TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models
- Authors: Tong Guan, Zijie Meng, Dianqi Li, Shiyu Wang, Chao-Han Huck Yang, Qingsong Wen, Zuozhu Liu, Sabato Marco Siniscalchi, Ming Jin, Shirui Pan
- Paper: https://arxiv.org/abs/2509.24803
- Code: https://github.com/AntonGuan/TimeOmni-1
- Affiliation: Griffith University, Zhejiang University, NVIDIA Research, Squirrel Ai Learning, University of Palermo, NTNU
- Conference: ICLR 2026
TL; DR
시계열 추론을 위한 포괄적 benchmark TSR-Suite와 SFT+RL 2단계 학습 기반의 통합 추론 모델 TimeOmni-1을 제안. GPT-4.1 대비 causal discovery 정확도 +40.6% 달성
Background
- 시계열 데이터는 에너지, 금융 등 실세계 전반에 걸쳐 사용되지만, LLM은 pretraining 과정에서 temporal prior를 거의 습득하지 못함
- 기존 접근의 발전 방향:
- TSFM (Moirai, Time-MoE, Chronos 등): 대규모 pretraining 기반 forecasting foundation model. textual event 처리 불가, multi-task 불가
- TSLM (ChatTS, Time-MQA 등): LLM을 시계열 QA에 적응시키지만, 패턴 매칭 수준으로 진정한 reasoning 없음
- 최근 DeepSeek-R1 패러다임을 차용한 TSRM (Time-R1 등)이 등장했지만, 여전히 single-task 실험에 국한
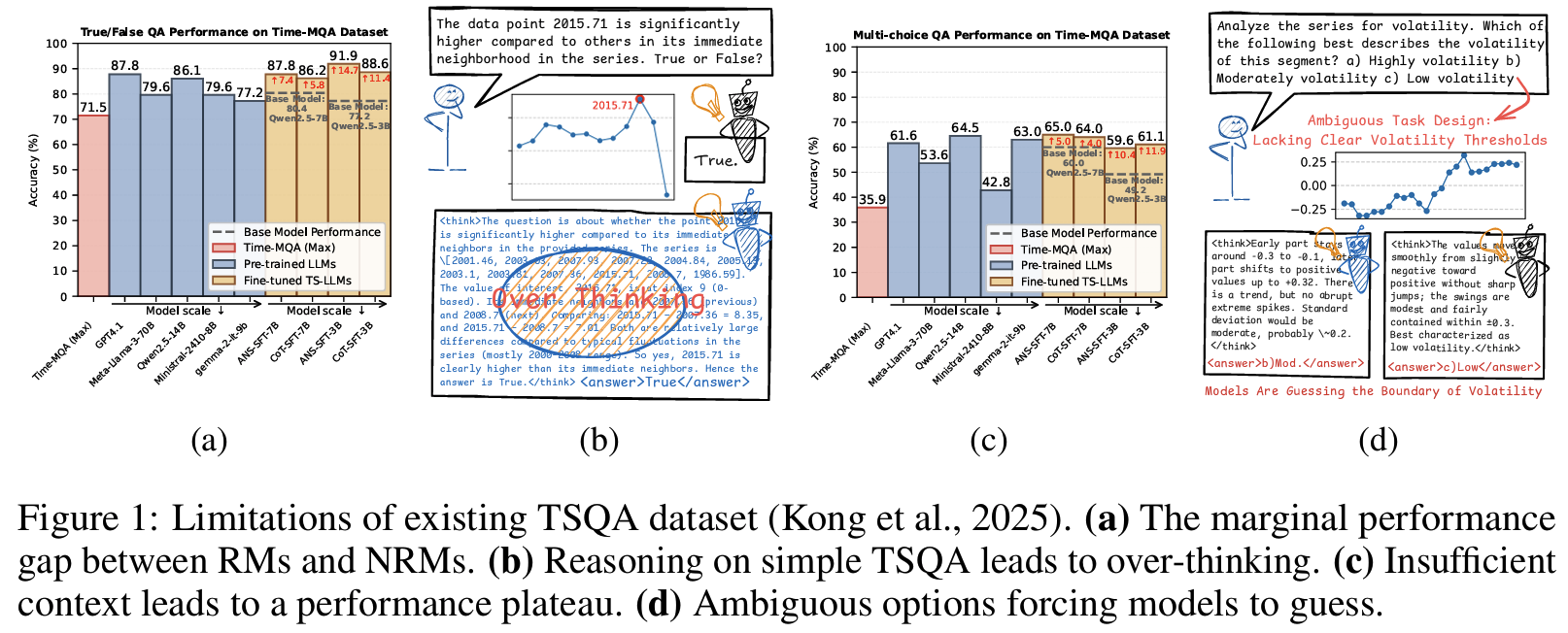
- 기존 TSQA 데이터셋(Time-MQA)의 구조적 한계 (Fig 1):
- 추론 필요성 없음: reasoning model이 non-reasoning model 대비 이득 없고, 모든 모델이 75% 이상 달성 → 너무 쉬운 task (Fig 1 (a), (b))
- 맥락 불충분: “high vs. low volatility” 경계 없는 모호한 선택지 → 추론이 아닌 추측을 강제; SFT 후에도 65% 이하에서 plateau (Fig 1 (c), (d))
Problem States
진정한 reasoning을 요구하는 task 설계를 위한 두 가지 원칙 제안:
- Principle 1 (추론 필요성): reasoning model(RM)이 non-reasoning model(NRM)을 유의미하게 앞서야 함
