H2HMem: A Multimodal Memory Benchmark for Agents in Human-Human Interactions
Meta info.
- Authors: Shiping Zhu, Yibo Yang, Zhengyang Wang, Tiancheng Shen, Dandan Guo, Ming-Hsuan Yang
- Affiliation: Jilin University, Shanghai Jiao Tong University, University of California at Merced
- Paper: https://arxiv.org/abs/2606.09461
- Published: June 9, 2026 (arXiv preprint)







TL; DR
agent가 participant가 아닌 observer로서 human-human 대화를 관찰+기억하는 상황을 평가하는 multimodal, multi-session, multi-party 메모리 벤치마크 H2HMem 제안
Review Video
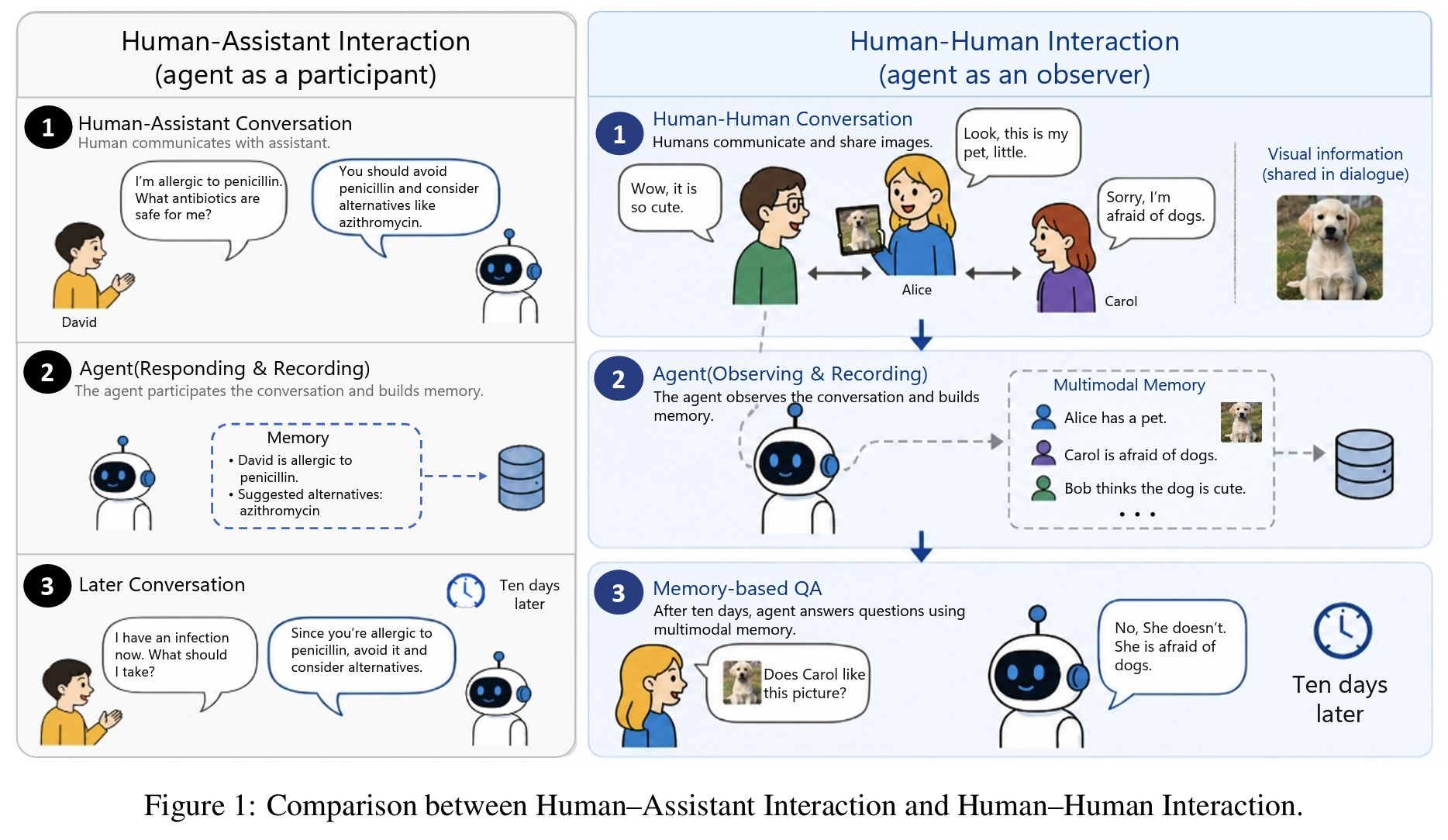
Background
- LLM agent의 새로운 배치 환경: human-assistant 대화의 participant가 아니라 human-human 대화의 observer
- meeting assistant, clinical documentation (ambient AI scribe), Zoom AI Companion 등 실응용에서 agent는 제3자로 대화를 듣고 이후 질의에 답함 (Asthana et al., 2025; Razaghi et al., 2026)
- 사람들 간 정보 분산을 추적하고, 긴 시간 범위에서 맥락을 유지하고, modality 간 신호를 통합해야 함
- observer setting 고유의 세 가지 난점
Fig 1- multimodal: 사람들끼리 사진, 스크린샷을 자연스럽게 공유 (Lee et al., 2024)
