Reasoning with Sampling: Your Base Model is Smarter Than You Think
Meta info.
- Authors: Aayush Karan, Yilun Du
- Paper: https://arxiv.org/pdf/2510.14901
- Affiliation: Harvard Univ.
- Published: October 16, 2025
TL; DR
추가 학습 없이 단순 MCMC 기반 샘플링만으로 LLM의 base model이 RL로 post-training된 모델 수준의 추론 능력 낼 수 있다.



Background
- LLM의 RL기반 post training이 일반화되고, 이렇게 학습된 모델은 수리추론, 코딩 등에서 눈에 띄는 성능을 보이지만
- 그렇다고 RL 등이 새로운 능력을 학습하게 하는 건 아니라는 견해도 등장 [He et al. 2025, Yue et al. 2025]
- RL은 그냥 SFT 모델이 이미 잘하는 high-likelihood reasoning 경로를 집중적으로 선택하게 만들 뿐
Problem States
추가 학습 없이도, 단순히 샘플링 과정만 조정해서 RL 수준의 reasoning 능력을 끌어낼 수 있는가?
- RL 비용이 비싸니, inference-time only로 base model을 shape하게 resampling하기
Suggestions
Power sampling via MCMC
- power distribution sampling : 목표 분포 p_\alpha인 p(x)p(x)가 >1인 경우 이미 모델이 높게 평가한 후보 (토큰 확률이 높음)가 강화 ; test-time 전용 Sampling 알고리즘
- 절차: 문장을 block 단위(B) 로 잘라서 점진적으로 확률분포 p_\alpha에 맞게 샘플링
- 길이 T짜리 전체 문장을 한 번에 샘플링하는 것은 계산 불가하므로, 대신 B길이만큼의 k개 블록으로 나눔
- (k개 블록) * (각 블록별 길이 B)까지의 joint likelihood(=p_\alpha)를 중간목표로 설정
- k=0에서 시작(짧은 문장부터)해서
- k=1에서 첫 block 기준으로 p_\alpha에 맞게 샘플링
