Cooper: Co-Optimizing Policy and Reward Models in Reinforcement Learning for Large Language Models
Meta info.
- Authors: Haitao Hong, Yuchen Yan, Xingyu Wu, Guiyang Hou, Wenqi Zhang, Weiming Lu, Yongliang Shen, Jun Xiao
- Paper: https://arxiv.org/pdf/2508.05613
- Affiliation: Zhejiang Univ
- Published: August 7, 2025
- Code: https://github.com/zju-real/cooper
- References: https://zju-real.github.io/cooper
TL; DR
policy와 reference-based RM (verifyRM) 을 동시에 update하는 RL framework COOPER 제안. reward hacking을 막기 위해 rule-based positives와 LLM-generated negatives를 활용한 contrastive pair 구축.
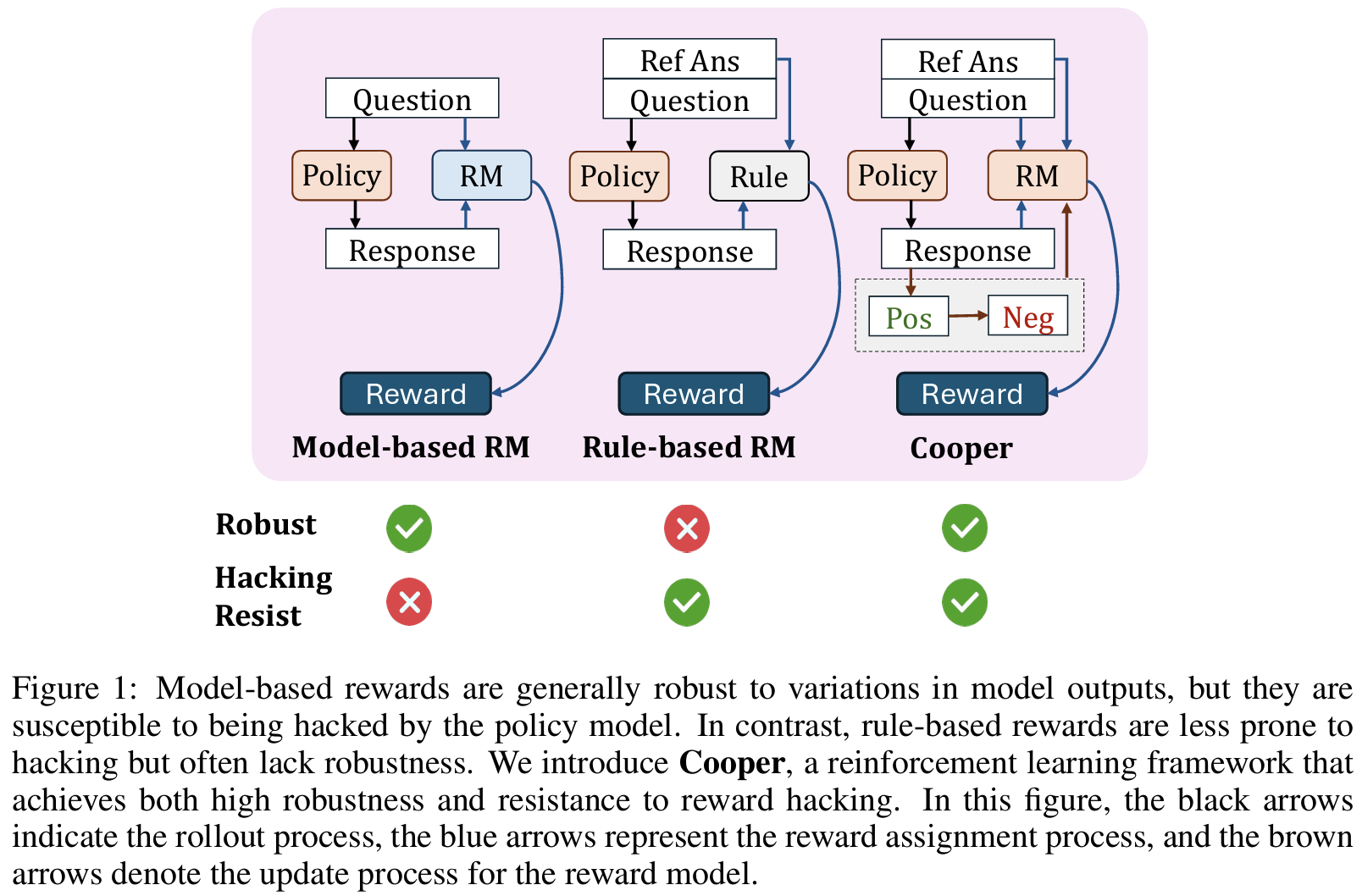

Background
- RLHF, DPO, GRPO 등 RL-based post training의 reward design은 크게 두 축으로 rule-based/verifiable 또는 model-based
