Honeybee: Locality-enhanced Projector for Multimodal LLM
Meta info.
- Authors: Junbum Cha, Wooyoung Kang, Jonghwan Mun, Byungseok Roh
- Paper: https://arxiv.org/pdf/2312.06742
- Code: https://github.com/kakaobrain/honeybee
- Affiliation: Kakao Brain
- Conference: CVPR 2024
TL; DR
MLLM에서 vision encoder와 LLM 사이의 visual projector가 핵심 병목임을 분석하고, visual token flexibility와 locality preservation을 동시에 만족하는 Honeybee projector를 제안

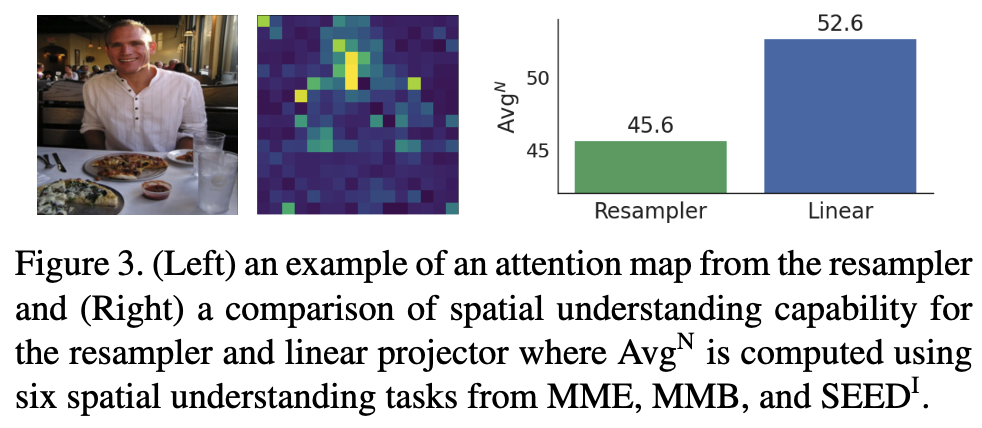

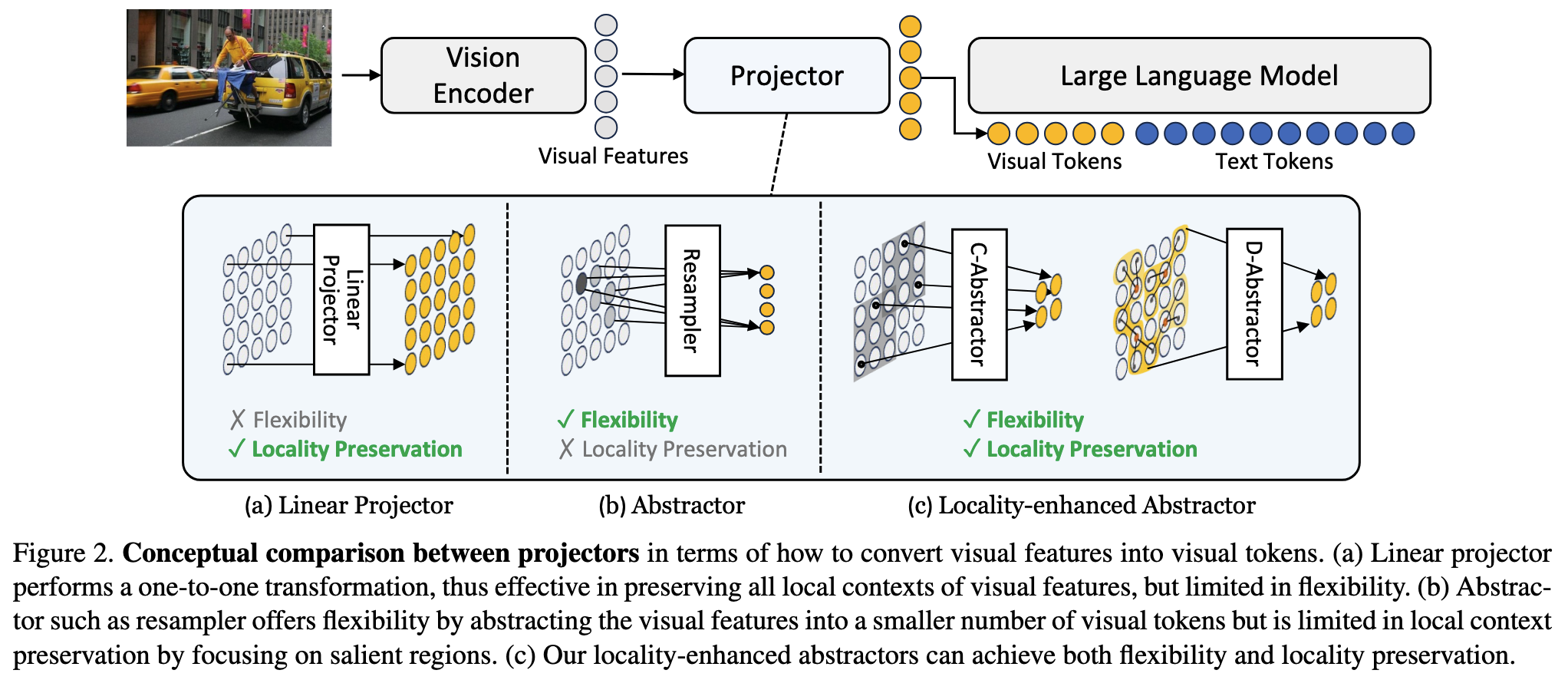
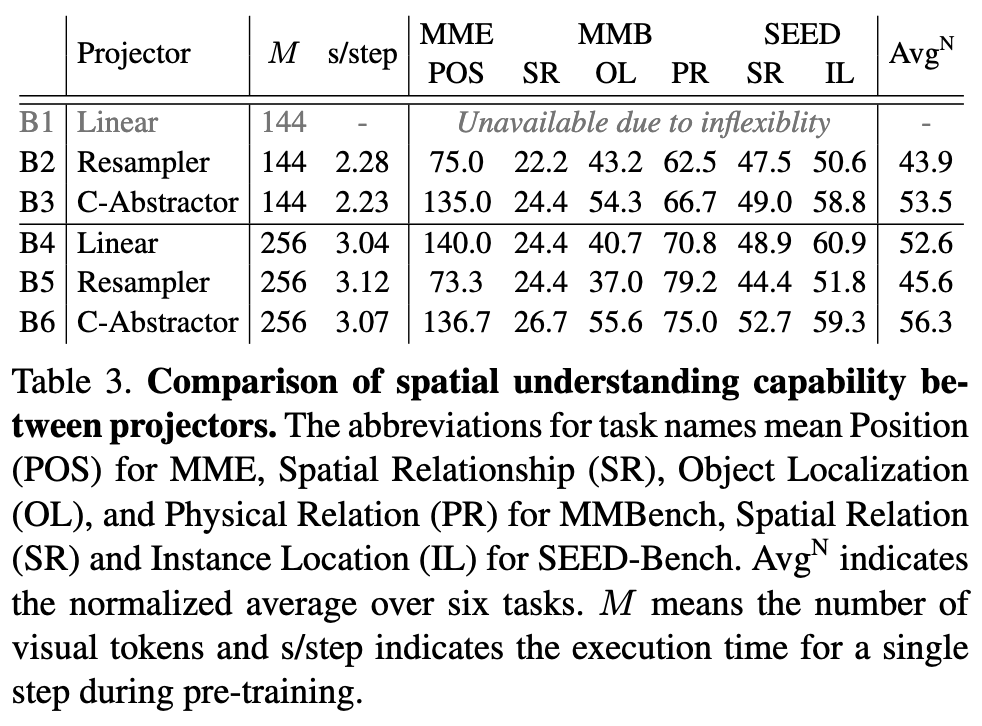
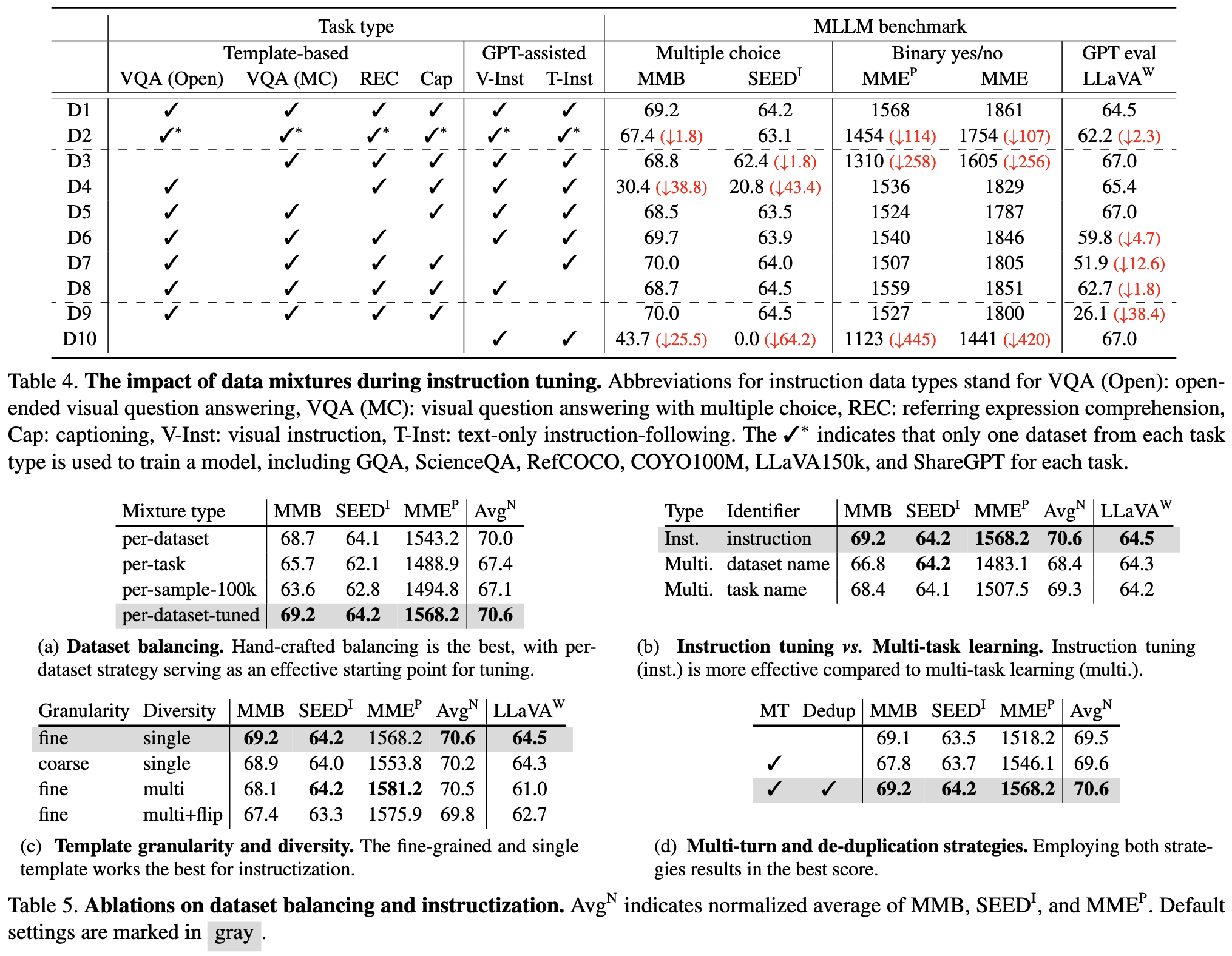
Background
- MLLM은 대체로
image -> visual projector -> LLM -> text구조를 가짐- LLaVA의 linear projector, BLIP-2의 MLP/Q-Former, Flamingo의 resampler 등 다양한 projector가 존재
- 그런데 기존 연구의 초점은 주로 vision encoder나 LLM 자체에 있었고, projector는 상대적으로 가볍게 다뤄짐
- 저자들은 visual projector가 단순한 연결부가 아니라, 성능과 효율을 함께 좌우하는 병목이라고 주장
Problem States
좋은 visual projector는 token flexibility와 spatial locality preservation을 동시에 만족해야 한다.
