MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Meta info.
- Authors: Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Bryan Kian Hsiang Low, Paul Pu Liang
- Paper: https://openreview.net/pdf?id=XY8AaxDSLb
- Code: https://github.com/MIT-MI/MEM1
- Affiliation: SMART, NUS, MIT, Yonsei Univ.
TL; DR
memory consolidation과 reasoning을 하나의 internal state로 통합하도록 RL 학습하여 long-horizon task에서 거의 일정한 context size 유지하며 성능 향상
Review Video

Background
- multi-turn QA, web navigation, tool-using agent 등에서 long-horizon reasoning 요구 증가
- 기존 연구는 대체로 모든 이전 interaction을 prompt에 그대로 포함
- attention cost가 context 길이에 따라 O(N^2)로 증가
- OOD: training horizon보다 긴 상황에서는 generalization 급격히 저하
- 다른 한편 external memory module, retrieval-based compression, hierarchical memory 등 제안
- memory management가 policy 학습과 분리
- reasoning policy가 어떤 정보를 유지하고 어떤 정보를 버릴지 학습하지 못함
Problem States
memory consolidation을 reasoning 과정에 내재적으로 학습할 수 있는가?
- long-horizon 환경에서 full-context accumulation의 비효율성
- memory module과 policy learning의 분리로 인한 구조적 한계
Suggestions
- formulation: MDP 하에서 cumulative reward 최대화 + memory usage를 제한되어 유지
- memory가 horizon에 따라 선형 증가 없이
- memory 축소 과정이 task performance에 loss 없이
- consolidated state가 이후 reasoning에 충분한 정보를 포함
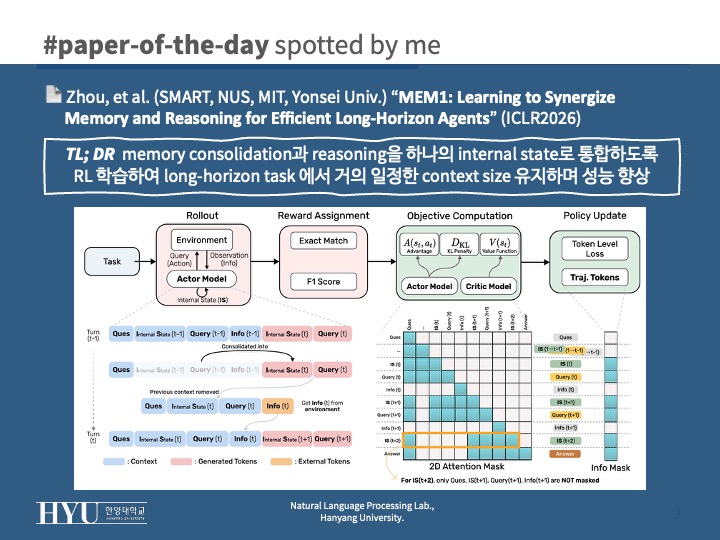
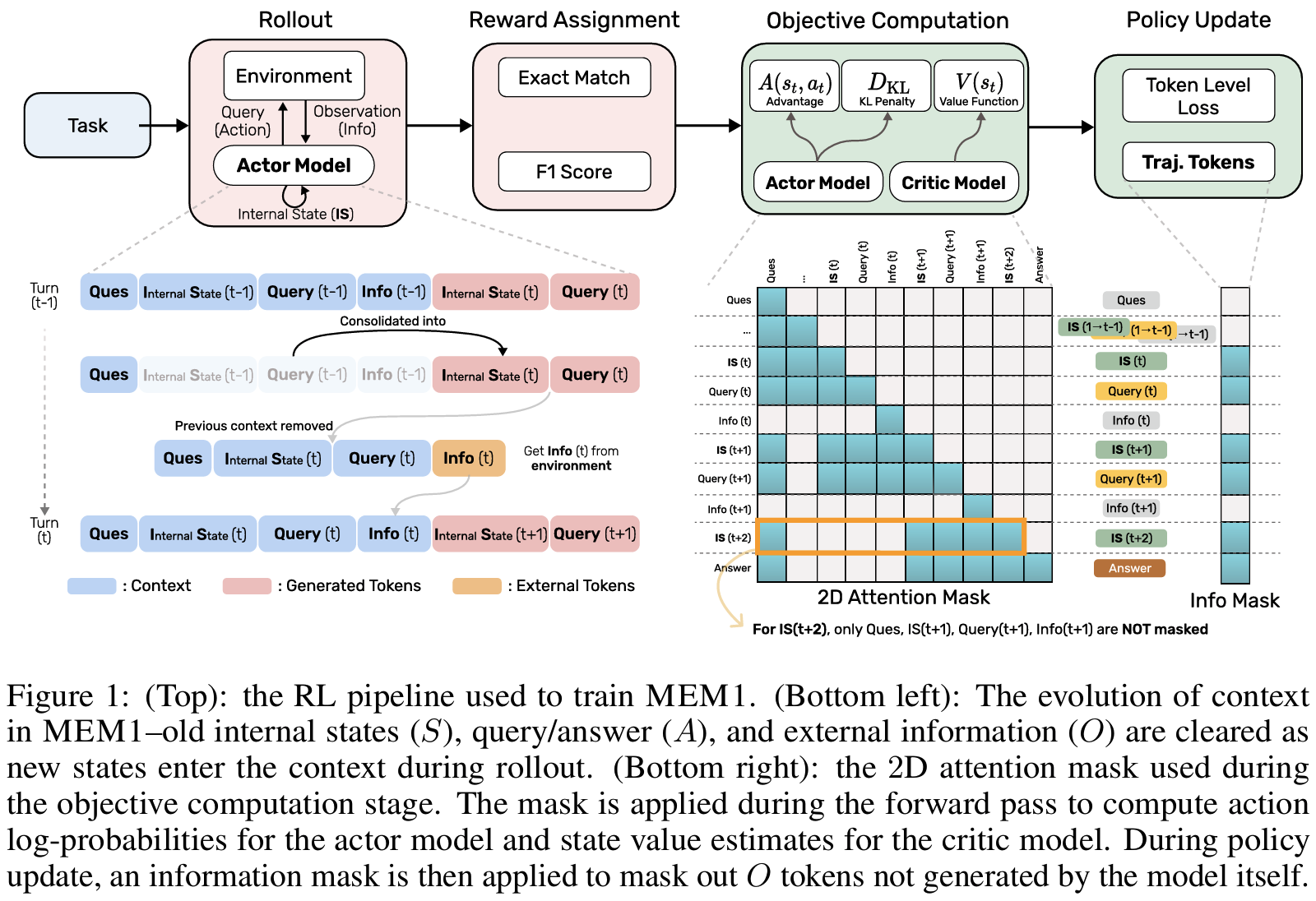
- MEM1:
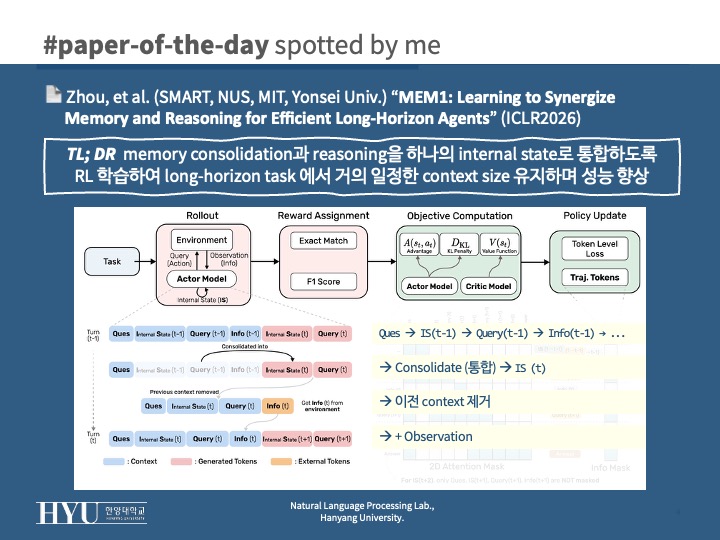
- memory: 매 step t 마다 생성하는 internal state S_t