- Principle 2 (맥락 충분성): reasoning capacity가 무한해도 맥락이 부족하면 random guess 수준
두 원칙에서 도출되는 해결 과제:
- 두 원칙을 동시에 만족하는 reasoning-critical time series 데이터 부재
- 범용 TSRM 학습을 위한 검증된 훈련 경로 부재 (기존 접근은 task/dataset마다 개별 모델)
Suggestions
Problem Formulation
Time series reasoning을 다음과 같이 정의: 중간 rationale R을 생성한 후 최종 답변 y를 출력하는 과정
\[(R, y) \sim p_\theta(R, y \mid X, C) = p_\theta(R \mid X, C) \cdot p_\theta(y \mid R, X, C)\]- RM:
<think>…</think><answer>…</answer>형식으로 출력 - NRM:
<answer>…</answer>만 출력
이 분리 덕분에 두 모델 간 성능 차이를 명확히 측정할 수 있고, Principle 1의 정량 검증이 가능해짐
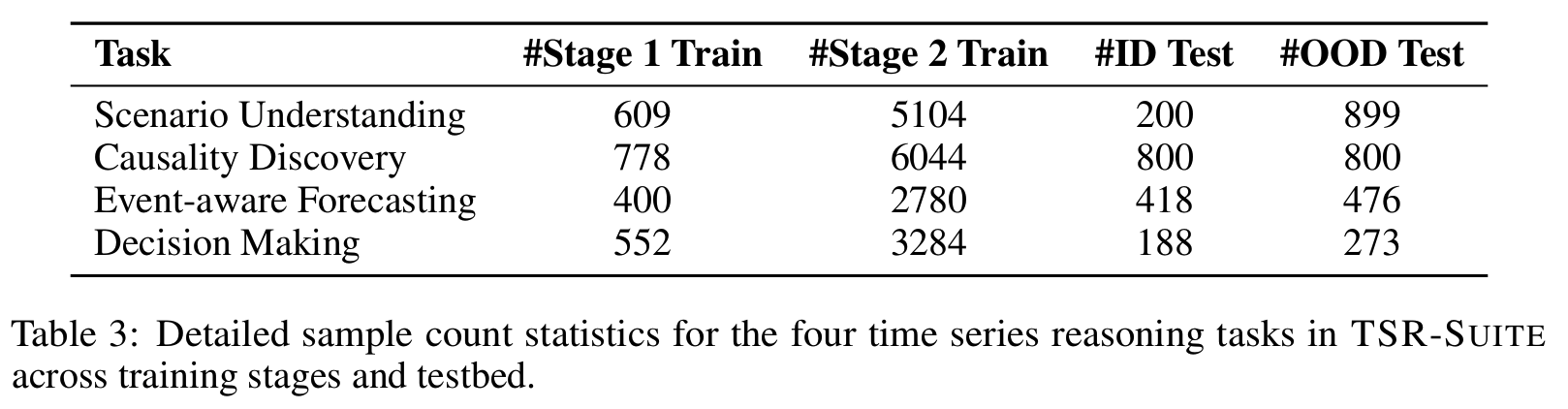
TSR-Suite: Time Series Reasoning Suite
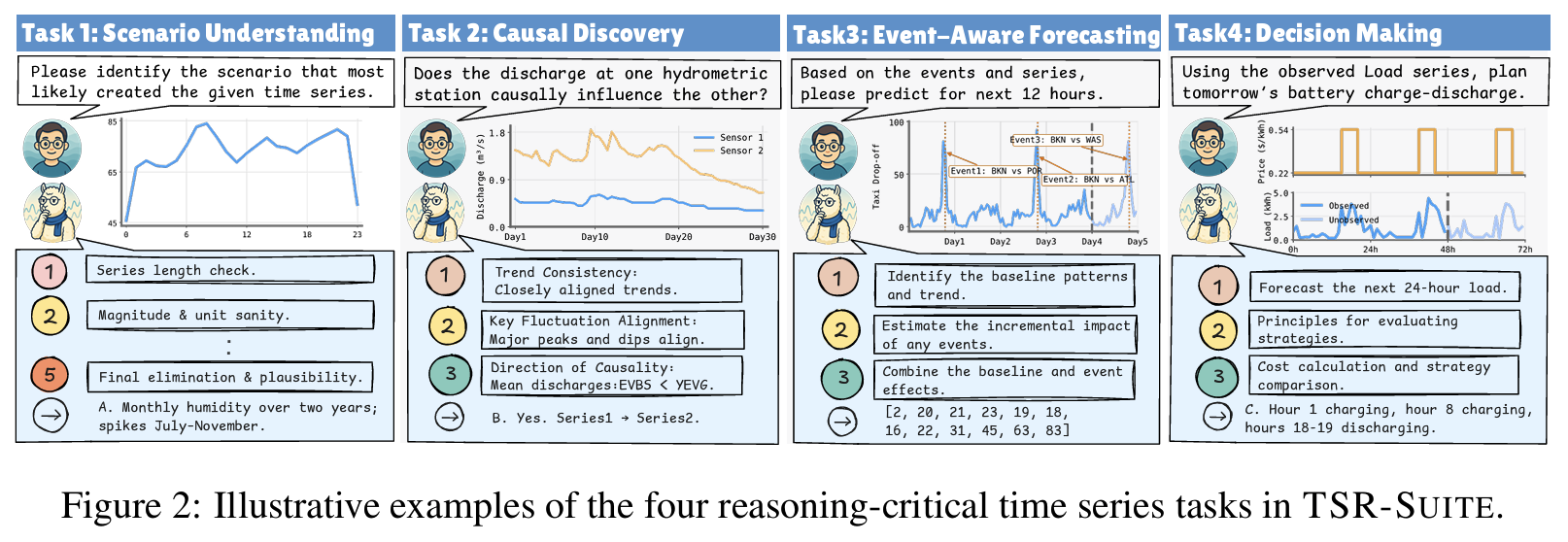
perception → extrapolation → decision-making 3단계 인지 능력을 커버하는 4개 task로 구성 (Fig 2):
