Beyond Entangled Planning: Task-Decoupled Planning for Long-Horizon Agents
Meta info.
- Authors: Yunfan Li, Bingbing Xu, Xueyun Tian, Xiucheng Xu, Huawei Shen
- Paper: https://arxiv.org/pdf/2601.07577
- Affiliation: UCAS
- Published: January 12, 2026
TL; DR
long-horizon task에서 발생하는 planning 실패의 핵심 원인을 entanglement로 규정, 이를 subtask 단위로 분리된 DAG 기반 planning으로 해결하는 것을 제안, 성능 향상 및 토큰 절감에서 유의
Review Video





Background
- 최근 LLM이 reasoning도 tool use도 잘 하는 것처럼 보이지만, long-horizon task에서 한계
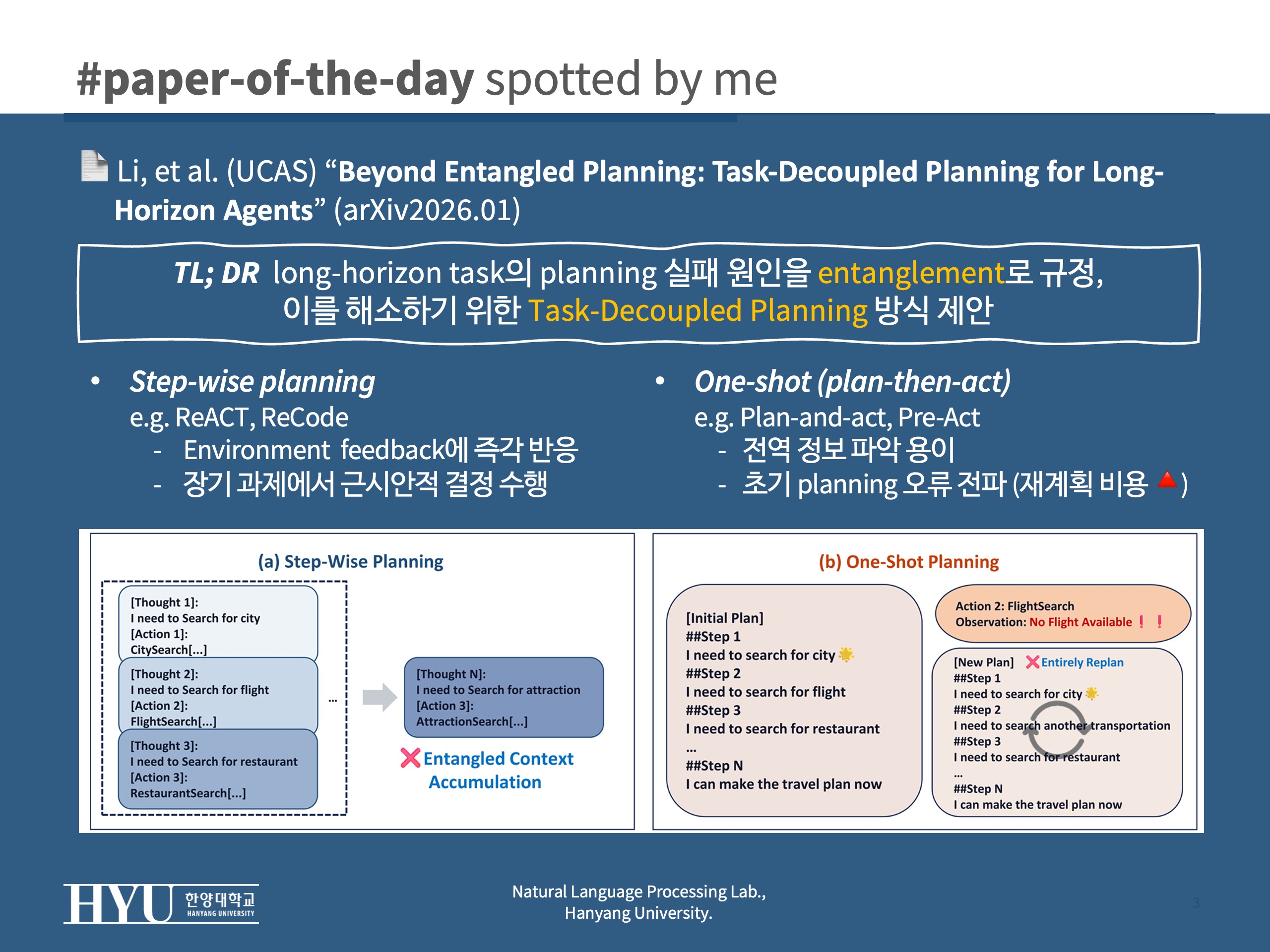
- step-wise planning: ReAct, ReCode