<think> ... consolidated reasoning state ... </think>에서 state consolidation 수행- S_t = f(S_{t-1}, A_{t-1}, O_{t-1})
- 입력: 이전 internal state S_{t-1}, 이전 action A_{t-1}, observation O_{t-1}
- f: LLM
- 현재까지 해결된 sub-goal + 아직 해결되지 않은 objective + 필요한 intermediate fact + 다음 query 계획
- 매번 rewrite해야 하므로 우려사항: compression-sufficiency trade-off
- 너무 많이 압축하지도 너무 적게 압축하지도 않도록 어떤 정보를 유지하고 어떤 정보를 버릴지 학습해야 함
- optimization: S_t도 모델의 생성 결과이므로 PPO로 동시 학습 수행
- reward 설계: Multi-Objective QA에서 Exact Match / WebShop에서 final reward
- 의도: gradient는 잘못된 action이나, 불충분한 memory로 action 실패 시 reward 감소
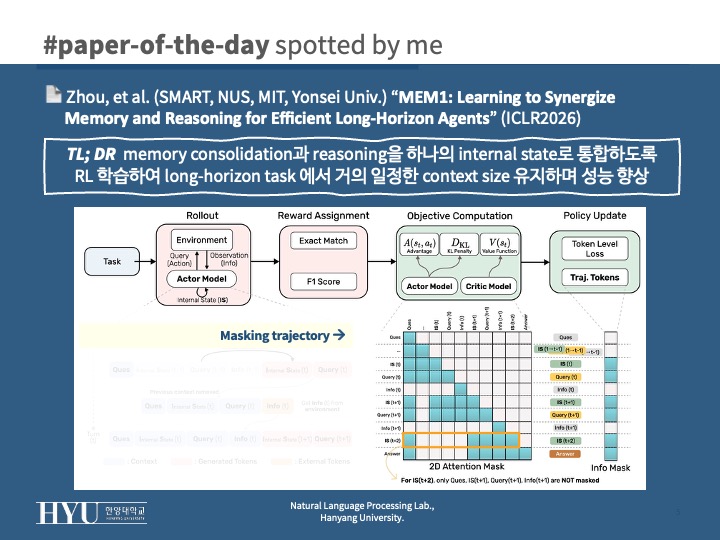
- 문제: PPO는 전체 trajectory의 log-prob를 계산해야 하나, MEM1은 매 step에서 raw context는 버림
- 해결: masked trajectory (전체 trajectory를 1개 시퀀스로 붙이되 attention mask 조작)