- Task 1 [Scenario Understanding]: Perception 능력 / Multi-domain / Multi-choice
- Task 2 [Causality Discovery]: Perception 능력 / River discharge (CausalRivers) 도메인 / Multi-choice
- 추론 흐름: trend consistency → key fluctuation alignment → causal direction (“small rivers flow into big rivers” 도메인 규칙)
- Task 3 [Event-aware Forecasting]: Extrapolation 능력 / 인간 이동·전력 부하 도메인 / Sequence output
- Task 4 [Decision Making]: Decision-making 능력 / 건물 에너지 (CityLearn) 도메인 / Multi-choice
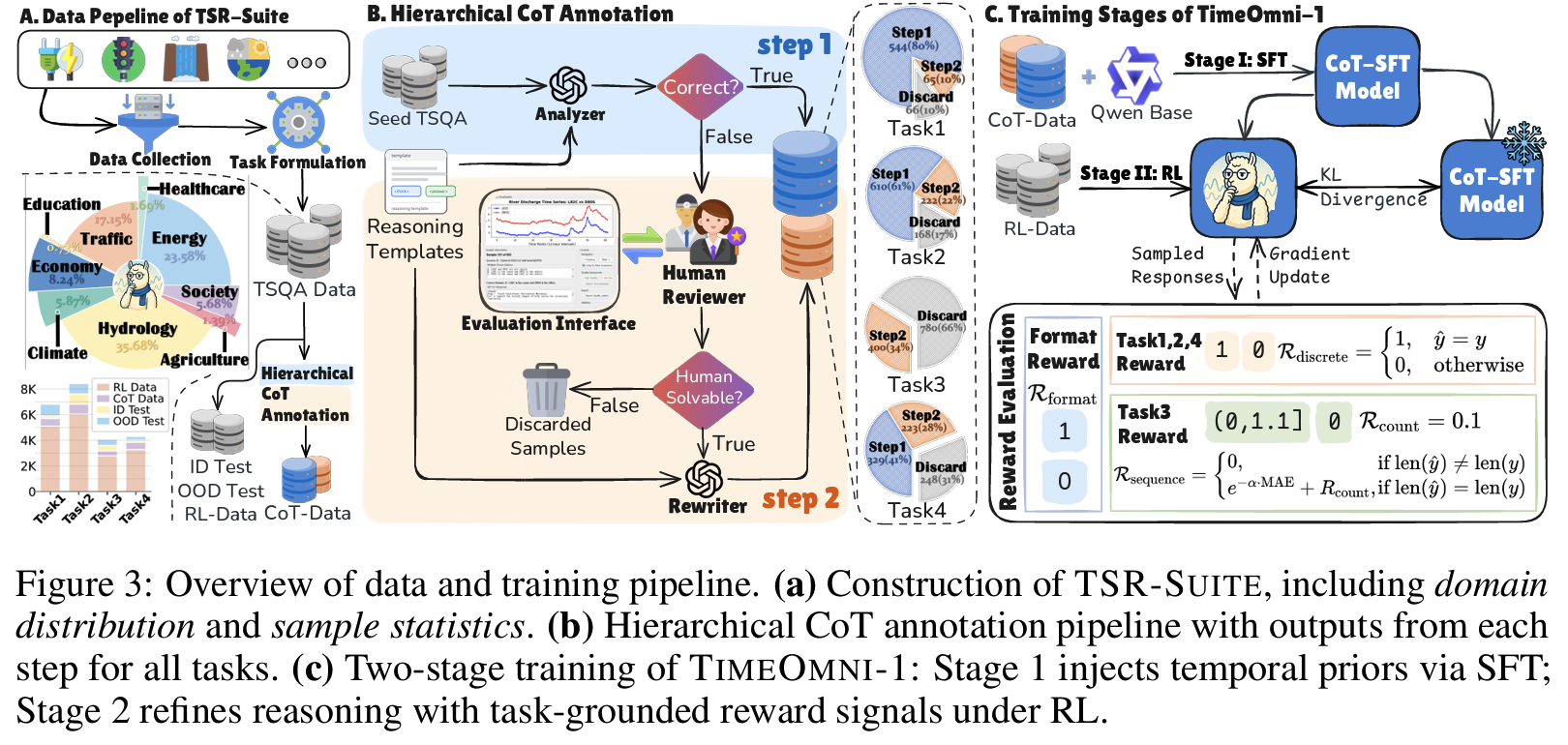
Hierarchical CoT Annotation 파이프라인 (Fig 3):
LLM Analyzer (구조화 템플릿 사용) → Human Reviewer (맥락 충분성 검토) → LLM Rewriter
- LLM과 인간 모두 실패한 샘플은 폐기
- Task 3 특이사항: ground-truth hint로 생성한 chain이 오히려 SFT 성능 하락
