WAIT, WAIT, WAIT… Why Do Reasoning Models Loop?
Meta info.
- Authors: Charilaos Pipis, Shivam Garg, Vasilis Kontonis, Vaishnavi Shrivastava, Akshay Krishnamurthy, Dimitris Papailiopoulos
- Paper: https://arxiv.org/pdf/2512.12895
- Affiliation: MIT, Microsoft Research, Univ. of Wisconsin-Madison
- Published: December 15, 2025
TL; DR
Reasoning 모델의 looping은 decoding artifact만이 아니라 learning errors가 greedy/low-temp에서 증폭되며 발생, temperature는 loop를 줄이지만 근본 원인을 고치지 못해 불필요하게 긴 CoT를 생성한다.
Background
- reasoning 중심 LLM들이 inference time scaling을 축으로 강조하고 있고, 오래 생각할수록 정확도가 나아진다는 경향 주장
- 가정: 더 많은 reasoning path == 더 나은 reasoning, 즉 reasoning quality는 inference-time compute에 비례한다는 전제
- CoT, scratchpad, verifier-assisted decoding, test-time compute scaling, …
- LRM들의 repetition, 무의미한 self-check, wait loop 등에 대한 한계에 대해 표면적 해석에만 그침
- decoding artifact, sampling instability, repetition penalty 부족 등
Problem States
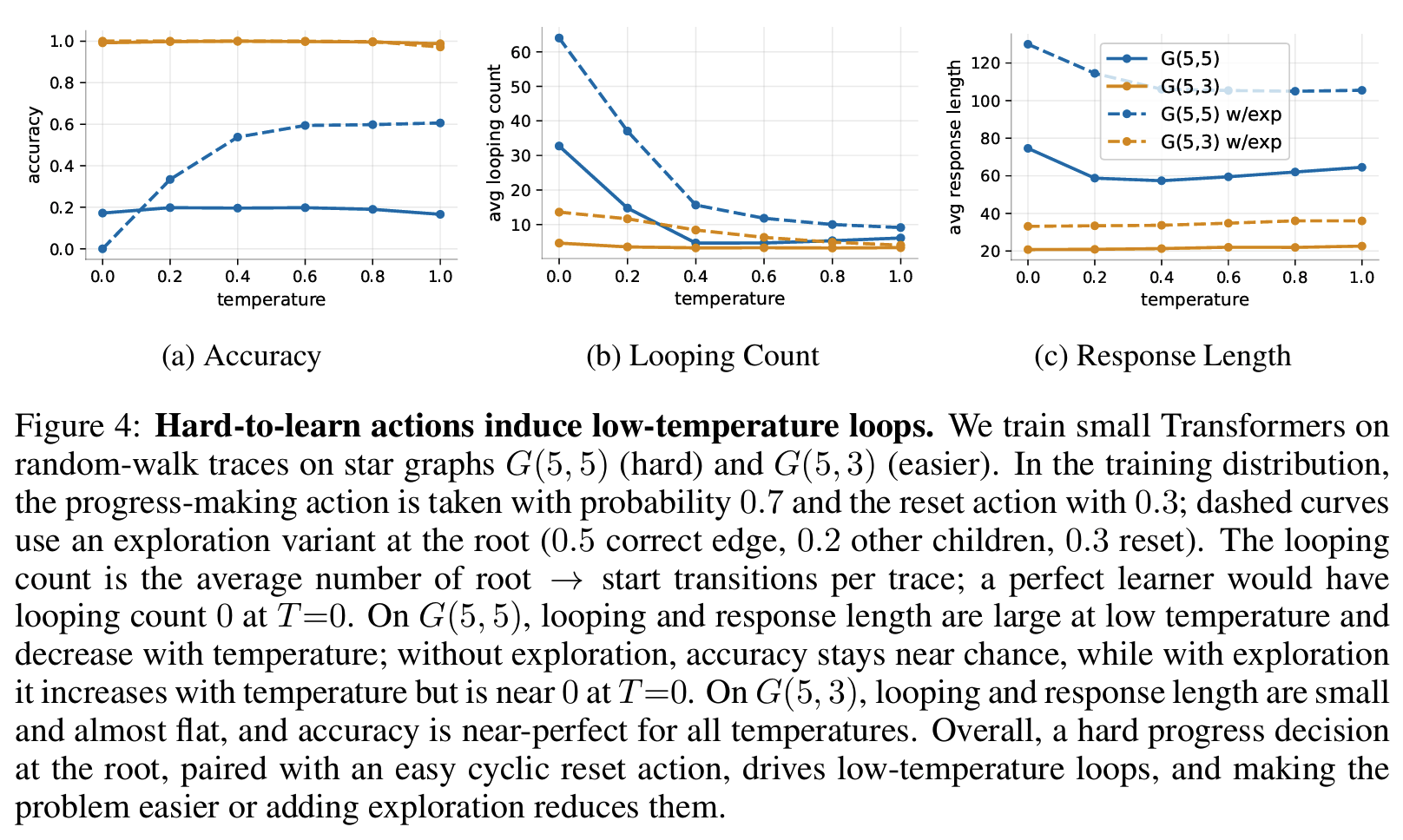
왜 progress-making action 대신 cyclic action을 계속 선택하게 되나?
