When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Meta info.
- Authors: Zhongxiang Sun, Yi Zhan, Chenglei Shen, Weijie Yu, Xiao Zhang, Ming He, Jun Xu
- Paper: https://arxiv.org/pdf/2601.11000
- Affiliation: RUC, Lenovo Research, UIBE
- Published: January 16, 2026
TL; DR
Personalization은 단순히 user-aligned bias가 아니라 factual representation과 entangle되면서 체계적인 hallucination을 만든다는 사실을 representation level에서 밝히고 inference-time에서 이를 제거하는 FPPS 제안


Background
- Personalized LLM 연구 전반에서는 personalization과 factual reasoning이 충돌하지 않는다고 간주
- user history / profile / memory 등을 prompt에 주입 -> user 맞춤형 대답
- 기대효과: personalized QA 성능 향상, user satisfaction 향상 정도에 그침
- Hallucination 연구의 주요 관점과도 충돌
- knowledge 부족, retrieval 실패, uncertainty miscalibration 등 지적
- 알고도 틀리는 케이스에 대한 분리가 없고, 해결이 단순 RAG/verification에 그침
Problem States
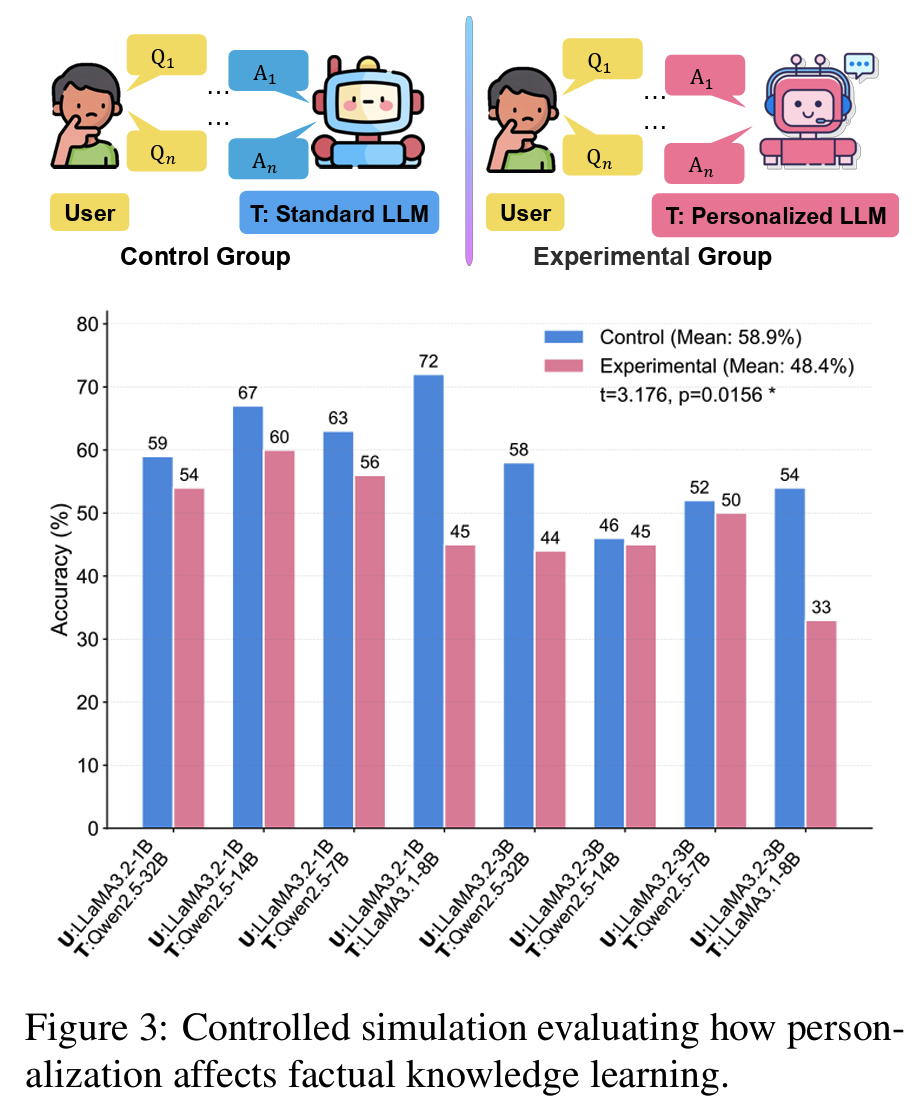
- 객관적 질문(factual query)에 대해 personalization이 부정적인 영향을 끼친다는 것을 systematic하게 검토
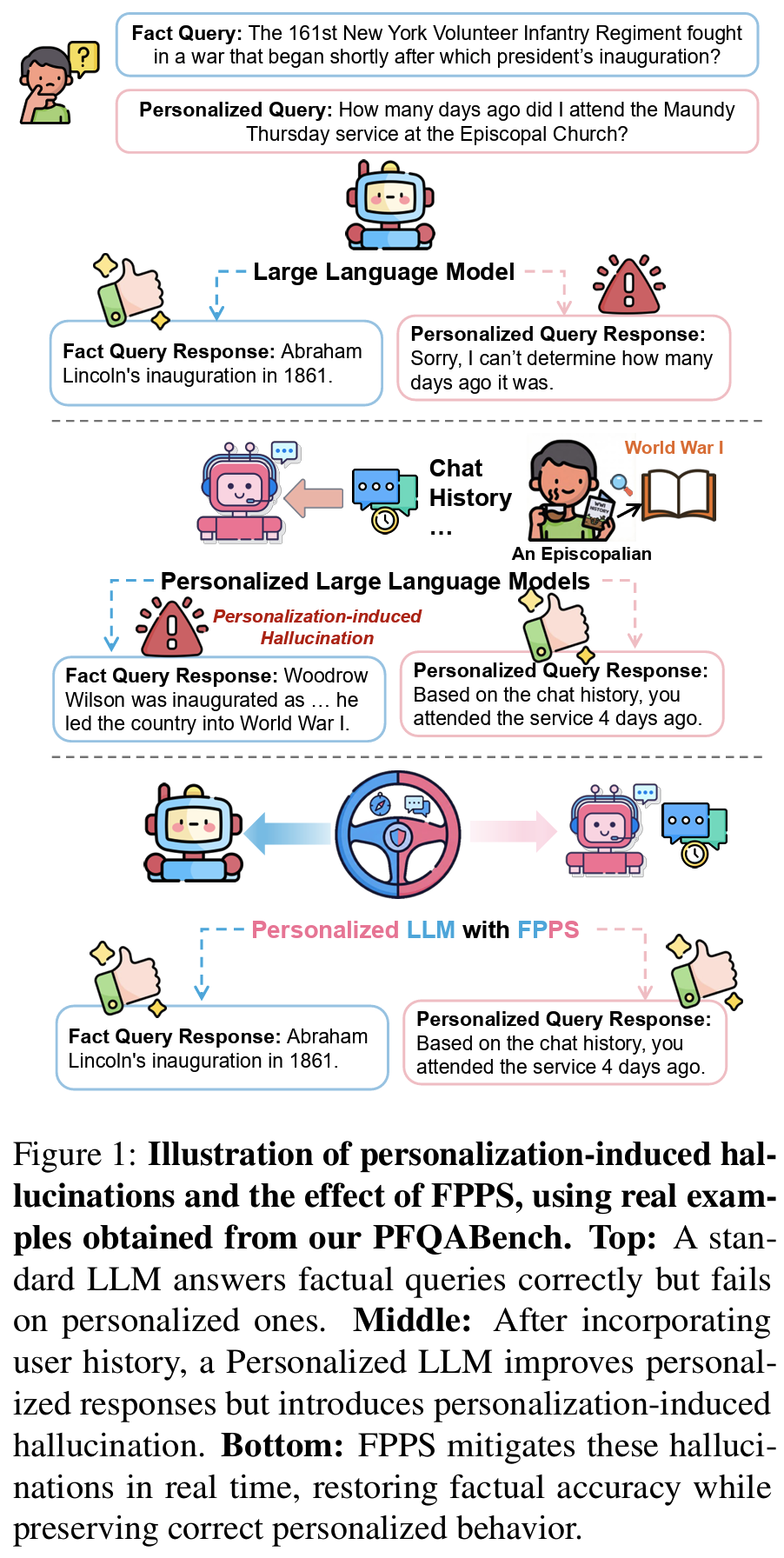
- personalization-induced hallucination: 원래는 맞추던 것을 personalization 이후 못 맞추는 문제
- 모델은 몰라서가 아니라 알아도 user history 때문에 틀린다
- personalization으로 인한 counterfactual error 발생
Suggestions
- Formulation
- notation
- query x, user info u, response y
-
personalized LM p_theta(y x, u), non-personalized LM p_theta(y x)
- counterfactual error로 hallucination 정의: personalization이 없으면 답을 맞추는데 들어오면서 오답이 된 경우
- personalization이 factual을 망칠 때만 건드리기 위한 흐름으로 personalization 자체를 명시적으로 가시화
- notation
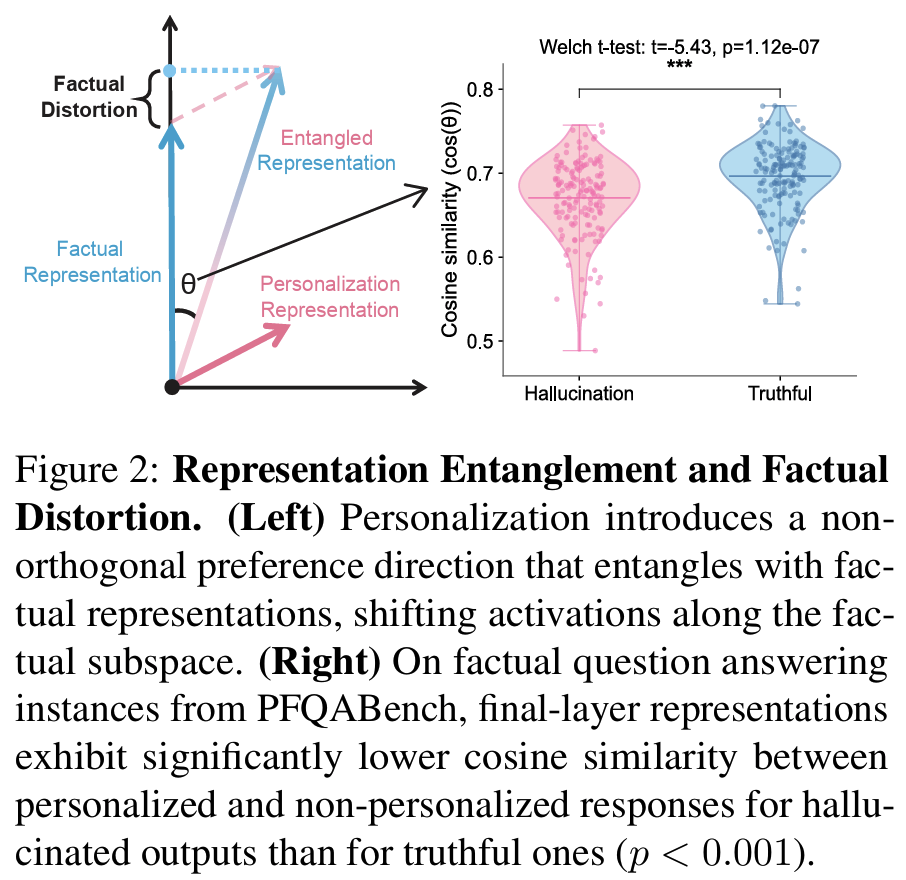
- Mechanism: Representation Entanglement으로 personalization-induced hallucination 발생 원인 분석