- Tab 6 기준 ID MAE 24.53 (hint 사용) vs. 15.10 (LLM 자체 생성)
- curriculum learning 원칙과 일치: 모델 현재 능력보다 약간 어려운 데이터가 최적
TimeOmni-1: 2단계 학습
Stage 1 — SFT로 temporal prior 주입
계층적 CoT 데이터로 4개 task에 대한 CoT-SFT 수행
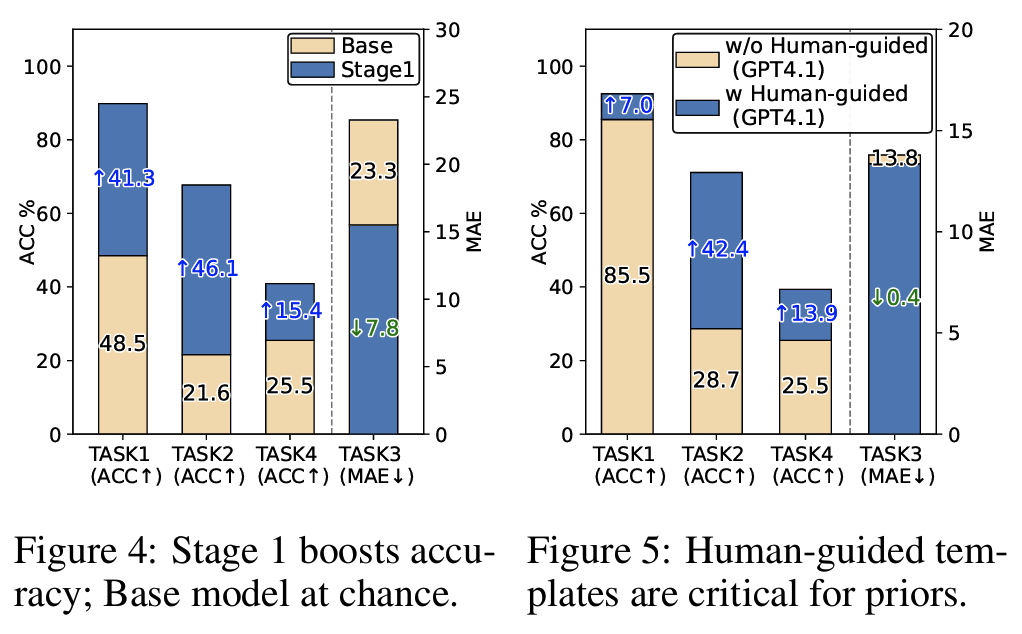
Finding #1: <1K seed 샘플만으로 Task 2 정확도 +46.1% (base 모델 21.6% = random guess 33.3% 미만으로 붕괴)Finding #2: 인간이 설계한 구조화 템플릿이 핵심 — GPT-4.1 zero-shot Task 2: 28.7% → 템플릿 적용 시 71.1% (Fig 5)
Stage 2 — RL (GRPO)로 추론 정제
Task 맞춤형 outcome-based reward 설계:
- $R_{\text{format}}$:
<think>…</think><answer>…</answer>형식 준수 - $R_{\text{discrete}} \in {0, 1}$: Task 1/2/4 exact match
- $R_{\text{count}} = 0.1$: Task 3 시퀀스 길이 일치 보너스 (Stage 1 체크포인트에서 길이 성공률이 55.7%에 불과했기 때문)
-
Task 3 MAE → exponential decay로 정규화된 보상 범위에 매핑