- 점점 긴 시퀀스를 위해 앞은 prefix로 고정 > 뒤에 B길이씩 붙여가면서 MCMC*로 모델링
- 최종 T 만큼 길이에 근사
- 각 block마다 Metropolis–Hastings(MH) 절차로 “resample > accept/reject”.
- 이미 만들어진 문장 중 일부 토큰을 무작위로 골라서 p_prop으로 resample해보고
- 그 결과가 p(x)보다 더 높은 likelihood면 교체(accept) 아니면 유지(reject)
- p_prop: base model에 sampling temperature를 1/\alpha 로 설정해서 약간 sharpen된 버전으로사용. 즉 새 후보 문장을 생성하는 제안 분포
- 절차: 문장을 block 단위(B) 로 잘라서 점진적으로 확률분포 p_\alpha에 맞게 샘플링
- ) MCMC: 복잡한 분포에서 샘플을 직접 뽑기 어려울 때, 조금씩 움직이면서 점진적으로 그 분포를 따라가도록
- Markov Chain- 이전 상태에 의존해서 새 후보 생성
- Monte Carlo- 랜덤샘플링 반복수행
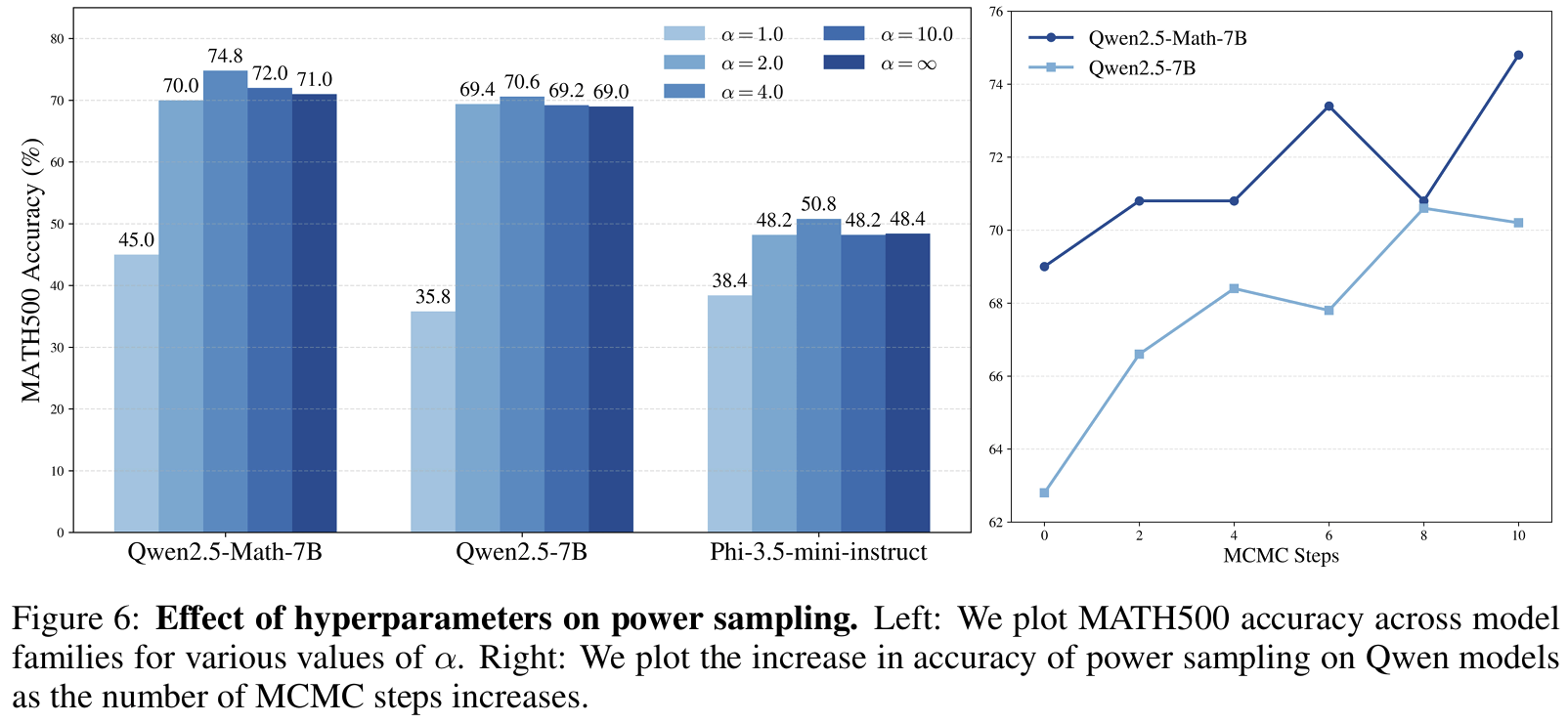
- test-time scaling: MCMC step 수 N 가 추론시간과 성능의 트레이드-오프를 결정하는데, 약 8.8배 추가 계산량이 필요하지만 training-free라는 점을 강조
Fig 6
- low-temperature sampling과 차이: 각 시점의 조건부 sharpen 수행하는 반면, power dist.는 미래 토큰 전체 likelihood trajectory를 고려한 샘플링
Effects
- Experimental setup:
- backbone: Qwen2.5-Math-7B / Qwen2.5-7B / Phi-3.5-mini-instruct
- baseline: Base / Low-temperature sampling / Power Sampling (제안방식) / RL-post training (GRPO)
- benchmark: MATH500(수리추론), HumanEval(코딩), GPQA (과학), AlpacaEval 2.0
- domain 구분;