- personalization induced shift v_u: personalization이 내부 activation에 주는 net effect 를 추상화한 vector
- personalization 없는 hidden state h_t(x), 포함 hidden state h_t(x, u)
- v_u = h_t(x, u) - h_t(x), so that h’_t = h_t + v_u
- entanglement (Fig. 2)
- personalization이 non-orthogonal preference direction을 도입
- factual representation과 얽히고 factual reasoning에 깔끔하게 추가되는 게 아니라
- activation을 factual subspace로 옮김 -> factual subspace 자체를 왜곡 가능
- personalization-induced hallucination: 원래는 맞추던 것을 personalization 이후 못 맞추는 문제
- 모델은 몰라서가 아니라 user history 때문에 틀린다
- personalization으로 인한 counterfactual error 발생
- 실증: PFQABench factual QA에서 personalized vs non-personalized 응답의 final-layer representation cosine similarity 비교
- hallucinated outputs에서 similarity가 유의하게 더 낮음 (p < 0.001)
- 오류가 surface decoding에서 우연히 생긴 게 아니라 representation level에서 이미 다른 곳으로 이동한다는 사실 반증
- personalization induced shift v_u: personalization이 내부 activation에 주는 net effect 를 추상화한 vector
- PFQABench 구축: personalization 조건에서 factual correctness 평가 가능
- 총 500 users, 1000 examples (Tab. 3)
- user histories: LongMemEval (Wu et al., 2025)
- factual multi-hop QA corpus: FactQA (HotpotQA + 2WikiMultiHopQA 기반)
- 구성: 동일한 user session context에서 “history를 써야 하는 질문”과 “history를 무시해야 하는 질문”을 같이 둠
- personalized questions 500 (history 필요)
- factual questions 500 (history 넣어도 답이 변하면 안 됨)
- 총 500 users, 1000 examples (Tab. 3)
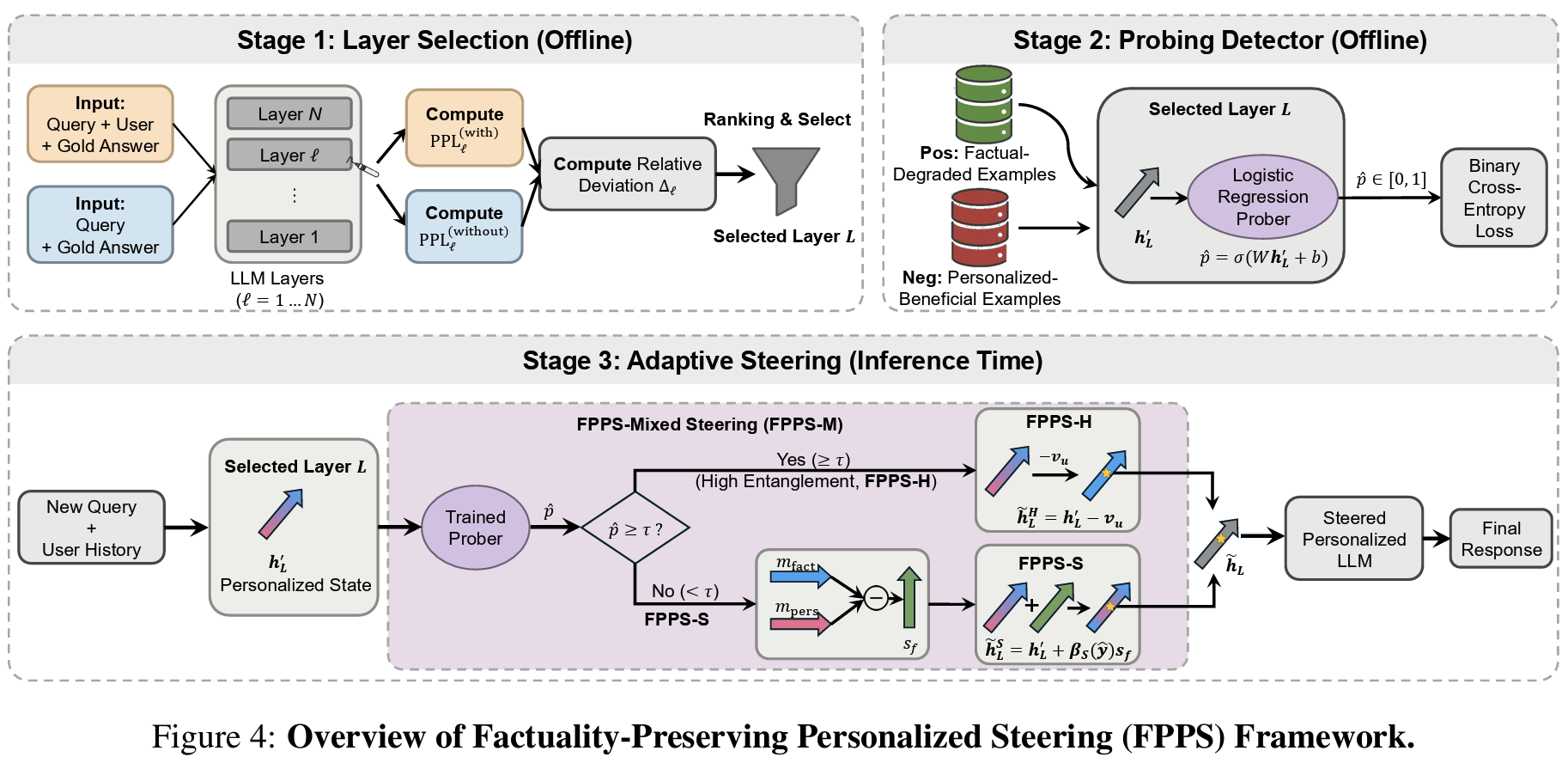
- Methods: Factuality-Preserving Personalized Steering (FPPS)
- personalization-sensitive layer를 찾고, 해당 layer에서 entanglement risk를 probe로 추정하고, 그 risk에 따라 activation steering을 다르게 적용
- h_tilde_L = T_FPPS(h_prime_L, p_hat)
- p_hat: personalization이 factual reasoning을 방해할 확률(정도)