- discourse 현상: anaphora, deixis 해소를 위해 isolated fact retrieval이 아닌 evolving memory에 대한 reference resolution 필요
- multi-participant: 여러 화자가 비동기적으로, 때로는 상충하는 정보를 기여 (Abbo et al., 2025)
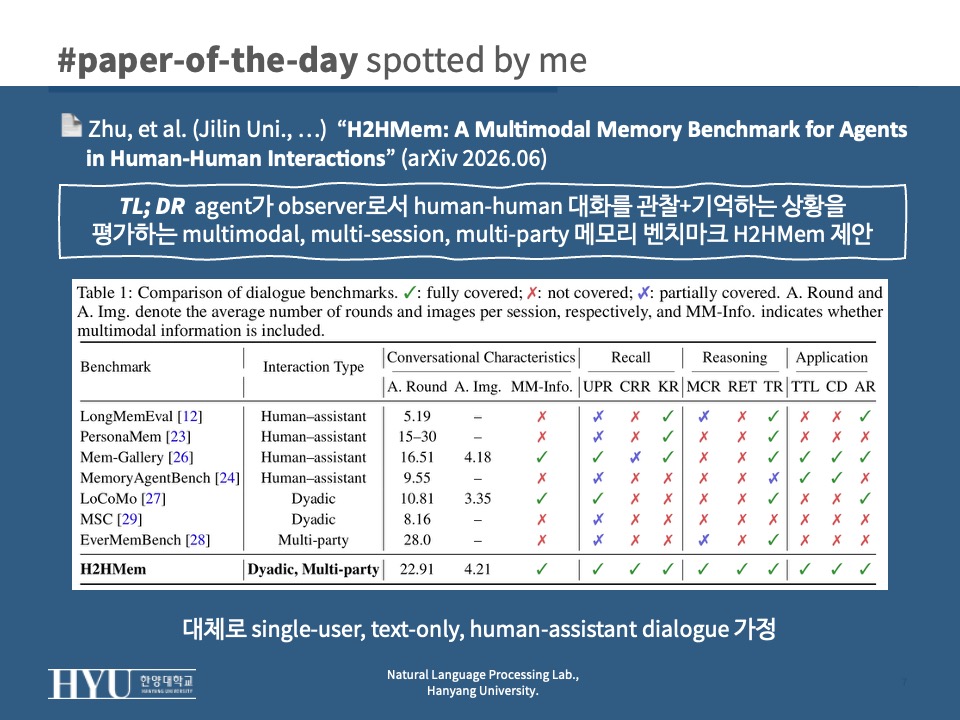
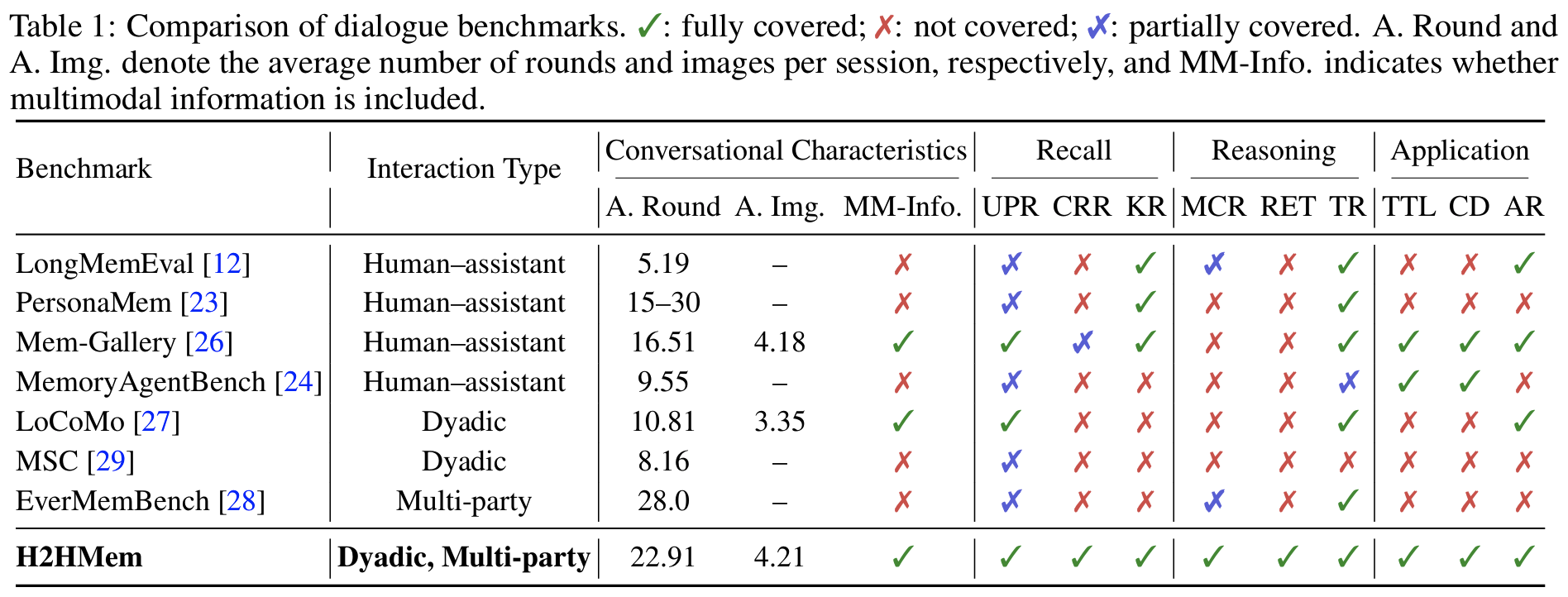
- 기존 메모리 벤치마크의 공백
Tab 1- 대부분 single-user, text-only, human-assistant: LongMemEval, PersonaMem, MemoryAgentBench (Wu et al., 2025; Jiang et al., 2025; Hu et al., 2026)
- LoCoMo는 vision을 포함하지만 dyadic 한정 (Maharana et al., 2024); EverMemBench는 multi-party지만 text-only (Hu et al., 2026)
- multimodality, dyadic & multi-party, long-horizon을 통합 프레임에서 동시에 다루는 벤치마크 부재
- 메모리 메커니즘 각각의 한계: 아래 세가지 갈래 모두 human-assistant setting에서 개발/평가 → multimodal human-human 환경에서의 유효성 미검증
- context window 확장: 단순하지만 비용 크고 long-context degradation 발생, cross-session persistence 없음
- retrieval-augmented memory: 확장성 있으나 factual recall 위주, episodic dependency와 causal structure에 취약 (Lewis et al., 2020)