- 각 token은 자기 step에서 실제로 접근 가능했던 history만 보도록 이전 raw history는 masking
- 오직 해당 시점의 internal state + 해당 turn 내 토큰만 attend 가능하도록 (policy gradient consistency 유지)
- memory: 매 step t 마다 생성하는 internal state S_t
Effects
- Experimental Setup
- datasets:
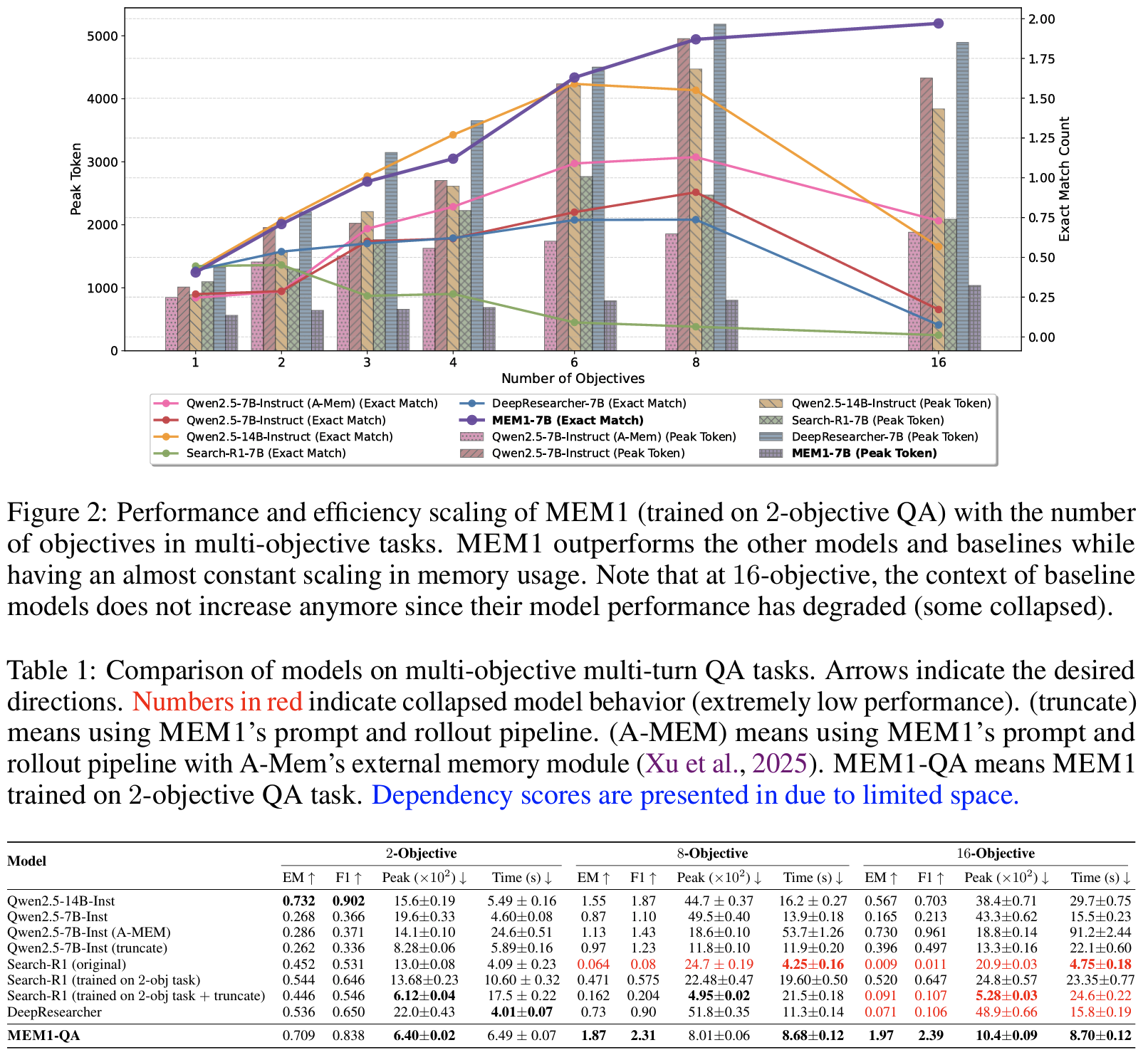
- Multi-Objective QA Design: long-horizon generalization을 정량 측정 가능하도록 실험적 환경 설계 (synthetic horizon 확장)
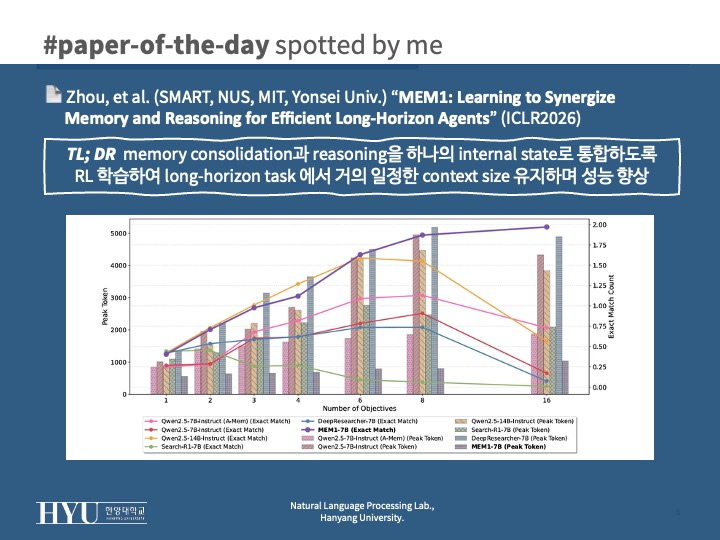
- 기존 multi-hop QA는 horizon이 짧기 때문에 여러 QA를 하나의 composite objective로 묶음 (2, 8, 16 objective로 scaling)
- Long-horizon QA: HotpotQA + NQ
- training에는 2-objective (짧은 horizon)만 활용하고 test는 8-/16-objective (긴 horizon)로 수행
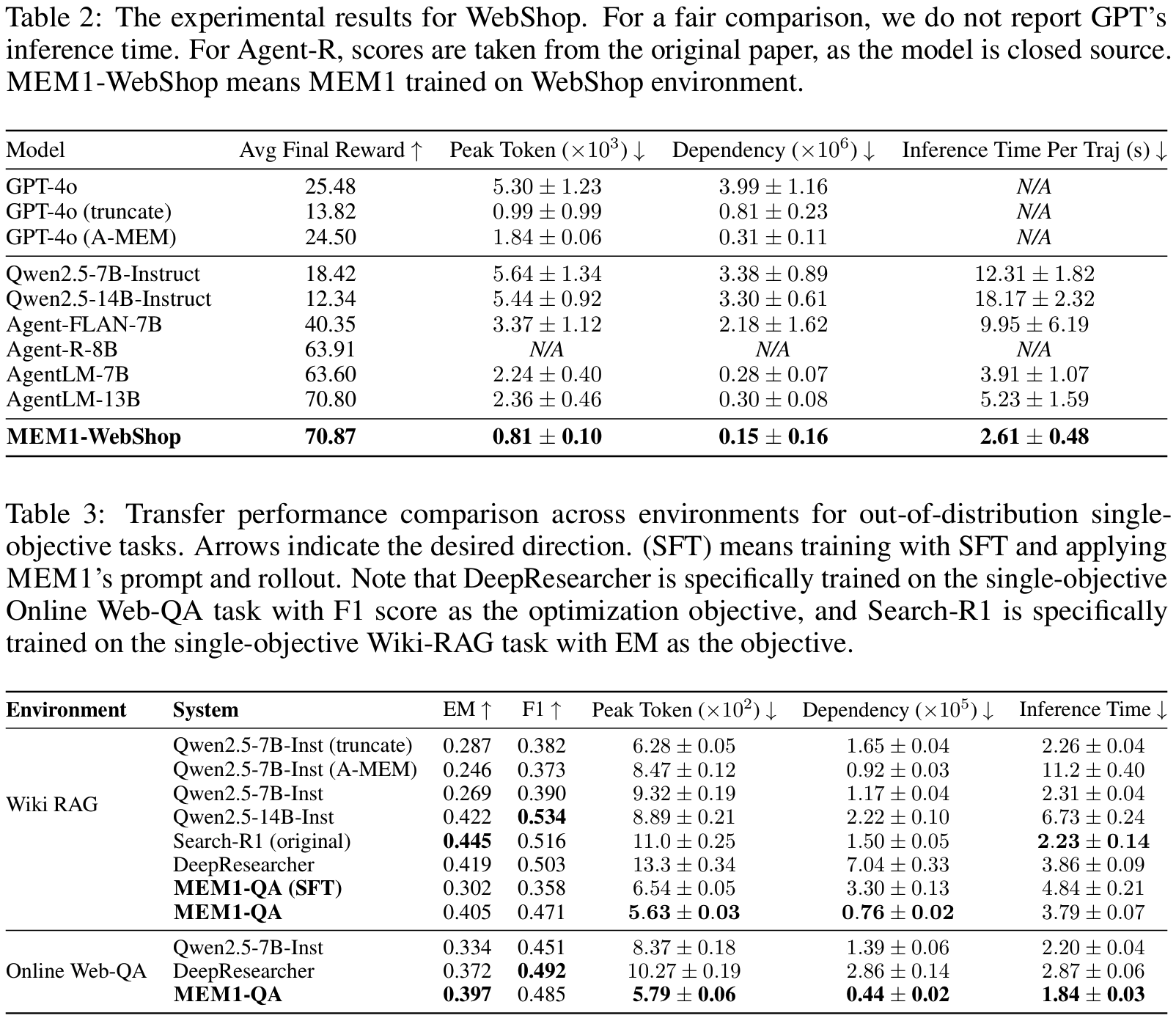
- WebShop
