Memex(RL): Scaling Long-Horizon LLM Agents via Indexed Experience Memory
Meta info.
- Authors: Zhenting Wang, Huancheng Chen, Jiayun Wang, Wei Wei (Accenture)
- Paper: https://arxiv.org/pdf/2603.04257
- Published: March 5, 2026
TL; DR
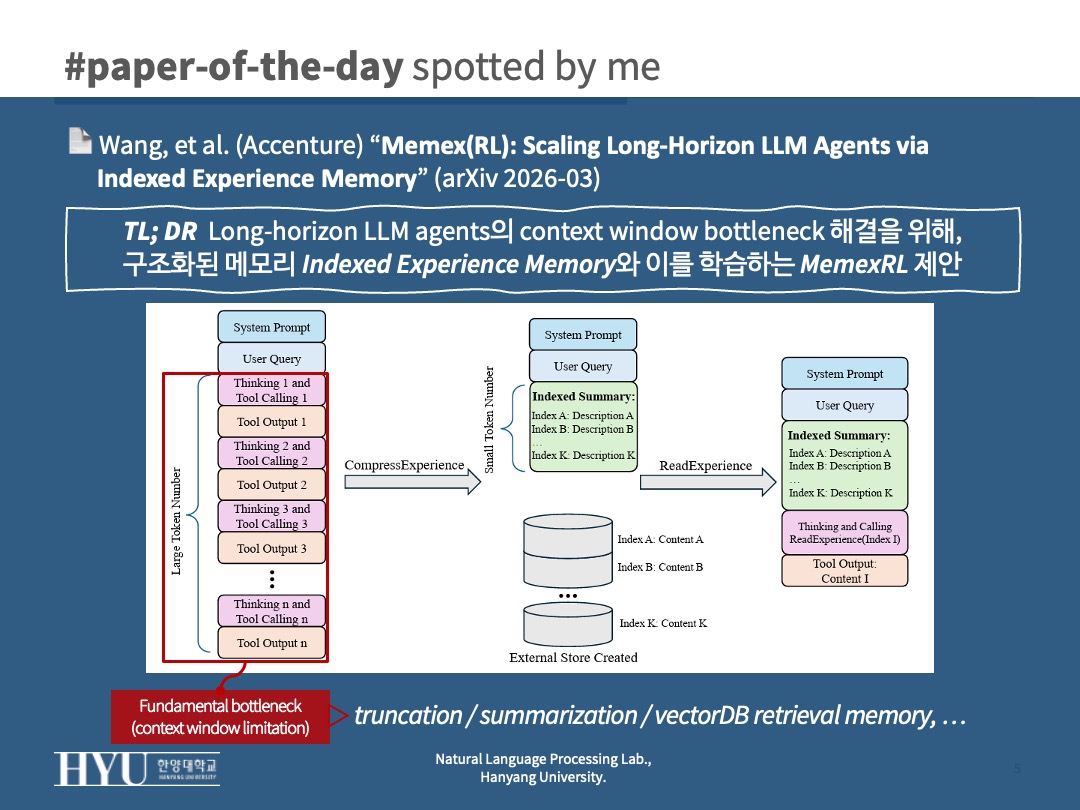
Long-horizon LLM agents의 context window bottleneck 해결을 위해, 구조화된 메모리 시스템 Indexed Experience Memory와 이를 학습하는 MemexRL 제안
Review Video








Background
- long-horizon tasks: multi-step tool use, multi-API orchestration, code debugging, literature search, …
- fundamental bottleneck = context window limitation
- truncation / summarization / vectorDB retrieval memory 등의 해결 접근
- 정보 손실 발생 혹은 retrieval 자체는 memory의 구성을 건들지는 못하는 점에서 한계
Problem States
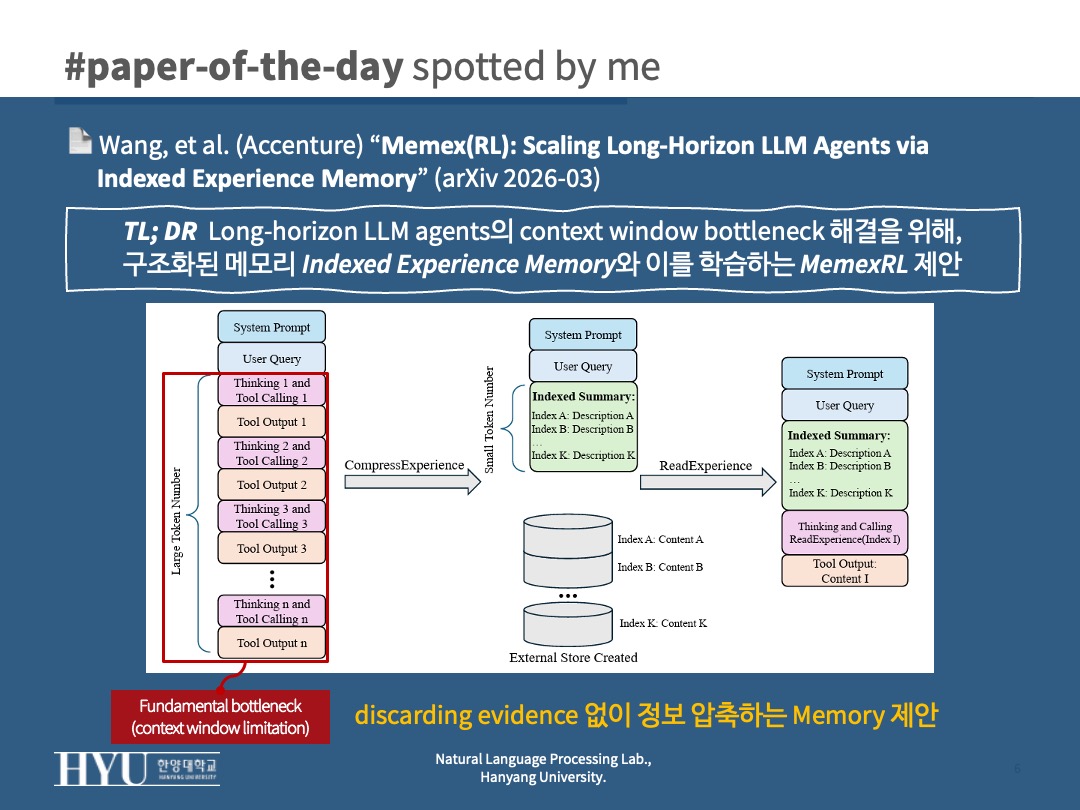
discarding evidence 없이 정보 압축
- long-horizon tasks에서 LLM은 (1) small working context + (2) full-fidelity past evidence 필요하지만,
- 기존 방법론들이 둘 중 하나만 취함
