Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Meta info.
- Authors: Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li†, Jingrui He, Ed H. Chi, Chi Wang, Shuo Chen, Fernando Pereira, Wang-Cheng Kang, Derek Zhiyuan Cheng
- Paper: https://arxiv.org/pdf/2511.20857
- Affiliation: Google DeepMind, UIUC
- Published: November 25, 2025
TL; DR
LLM Agent가 test-time에 과거 경험을 스스로 진화시키며 학습하는 능력을 평가하는 streaming benchmark Evo-Memory 제안, ExpRAG / ReMem 같은 baseline을 제안하여 경험 재사용 기반 성능 향상에 대한 비교 평가 기반 제시
Background
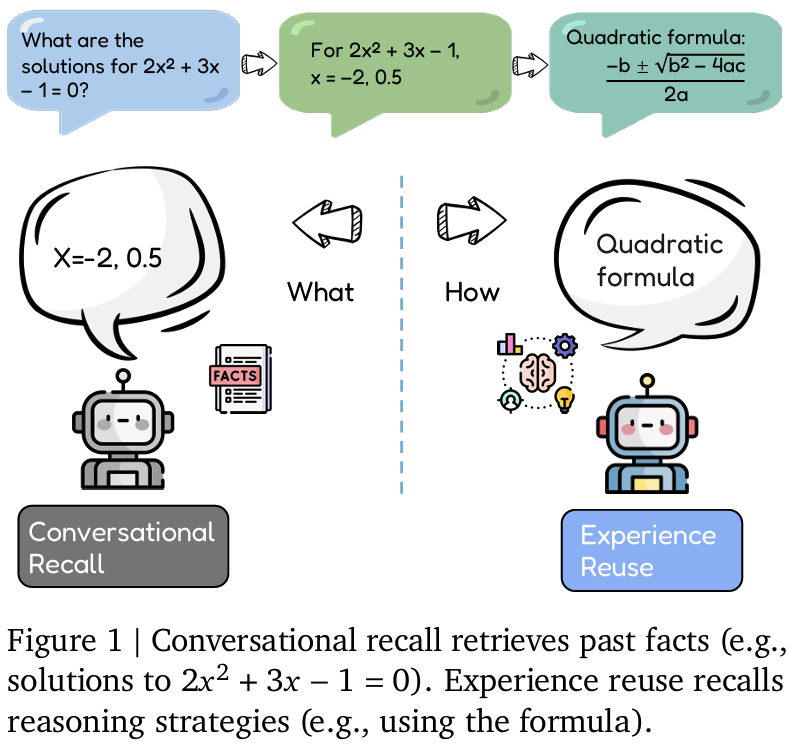
- LLM의 memory system은 대중화되었는데도 여전히 기억을 recall하는 것을 중심으로 연구 진행
- recall한 기억을 잘 쓰는지에 대한 평가 부족: test-time learning / self-evolving memory 등 실제로 잘 찾아다가 써서 성능이 오르는지
- recall: 과거 정보를 단순히 다시 말할 수 있는 능력
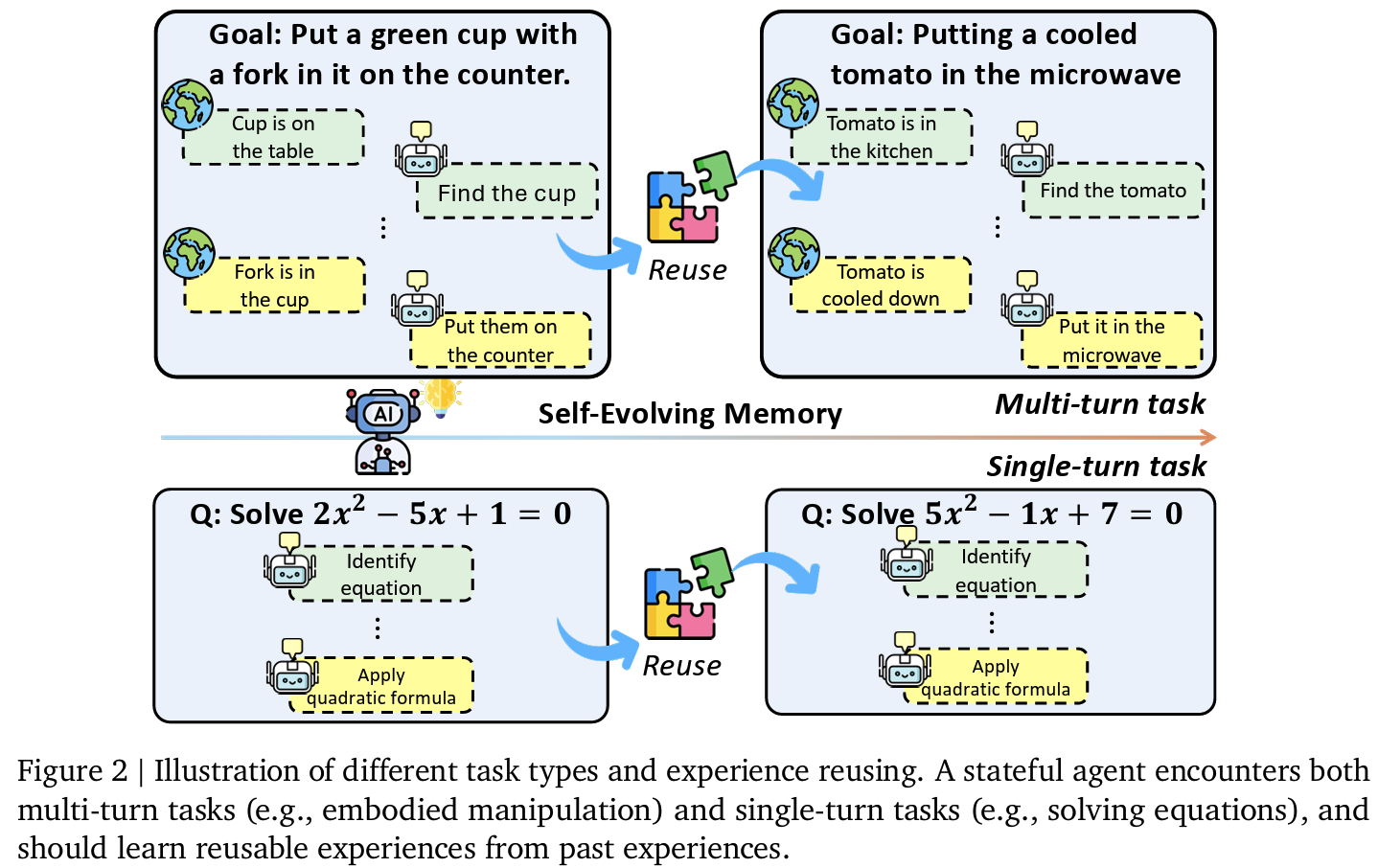
- (experience) reuse: 과거 작업에서 학습한 해결 전략을 새로운 작업에 적용하는 능력
Problem States
reuse를 평가하기위한 benchmark 제시
- 정적 memory: append > retrieval로 스스로 memory를 재구성하거나 개선하지는 않음 (초기 구조를 유지)
