RefCritic: Training Long Chain-of-Thought Critic Models with Refinement Feedback
Meta info.
- Authors: Qiaoyu Tang, Hao Xiang, Le Yu, Bowen Yu, Hongyu Lin, Yaojie Lu, Xianpei Han, Le Sun, Junyang Lin
- Paper: https://arxiv.org/pdf/2507.15024
- Affiliation: Alibaba Group, CISAS
- Published: July 20, 2025
TL; DR
해답의 정확성 및 개선 기여 피드백을 모두 평가하는 dual-reward RL-trained critic model을 도입한 RefCritic 제안, 수리 추론 과제에서 큰 성능 향상

Background
LLM-based critic 모델의 대두
- LLM-based critic model: SFT로 훈련, 추론 검증 및 설명
- 실제 유용성보다는 표면적인 판단(정오 판단)에 초점 > 개선에 유익한 실행 가능한 피드백 부족
- DeepCritic, ThinkPRM
- ProcessBench, CriticBench 등의 한계: step-level 또는 outcome verification에서 critic 평가
- critic feedback과 downstream task 연결성 부족
Problem States
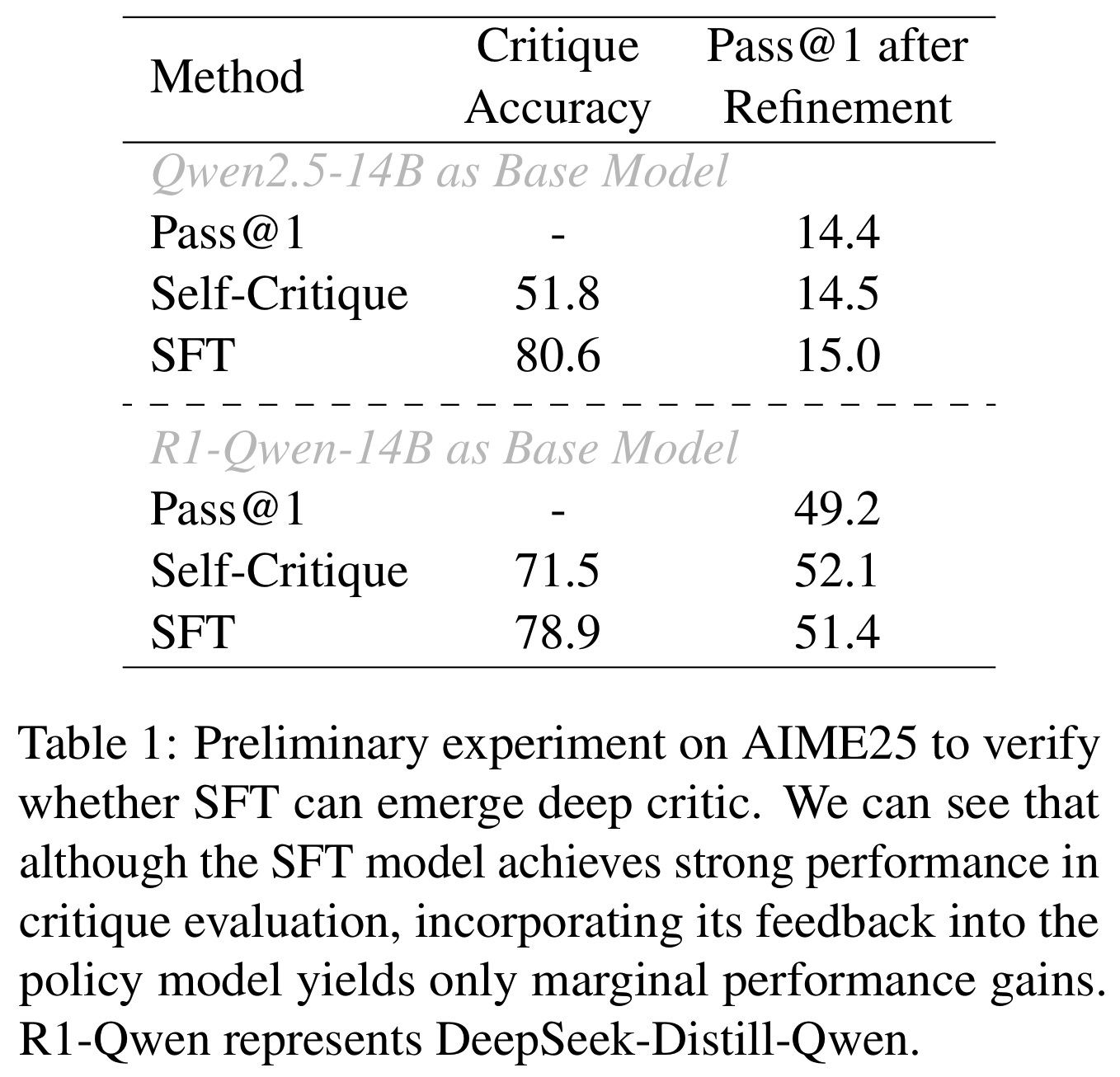