- Vision token flexibility 부족
- linear projector나 fixed MLP는 visual token 수를 유연하게 줄이기 어려움
- image resolution이 올라가면 ViT token 수도 급증해서 LLM inference cost가 크게 늘어남
- Local context preservation 부족
- vision feature는 본질적으로 spatial structure를 가지는데, flatten 후 projection하면 이 locality 정보가 쉽게 손실됨
- spatial reasoning, OCR, grounding 같은 task에서 이 손실이 더 치명적일 수 있음
Suggestions
- Honeybee: locality-enhanced projector architecture
- 전체 흐름은
vision encoder -> feature map -> locality-enhanced token compressor -> visual projector -> LLM
- 전체 흐름은
- (1) Locality-enhanced token compressor
- visual token 수를 줄이기 위해 local aggregation 기반 compression 수행
- 단순 token pruning이 아니라 neighborhood 단위의 spatial-aware compression을 적용
- convolutional aggregation과 neighborhood attention을 활용해 local structure를 유지하면서
N -> M (M < N)으로 축소
- (2) Locality-preserving projection
- 기존의 flatten 후 linear/MLP projection 대신, feature map 상태에서 convolution 기반 projection을 적용
- goal은 language space로 정렬하면서도 인접 patch 관계를 최대한 보존하는 것