- 초기 관찰
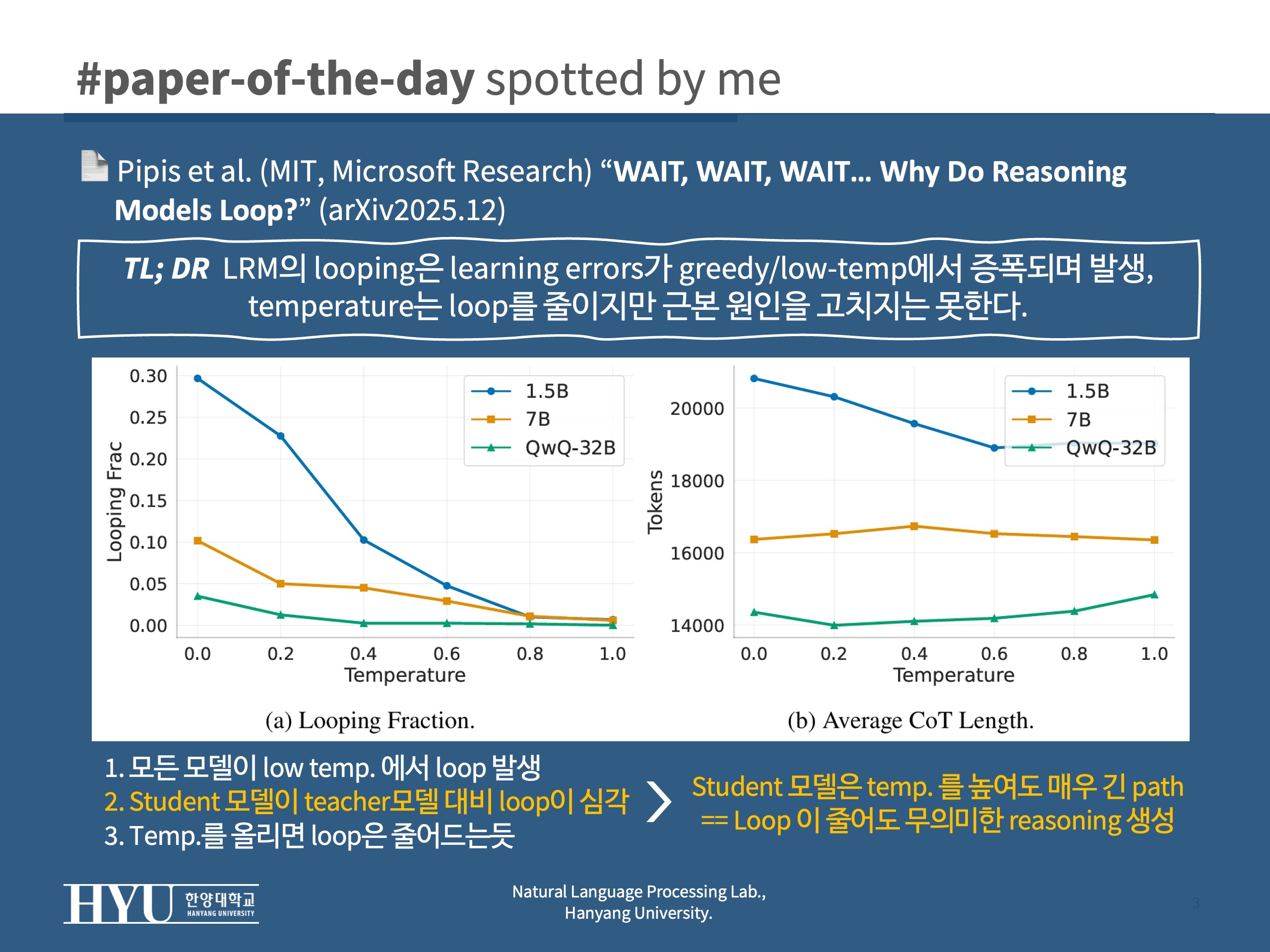
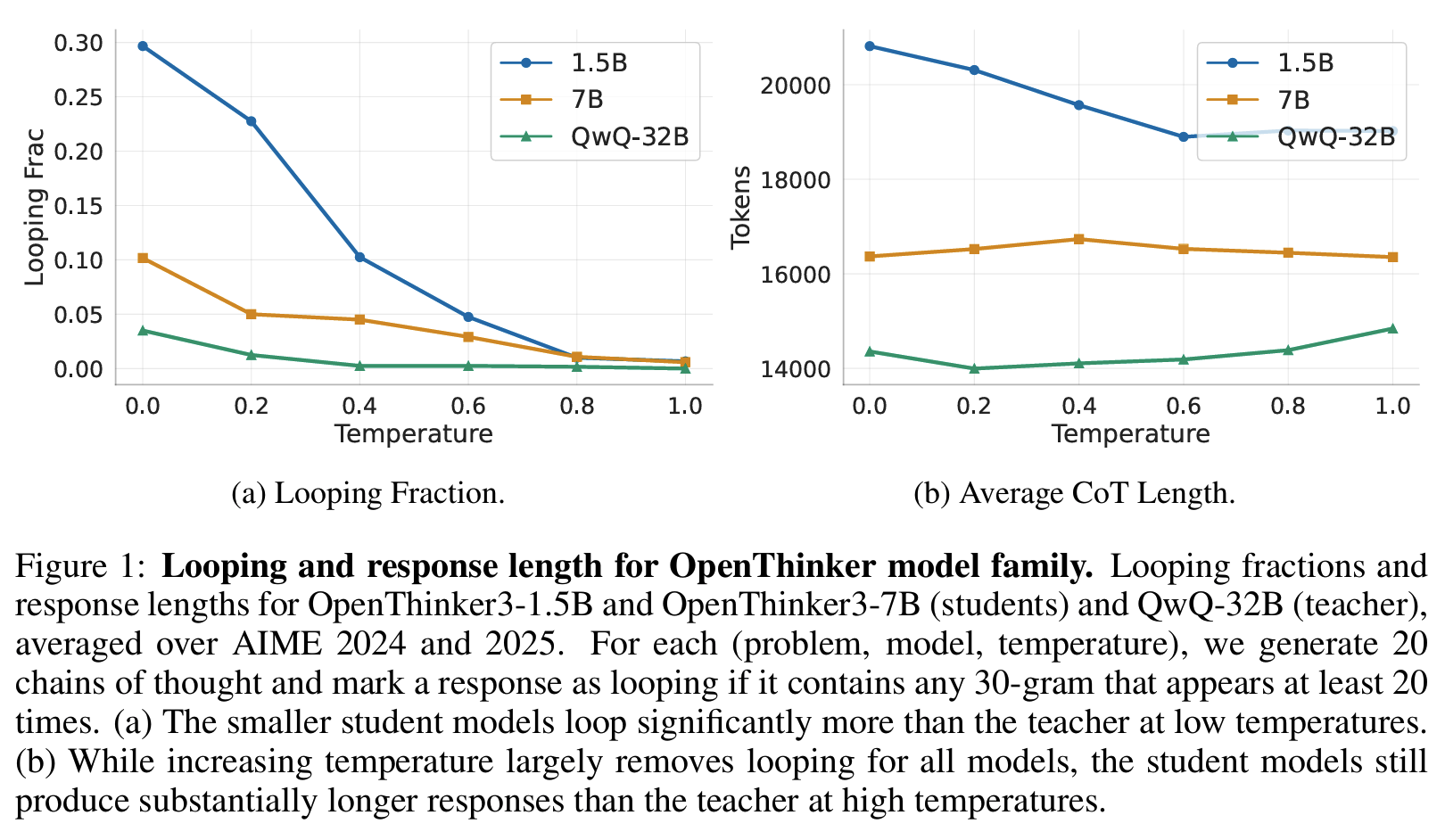
- 낮은 temperature에서 looping이 광범위하게 발생
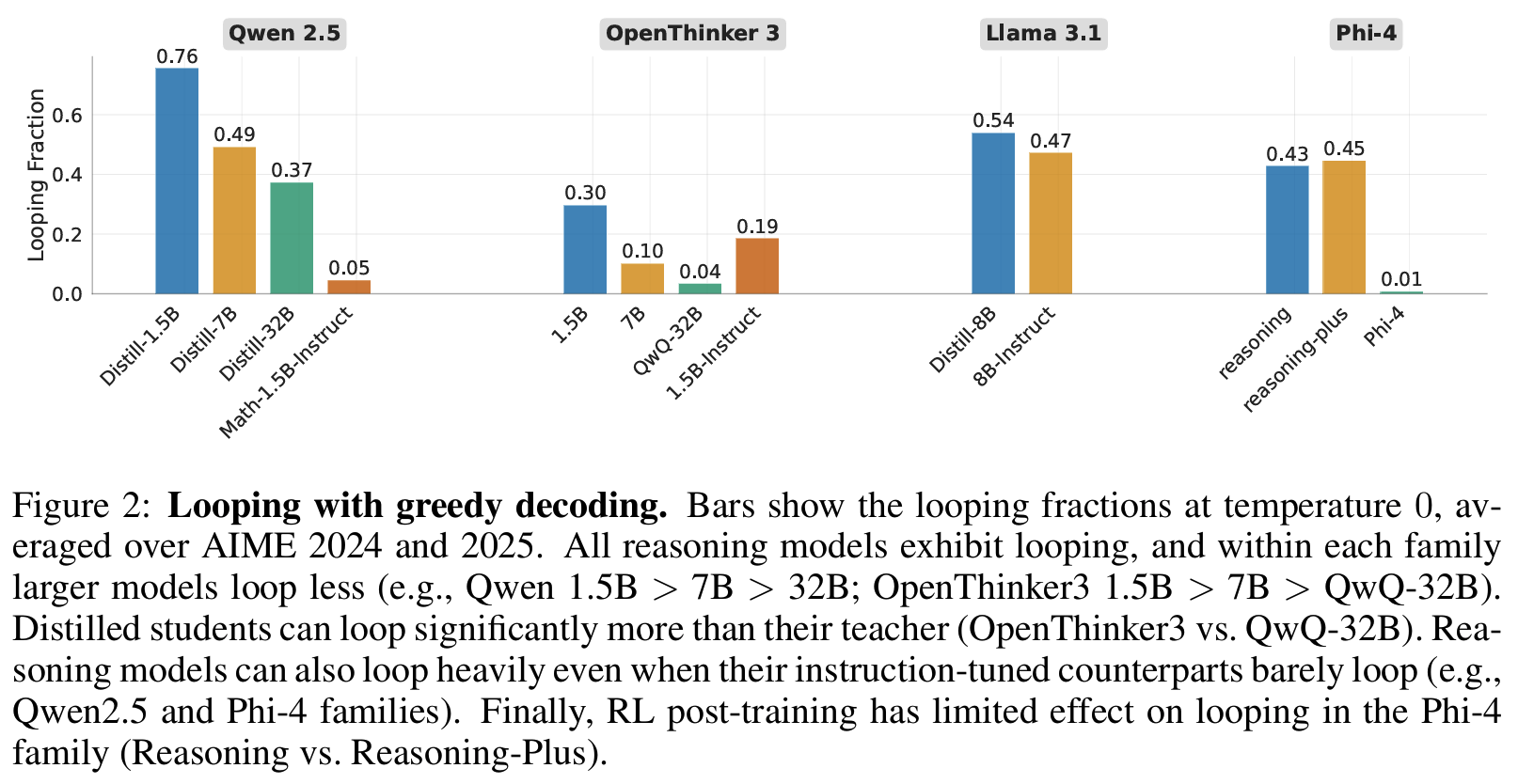
- 모델이 클수록 looping이 감소
- distilled student가 teacher보다 looping이 훨씬 심함
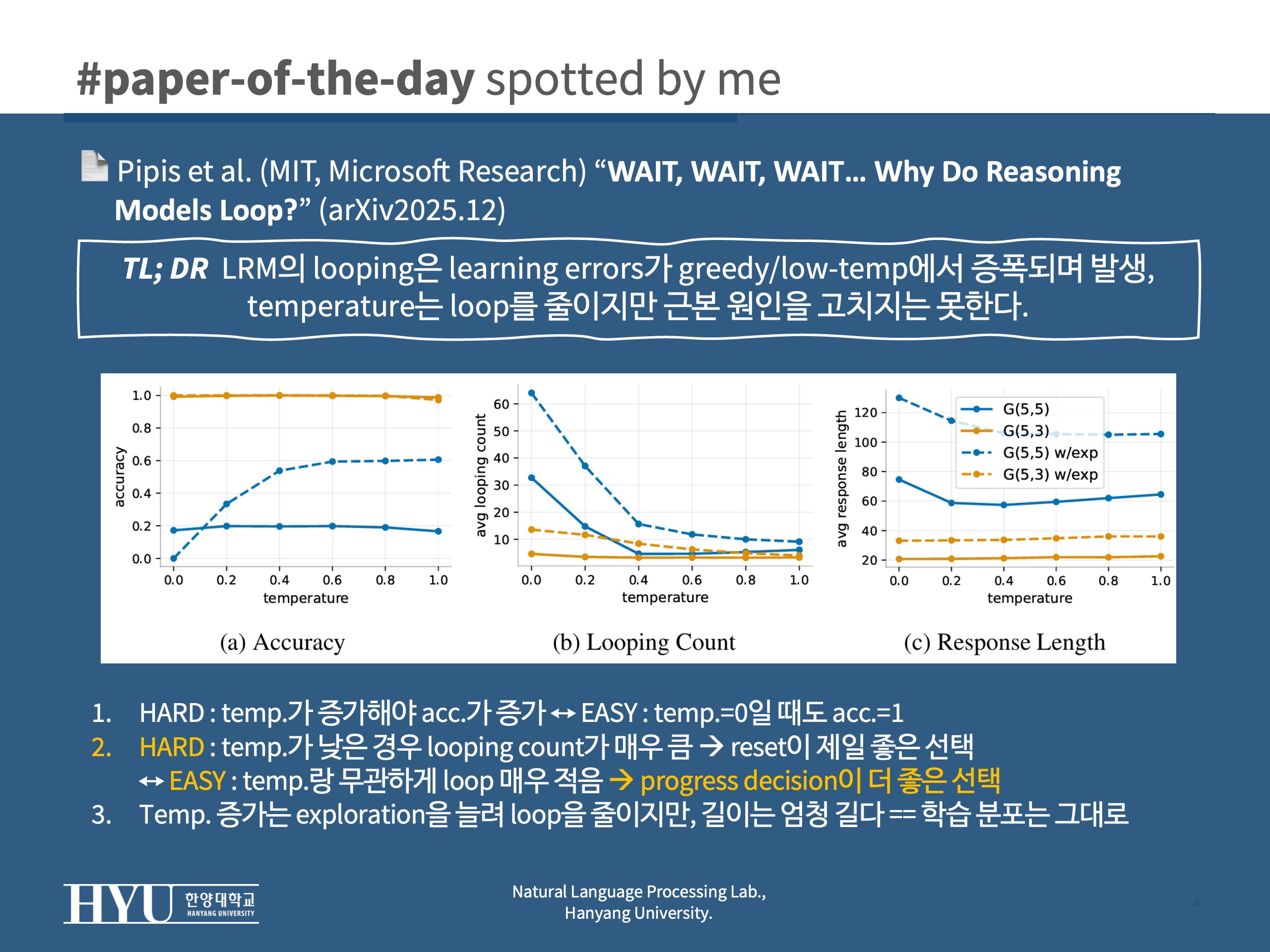
- hard problem일수록 looping이 더 많음
- 모델은 계속 같은 선택이 제일 그럴듯하다고 판단해서 반복됨 = 학습에서 progress making decision에 충분한 확률을 할당하지 못함