SFT-based critic은 response의 개선으로 이어지는 깊이있고 신뢰할만한 비평을 생성하지 못한다.
- 판단은 종종 잘하더라도 그 추론은 얕거나 결함 포함
- 해주는 피드백이 모호하고 구체성이 부족하여 실제 모델 output 개선은 어려움
- 비평의 질을 policy 모델 개선과 연계할 수 있는 인센티브 구조가 없다.
Suggestions
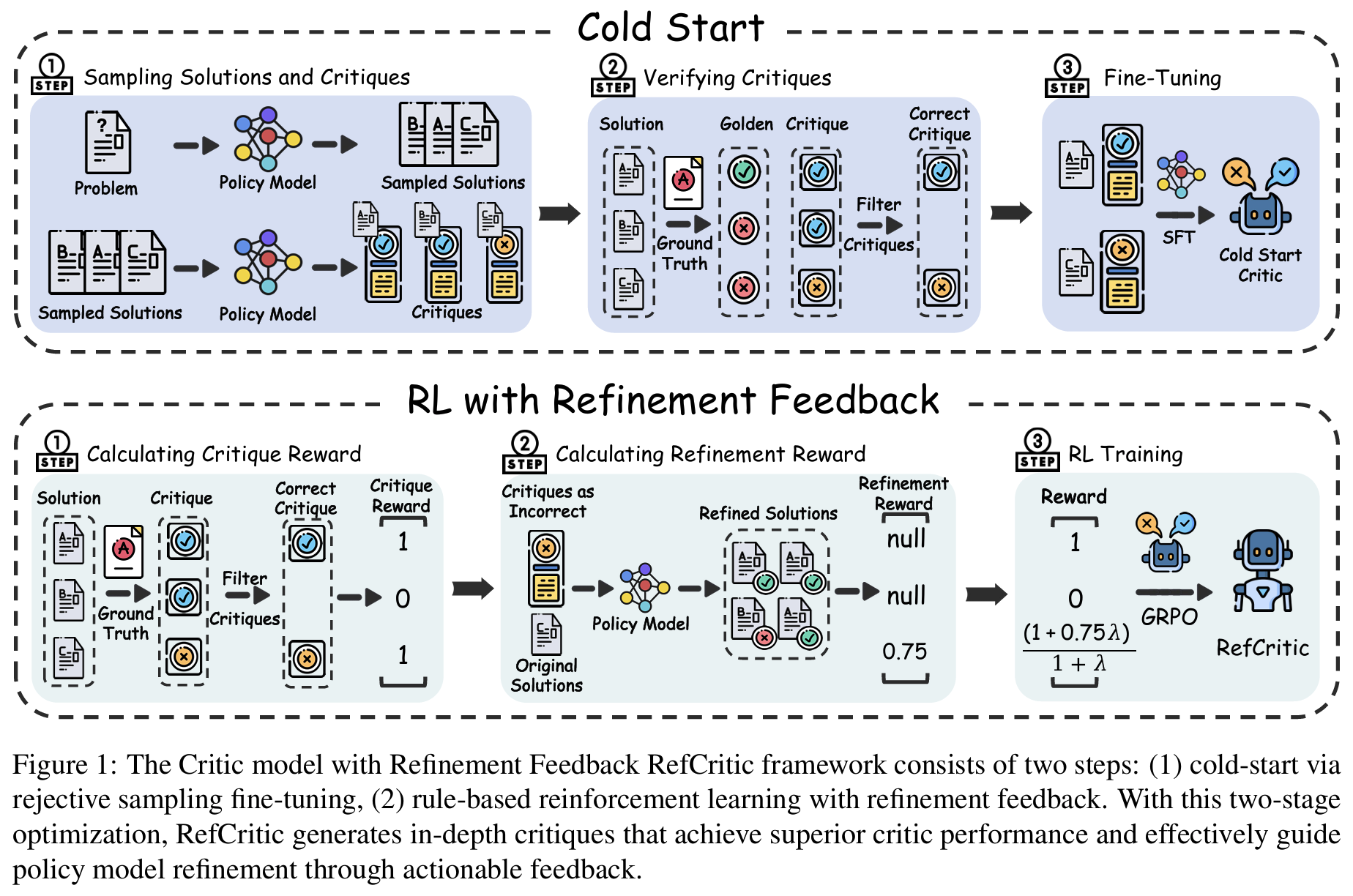
RefCritic Framework
- 2-stage critic model 훈련 Pipeline (GRPO-based RL)
- Cold-Start SFT
- NuminaMath-1.5의 약 1만개 고품질 sample 활용
- critic models이 Long CoT critiques