- h_tilde_L = T_FPPS(h_prime_L, p_hat)
- stage1) layer selection (offline): 가장 취약한 layer 식별
- with/without user history로 contrastive input을 만들고
- model-generated answer를 append해서 decoding trajectory를 동일하게 맞춘 다음,
- 각 layer L에서 ground-truth answer token들의 logit 기반 perplexity 계산, relative deviation 확인
- deviation을 (1) factual-degraded: personalization이 correctness를 망친 케이스, (2) personalized-beneficial: personalization이 correctness를 가능하게 한 케이스 모두에서 확인
- 둘의 ranking을 inverted-rank fusion으로 합쳐, 일관되게 deviation이 크고 안정적인 layer L을 empirical하게 고정
- stage2) Probing Detector (offline): 지금 망치고 있나?
- 선택된 layer L에서 hidden state로 logistic regression 학습
- feature: final-token hidden state h_prime_L in R^d
- label: positive = factual-degraded, negative = personalized-beneficial
- pred p_hat: 현재 representation이 personalization에 의존하는 방식이 factual reasoning에 영향을 줄 확률 (risk score)
- 선택된 layer L에서 hidden state로 logistic regression 학습
- stage3) Adaptive Steering (inference time): 망칠 때만 최소 개입
- FPPS-H (hard): threshold 이상 위험하면 personalization v_u 완전 제거
- FPPS-S (soft): 삭제 대신 연속적인 steering
- steering vector s_f = {non-personalized setting에서 factual query를 정답으로 맞춘 샘플들의 mean hidden state} - {user history 제공 시에만 personalized query를 정답으로 맞춘 샘플들의 mean hidden state}
- 직관: s_f는 representation을 factual reasoning pattern 쪽으로 밀고, history-conditioned personalization drift에서 멀어지게 하는 방향
- risk score가 0.5 이상이면 personalization을 억제하는 방향으로 (항상 personalization이 factual reasoning을 망치는 건 아니므로)
- FPPS-M (mixed steering): risk가 낮으면 FPPS-S, 높으면 FPPS-H
- personalization-sensitive layer를 찾고, 해당 layer에서 entanglement risk를 probe로 추정하고, 그 risk에 따라 activation steering을 다르게 적용