- objective는 reasoning중 특정 시점 이후에도 cyclic action을 더 선호하는 분포를 학습
Suggestions
- core hypothesis: local next-token probability estimates can favor cyclic actions over progress-making ones, leading to globally suboptimal reasoning trajectories
- 끝내는 것은 항상 locally suboptimal이고 계속 설명하는 것은 항상 locally safe
- 즉, 모델은 정답을 이미 맞췄어도 reasoning을 멈추지 않는 것이 합리적이게 된다.
- decoding은 cyclic action에 대한 학습된 확률 편향 증폭
- 끝내는 것은 항상 locally suboptimal이고 계속 설명하는 것은 항상 locally safe
- hardness-induced risk aversion
- 어떤 단계에서 progress-making action (정답으로 나아가는 action)이 학습하기 어려운(hard-to-learn) 경우, 확률이 수많은 대안들로 퍼져서(diffuse) 각 후보가 낮아짐
- 반면 easy cyclic action이 있다면 이 action에 확률 집중
- greedy / low-temp. setup에서는 가장 큰 확률 action만 반복선택 ->easy만 계속 선택되는 loop
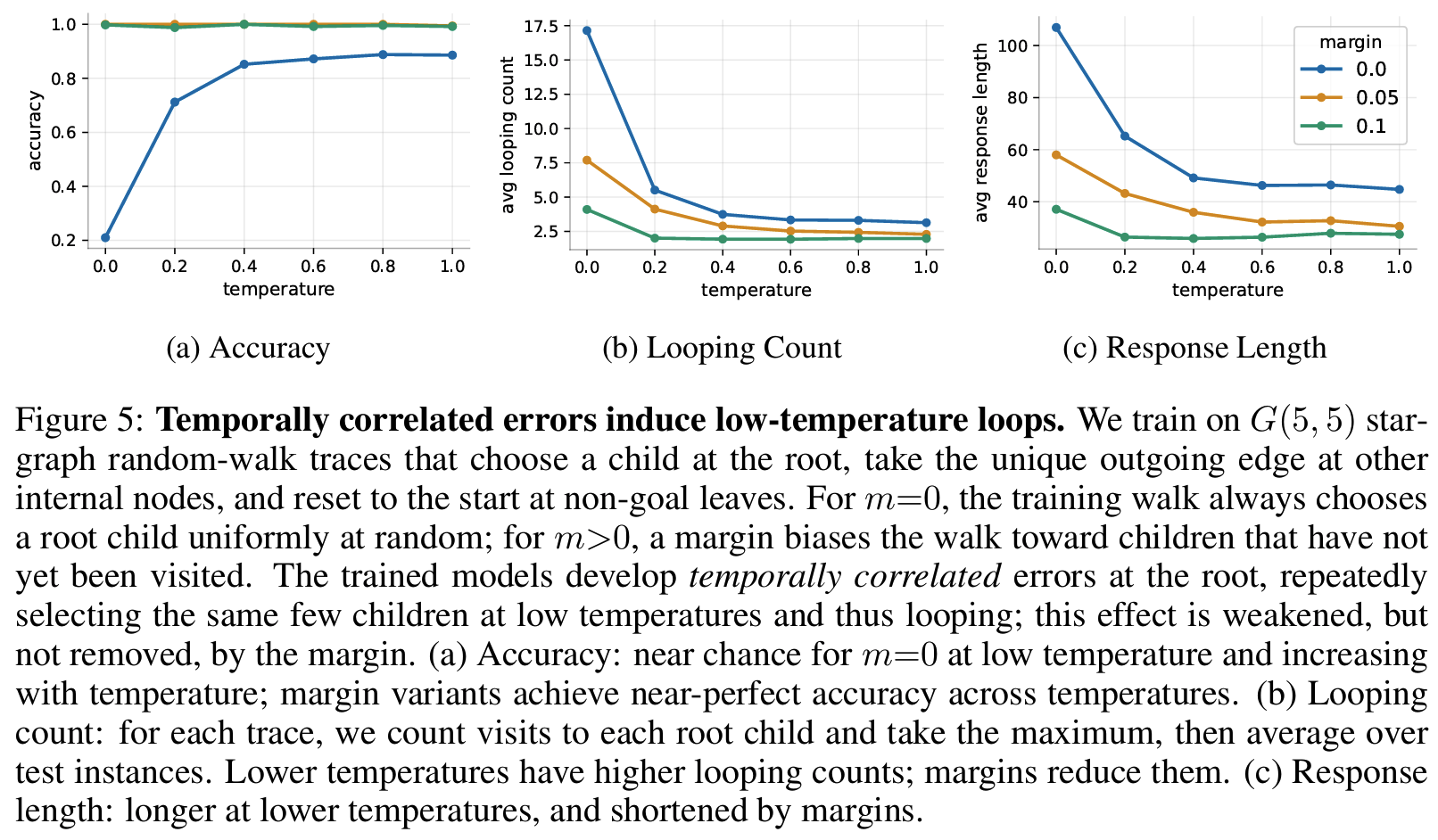
- temporally correlated errors
- hardness가 없더라도 transformers는 특정 decision point에서의 작은 확률 오차가 temporal correction으로 유지되는 경향
