GraphRAG-R1: Graph Retrieval-Augmented Generation with Process-Constrained Reinforcement Learning
Meta info.
- Authors: Chuanyue Yu, Kuo Zhao, Yuhan Li, Heng Chang, Mingjian Feng, Xiangzhe Jiang, Yufei Sun, Jia Li, Yuzhi Zhang, Jianxin Li, Ziwei Zhang
- Paper: https://arxiv.org/abs/2507.23581
- Affiliation: Beihang Univ., HKUST, Huawei, Nankai Univ.
- Published: July 31, 2025
TL; DR
RL(GRPO)에 2가지 constrained reward(RPA + CAF) 적용하여 GraphRAG agent 학습 > 검색할 때 입력으로 triplet과 자연어 하이브리드 활용하여 multi-hop QA에서 큰 성능 향상 확인
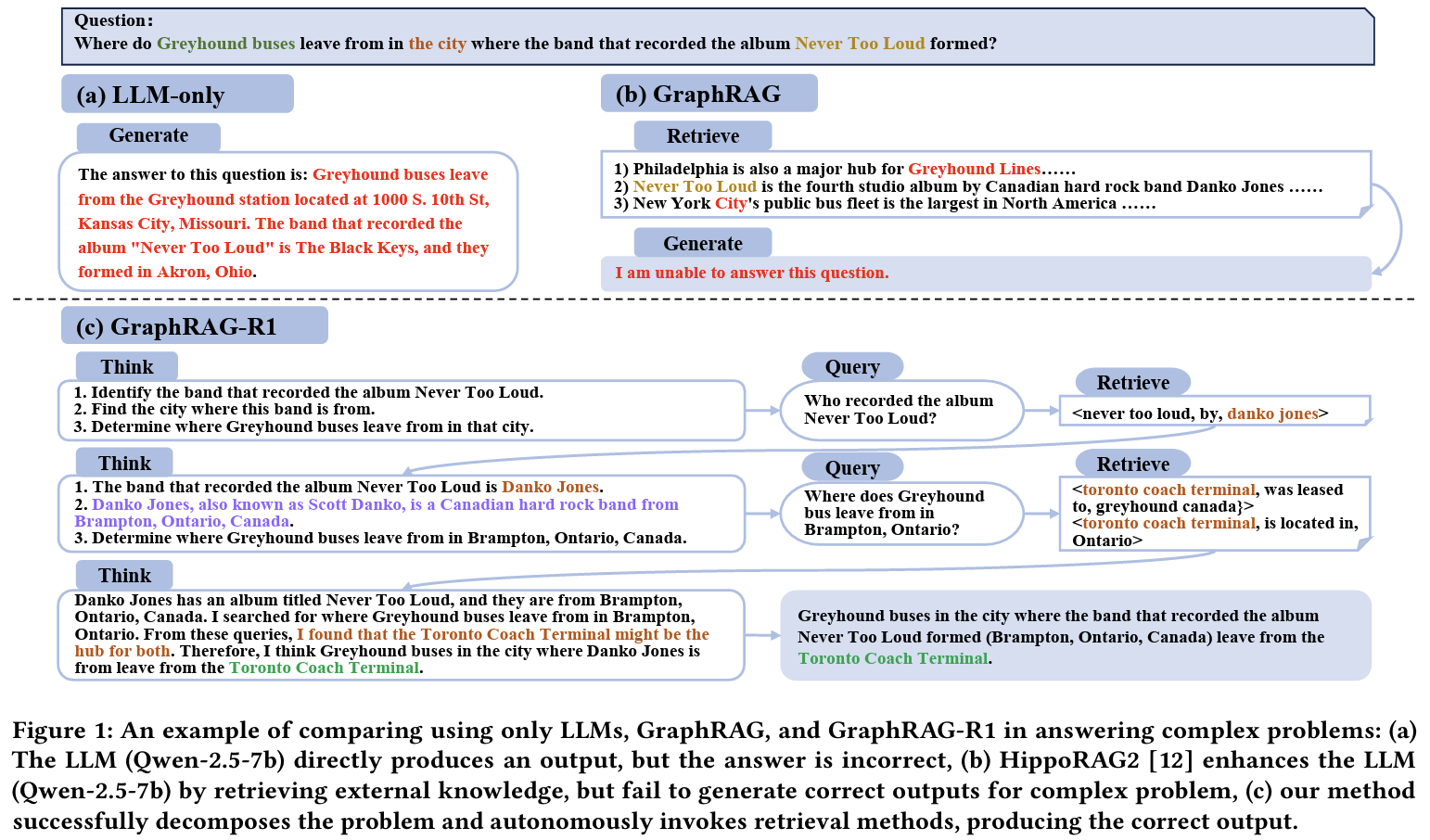
Background
- GraphRAG 대두되고 있긴 하지만, 여전히 multihop QA에서 실패 : 단순 유사도 기반 검색이나 heuristics에 의존
- RAG에서의 RL: DeepSeek-R1이나 R1-Searcher등에서 RL이 think-then-retrieve 능력을 향상시킬 수 있다는 보고.