- Multi-Objective QA Design: long-horizon generalization을 정량 측정 가능하도록 실험적 환경 설계 (synthetic horizon 확장)
- metrics:
- QA: EM, F1
- WebShop: final reward
- efficiency: peak token usage, average dependency, inference time
- baselines:
- QA: Search-R1, DeepResearcher, Qwen2.5-14B-Instruct
- WebShop: Agent-FLAN, Agent-R, AgentLM
- context compression baselines: A-MEM (vector 기반 retrieval)
- MEM1, MEM1-w/o RL (only prompting)
- SFT baseline: gpt-4o trajectory로 supervised fine-tuning
- datasets:
- Results:
- Tab 5 RL vs. SFT: SFT는 objective가 6개 이상이면 성능 붕괴
- Tab 6 integrated vs. separate memory: memory와 reasoning을 분리하면 성능 하락
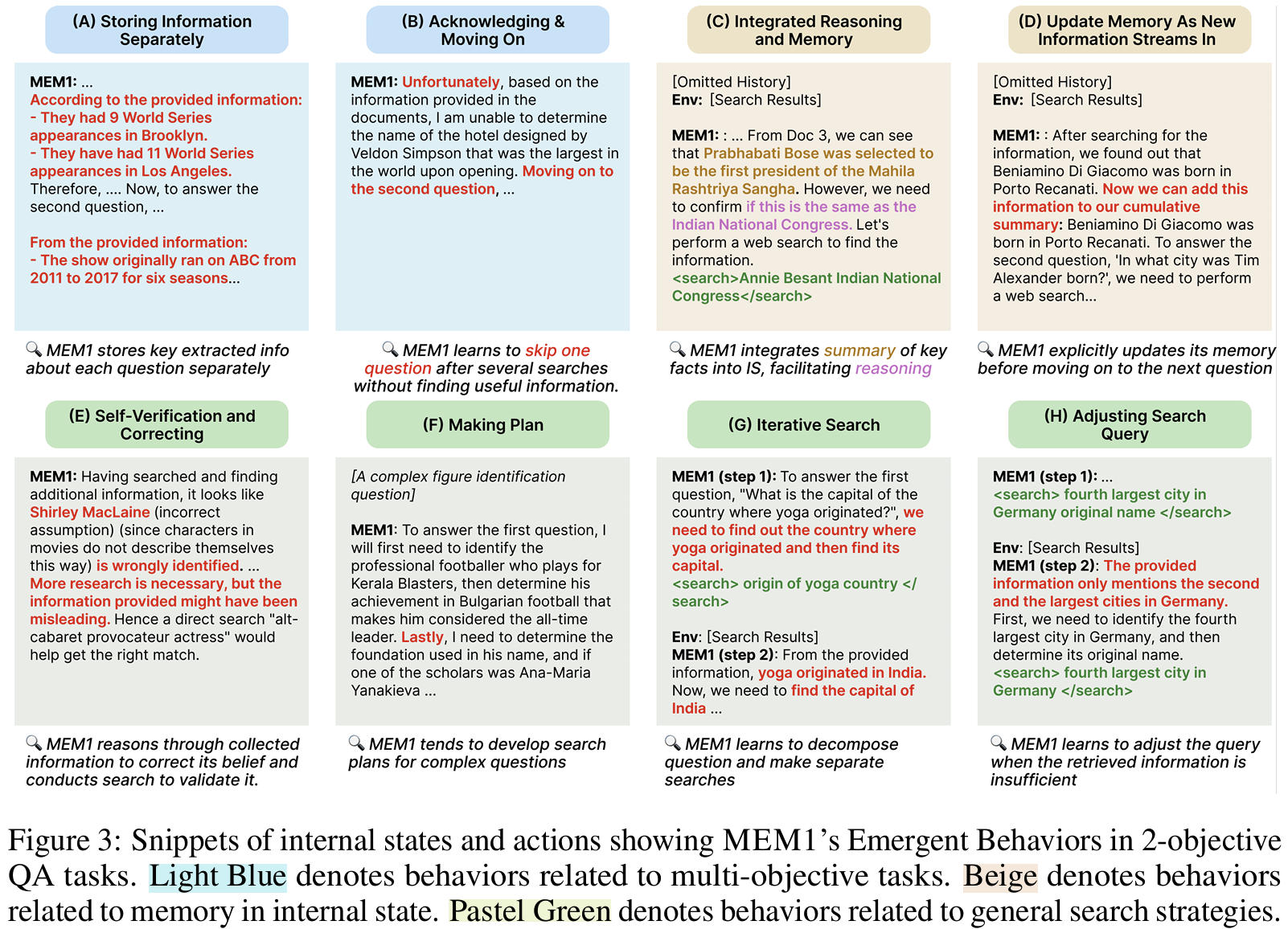
- Fig 3 emergent behavior: memory control을 학습하면 planning behavior가 emergent하게 나타난다