- 즉 반복 방문시 같은 선택을 계속 재선호하여 loop 발생 가능 = synthetic graph에서 관찰 가능
Effects
- Experimental Setup:
- models: reasoning-finetuned LLMs (Qwen distill, OpenThinker, Phi-4 reasoning 등)
- explicit CoT supervision을 받은 모델
- long scratchpad, reasoning trace를 생성하도록 튜닝된 계열
- loop = lexical repetition: n-gram overlap 증가 (30-gram repeated >=20 times)
- models: reasoning-finetuned LLMs (Qwen distill, OpenThinker, Phi-4 reasoning 등)
- Findings:
- Open reasoning models 관찰
- 공통적으로 budget이 증가할수록 loop도 증가한 반면, correctneses는 빠르게 포화
- 모델은 클수록 loop 이 감소하고, distilled student가 teacher보다 loop이 훨씬 심함 = 학습이 잘못되었음을 시사
- Synthetic graph reasoning task: learning error가 loop으로 이어진다는 인과 확인
- 왜 기존 해결책(temperature) 이 안먹히는지 ablation: loop != repetition
- temperature, top-p 조정은 exploration을 늘려 loop를 줄일 수 있지만
- temperature는 holistic solution이 아니라 stopgap에 가깝다.
- looping촉매: loop가 시작되면 반복이 이어지면서 모델의 분포가 더 확신적으로 변해, termination이 더 어려워지는 효과가 있음을 언급
- Open reasoning models 관찰
Personal note. 제출한 논문 쓰면서 LRM을 갖다 쓰긴 했는데 마찬가지의 반복 내지는 token 을 과하게 쓰는 문제에 직면했고(물론 이를 해결하는 것이 저희 연구의 주요 방향은 아니었기에, 추가적인 개선 시도하지 않고 경향만 확인했습니다만), 관련해서 비슷한 억제 시도가 있던 것으로 알고 있는데 저자들의 주요 주장은 temperature 건드는 등의 decoding단에서의 제시 정도로는 부족하다는 흐름을 꾸준히 주장하고 있습니다.