- environment 피드백에 즉각 대응이 가능하나,
- 장기 과제에서 근시안적 결정 수행, 히스토리 무한 확장에 대한 한계
- one-shot (plan-then-act): Plan-and-act, Pre-Act
- 전역 정보 파악이 가능하지만 초기 planning 오류에 취약하여 재계획 비용이 큼
- step-wise planning: ReAct, ReCode
Problem States
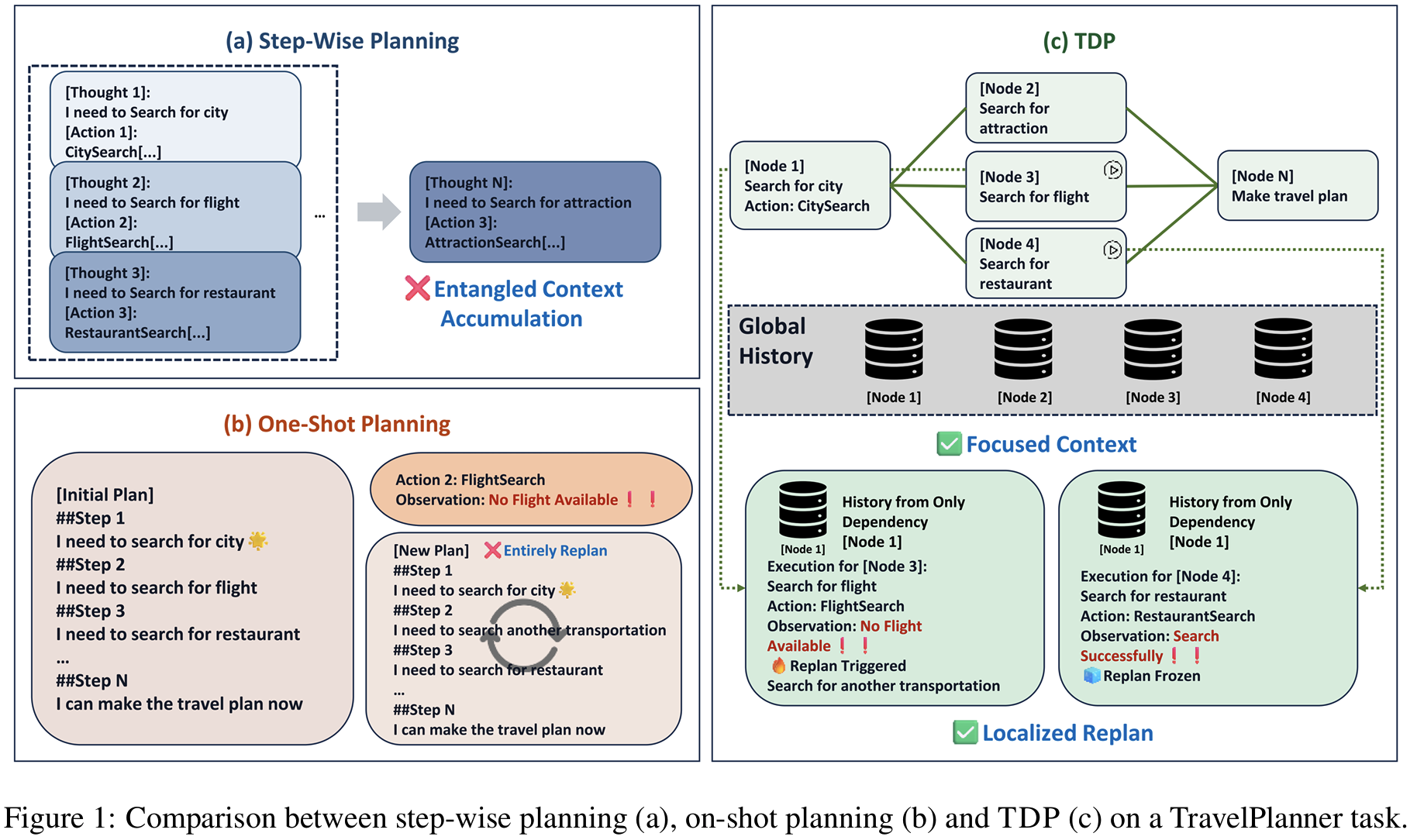
LLM-based Agent가 long-horizon task에서 실패하는건 Entangled planning 때문이라고 주장
- 여러 subtask에 대한 thought, 실패, 정보가 혼합된 긴 execution history에서 추론 (인지 부하 증가)
- 그에 따른 error propagation (로컬한 실패가 무관해보이는 결정까지 영향)
- 그러나 복구의 비효율성: 원인과 무관한 부분까지 재계획
- 선행연구 공통점: 구조적으로 여러 subtask의 정보 / 결정 / 실패가 섞인 단일 실행 history 위에서 추론하는 것이 문제