- Training: 기존 MLLM 파이프라인을 크게 바꾸지 않음
- stage 1: image-caption 데이터로 vision encoder와 projector alignment
- stage 2: instruction tuning 데이터로 multimodal instruction-following 학습
Effects
- Experimental setup
- visual encoder: CLIP ViT-L/14
- LLM: Vicuna, LLaMA
- tasks: VQAv2, GQA, TextVQA, VizWiz, POPE 등
- Results
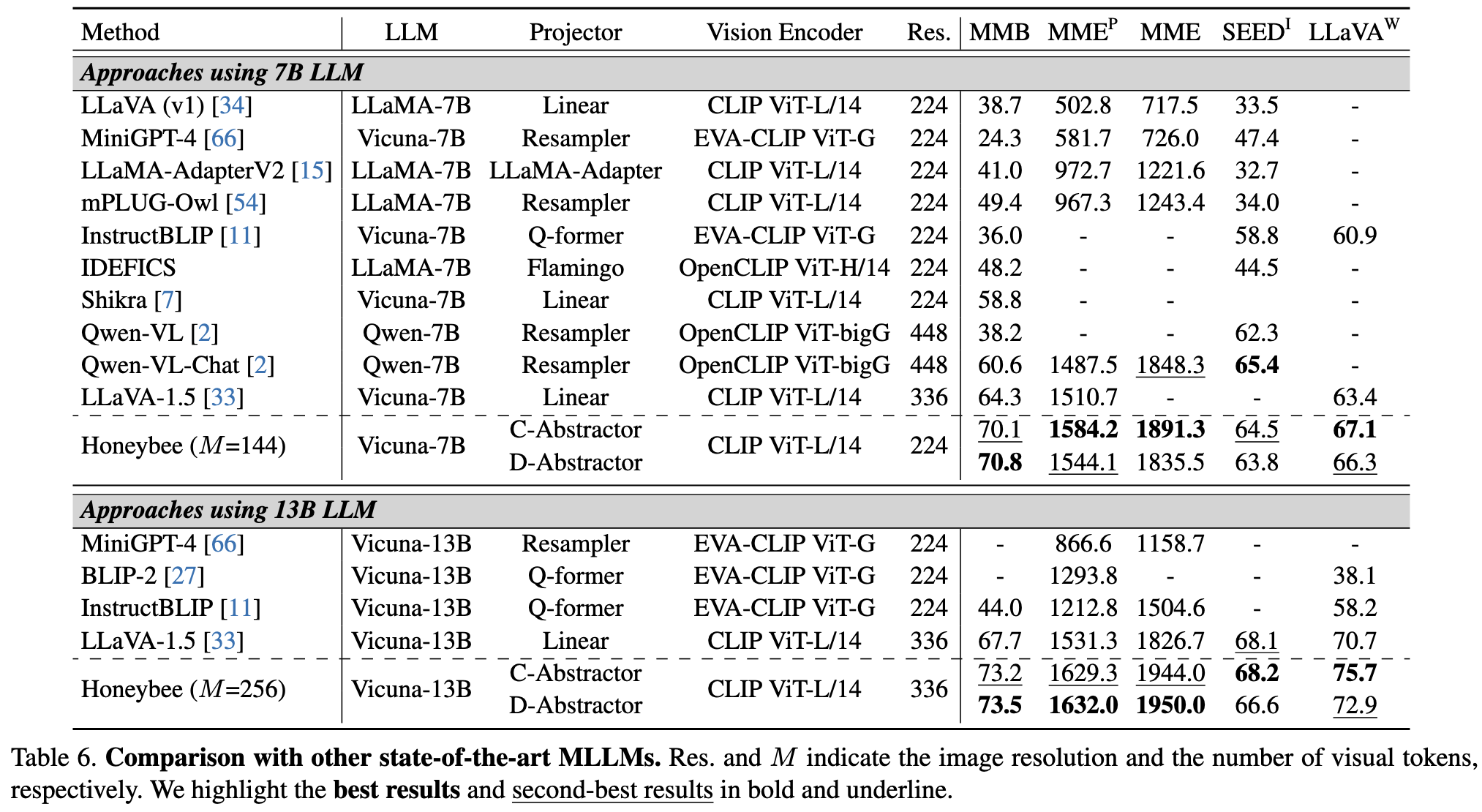
- 같은 compute budget 기준으로 Honeybee가 전반적으로 더 나은 성능을 보임
- 특히 spatial reasoning, OCR, visual grounding 관련 지표에서 강점이 확인됨
- visual token 수를 크게 줄여 LLM cost를 낮추면서도 성능 저하를 최소화
- 예시로 baseline 576 tokens 대비 144 tokens 수준으로 압축
- ablation에서도 token compressor와 locality modeling이 각각 유의미한 기여를 보임
Personal note. 카카오의 곧 출시 예정 서비스 backbone 모델인 kanana-v를 소개하는 세션에서도 이 페이퍼가 언급됐던 걸로 기억합니다. projector가 늘 중요해 보이는데도 MLLM 논의에서는 상대적으로 덜 조명된다는 인상이 있었는데, 이 글은 그 지점을 정면으로 다룹니다. 또 카카오가 이후 발표한 멀티모달 모델 흐름도 이후 기술 글과 자연스럽게 이어져 보여서 흥미로웠습니다. 다만 시간이 조금 지난 지금 기준으로는 이 구조가 다른 MLLM 계열에서 얼마나 널리 흡수되었는지, 혹은 locality를 보존하는 대신 생기는 trade-off가 무엇인지까지 같이 봐야 실제 임팩트를 더 정확히 평가할 수 있을 것 같습니다.