- emergent behavior: parallel tracking, query decomposition, self-verification, memory overwriting 등
memory 안에 담는 것은 summarization이 아니라는 점과 메모리를 어떻게 업데이트칠지 결정하는 부분은 PRefine과 유사한 지점입니다. 오히려 정답문제가 명확하도록 (실험환경이지만) long-horizon 문제를 설계하고 이를 바탕으로 RL 학습의 재료로 쓴게 주요 기여라고 느껴집니다. 이론적으로 masking trajectory가 증명된 건 아니라 아쉽지만 이는 저자들도 인정하는 부분이며, case study를 빡세게 해서 마지막에 (타당한지는 모르겠지만) 어쨌든 자가 수정이나 재작성을 명시적으로 지시하지 않았는데 끌어냈다는 점을 emergent behavior라고 정리한게 서술 측면에서 유익했다고 느껴집니다.
Personal note. memory를 별도 저장소로 다루는 흐름에서 한 단계 더 나아가, memory update 자체를 policy 학습에 포함시키려 한 점이 인상적이었습니다. 특히 long-horizon 일반화에서 SFT 대비 RL 차이를 명확히 보여준 건 설득력이 있었고, 다만 masked trajectory 정당화가 아직 실험적 주장에 머무는 만큼 후속 이론 보강이 붙으면 더 강해질 것 같습니다.