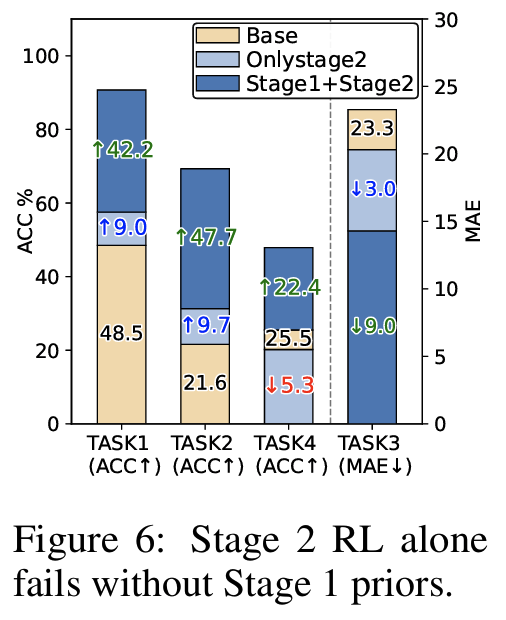
Finding #3: Stage 1 없이 RL만 적용 시 효과 미미하거나 오히려 하락 (Task 4: -5.3%) → Stage 1 prior가 전제조건 (Fig 6)
Joint Training
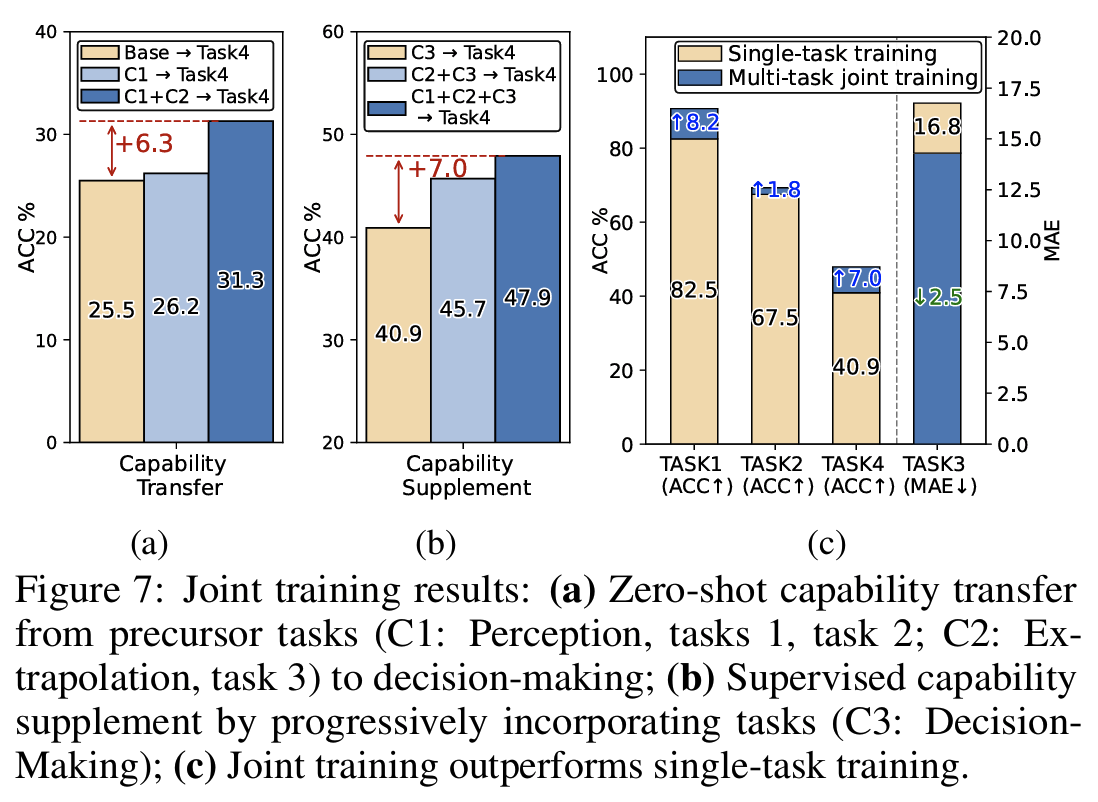
4개 task 통합 학습으로 “train-once, use-across-tasks” 패러다임 실증 (Fig 7):
- zero-shot capability transfer: decision-making ACC 25.5% → 26.2% → 31.3% (perception/extrapolation prior 순차 추가 시, Fig 7(a))
- supervised capability supplement: 40.9% → 45.7% → 47.9% (Fig 7(b))
- 기존 single-task 파이프라인(TimeMaster: 6개 데이터셋에 6개 모델 별도)과 대비
Finding #4실증 (Fig 7(c))
Effects
Experimental Setup
- Base Model: Qwen2.5-7B-Instruct
- Time-series input: 시계열 값을 텍스트로 직렬화 (serialization)
- ViT에 해당하는 범용 time series encoder가 아직 없기 때문; Time-R1, Time-MQA와 동일한 방식