Problem States
GraphRAG에서 RL 적용 가능성 확인 > multi-hop QA 성능 개선
- graphRAG의 heuristics에 대한 한계
- outcome-only based reward의 hacking 우려 > 얕은 검색 혹은 반대로 over-thinking 으로 이어질것
- long-input으로는 비용 한계
Suggestions
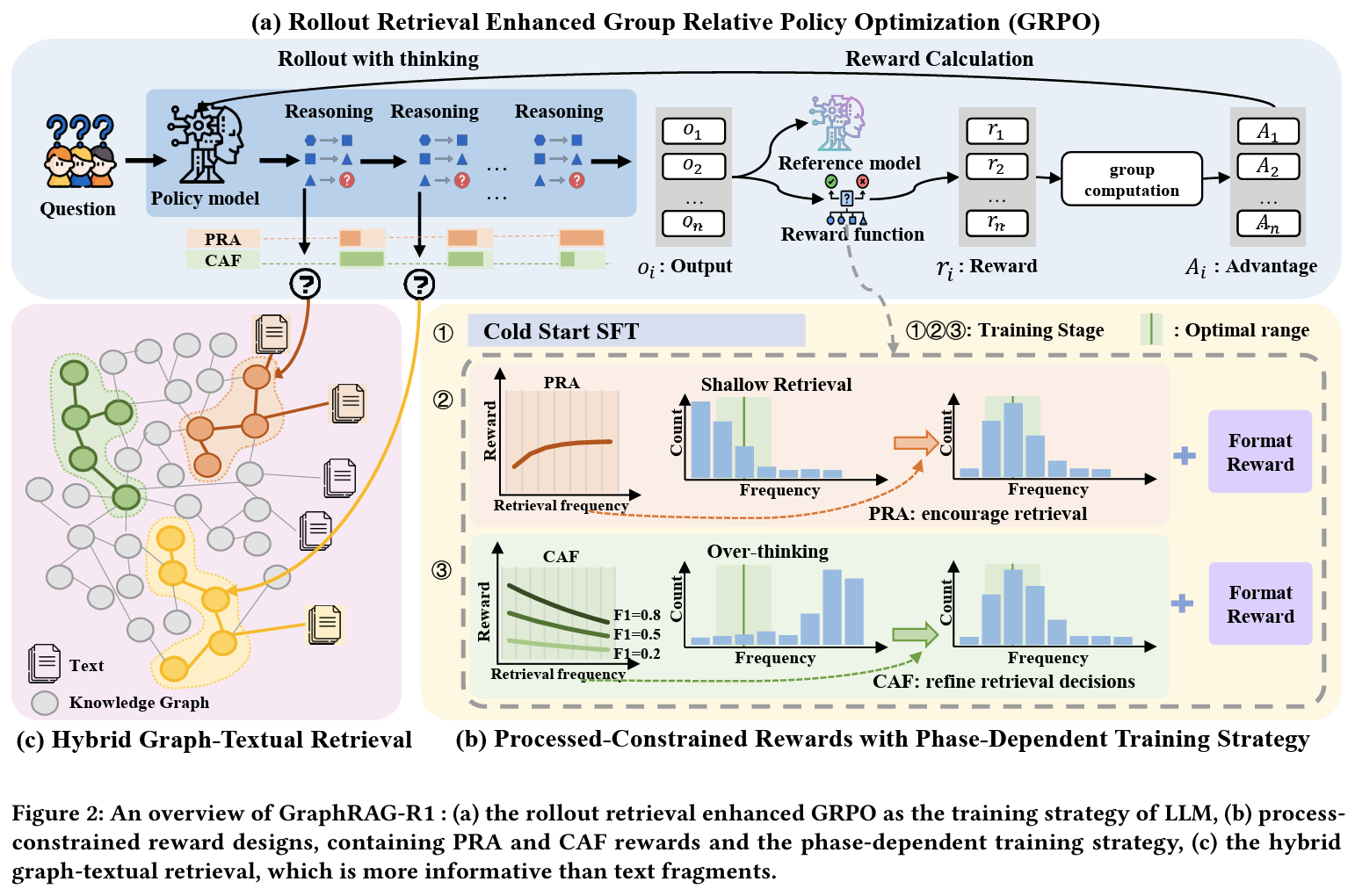
- GRPO 개선: w/Rollout-with-Thinking + Retrieval-Masked Loss
- Rollout-with-Thinking:
- 바로 검색하는 게 아니라 reasoning 과정에서 적절한 시점에서 필요할 때
…</end_of_query> 생성 - 검색 실행: (논문에서 기본 설정은 HippoRAG2)
-
검색 결과의 text snippet은 다음 추론을 위해 < begin_of_documents >…< end_of_documents > 사이에 추가
- 바로 검색하는 게 아니라 reasoning 과정에서 적절한 시점에서 필요할 때