- full history -> context overflow
- summary -> evidence loss
- retrieval -> fuzzy reference
- research question:
- MemexRL이 실제 long-horizon agent 문제를 해결하는지
- context compression과 retrieval 정책이 실제로 작동하는지
Suggestions
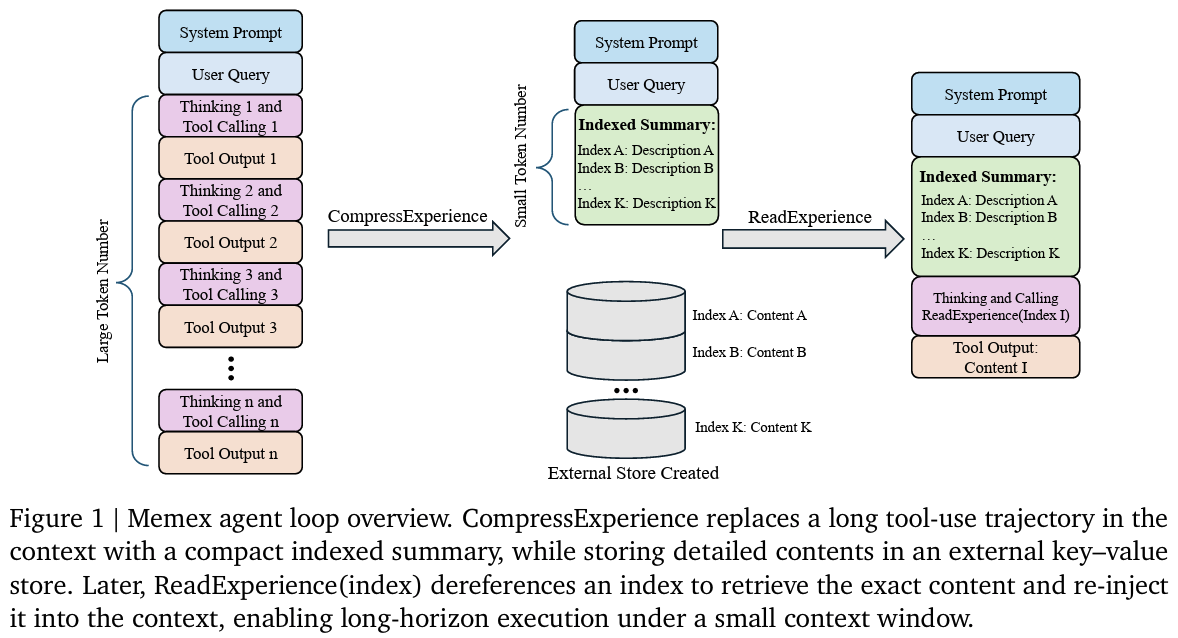
- Memex (Indexed Experience Memory) : 프롬프트에는 쿼리 + 현재 상태 + index별 요약만 남기고 실제 내용을 외부에 저장
- formulation
- σ = (s, I)
- s: actionable progress state. 현재까지의 관측, 다음 계획 등
- I: index map. {index, description}
- D: external store. D[index] -> content
- content(= 원문): tool output, code snippet, logs, reasoning trace, …
- σ = (s, I)
- operation: Agent가 call/use 할 수 있는 actionable 형태의 tool API들
- CompressExperience: 현재 trajectory 압축 및 full artifact를 D에 저장
- ReadExperience: index를 기준으로 D에 있는 full artifact 다시 불러오기 (recover)
- ExecuteTool: 일반적인 agent tool-call
- Finish: task 종료 action
- formulation
- MemexRL: memory management는 long-horizon assignment에 대한 문제이므로, policy의 문제 = memory action도 학습하자