Effects
- Experimental Setup
- baselines: PAG (profile augmented), DPL, RAG, LLM-TRSR 등 profile 혹은 retrieval 계열 포함
- backbones: LLaMA-3.1-8B-IT, Qwen2.5-7B-IT, Qwen2.5-14B-IT
- metrics: LAAJ
- P-score: personalized questions에 대한 accuracy
- F-score: personalization 조건에서 factual accuracy
- Overall = (P + F) / 2
- Result
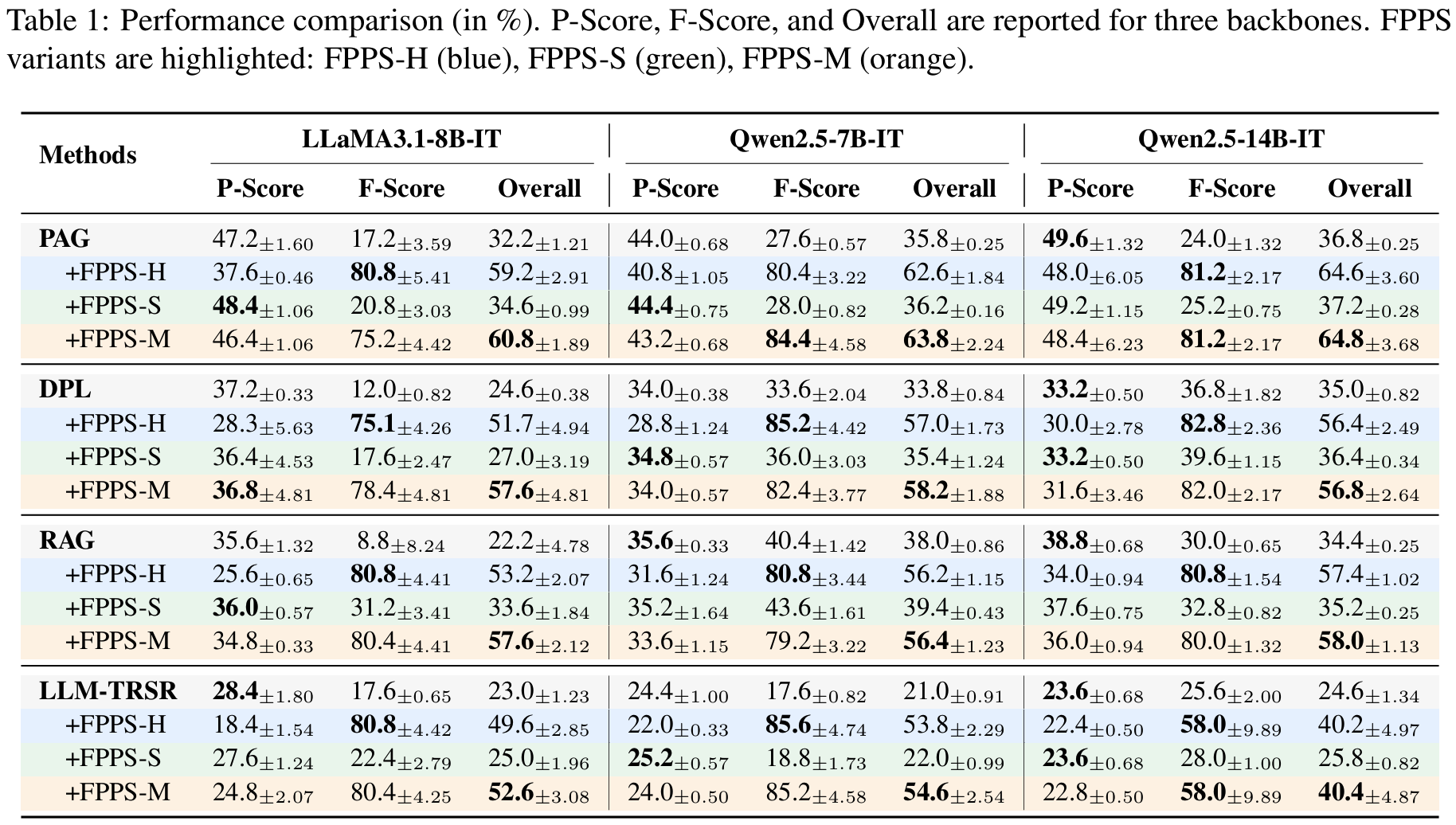
- main results (Tab. 1): baseline마다 각 steering 방식의 score 확인
- FPPS-H: F-score를 크게 끌어올리지만 P-score 하락 가능성. 즉 사실은 잘 복원하는 듯하지만 personalization 손상
- FPPS-S: P-score를 보존하지만 F-score 개선이 제한적. 즉 사실 복원 효과는 미미
- FPPS-M: overall이 가장 안정적으로 큼
- Ablation
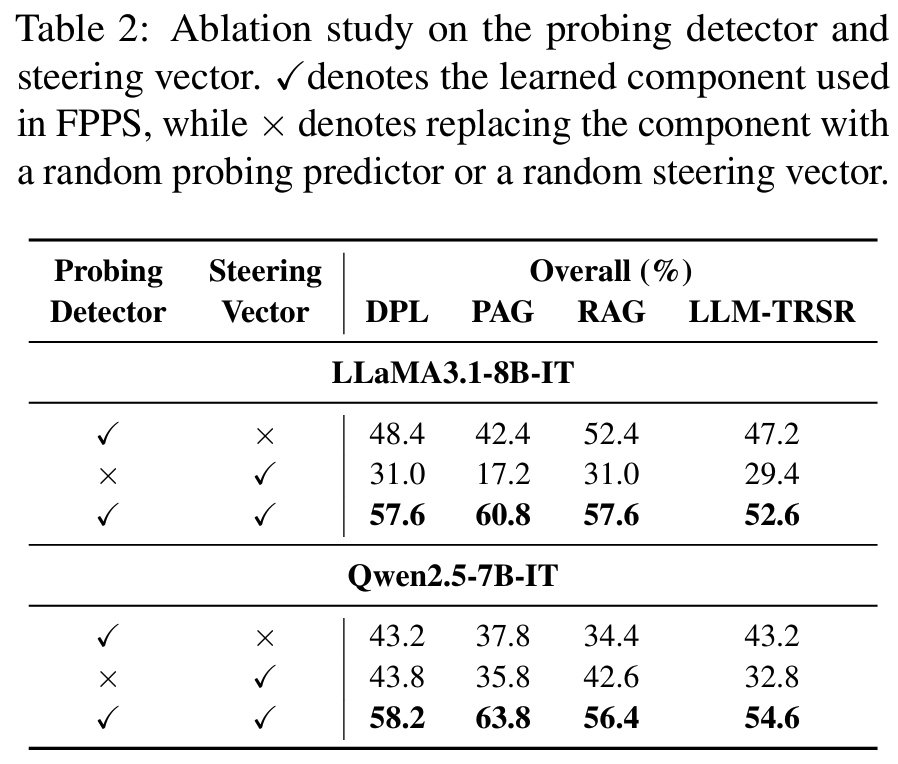
- Tab. 2: probe + steering vector 둘 다 학습돼야 하는지 확인
- probing detector를 랜덤으로 하면 언제 intervention 해야 하는지 못 잡아서 성능 불안