z, 정답 판단 (correct/incorrect)c^, refinement feedbackf생성하도록 학습
- Dual-Reward RL with Refinement Feedback
- Judgment Reward
R_j: critic 모델의 prediction가 ground truth랑 일치하는가? - Refinement Reward
R_r: policy model이f반영 후 생성한 m개의 새 해답에 대해 개선된 만큼 Reward 부여- policy model의 prediction이 틀렸고, critic 모델의 판단이 맞을 때만 계산
- 무의미한 feedback을 준 경우 refinement에 대한 강화학습 reward 0
- e.g., 정답이 7인데 policy model은 8이라고 대답 (오답) > critic model은
c^틀렸다고 판단 (정오 맞춤,R_j) + feedbackf생성 > f 보고 policy model이 m개 output 생성 > 그 중 맞춘 만큼이 critic model의R_r
- Judgment Reward
- Cold-Start SFT
Effects
- SFT만으로는 모자라다: Q-wen의 Self-Critique과 SFT critic의 한계 지적 (accuracy != actual improvement)
- 제안 방식이 실제 유익하다
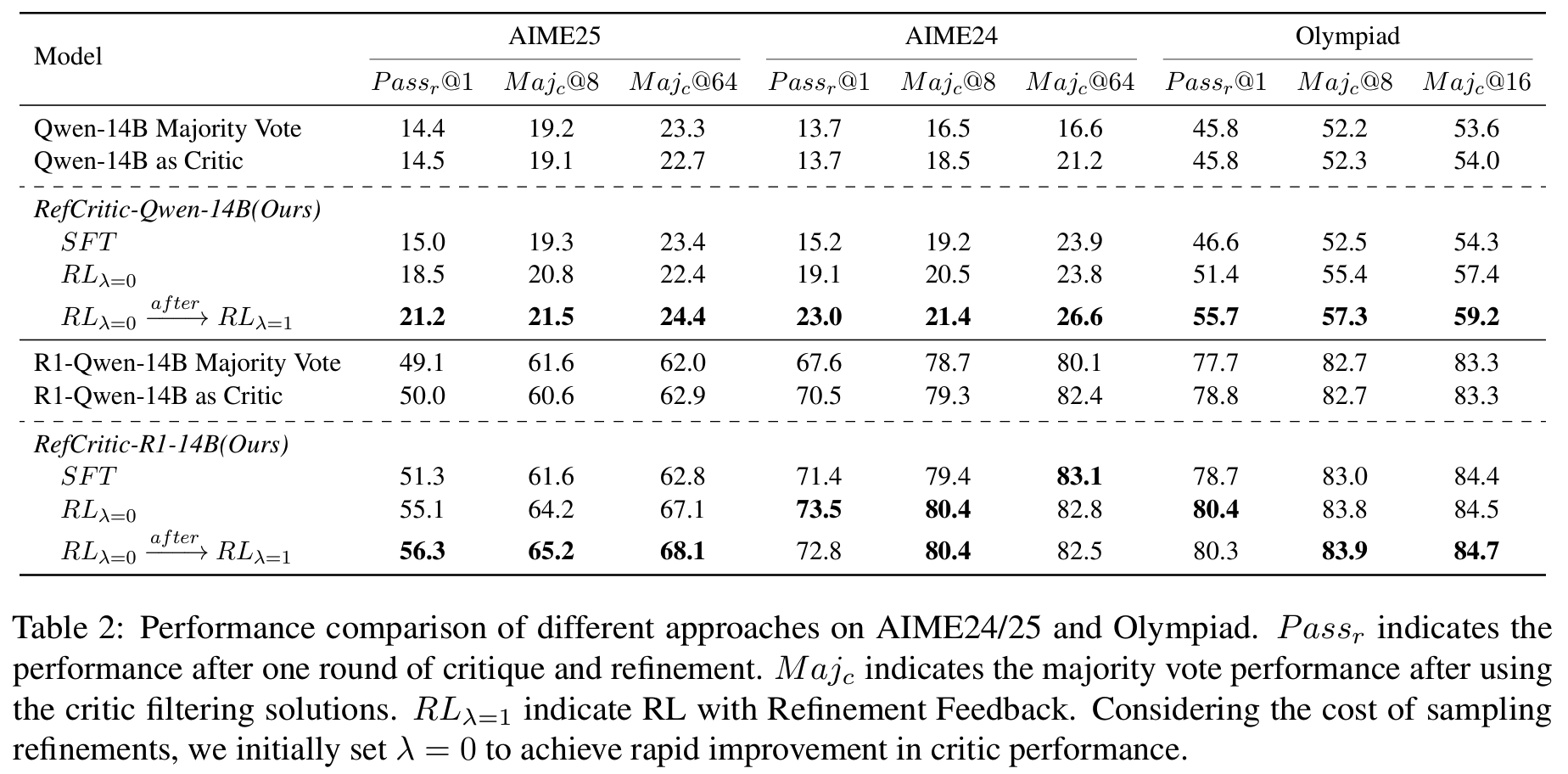
- AIME25~: RefCritic-R1-RL이 최고성능 달성, pass@1 최대 +7.2% 향상