- Retrieval-Masked Loss
- text snippet은 mask하여 gradient 계산에서 제외
- 모델 스스로가 생성한 Reasoning에 대해서만 optimization
- 의도: retriever의 외부 텍스트에 의존 없이 안정적 학습, 검색 결과를 활용하는 방식만 배움
- Rollout-with-Thinking:
- Reward Design: Process-Constrained Rewards:
- format: Retrieval calling format이 맞을 때 0.5 리워드 부여
- PRA(Progressive Retrieval Attenuation): 첫 호출은 기본 보상 크게 주고, 이후 검색 호출마다 지수적으로 decay된 보상 누적 = shallow retrieval(너무 적은 검색과 무한 검색 동시에) 방지
- CAF(Cost-Aware F1): over-thinking 방지하고자 최종 답의 f1-score에 검색 횟수 * 비용 패널티 > 같은 정확도라면 검색 횟수가 적을수록 보상 향상
- 3-phrase training: cold-start SFT(retriever calling 학습) > behavior shaping with format +PRA (검색을 언제 얼마나 자주 할지) > smartness optimization w/CAF (정답 정확도와 효율 균형)
- hybrid retrieval: triple + 자연어 모두 활용하여 학습과 추론 모두에 활용
Effects
- Experimental Setup: 주로 Qwen-2.5-7B에 retriever로 HippoRAG2
- target datasets: HotpotQA, 2Wiki, MuSiQue, PopQA
- metrics: F1, SBERT similarity, LLM-as-Judge Accuracy
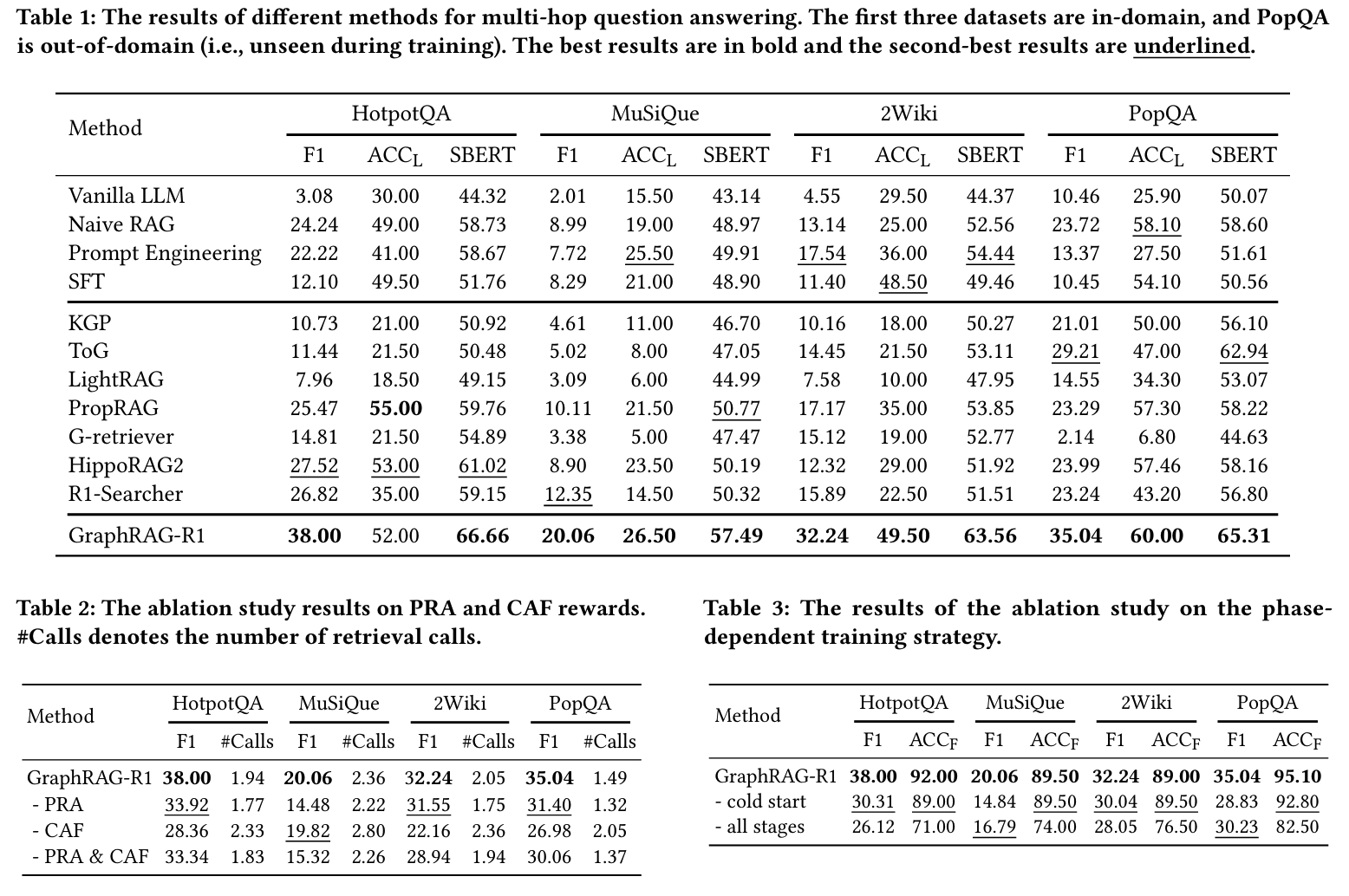
- 모든 데이터셋에 대해 성능 향상 확인
Tab 1 - ablation
- PRA 제거: call 수는 줄지만 검색 depth가 얕고 F1 하락
- CAF 제거: call 수 과도한데 F1 향상 없음
- 2-reward 모두 필수적. reward 결합시 task 난이도에 따른 검색 조정 효과
