: SBERT로 prompt embedding 생성
- parameter generator: Hyper-Convolutional Decoder
- input: condition prompt embedding batch, output: weight matrix
-
B=batch size, N=prompt 개수, C: embedding 차원, L: token 길이 (prompt 당)
clW = Conv1H(Conv1W(cl−1)) # prompt 내부 관계 포착 > prompt간 상관성 포착 clH = Conv2W(Conv2H(cl−1)) # prompt간 상관성 포착 > prompt 내부 관계 포착 cl = ConvL((clW + clH + b) / 3) # 레이어별로 LoRA weight를 분리해서 생성- clW: 프롬프트 내부 먼저 보고 > 프롬프트간 패턴 확인
- Conv1W: L × C 차원에서 프롬프트 내부 토큰 시퀀스 상관성 포착
- Conv1H: N × L 차원에서 프롬프트 간 상관성 포착
- clH: clW 순서 교체
- cl: 서로 다른 정보의 clW와 clH 평균 > ConvL 처리(레이어별로 LoRA weight를 분리해서 생성)
- clW: 프롬프트 내부 먼저 보고 > 프롬프트간 패턴 확인
- training: 생성된 weight vs 실제 weight MSE Loss 학습
- inference: 뽑힌 weight를 바로 LLM에 꽂아서 inference 수행
Effects
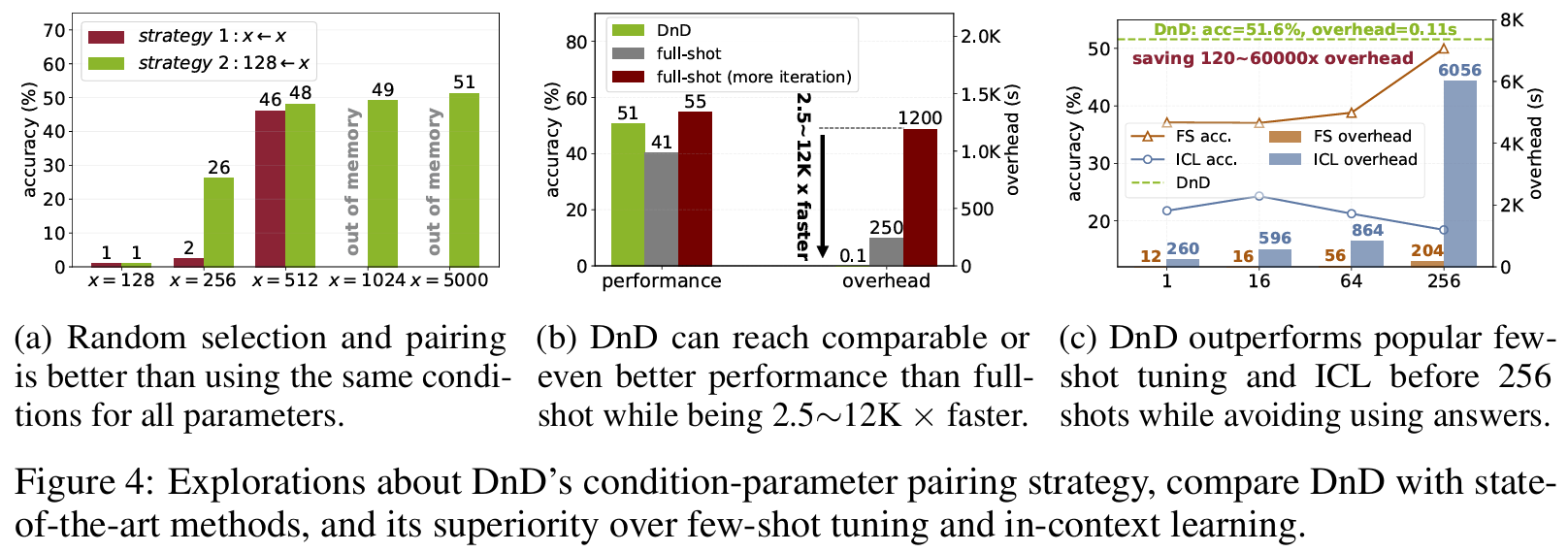
효율성, 속도, few-shot/ICL과 비교 결과 DnD가 우위
- full fine-tuning 대비 연산량 1만 2천배 절감 (초단위 weight 생성)
- LoRA full-shot 튜닝보다 성능 우위: few-shot, ICL과 비교해도 256-shot 이전에는 무조건 우위
- 심지어 일부 task에서는 원본 LLM 자체보다도 더 좋은 성능
- 실험한 task들에서 unseen task 수행시, 기존 optimized-LoRA보다 평균 30% 성능 향상 확인
- ablation study:
- 대형모델도 DnD 가능: 7B 모델까지 확장 가능 확인
- prompt 개수는 많을수록 좋았고, 답은 안주는게 더 성능이 좋고
- embedding 성능이 중요. 실험에서 SBERT가 가장 좋았다고
- DnD학습데이터는 많은게 좋다고
Personal note. input text 주고 LoRA matrix 숫자로 뱉게 학습한 모델 하나 잘 뽑아놓으면 = DnD, 그 모델에 원하는 input 잘만 정의해서 줬더니 꽤 그럴듯한 weight matrix뽑아주더라 당연히 매 task마다 LoRA 튜닝하는것보다야 싸고 성능도 비슷하거나 더 잘하기도~의 흐름입니다. 단순하게 써먹을 데가 많아보이고, 각 도메인에 잘만 갖다 쓰면 또 쉬운 활용이 될 것 같습니다. 예를 들면 personalization에서 쓴다던가..