- 문제의 본질은 계획을 얼마나 세세히 잡느냐 같은 게 아니라,
- context entanglement에 의한 오류 전파를 어떻게 잡느냐 = 모델의 추론 범위를 잡아줘야 한다
Suggestions
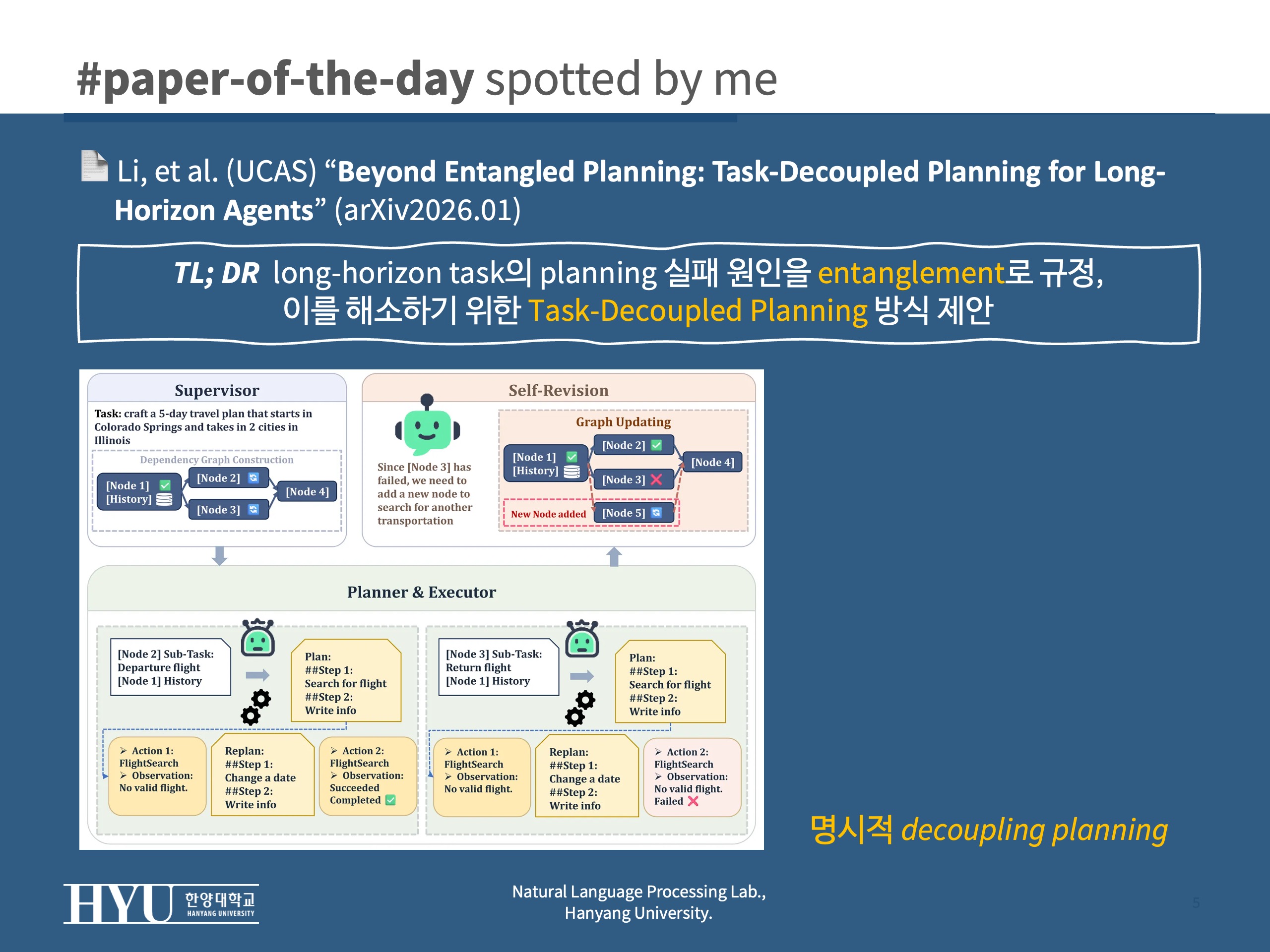
Task-Decoupled Planning (TDP)
- 명시적 decoupling (=task를 가능한한 분리하면서) planning 하자
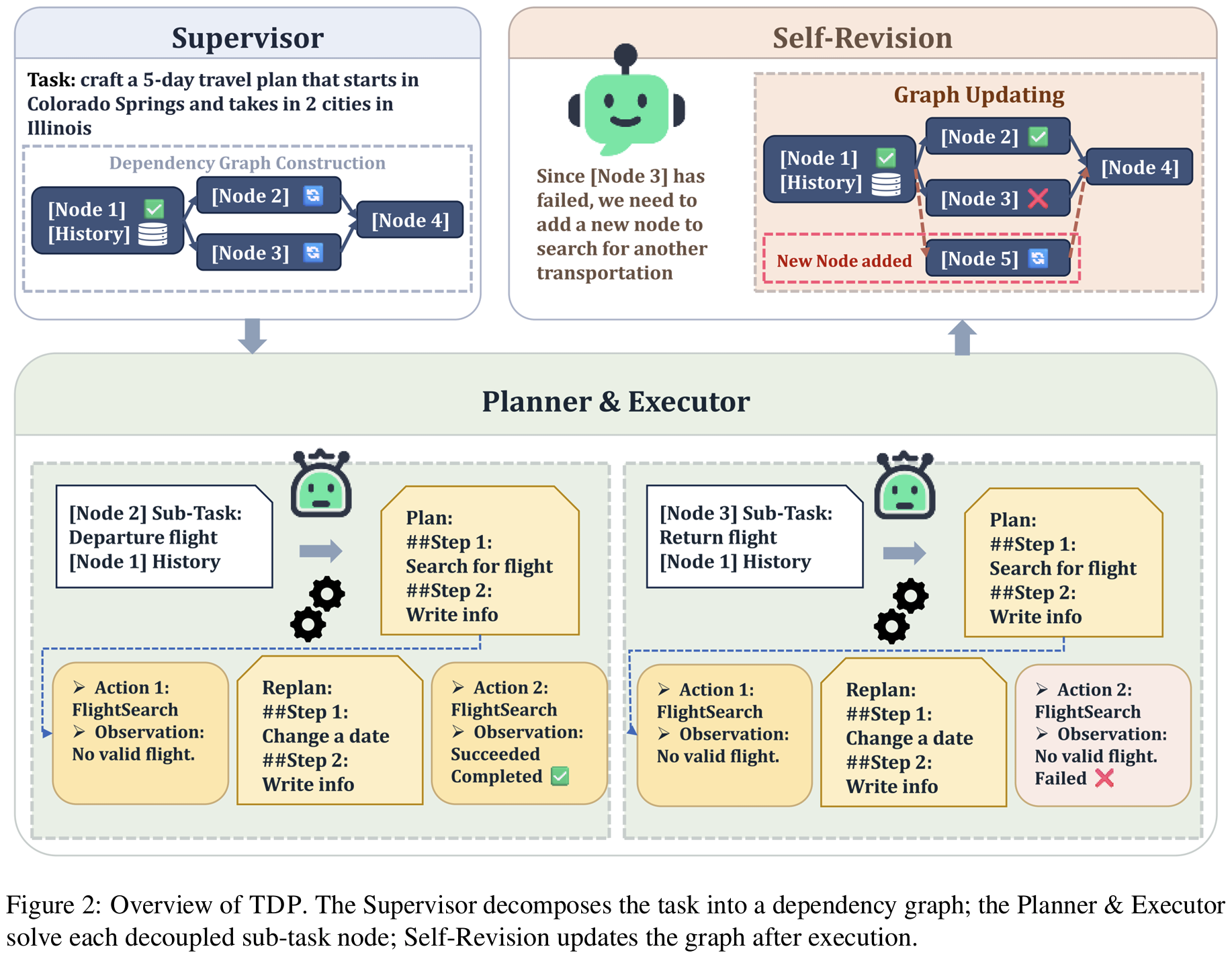
- #1 Supervisor: 전체 과제를 Subtask로 분리 > DAG(directed Acyclic Graph)로 정리
- node == 1개의 sub-task
- edge == dependency
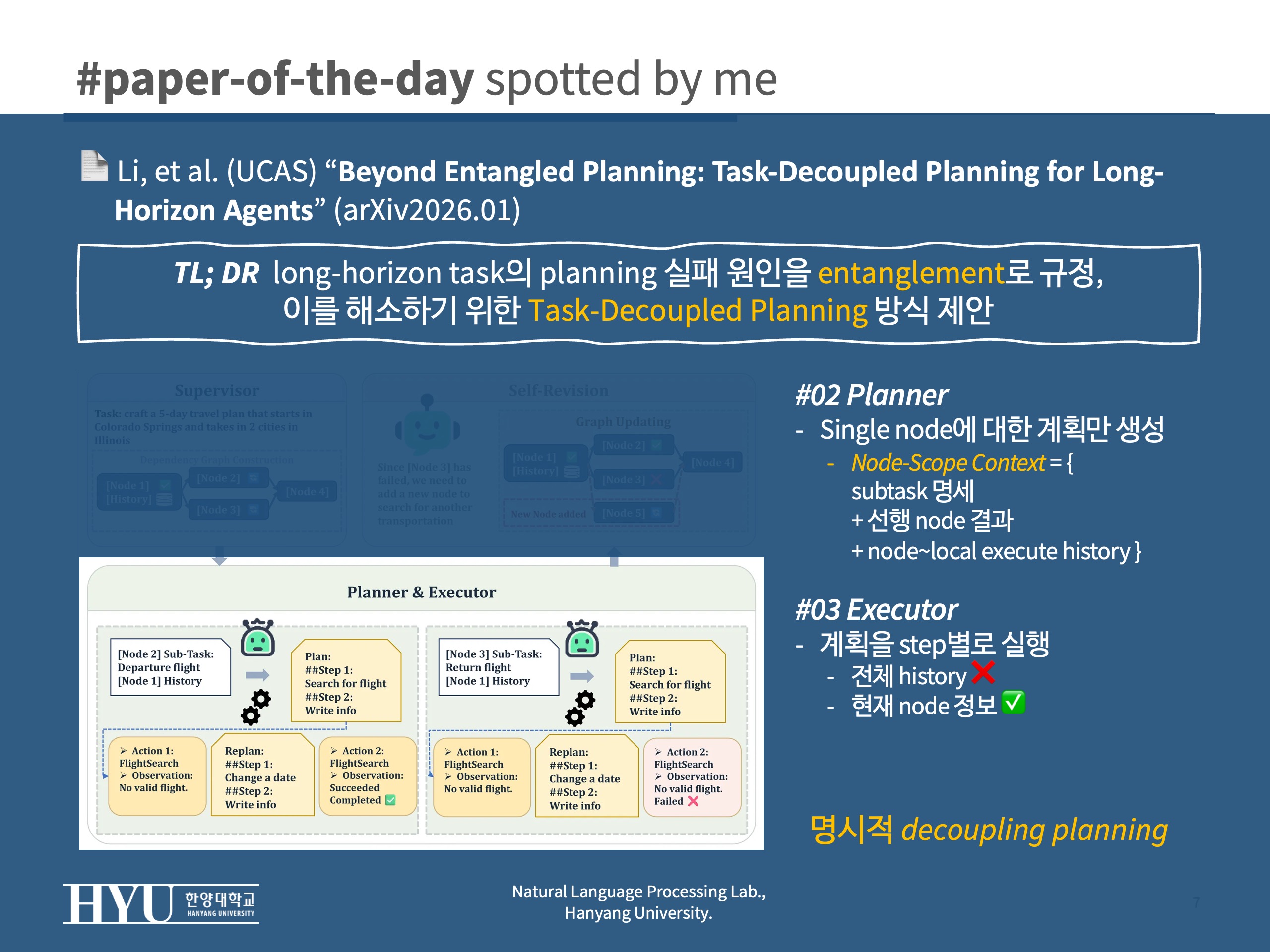
- #2 Planner: single node에 대해서만 계획 생성, input을