- memory가 어떻게 성능을 변화시키는지는 확인되지 않음
- TTL(test time learning)에 대한 memory 연구 부족
- Research Objective
- 다양한 도메인을 아우르는 streaming bench 제시
- 여러 메모리 구조를 같은 프로토콜에서 비교
- test-time에서 agent가 진짜 learn하는지 정량적 측정 시도
Suggestions
- memory-augmented agent 공식화 : RAG, LTM(long-term memory), workflow memory등 통합
- t 시간에 x_t 입력에 대해
- R: retrieval module → R_t = R(M_t, x_t)
- C: Context Constructor → \tilde{C}_t = C(x_t, R_t)
- F: base LM → prediction \hat{y} = F(\tilde{C}_t)
- U: Memory Update pipeline
- 경험 m_t = h(x_t, \hat{y}_t, f_t) 생성
- M_{t+1} = U(M_t, m_t)
- dataset을 streaming taks로 재정의
- 각 벤치마크는 task trajectory \tau = {(x_1,y_1),…, (x_T,y_T)} 로 변환 가능, 이전 task 경험 이후 task 성능에 영향 미치도록 설계
- ExpRAG: Experience-level RAG
- baseline으로서 각 경험을 structured text로 정리 > 현재 task와 유사한 과거 경험을 top-k retrieval, Memory update는 append 방식
- 과거 task를 ICL context처럼 활용하는 방식으로 설계
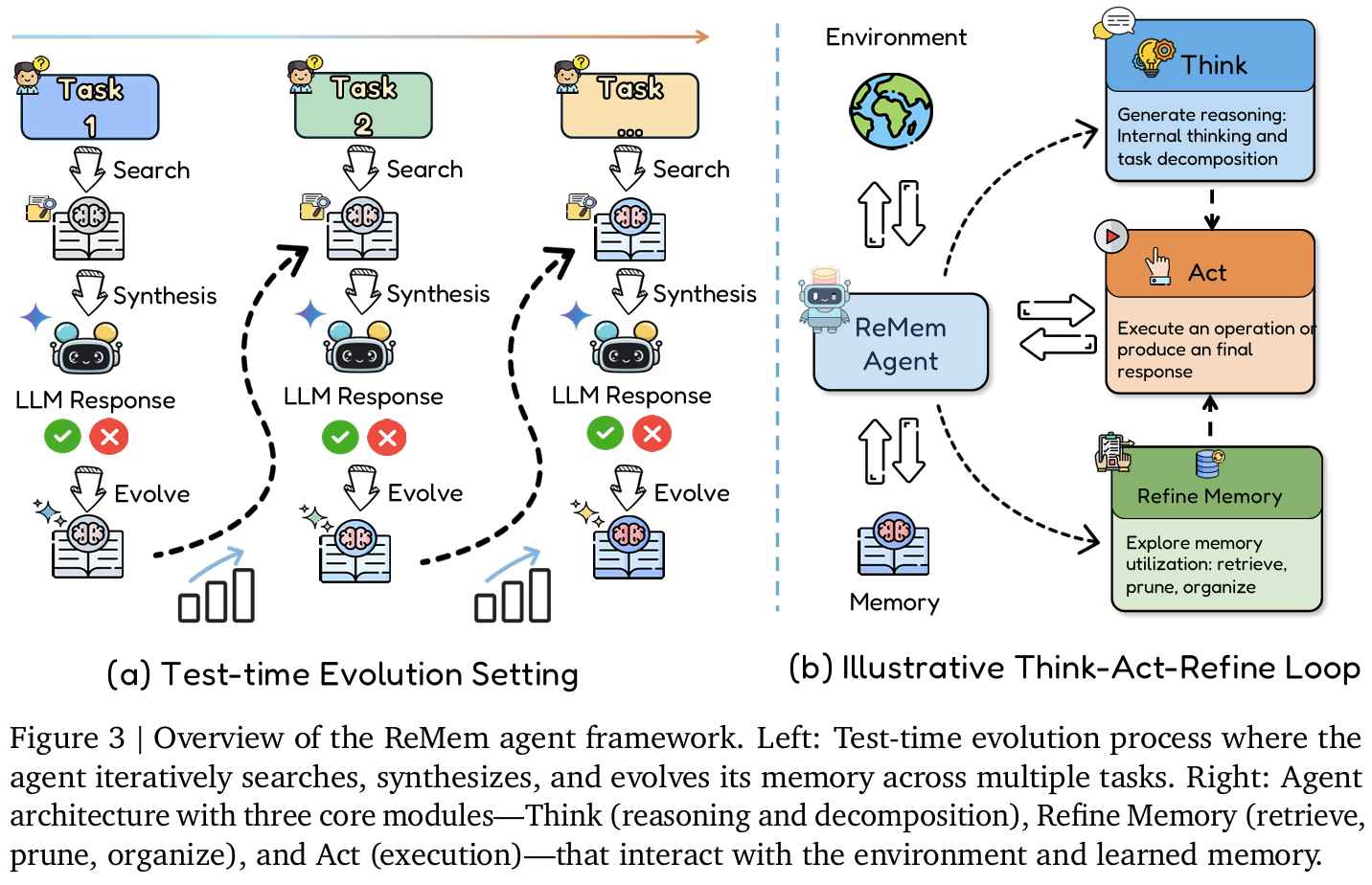
- ReMem: Think–Act–Refine 기반 Self-Evolving Memory Agent