- 최근 verifiable reasoning 파이프라인(o1, R1 등)은 rule-based reward 활용이 보편적
Problem States
RM의 두 방식에 대한 장점만 취한 RM 설계
- static RM은 flexible한데 반해 reward hacking에 취약하고 (RL 성능 저하)
- rule-based reward의 강건성에 한계 (hacking에 강건하나, 상대적으로 format과 내구성 등에 issue)
Suggestions
- Preliminary Observations:
Table 1- rule-based verifiers는 correctness에서 높은 precision 낮은 recall
- small LLMs-based judges(model-based methods)는 상대적으로 균형잡힌 성능
-
positive case에 대해 rule-based 방식을 활용하자
- VerifyRM: 일반적으로 RM이 입력받는 query q + completion o 뿐만 아니라 + reference a를 추가로 받아 정답 여부 판단하는 binary classifier 훈련
- backbone: Qwen2.5-Math-1.5B-Instruct, objective: BCE
- datasets: Math-Verify(rule-based) + Qwen3-4B’s judge; Consensus labeled만 사용 « 기존 reference-based 방식과의 차별점
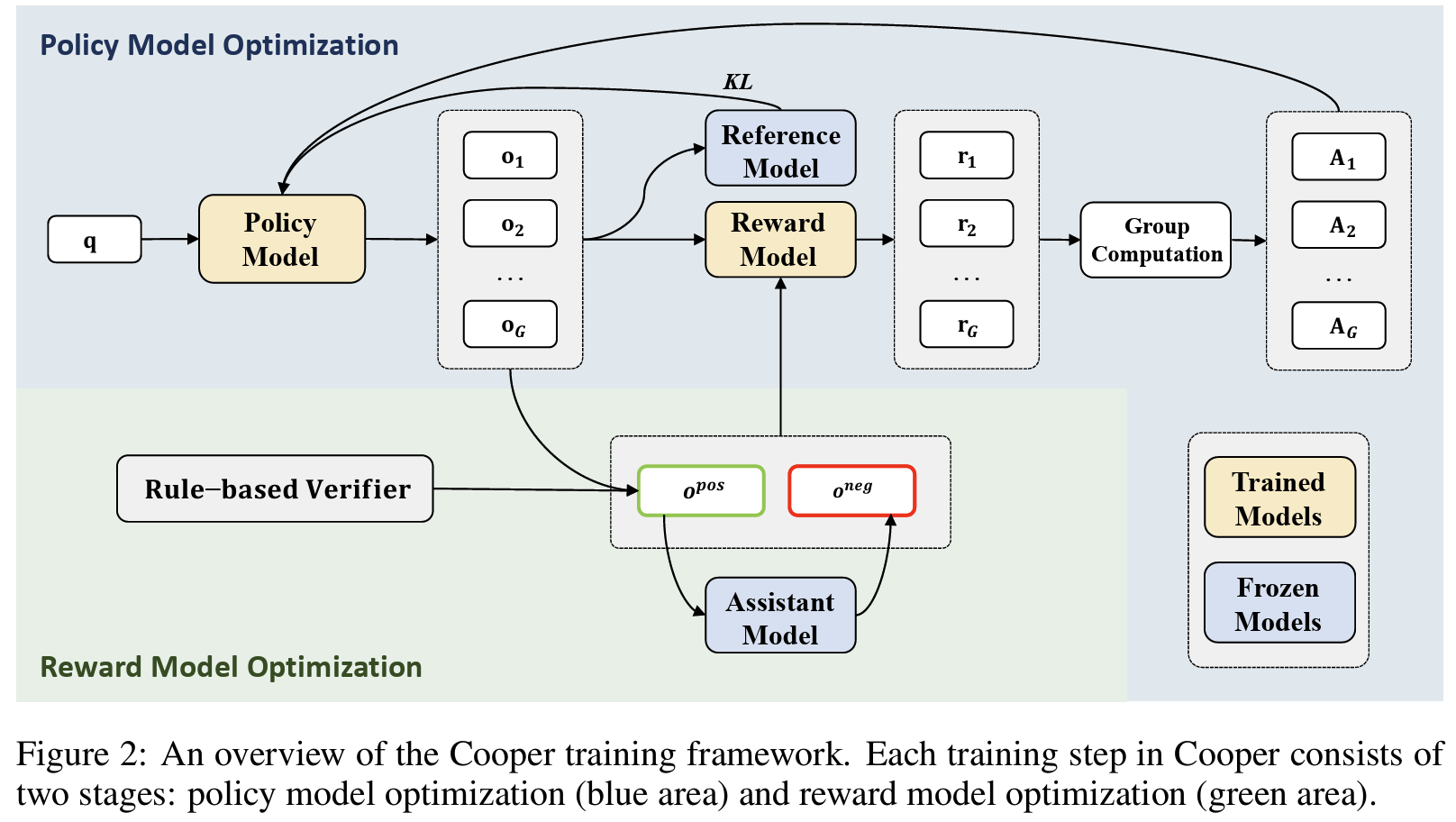
- Cooper
Algorithm 1- Stage 1. Policy optimization w/GRPO
- 각 q + a에 대해, 현재 Policy로 G개의 rollout 샘플, 각 rollout을 VerifyRM(q, a, oᵢ)로 평가 (=r),
- reward를 group별로 normalization + KL divergence penalty
- Stage 2. Reward model optimization w/ contrastive learning
- positive samples:
Table 1의 결과에 따라, rule-based verifier(높은 precision)의 정답 - negative samples: assistant LLM이 pos sample 보고 negative reasoning 생성 > rule-base verifier가 검증하여 확인
- objectives: pos와 neg 간 마진 최대화
- positive samples:
- Stage 1. Policy optimization w/GRPO
Effects
- Experiment setup:
- RL dataset: DeepMath (자원 문제로 10k 이하로 sampling)
- Base policies: Qwen2.5-1.5B-Instruct, Llama-3.2-1B-Instruct