- problem: tool 선택을 어떻게 할지 즉 언제 압축하고 언제 저장하고 언제 index를 읽을지를 결정하는건 단순 프롬프팅으로 불가하다고 주장
- e.g. 앞쪽 step에서 저장한 메모리가 한참 뒷쪽 step에서 도움을 준다면 즉각 보상도 없고 단순 prompting으로 학습 불가
- formulation:
- state = context; context: system prompt, task, indexed summary, index map, retrieved artifacts
- action: A = {CompressExperience, ReadExperience, ExecuteTool, Finish}
- reward: R = (task reward) - (context overflow penalty) - (redundant tool penalty) - (format error penalty)
- task reward: task 완료
- context overflow penalty: context 길면 불리
- redundant tool penalty: 같은 tool 반복 호출시 불리
- format error penalty: tool-call format 오류시 불리
- trajectory segmentation: compression이 발생하면, trajectory를 segment로 나눈다
- compression 이후에는 원본 history가 삭제되므로, trajectory를 compressed unit으로 학습하기 위함 (= memory episode)
- e.g. step 1 -> step 2 -> step 3-> CompressExperience -> step 4 -> step 5 -> step 6 -> CompressExperience -> step 7 -> ,,, 에 대해, segment 1이 step 1~3, segment 2가 step 4~6 …