- in-domain: RL이 학습된(또는 post-training된) 태스크와 동일한 영역
- ood: RL 학습 때 보지 못한, 도메인이 다른 영역
- Results
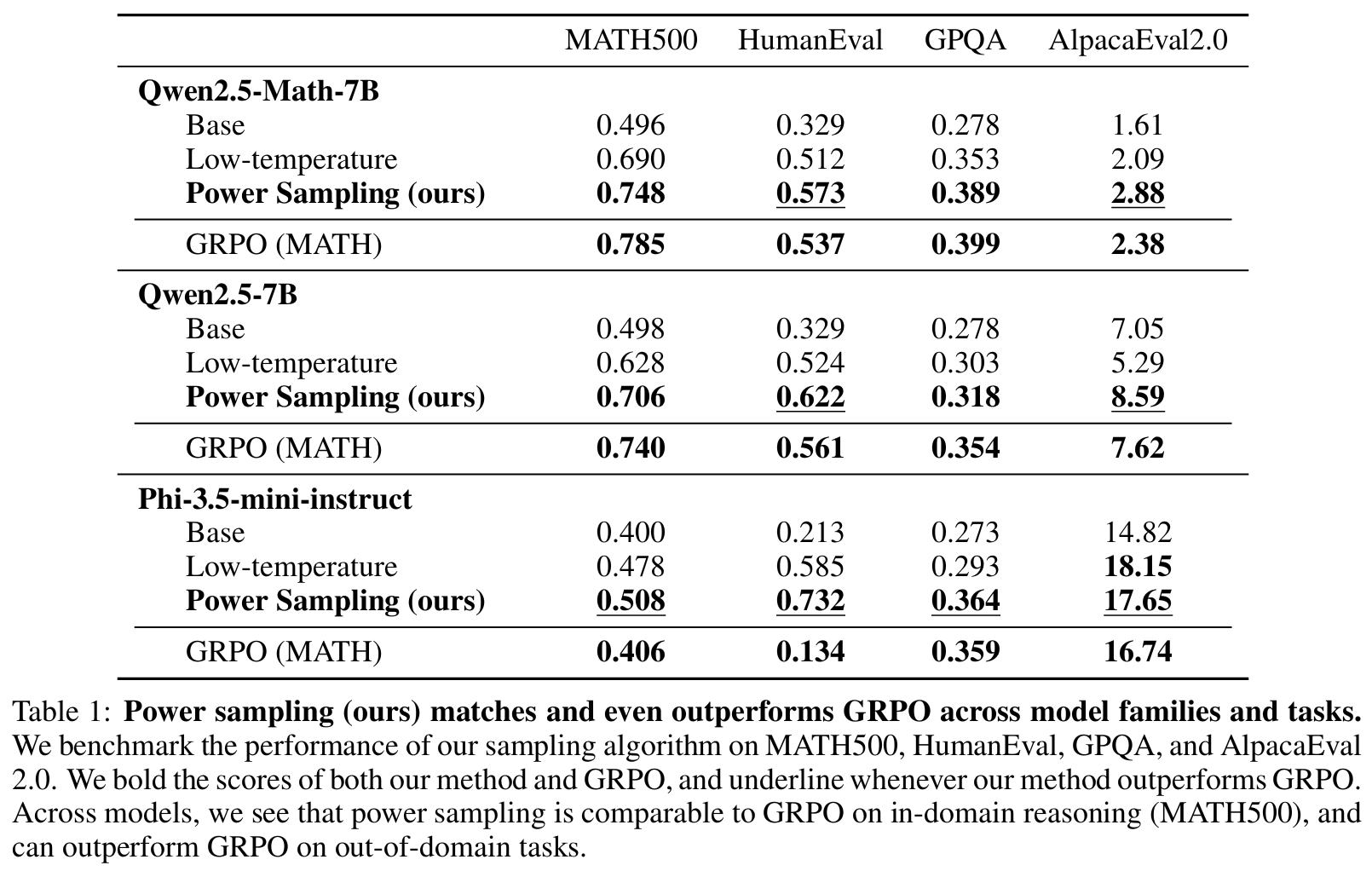
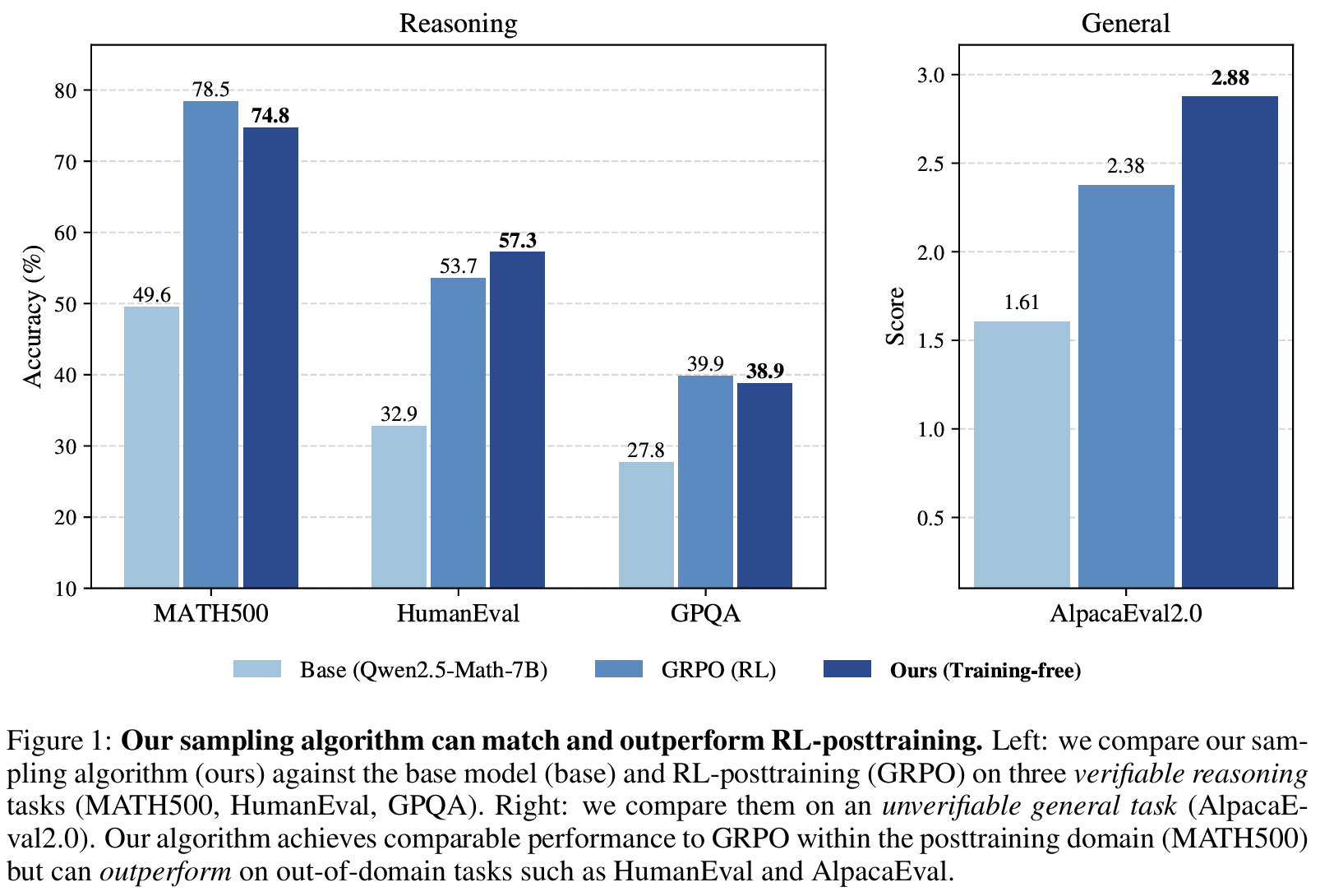
Tab 1/Fig 1Training 없이도 single-shot reasoning 성능 개선 확인- in-domain인 MATH500은 제안 방식이 RL 수준에 근접하고
- ood 측면에서 HummanEval, AlpacaEval이 RL 보다 3-5%p 향상
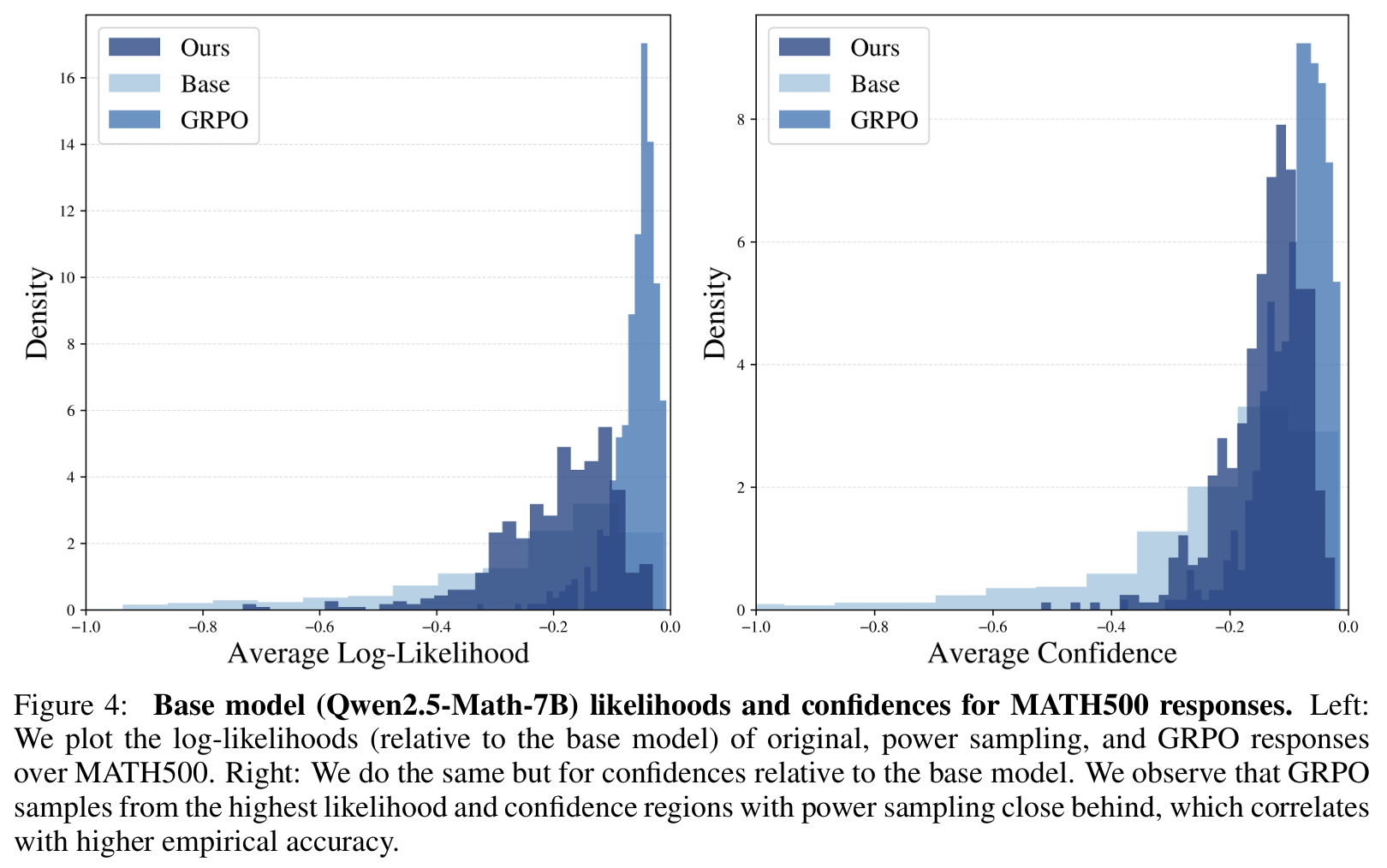
Fig 4Likelihood 확인- Power Sampling은 base model의 높은 likelihood 구간을 폭넓게 커버
- GRPO는 최고 likelihood 근처로 집중(=mode collapse)
- Confidence 분포 역시 GRPO가 가장 높지만 너무 뾰족..
- Power Sampling은 그 바로 아래 수준으로 균형적 sharpness 유지.