- ReAct 구조 확장하여 Refine (=메모리 조작) action 추가
- Think: 내부 reasoning 생성
- Act: API/tool/최종 답변 행동
- Refine: memory 검색 요약 삭제 재구성 수행
- 각 상태에서 agent가 action 중 한가지 택1
- ReAct 구조 확장하여 Refine (=메모리 조작) action 추가
Effects
- Tasks
- single-turn reasoning + QA: MMLU-Pro, GPQA-Diamond, AIME-24/25, ToolBench
- multi-turn interaction(AgentBoard): AlfWorld, BabyAI, ScienceWorld, Jericho, PDDLBench
- Backbone: Gemini 2.5 Flash, Flash-lite, Pro / Claude 3.5 Haiku, 3.7 Sonnet
- Baseline:
- no-memory: History, ReAct, Amem
- Adaptive memory: SelfRAG, MemOS, Mem0, LangMem
- Procedural memory: DC(Dynamic Cheatsheet), AWM
- 제안(ours): ExpRecent, ExpRAG, ReMem
- Metrics:
- Accuracy, Exact Match
- Success Rate(S), Progress(P)
- 평균 step 수
- Task sequence robustness
- Task similarity correlation
- Memory pruning ratio
- Results:
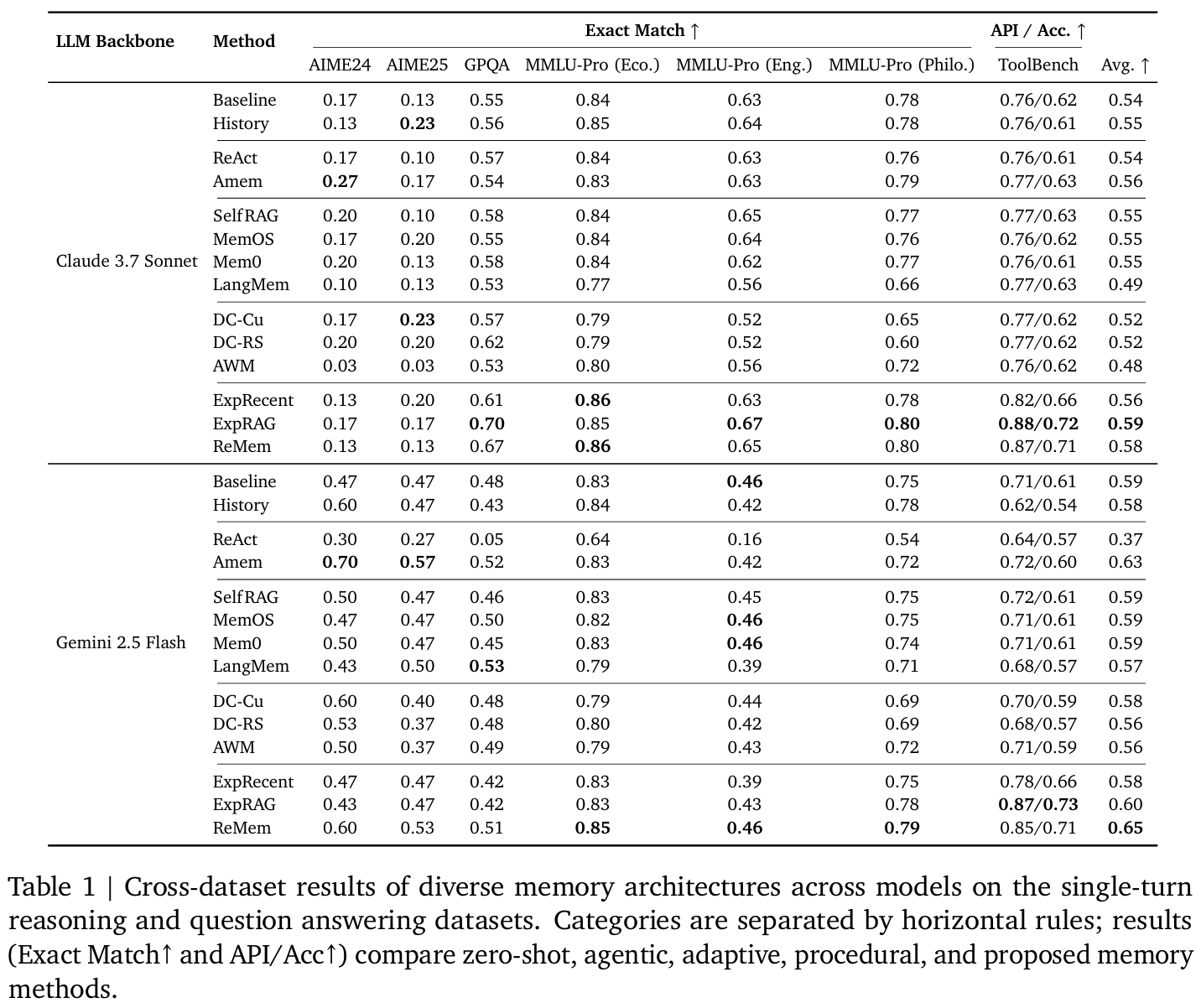
Tab1single-turn- ExpRAG, ReMem이 대부분 베이스라인보다 높은 평균 상회
- ReAct는Gemini Flash 등에서 오히려 성능 저하
- ReMem은 backbone 안타고 모두에서 최고 혹은 그에 준하는 성능