- trajectory segmentation
- memex의 역할은 trajectory를 segmented trajectory로 변환, compression을 RL 학습 단위로 적용
- -> long-horizon credit assignment 문제 (리워드는 episode 끝나야 나옴)에 대한 일종의 해결 제공
- horizon reduction: Markov Property Recovery
- context에 partial history만 들어있기 때문에 일반 agent에서는 state가 사실상 non-Markovian
- -> memex가 Markov state를 apprixomate하므로 마찬가지로 일종의 해결 제공: P(s_{t+1} | history) ≈ P(s_{t+1} | σ_t)
- compression 이후에는 원본 history가 삭제되므로, trajectory를 compressed unit으로 학습하기 위함 (= memory episode)
- training pipeline: trajectory 생성 -> compression 기준으로 segmentation -> 각 segment에 reward 할당 -> PPO
- compression timing: 언제 compress 할지
- what to archive: 언제 D에 저장할지
- retrieval decision: 언제 다시 D를 읽어올지
- problem: tool 선택을 어떻게 할지 즉 언제 압축하고 언제 저장하고 언제 index를 읽을지를 결정하는건 단순 프롬프팅으로 불가하다고 주장
- Theoretical analysis (justification)
- Decision quality preservation : Memex can match a full-context optimal policy.
- Decision-sufficient indexed summary : σ_t is B-bounded decision-sufficient
- full history 기반 optimal policy = summary + retrieved blocks 기반 policy
Effects
- Experimental Setup:
- Environment: ALFWorld 수정
- admissible comomands 제거 : 원래 ALFWorld는 필요한 행동 목록을 다 주는데 제거,
- initial observation 제거 : 환경의 초기 상태 설명도 제거,
- look action 제한 : environment를 다시 보여주지 않도록 제한; look = free memory reset
- summary length 제한:
- Backbone: Qwen3-30B-A3B-Thinking
- Baselines:
- full-context agent: no compression
- Memex (no RL): memory actions을 배우진 않음
- MemexRL: memory action까지 배움
- Environment: ALFWorld 수정
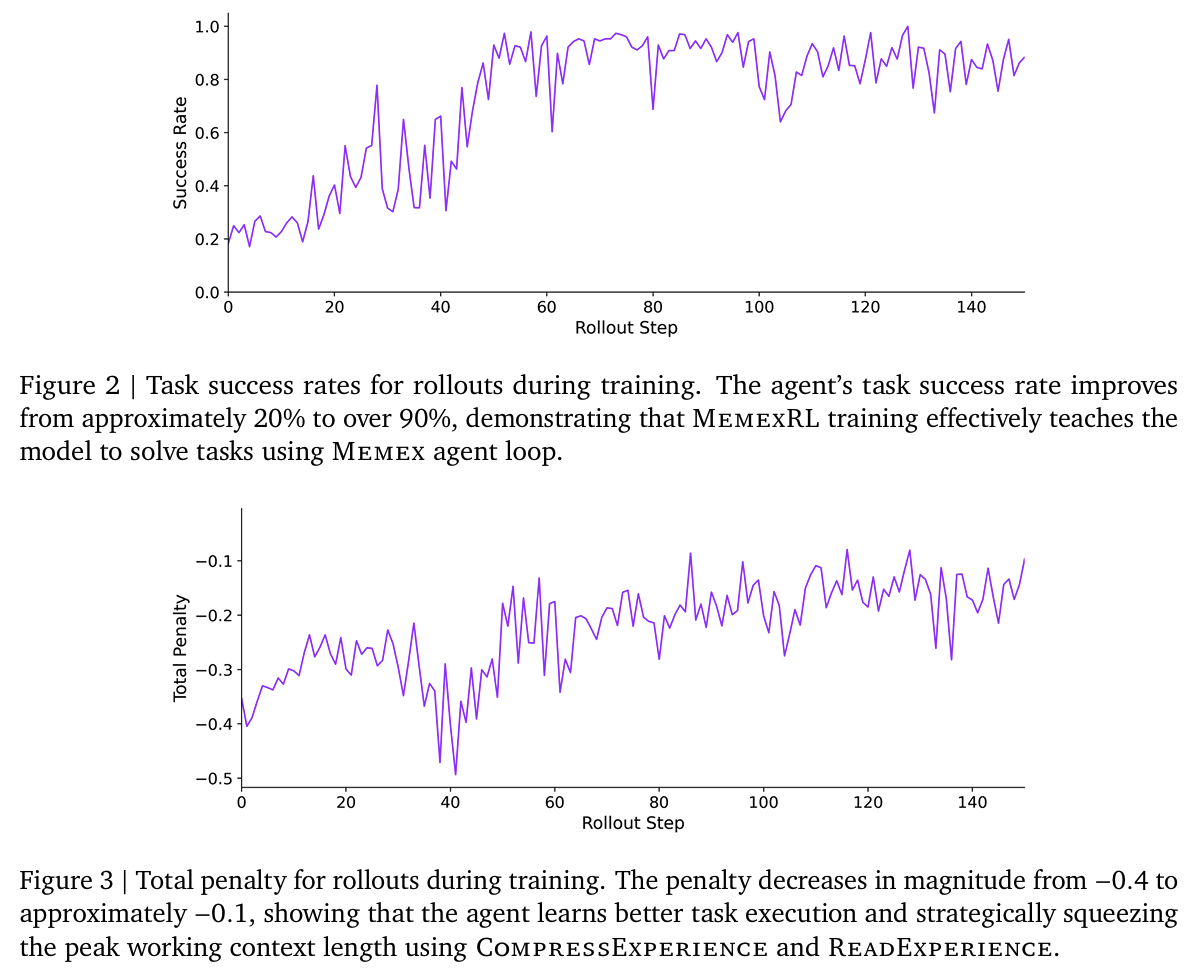
- Results: 더 잘 long-horizon task를 해결하면서 context size는 줄이고, memory 자체를 잘 활용하게 됨.
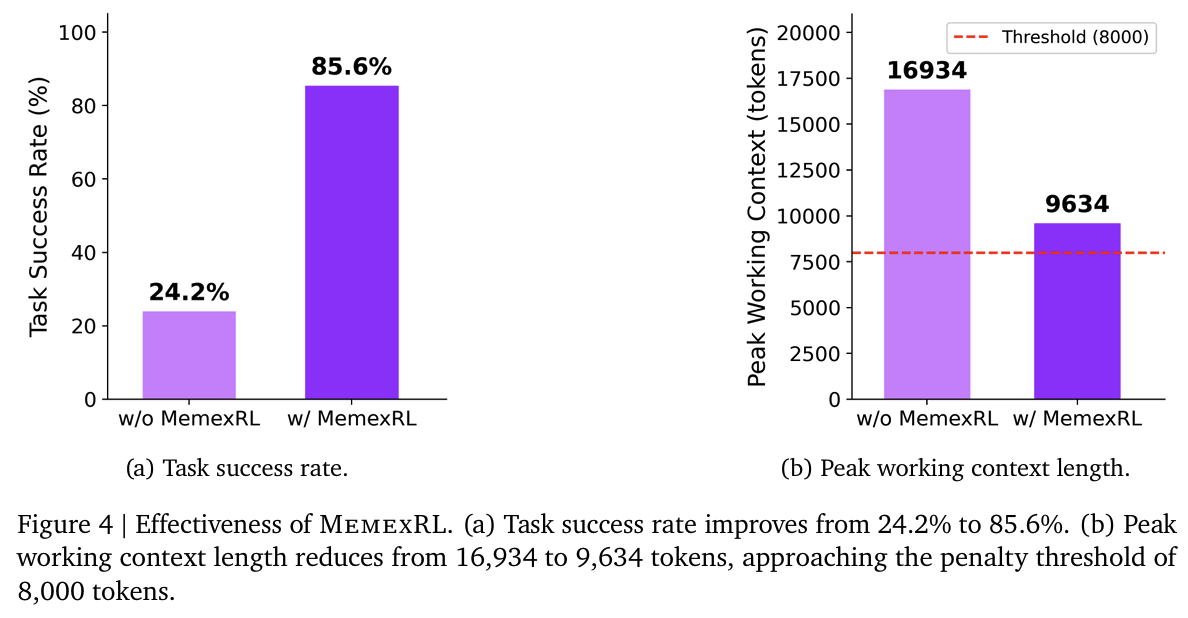
- Fig 4 (a): main results; MemexRL > Memex > baseline
- baseline: long trajectory가 context overflow를 일으키므로 중요 정보가 잘림
- Memex: compression으로 memory 유지