Node-Scoped Context로 제한Node-Scoped Context= {subtask 명세 + 선행 node=subtask 결과 + 해당 노드의 local execute 기록}- 다른 subtask에 대한 history나 과거 실패 로그 등 제외
- #3 Executor: 계획을 단계적 실행
- 전체 히스토리를 보지 않고 현재 노드 history만 보되, env. 와 상호작용 담당
- #4-1 local revision: 실패시 (필요하다면) 재계획은 노드 내부에서만 발생되도록 (localized replanning)
- #4-2 global revision: 어떤 실패가 DAG 구조 자체의 오류를 의미한다면 그때 Supervisor가 DAG 수정 (노드 추가/제거)
Effects
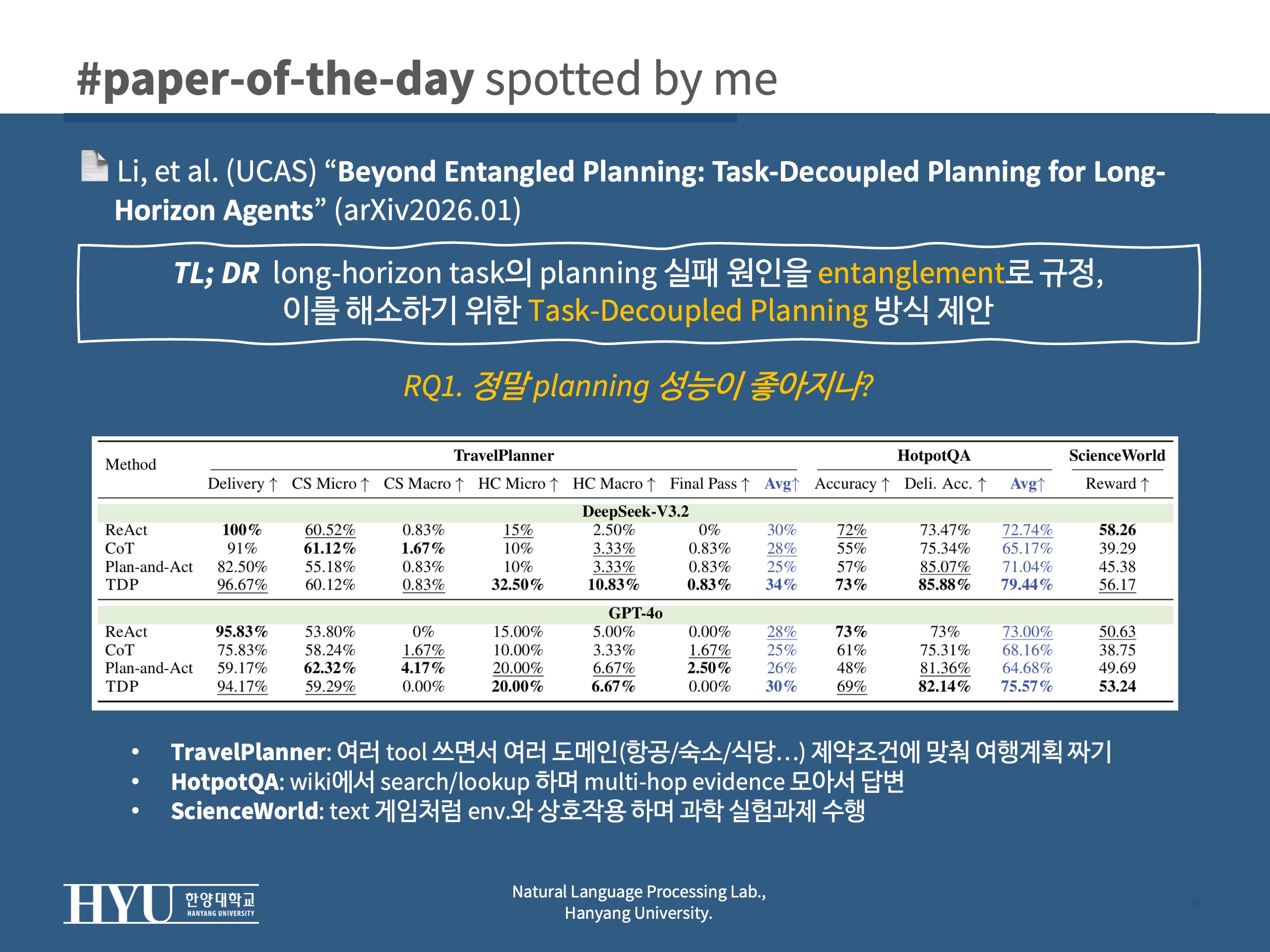
RQ1그래서 정말 성능 향상이 됐는가 (task success, constraint satisfaction, reward, accuracy)RQ2비용도 줄었나 (replanning 때문에 새로 뱉는 token등)- Experimental Setup:
- benchmarks:
- TravelPlanner(constraints 중심 tool-planning): 여러 tool 쓰면서 여러 도메인(항공/숙소/식당/관광/이동 등) 제약조건에 맞춰 여행계획 짜기
- HotpotQA (interactive, multi-hop 추론): wiki에서 search/lookup 하며 multi-hop evidence 모아서 답변
- ScienceWorld(closed-loop 환경에서 상호작용): text 게임처럼 env.와 상호작용 하며 과학 실험과제 수행
- baselines:
- ReAct: 매 step마다 think > action
- CoT: 처음에 plan (같은 걸) 세우고 그대로 밀고 나가는 one-shot setup
- Plan-and-Act: high-level plan을 세우고 실행중 문제가 생기면 재계획 (global일때 고비용)
- TDP: 제안방식. DAG + node-scoped context + localized replanning
- backbone: DeepSeek-3.2, GPT-4o
- benchmarks:
- Results:
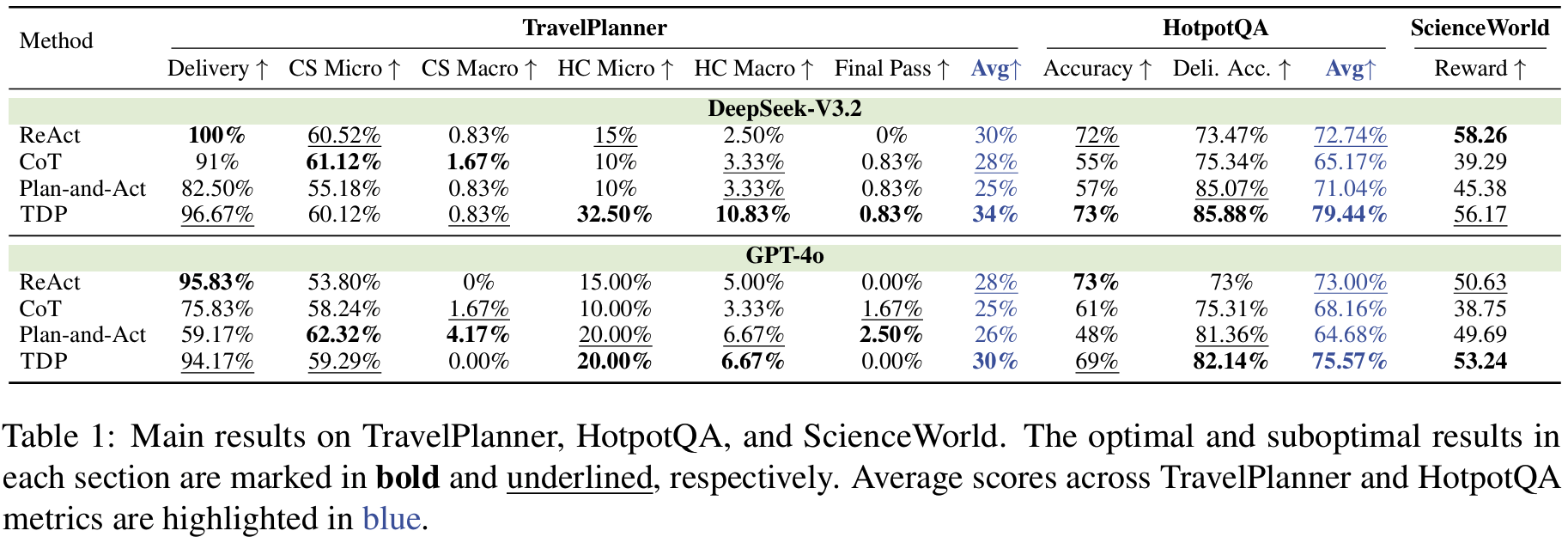
- Tab 1:
RQ1주요 성능 비교; deepseek-3.2, gpt-4o 모두에서 TDP가 항상 상위권- TravelPlanner (제약을 잘 지켰느냐가 핵심): TDP가 제약 만족(특히 HC)를 끌어올리면서 제출 실패(=중간에 무너져서 끝을 못내는) 문제 감소
- 제약 종류: CS(commonsense constraints; 상식수준), HC(hard constraints; 구체적인 시간/날짜/도시/예산 등 제약)
- 평가: micro(여러 제약 중 얼마나 많이 만족했는지), macro(해당 카테고리 제약을 전부 만족했는지 all-or-nothing) > final pass(모든걸 전체 통과했는지)
- HotpotQA (증거 잘 모아다가 최종 답 내는지가 핵심): TDP가 sub-task 단위로 reasoning을 깔끔하게 유지해서 delivered correctness 향상
- 평가: accuracy(최종 답 맞는지), Deli. Acc. (task completion 전제로 답이 맞는지)