- Hotpot/PopQA에서는 call 수 감소
- MuSiQue/2Wiki에서는 call 수 증가
- phrase-training: cold start 생략하든 모든 loss/reward 한번에 하는 것보다 제안한 3단계 방식이 가장 우수
- 초기에 format과 calling 방식을 배우는게 최적화에 유리
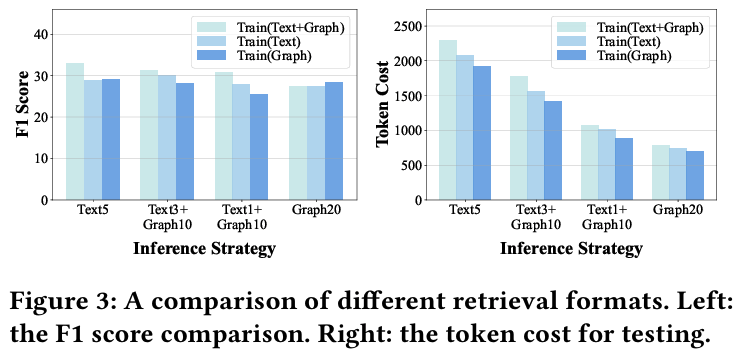
- hybrid 방식의 검색이 학습면에서도 best F1, triple 비율 높이면 F1 살짝 손실은 있지만 토큰을 크게 벌 수 있음
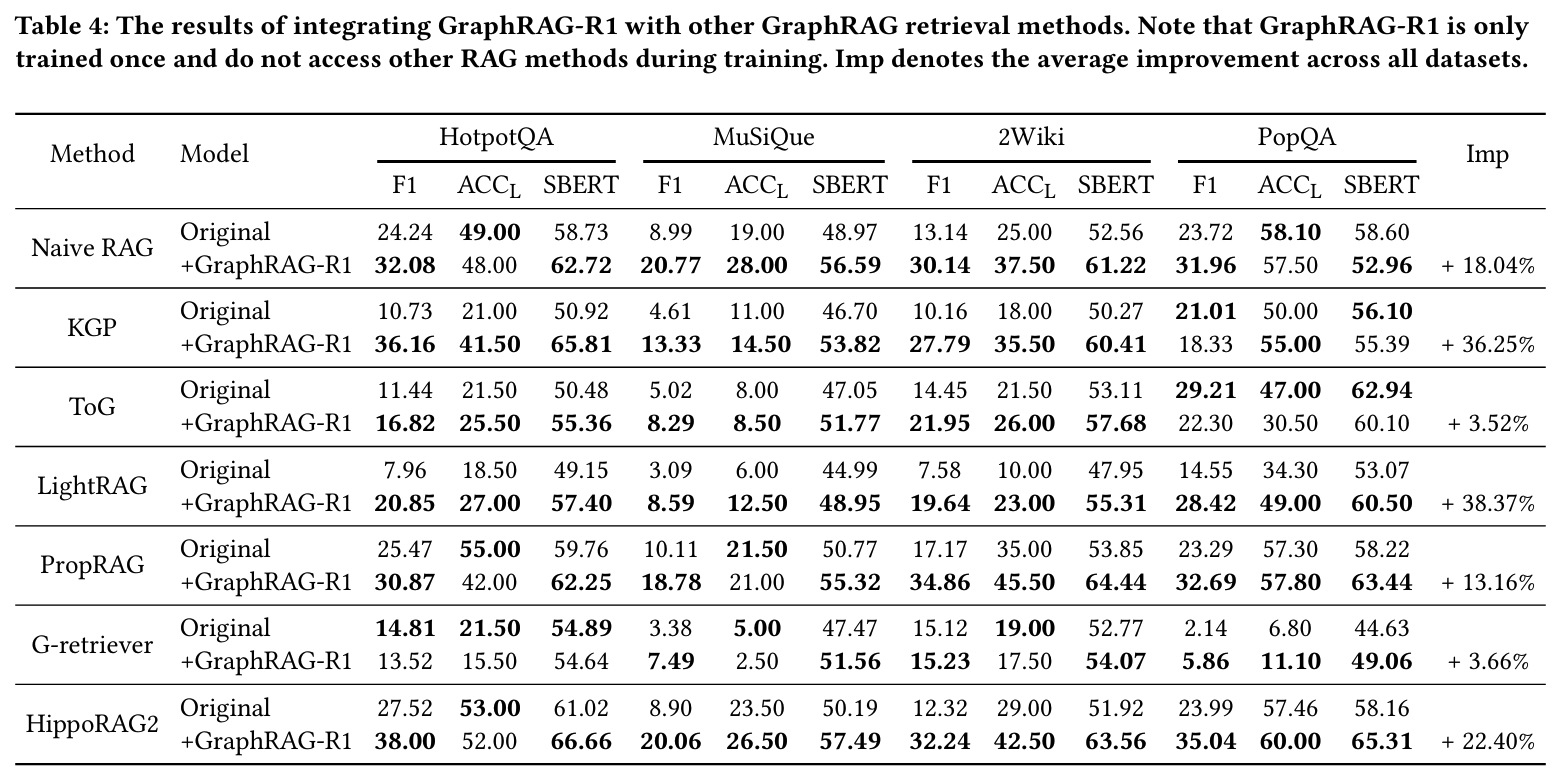
- backbone이나 retriever 뭐로 바꿔도 제안 방식의 강건한 개선효과 확인
Personal note. 화자 정보를 효율적으로 보게 하기 위해서 RL을 활용할 수 있는가? 에 대해 고민해보려고 RL을 task에 적용하는 페이퍼 눈에 띄는 것 위주로 확인하고 있는데, optimization 단계에서 일부를 mask하거나, loss를 다층위로 설계해서 단계를 주는 방식은 유익한 것으로 보입니다.