- External Benchmarks:
- MTBench: 실제 주식·기상 시계열, 시간 범위별 QA
- TimeSeriesExam: 합성 시계열 5개 task (ground truth 명확성을 위해 합성 데이터 사용)
- CaTS-Bench: 시계열↔자연어 alignment 능력 측정, retrieval 류 task
- DROP / GPQA / ReClor: 수치 추론 / 대학원급 전문 지식 / 논리 추론 벤치마크
- Metrics: 모든 지표는 valid response에 대해서만 산정
- Success Rate (SR): 유효 응답 비율 — 특화 모델들의 잦은 포맷 실패 때문에 별도 보고 (ChatTS: Task 3에서 SR 0%)
- ACC (Task 1/2/4): exact match
- MAE (Task 3): 낮을수록 좋음
Results
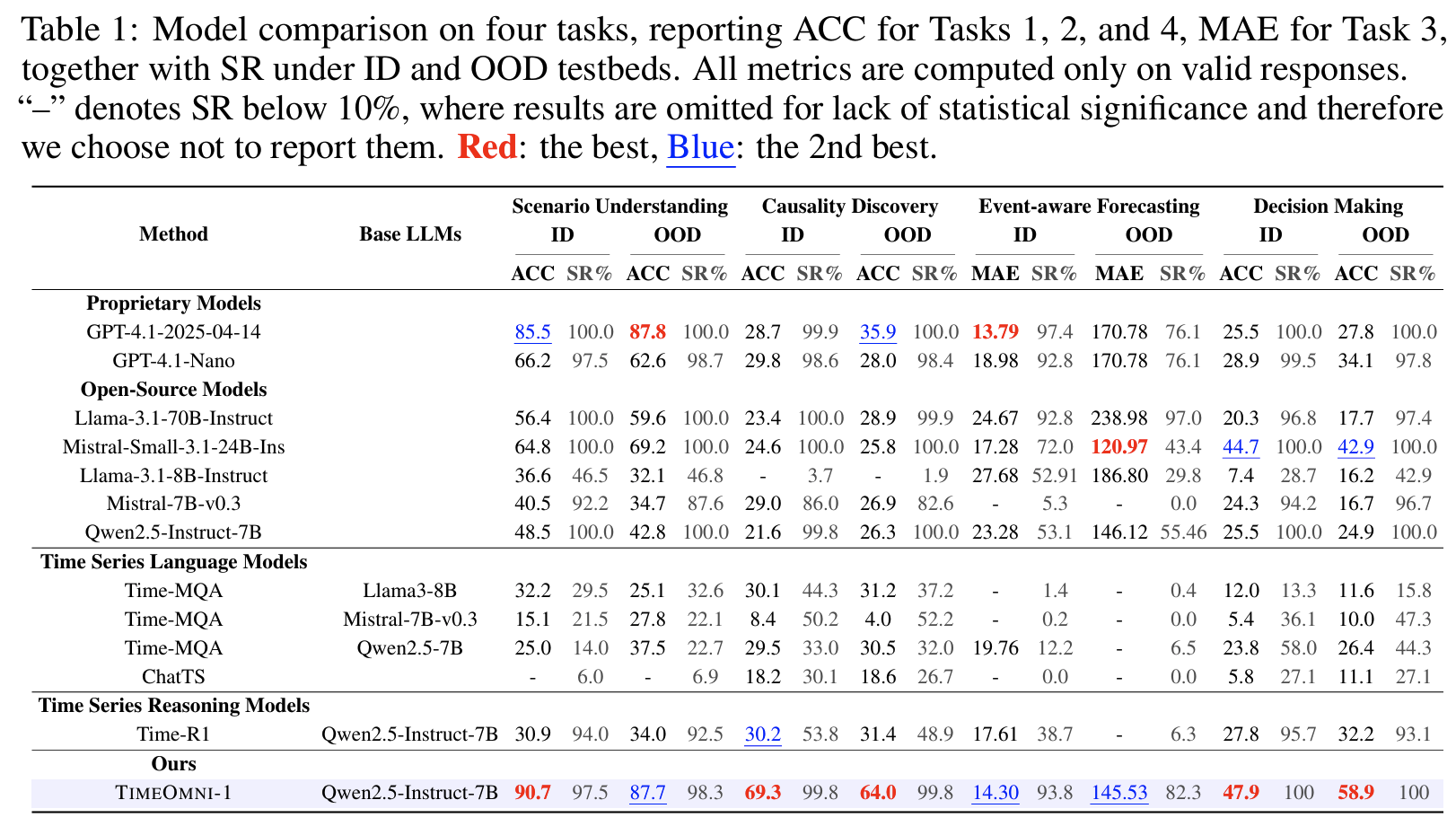
Main Table (Tab 1)
- GPT-4.1 대비 causal discovery 정확도: +40.6% (ID) / +28.1% (OOD)
- 기존 TS 특화 모델들의 낮은 SR이 두드러짐: ChatTS는 Task 3에서 SR 0% (숫자 시퀀스 대신 자유 형식 텍스트 생성)
- Task 3 OOD MAE(145.53) vs. ID MAE(14.30): NYC 택시 → 전력 부하 도메인 시프트에서 여전히 차이가 큰 것 확인