- Target tasks: math problems; GSM8K, SVAMP, MATH500, OlympiadBench-EN (OB-EN), Math Odyssey
- Baselines: (a) Rule: Math-Verify as reward; (b) Model: VerifyRM-1.5B fixed (no updates).
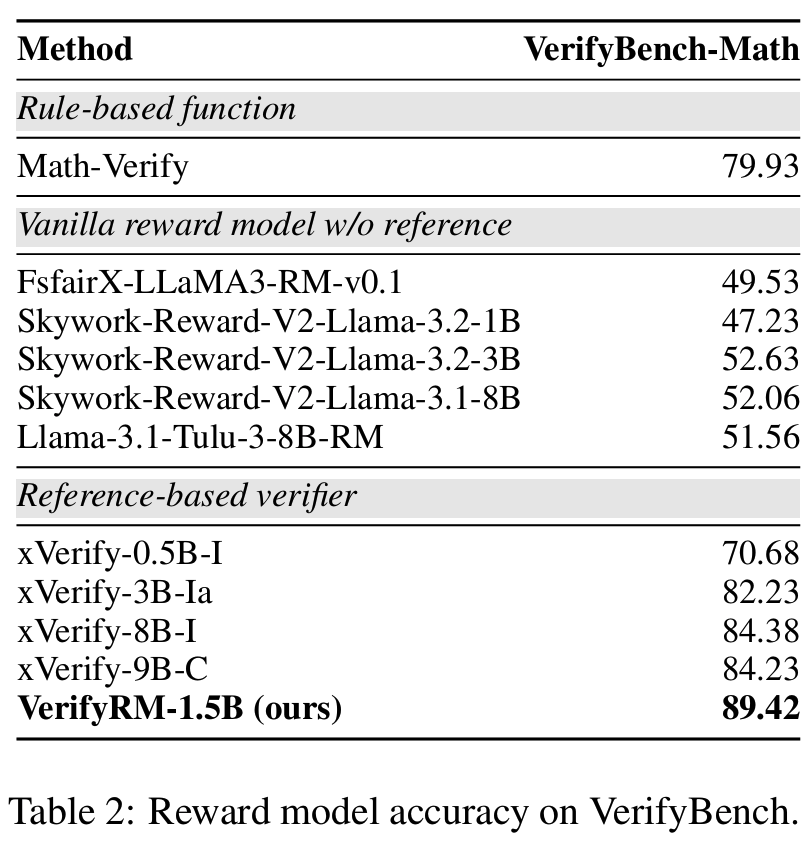
Table 2VerifyRM이 쓸만한가? » yes- VerifyBench 기준 제안한 VerifyRM-1.5B가 baselines대비 최고 정확도 (89.42%) 달성
- vs. rule-based baselines: Math-Verify (79.93%)
- vs. reference-based baselines : xVerify-9B-C (84.23%)
- xVerify: 모델이 낸 답과 최종 답이 수학적으로, 자연어 해설로도, 기호로도 동치인지 확인한다고
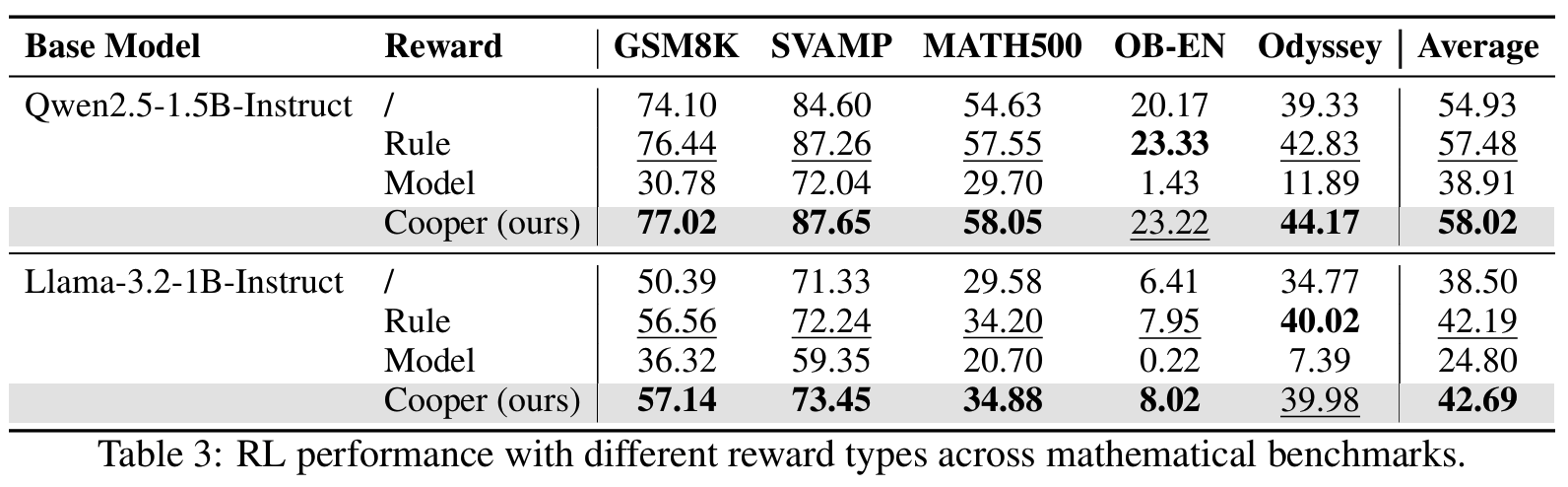
Table 3Cooper가 쓸만한가? (target tasks 결과, main results) » yes- Qwen2.5-1.5B 기준 5개 task 평균: base 54.93 > rule-based 57.48 > static RM (model-based) 38.91 > Cooper 58.02