- steering vector를 랜덤으로 하면 intervention이 오히려 representation을 붕괴시킴
- 즉 개입 여부 판단 (probe) + 개입 방향 (steering vector) 모두 구조화돼야 성립
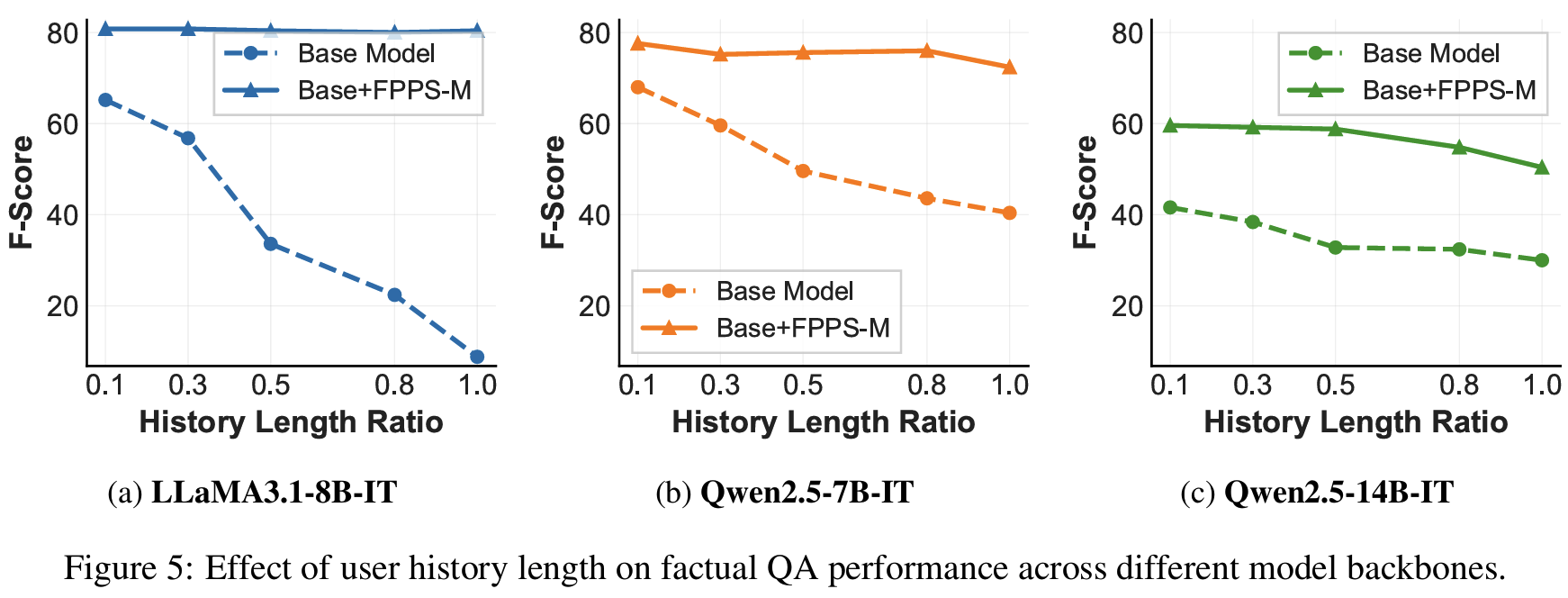
- Fig. 5: user history length가 늘수록 factual QA 성능이 떨어짐. FPPS 활용 시 이 하락 완화
- long-term memory, 과도한 context가 personalization drift를 강화
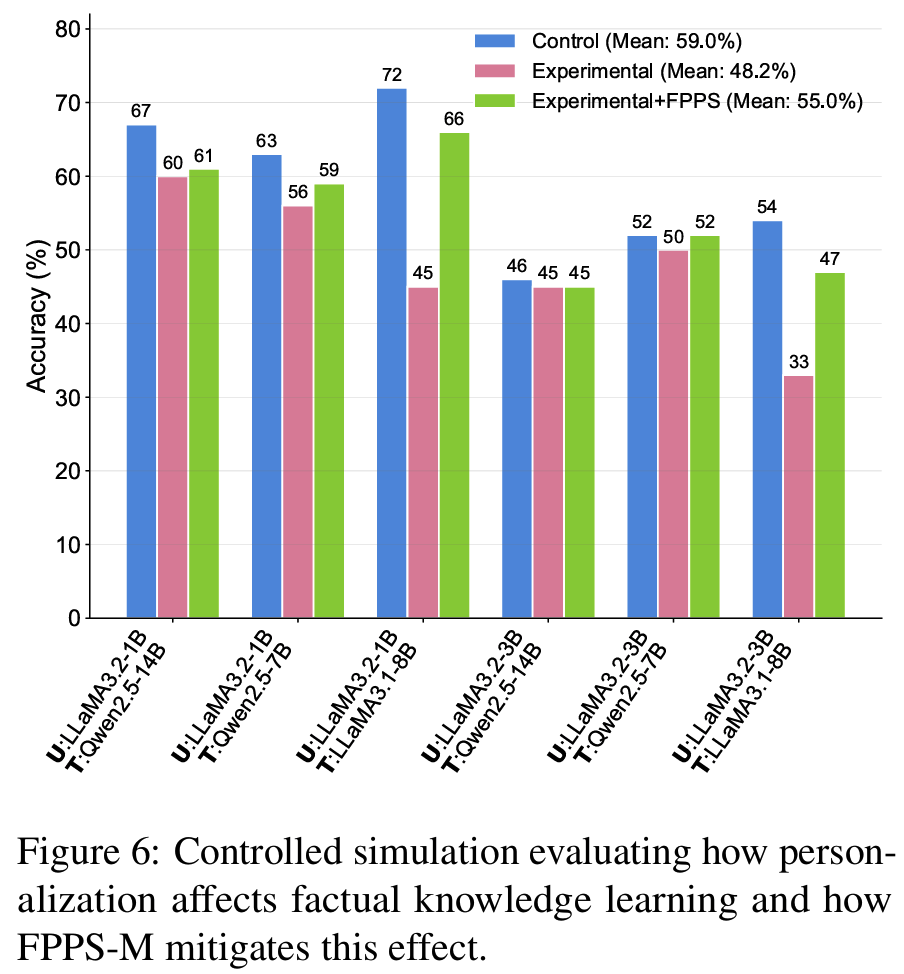
- Fig. 3, Fig. 6: personalization-induced hallucination은 순간적인 오답이 아니라 사용자에 대한 belief/knowledge acquisition에 영향을 줘서 장기적으로 틀린 지식 강화 위험
- Fig. 7: threshold 민감성 관련 성능이 안정적인 plateau가 있음
- Tab. 2: probe + steering vector 둘 다 학습돼야 하는지 확인
- main results (Tab. 1): baseline마다 각 steering 방식의 score 확인
Personal note. KC 관점에서 preference(가 담긴 user memory와의) 충돌을 고민해본 연구 같습니다. steering 하겠다는 흐름은 적용 관점에서 특별해 보이지 않을 수도 있지만, 앞에서부터 탄탄한 분석과 함께 논지를 일관되게 끌고 나가는 힘이 강하다고 느꼈습니다. (효과가 대단히 명확하지 않더라도, 이 문제가 모호한 구석이 있기 때문에…)