- MemexRL: + retrieval policy까지 최적화됨
- Fig 4 (b): context 길이 비교; peak 기준 43%가량 감소
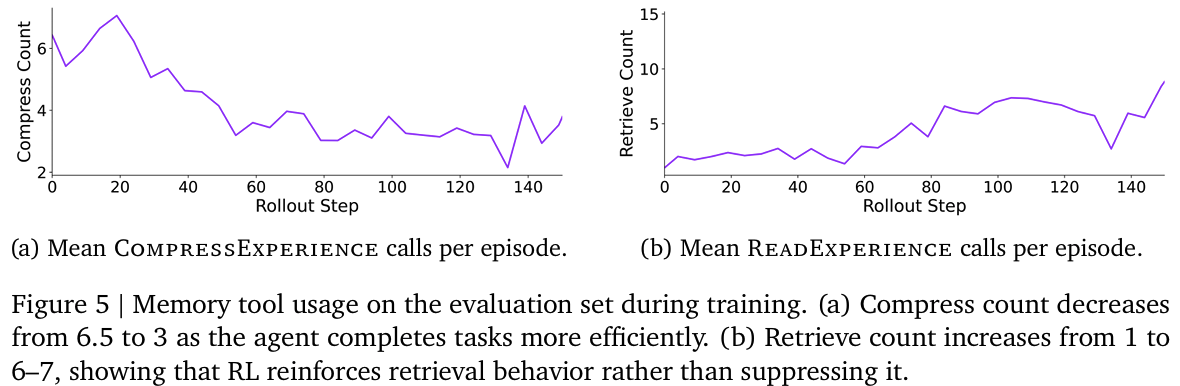
- Fig 5: memory tool usage frequency 분석; Memex만으로는 compression을 너무 자주하고, +RL 해야 제대로 archive > recover 수행
- tool call 횟수: Memex 6.5-call > MemexRL 3-call
- retireval 횟수: Memex 1-retrieval < MemexRL 6~7-retrieval
- Fig 4 (a): main results; MemexRL > Memex > baseline
- Limitation; ALFWorld라는 환경 제약, Domain 역시 한정적, index scaling 문제는 범위 밖으로 상정
Personal note. memory 연구에서 RL 접목한 시도가 자주 보이고, 이 연구 역시 그 흐름을 크게 벗어나지 않습니다. 이 연구의 memory 구조를 거칠게 요약하면, memory를 dict 형태로 정의하고, 상대적으로 memory마다 아주 짧은 요약을 들고 있으면서 이를 retrieval의 key로 사용하는 방식으로 compression을 수행한다고 할 수 있습니다. 이와 같이 memory를 정의하고, 그에 맞춰서 reward 설계 후 optimize한다는 흐름 자체는 매우 평이한데, 어느 환경에 어떻게 적용해서 평가를 하는지가 실질적인 개선 폭을 눈속임(?) 한다고 느낍니다. 물론 그런 환경을 잘 찾는 것이 중요하겠지만, PRefine과 매우 비슷한 방식의 아키텍쳐를 어떻게 적용할 것인지에 대한 흐름을 주목해볼만 하다고 느낍니다.
중간에 이론적 분석에 대한 부분은 타당한건지 잘 판단이 서지 않습니다..(안와닿음..)