- 특히 Odyssey에서 강력한 성능
- Llama-3.2-1B도 마찬가지 경향 확인
- Qwen2.5-1.5B 기준 5개 task 평균: base 54.93 > rule-based 57.48 > static RM (model-based) 38.91 > Cooper 58.02
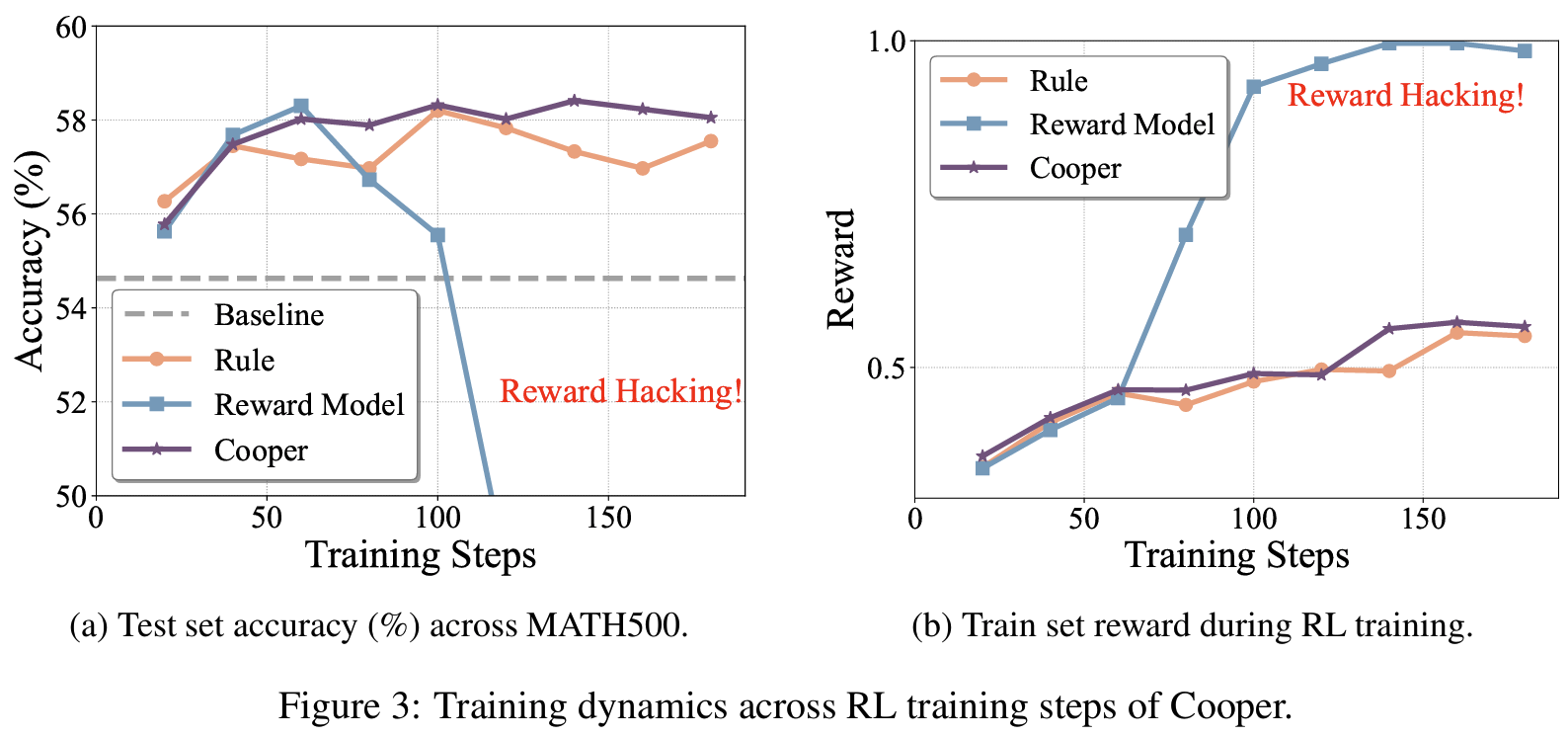
Figure 3Training Dynamics (=reward hacking의 증거)- overoptmization: 앞선 static RM의 실패를 reward로 확인해보면 실제 training에서 spikes가 거의 1에 가까운 반면 test에서 성능은 step ~120쯤에서 급락
- 제안 방법의 강건성: Cooper의 training reward가 훨씬 stable 하고 실제 정확도도 높은 결과로 이어짐
Personal note. 읽어보고 나니 대단히 특별한 내용은 아닌데, preliminary experiments로 의도하고자 하는 방향의 모티베이션을 얻어서 data 구축에 참고했다는 흐름은 설득력있는 주장으로 잘 포장한 것처럼 보이게 합니다. 좁은 target space를 상정한 것 같기는 한데 다른 Task Reward shaping 관점으로 쉽게 확장해봄직은 할 것으로 보입니다. LLM 시대에서 리더보드에 줄세우는 방식이 아직도 가능한 테스크로 수학문제풀기가 거의 유일한건지에 대한 궁금증도 드네요.