- step-wise는 history가 길어질수록 drift 발생
- one-shot은 최초 방향성이 틀리면 취약
- ScienceWorld (env.의 feedback( [0,1] scale의 progress 기반 reward)을 보고 상호작용 잘 하는지가 핵심; ReAct 계열 step-wise 방식이 유리하다고): 결과적으로 gpt-4o가 best, deepseek도 경쟁수준
- TravelPlanner (제약을 잘 지켰느냐가 핵심): TDP가 제약 만족(특히 HC)를 끌어올리면서 제출 실패(=중간에 무너져서 끝을 못내는) 문제 감소
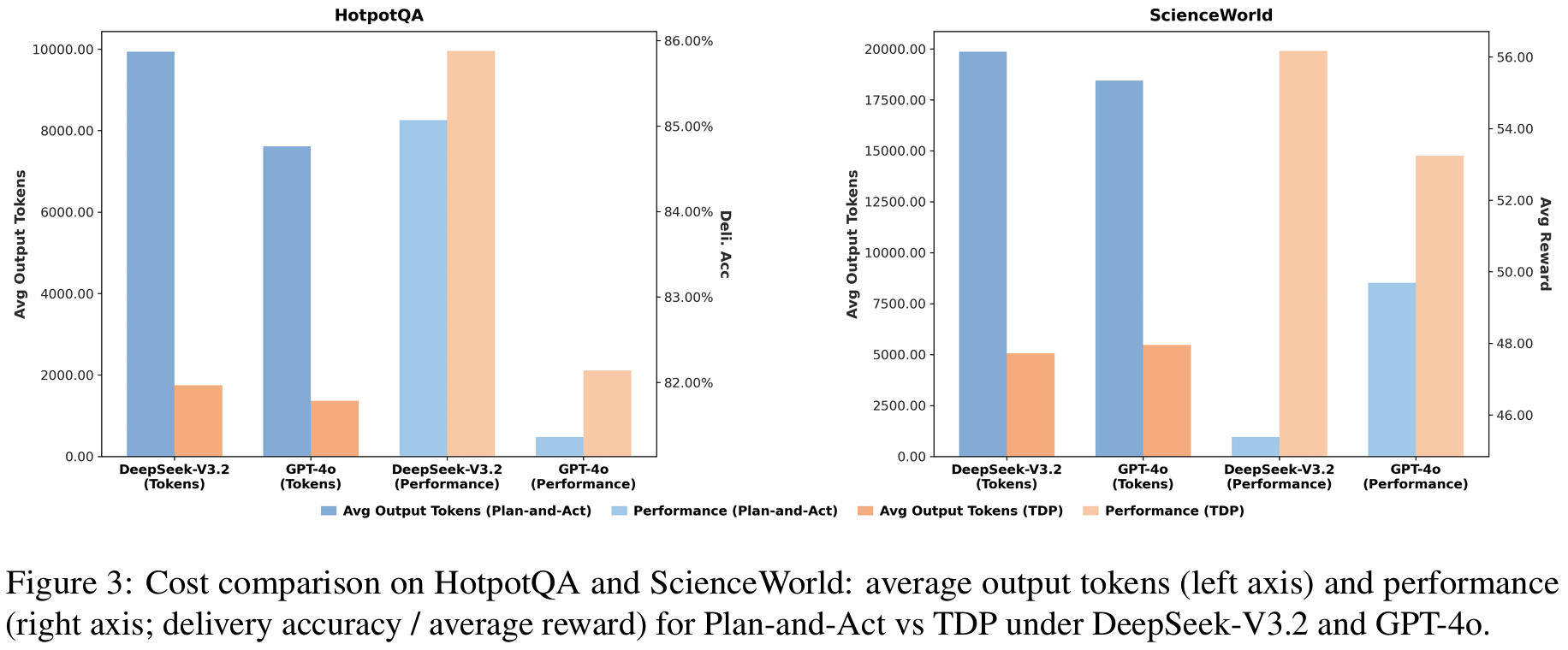
- Fig 3:
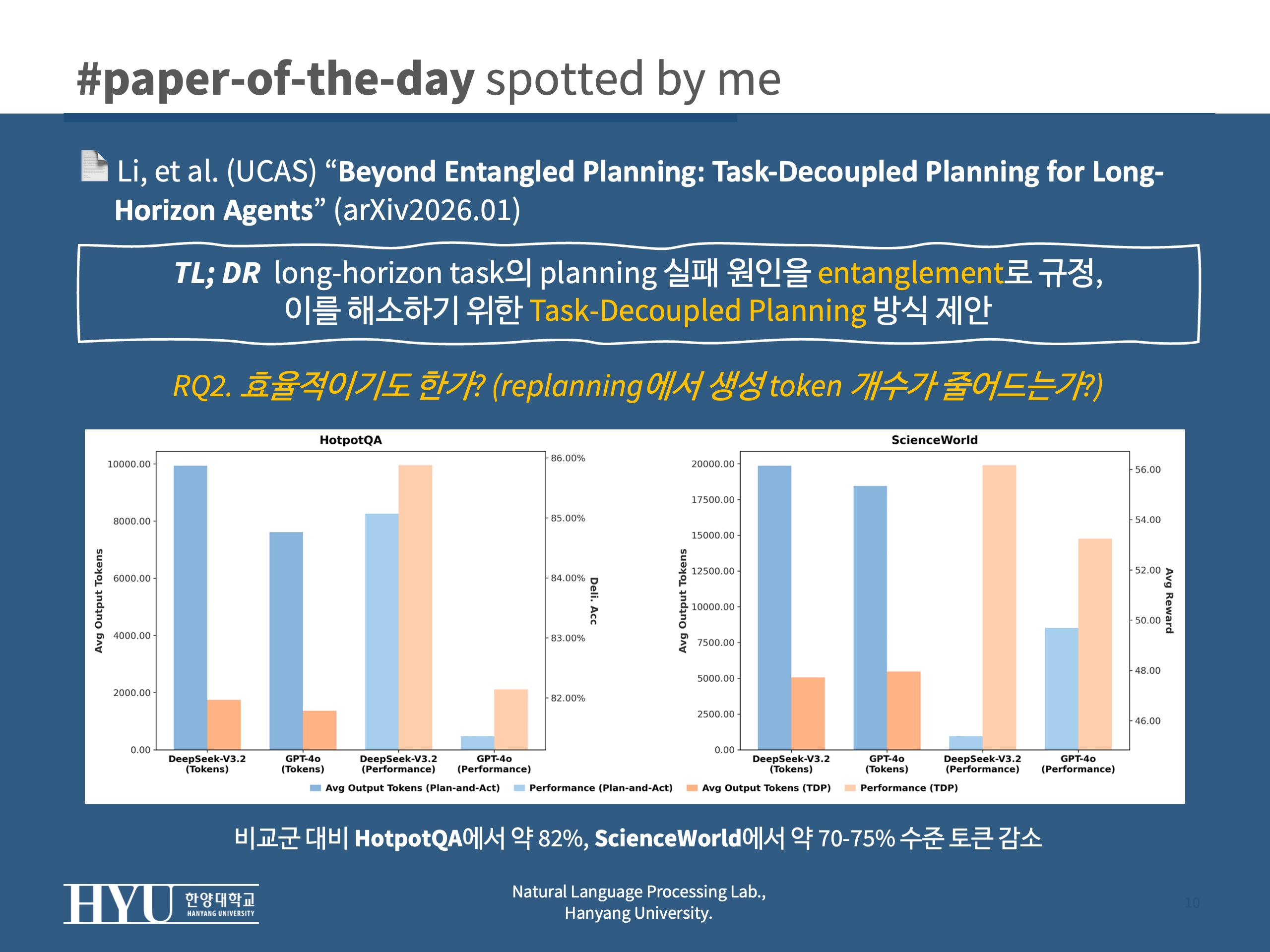
RQ2token 비교 (plan-then-act vs. TDP)- 비교군 대비 HotpotQA에서 약 82%, ScienceWorld에서 약 70-75% 수준 토큰 감소
- Plan-and-Act는 deviation이 생기면 global plan을 다시 짜느라 이미 결정된 것까지 재정당화를 반복 > 토큰 폭증
- TDP는 deviation이 생겨도 active node 안에서만(=local) replan하니 말이 길어질 이유가 없음
- 비교군 대비 HotpotQA에서 약 82%, ScienceWorld에서 약 70-75% 수준 토큰 감소
- Fig 4: case study (TravelPlanner 사례로 decoupling 작동 상세 설득)
- decomposition이 정보 공백을 메꾸기도 하고 node isolation(localization)이 실제 불필요한 정보 오염을 막음
- Tab 1:
Personal note. long-horizon 최신 연구같아서 읽어보긴 했는데, NL 측면에서 최신 벤치마크 등을 확인할 수 있었습니다. (타당한지와는 별개 문제..) 좀 별건이지만 오히려 저희 최근 preference reasoning 연구에서 preference-scope를 설계해보고 그에 따라 preference를 수정하는 것도 방법이 되겠다는 생각이 들어요. DAG 같은 구조를 활용하면 preference trasnfer와 연결될지도..