- Power Sampling은 base model의 높은 likelihood 구간을 폭넓게 커버
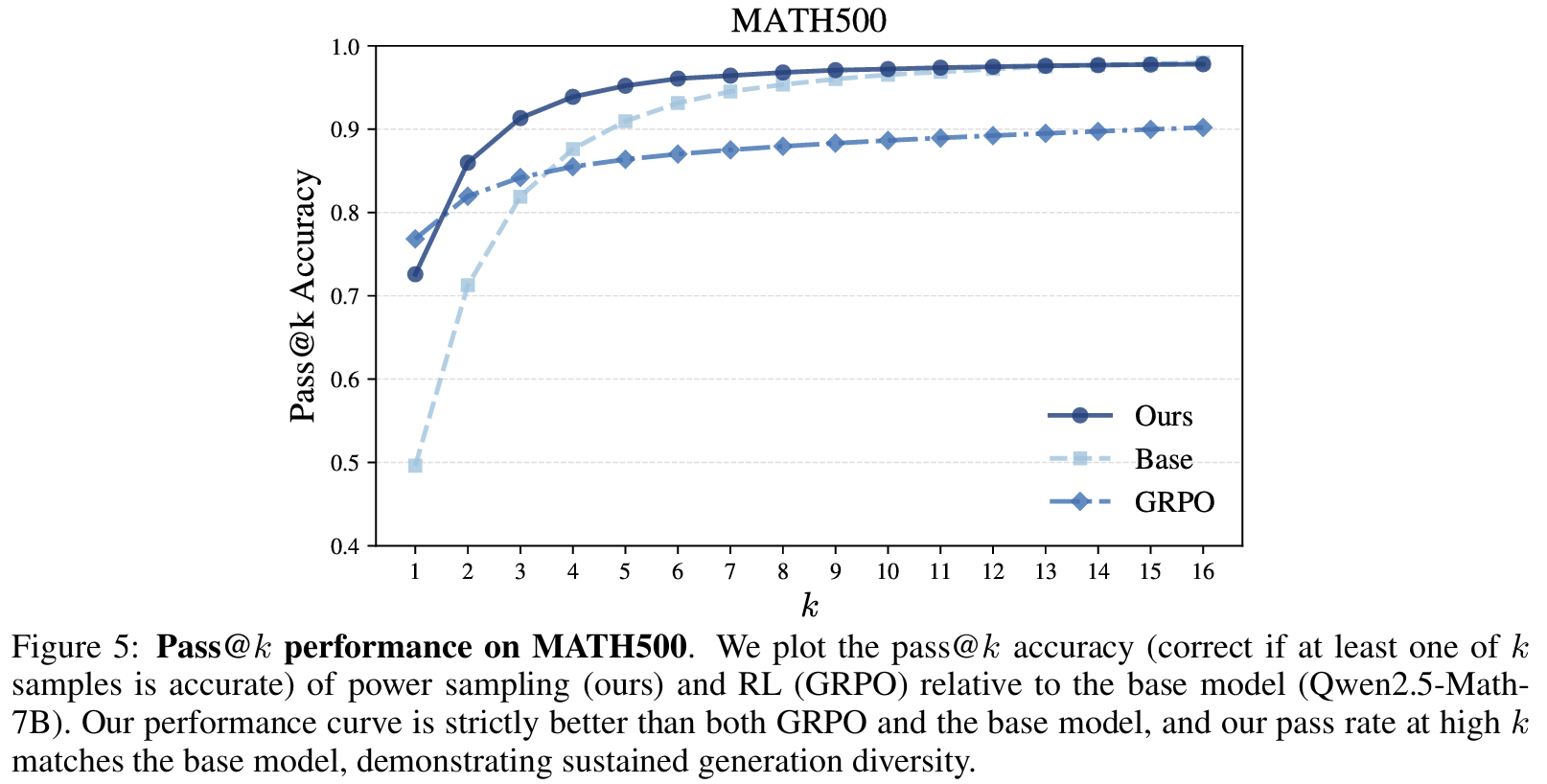
Fig 5Diversity 확인: single + multi-shot 모두 개선- pass@k (multi-shot) 성능: 제안이 가장 좋았고 GRPO>base 순
- RL은 diversity collapse로 k높이면 성능 정체됨
- 제안 방식은 k>1에서 꾸준히 상승됨 확인
- pass@k (multi-shot) 성능: 제안이 가장 좋았고 GRPO>base 순
Personal note. test-time에서 memory나 preference 제어 가능성에 대해서 고민해보다가 읽어봤는데, 아이디어가 단순해보여서 공유드립니다. reasoning은 학습의 영역이 아니라 탐색 문제라고 (거칠게) 요약한 페이퍼라고 볼 수 있겠습니다. 어제 세미나에서 언급한 문제 역시 일부 상통하는 부분이 있던 점도 흥미로웠고요. 수학적 해석도 나름 꼼꼼하긴 한데, 왜 high-likelihood sampling이 reasoning correctness와 연결되는지는 아직 설명이 부족하다는 인상이 있었습니다. (causation이 부족한데 어쩔 수 없다고 느낍니다.)