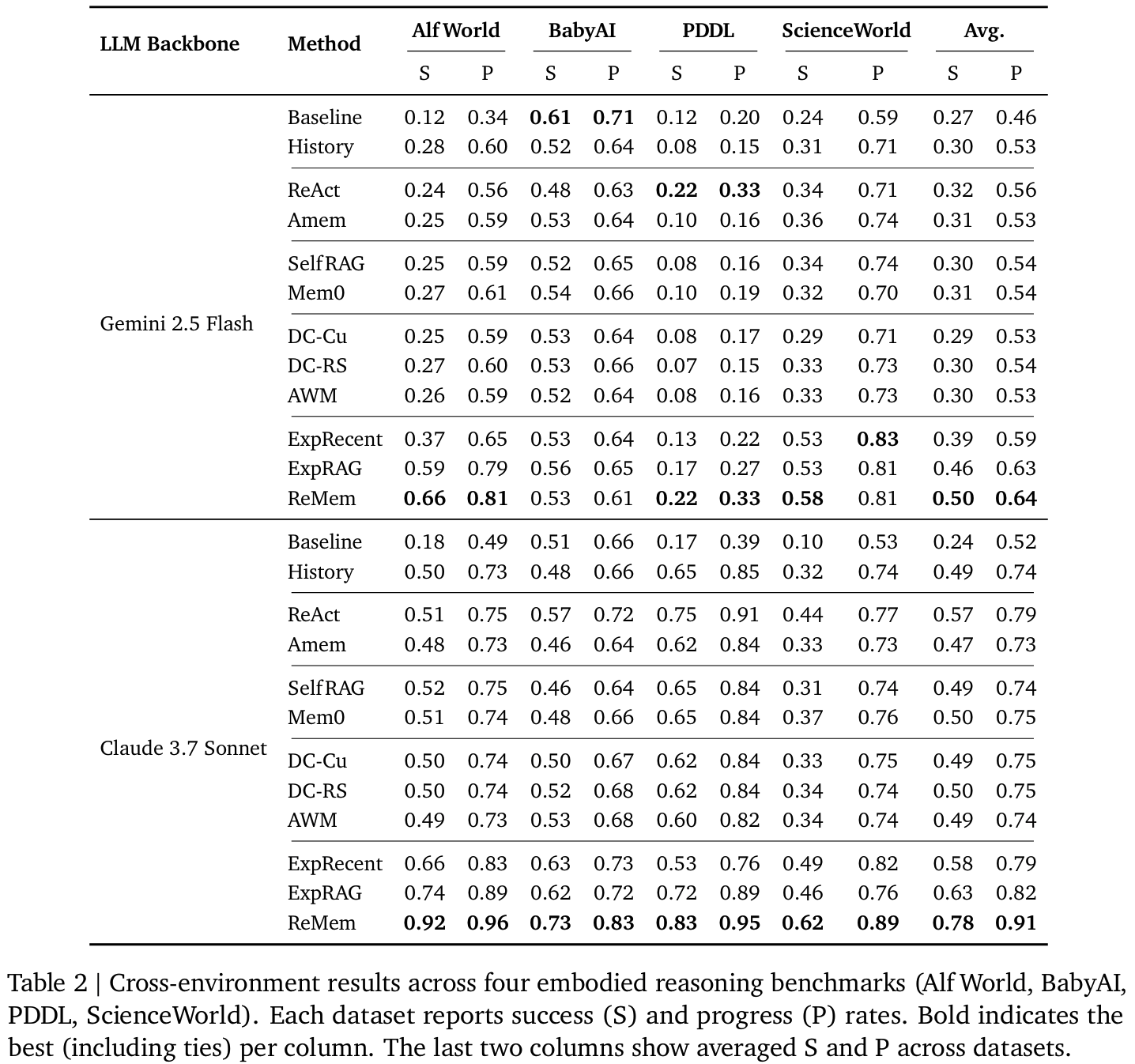
Tab2multi-turn- ReMem이 AlfWorld, ScienceWorld 등에서 큰 폭 성능 향상
- task 수행 위한 길이가 길수록 self-evolving memory 효과 증대
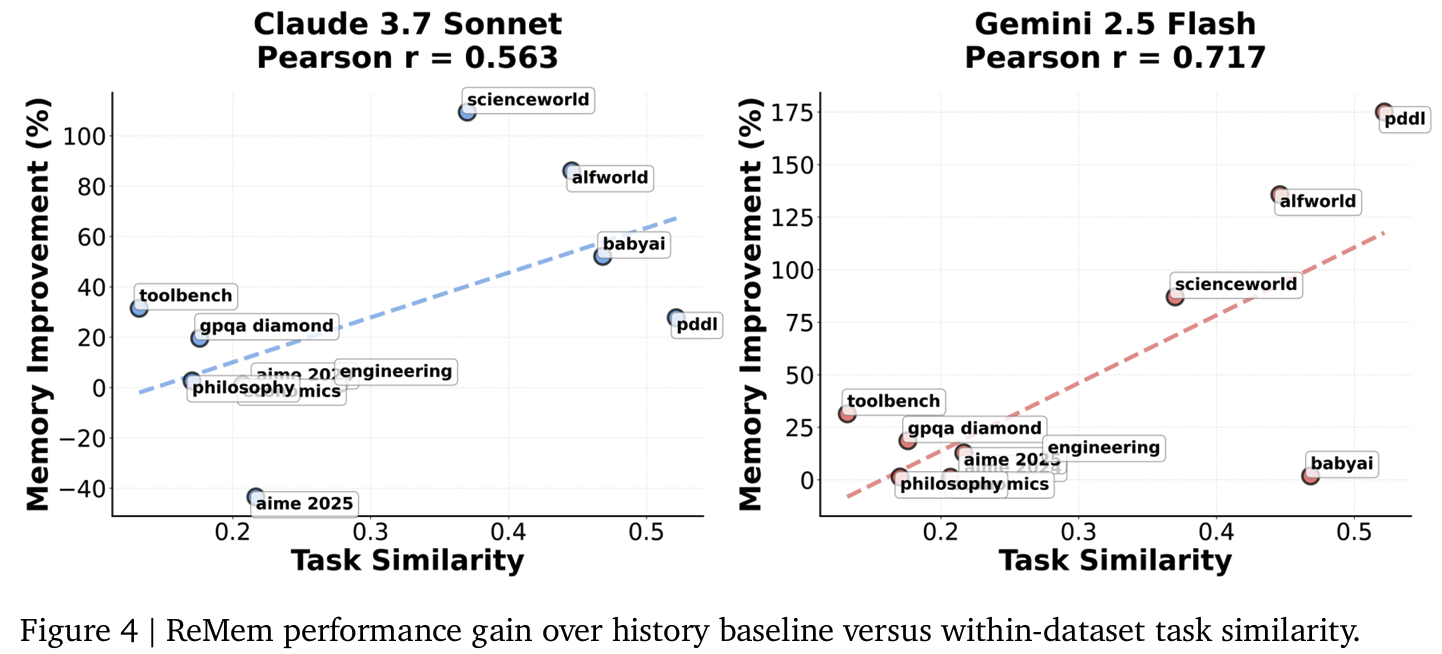
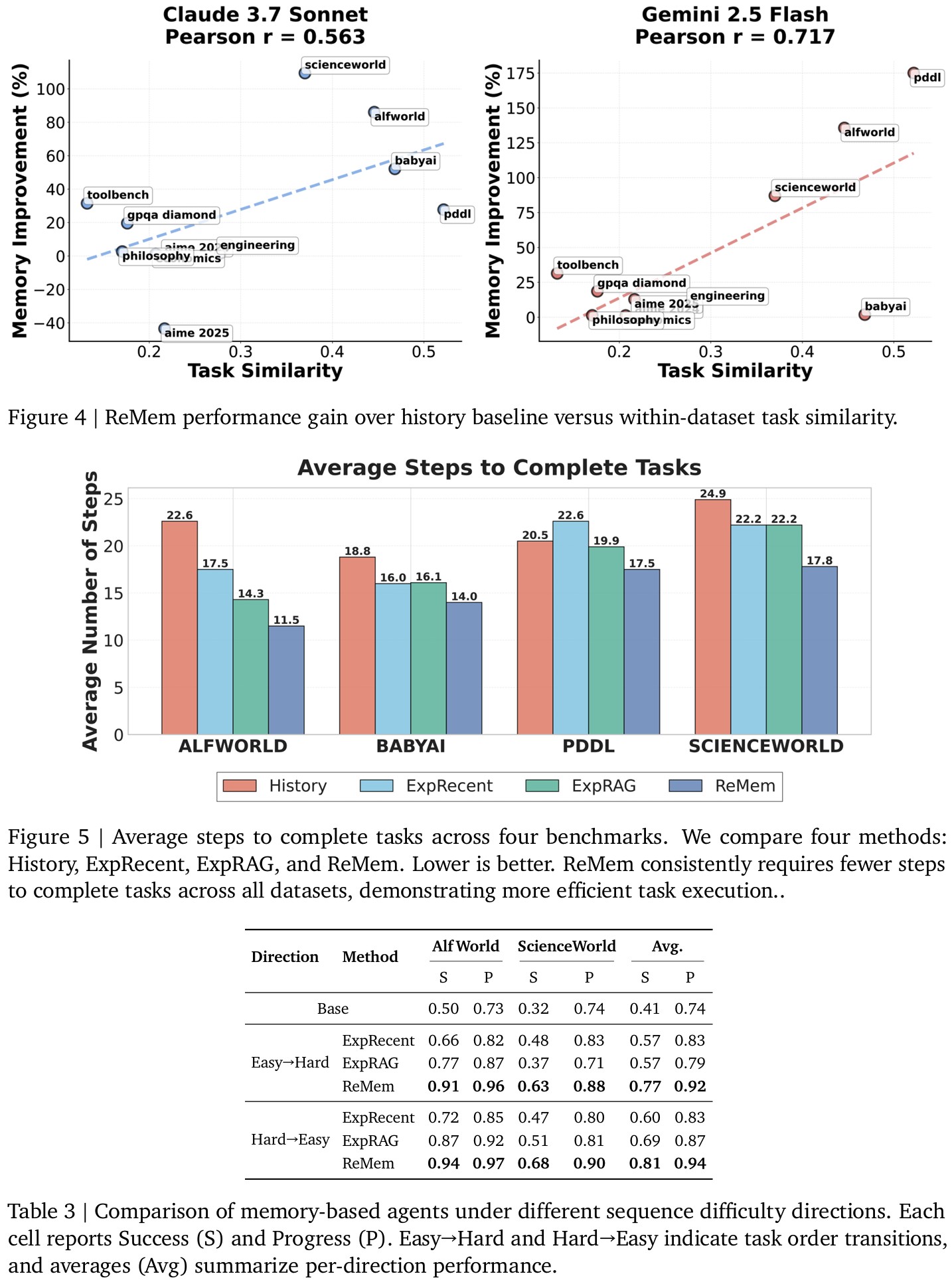
Fig4메모리가 언제 유익한가: Task similarity가 높을수록 (동질적인 게 반복될수록) ReMem의 성능 향상이 크다Fig5모든 bench에서 ReMem은 평균 step 수 감소 = 더 효율적Tab3Task 순서를 쉬운거 > 어려운거 혹은 그 반대에 대해- baseline들이 불안정한거에 비해 ReMem은 두 경우 모두 높은 robustness 유지
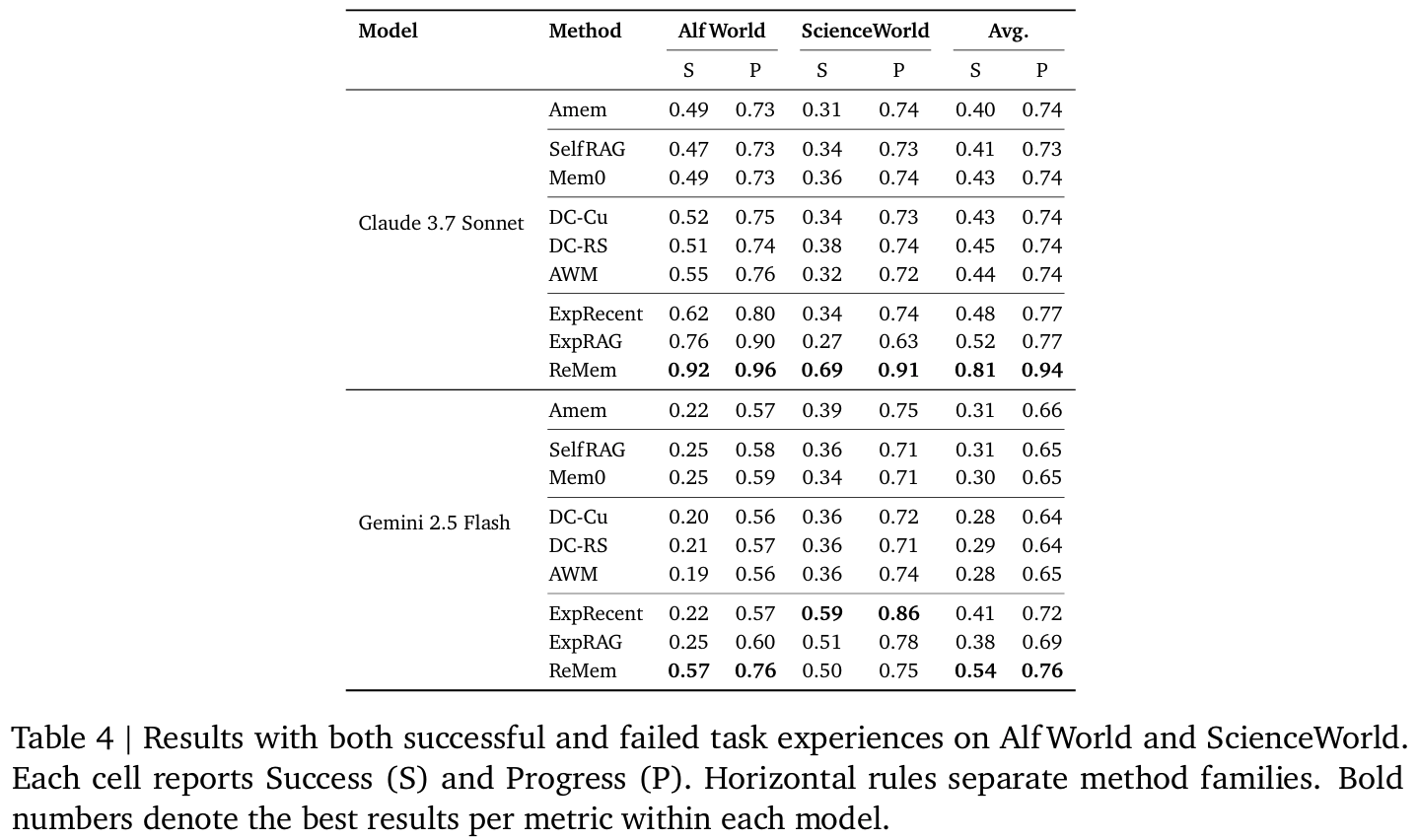