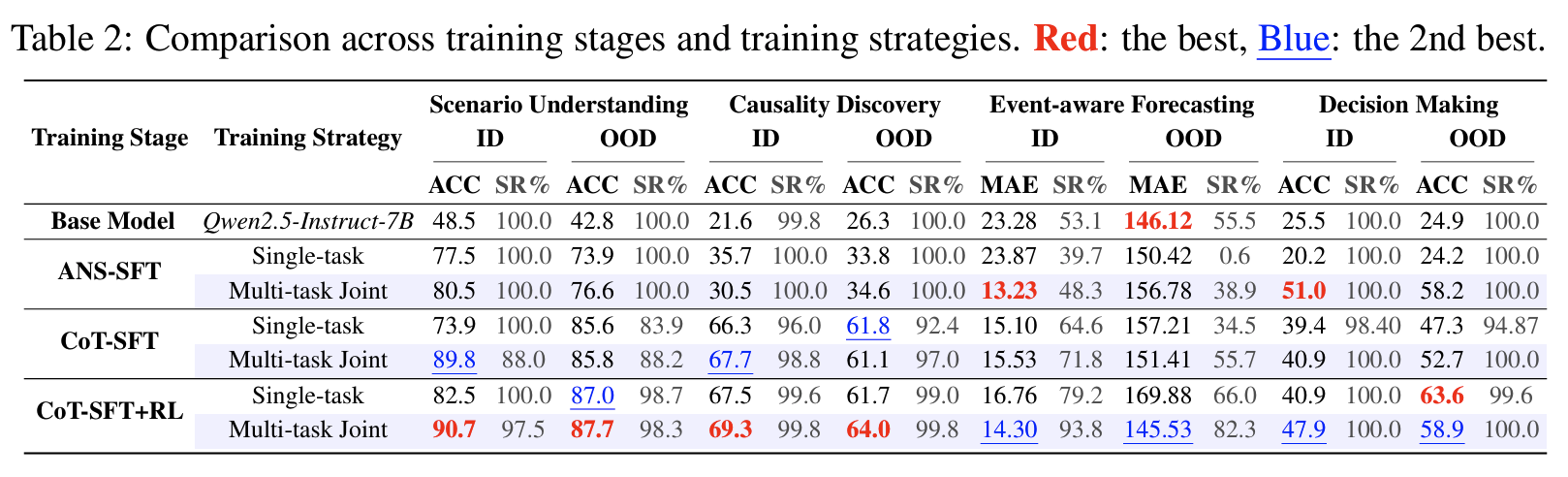
학습 단계별 ablation (Tab 2)
- Task 2 ANS-SFT vs. CoT-SFT: 30.5% vs. 67.7%
- answer-only supervision은 분포만 맞추고 추론 능력을 기르지 못함
- CoT-SFT + RL: 전 task에서 가장 균형 잡힌 성능
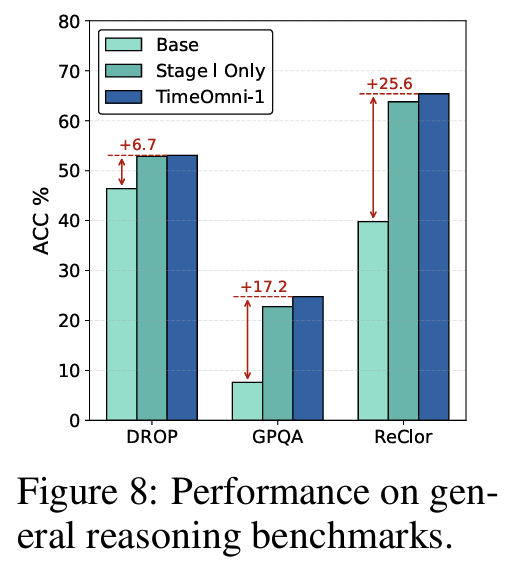
일반 추론 능력 보존 (Fig 8)
- DROP(수치 추론), GPQA(대학원 수준), ReClor(논리 추론)에서 base 대비 평균 +16.5%
- 시계열 특화 학습이 일반 추론 능력을 해치지 않음을 확인
Personal note. 이 논문의 의의는 진짜 추론을 요구하는 task가 무엇인지를 엄밀하게 정의하려 한 시도가 아닌가 싶습니다. 별건일 수도 있긴 한데, 시계열 추론과 personalized tool-calling은 표면적으로 매우 다른 문제지만, 핵심 구조가 동일하다고도 생각했습니다. 관측 히스토리에서 잠재 패턴을 추론하고 그 패턴을 미래 행동에 반영하는 거라고 볼 수도 있으므로…? 제안된 TSR-Suite의 Task 4(Decision Making)이 결국 과거 시계열 패턴을 추론해 최적 전략을 선택하는 구조는, Preference Inference/Transfer가 과거 세션 히스토리에서 잠재 선호도를 추론해 API 인자를 결정하는 구조와 동형이지 않을까 싶기도 합니다.