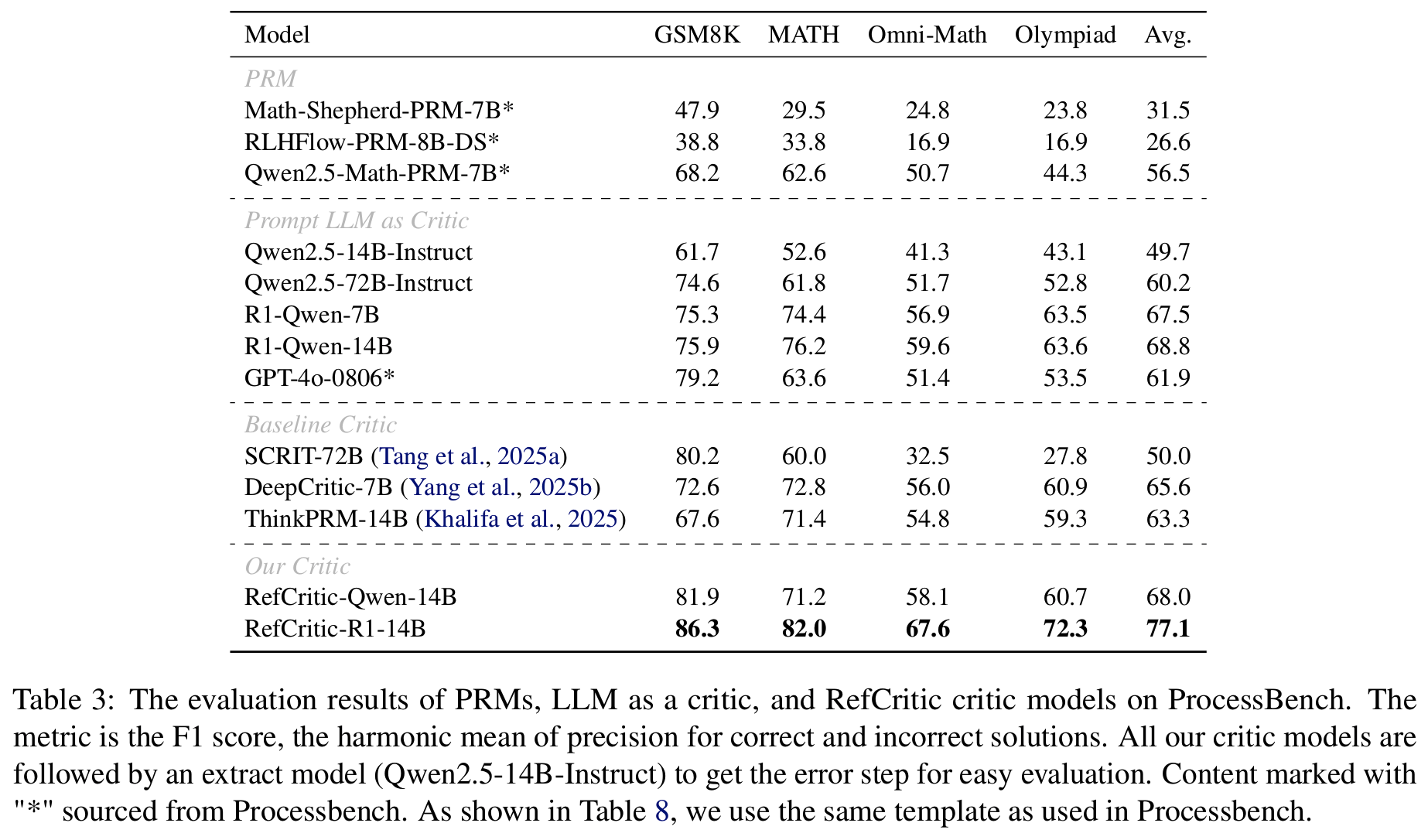
Tab 2 - ProcessBench: step-level supervision 없이 solution-level의 ciritic만으로도 baselines보다 우수
Tab 3
- AIME25~: RefCritic-R1-RL이 최고성능 달성, pass@1 최대 +7.2% 향상
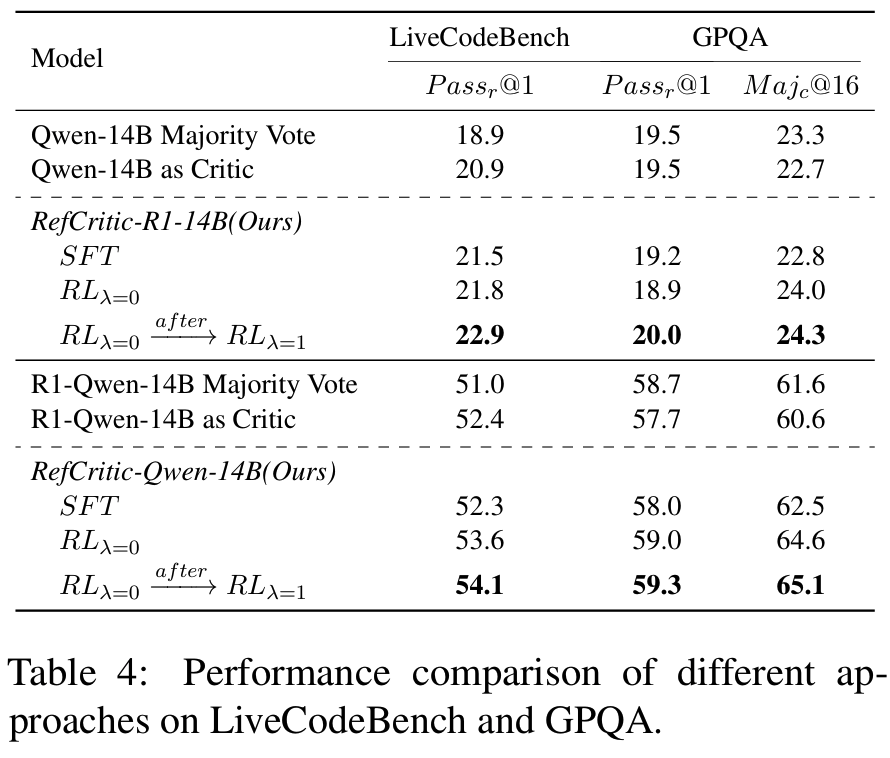
- OOD Generalization: LiveCodeBench에서 +3.1, GPQA Majc@64에서 +3.5
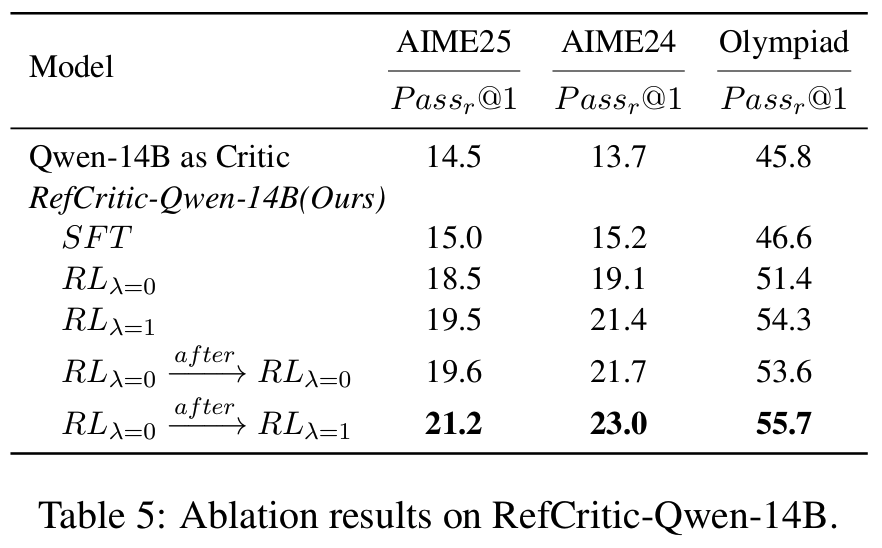
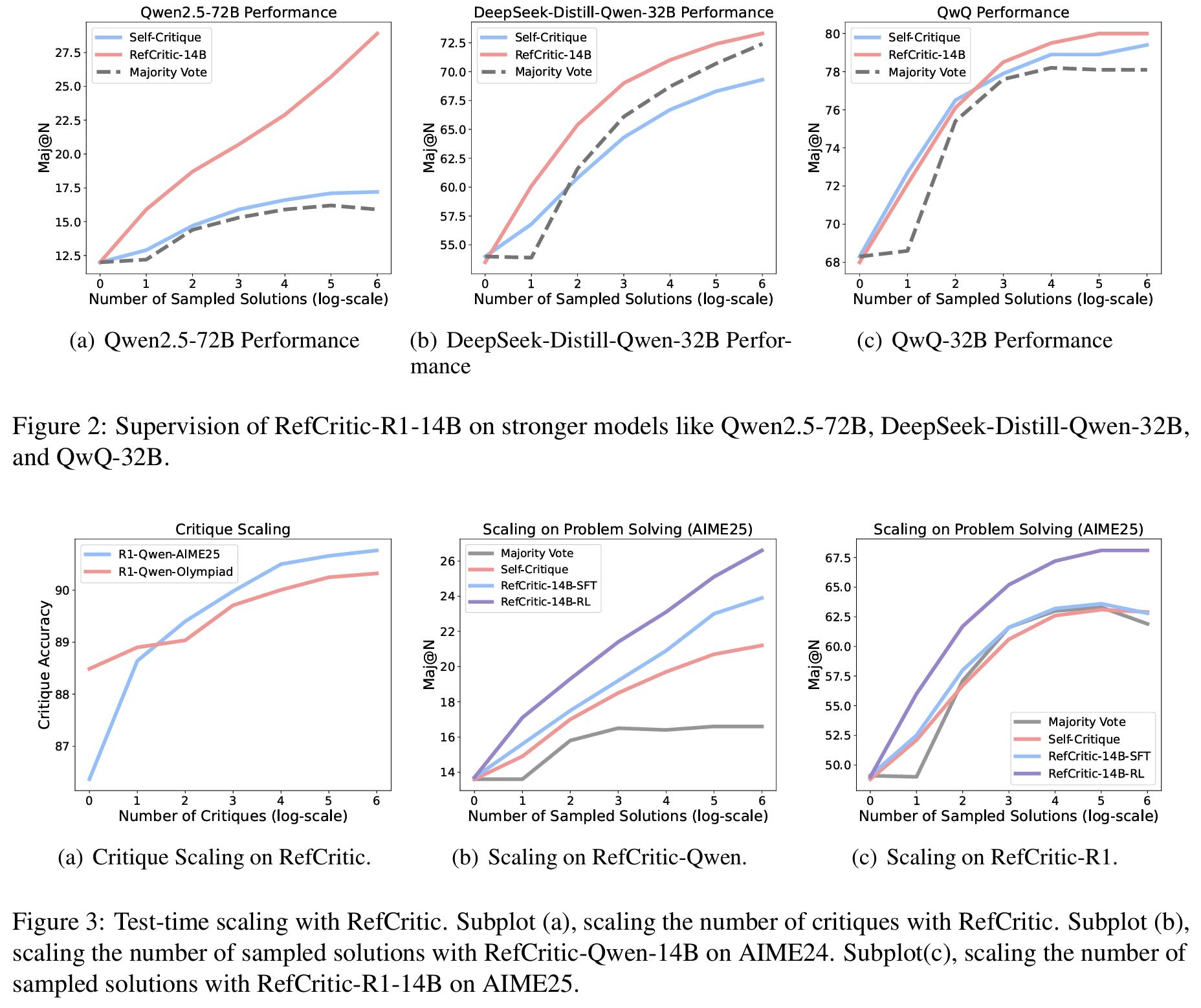
Tab 4 - Scaling Trends
- 더 많은 critic > 정확도 향상 (test-time scaling)
- 더 많은 솔루션 샘플 > majority나 self-critique보다 RefCritic이 더 나은 스케일링
Fig 3
- Supervision of Stronger Models: RefCritic은 추론 능력도 향상: LLM들의 self-critique보다 낫다
Fig 2
Personal note. inference-time에서 critic을 multi-turn으로 주고받았을 때 효과나 양상이 궁금하고, step-wise로 critic을 주는 연구나 self-critique으로의 확장이 향후 연구 방향이 될 것으로 보입니다.