Tab4다른 메모리 베이스라인들은 noise에 취약하나, ReMem은 실패 경험이 섞여도 S/P가 안정적 유지- refine action이 이를 정제하는 듯
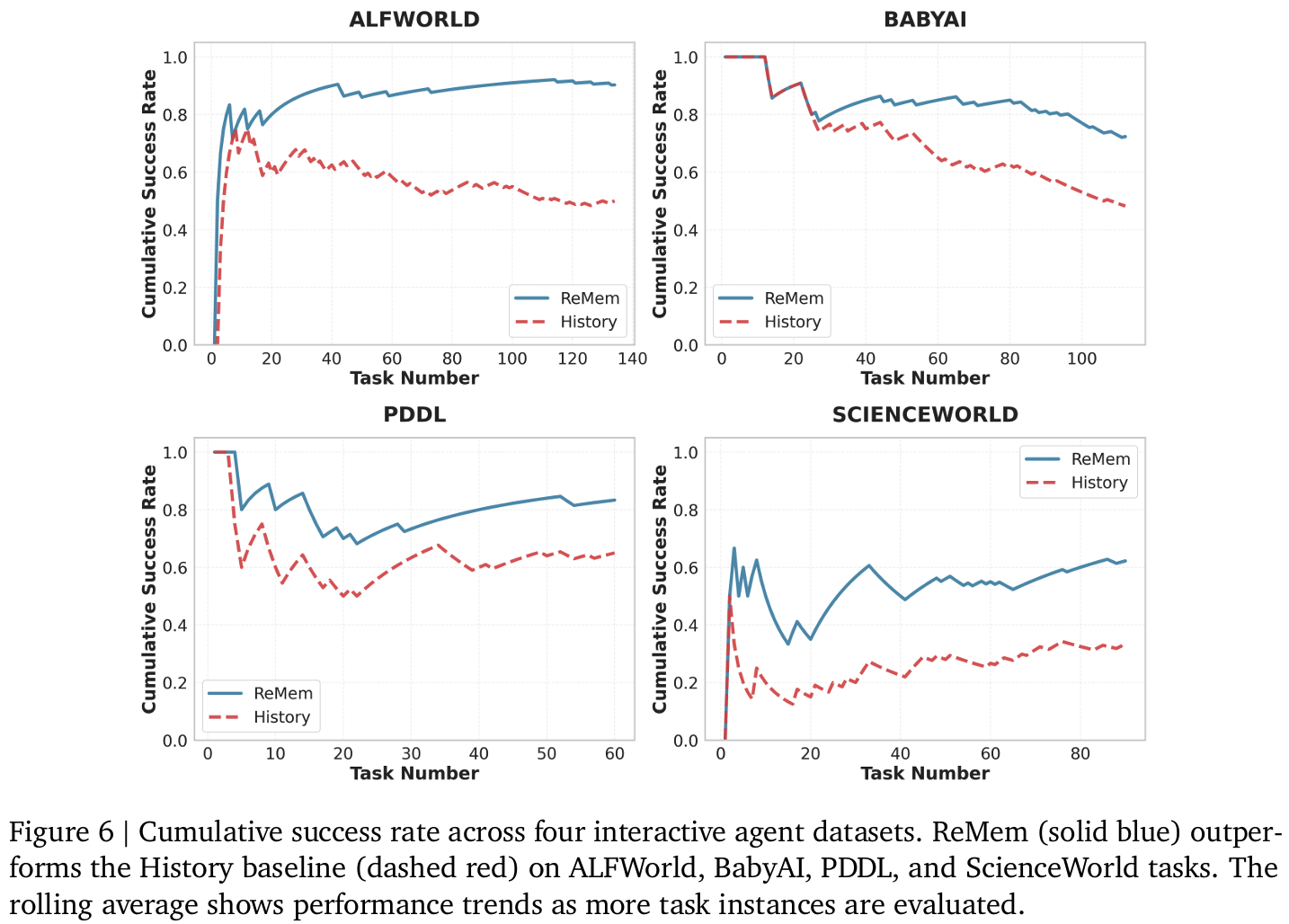
Fig6task index가 증가할수록 ReMem의 cumulative success curve가 History보다 꾸준히 높음 = test-time learning의 직접적 증거라 주장Fig7Dataset에 따라 pruning 비율 차이:- GPQA ~36.8% : 다양도가 높아 메모리 필터링 필요한데 반해
- AIME ~10-17% :경험 대부분 재사용 가능했다고
Personal note. 지금까지 memory 연구에서 답답하고 모호하던 부분들이 이 논문을 통해서 한결 정리된 느낌을 받았습니다. 현재 연구의 baseline 선정하는 과정에서 참고해볼만했고, 디테일도 더 살펴보겠습니다.