- 명시적 memory module (write/index/summarize/forget): A-Mem, MemoryOS (Xu et al., 2026; Kang et al., 2025)
Problem States
multimodal human-human 대화를 관찰하는 agent의 메모리를 체계적으로 평가할 수 있는가
- 실제 human-human 대화 수집은 privacy 위험이 커서 de-identification으로도 완전 해소가 어려움 → privacy-preserving 생성 파이프라인 필요
- 단순 recall 측정만으로는 부족 → discourse 해소, 인과 추론, conflict 처리까지 포괄하는 평가 taxonomy 필요
- dyadic과 multi-party는 정보 분산 구조가 다름 → 두 interaction type을 같은 프레임에서 비교 가능해야 함
Suggestions
수식 정의
- dialogue: $S = (s_1, \dots, s_T)$, 각 session $s_t$는 timestamp $\tau_t$가 붙은 하루치 대화 (하나의 토픽 중심)
- utterance: multimodal tuple $u_{t,i} = (p_{t,i}, x_{t,i}, v_{t,i})$
- $p_{t,i} \in \mathcal{P}$: 화자, $x_{t,i}$: 텍스트, $v_{t,i}$: optional 이미지
- $\lvert \mathcal{P} \rvert = 2$면 dyadic, $\lvert \mathcal{P} \rvert \geq 3$이면 multi-party
- memory와 질의 응답: $\mathcal{M}_T = {m_1, \dots, m_N}$, $\mathcal{R} = \mathrm{retrieve}(q, \mathcal{M}_T)$, $a = \mathrm{LLM}(\mathcal{R}, q)$
- storage-retrieve-answer의 표준 외부 메모리 추상화; 벤치마크는 이 추상화를 따르는 어떤 메모리 시스템이든 plug-in 평가 가능
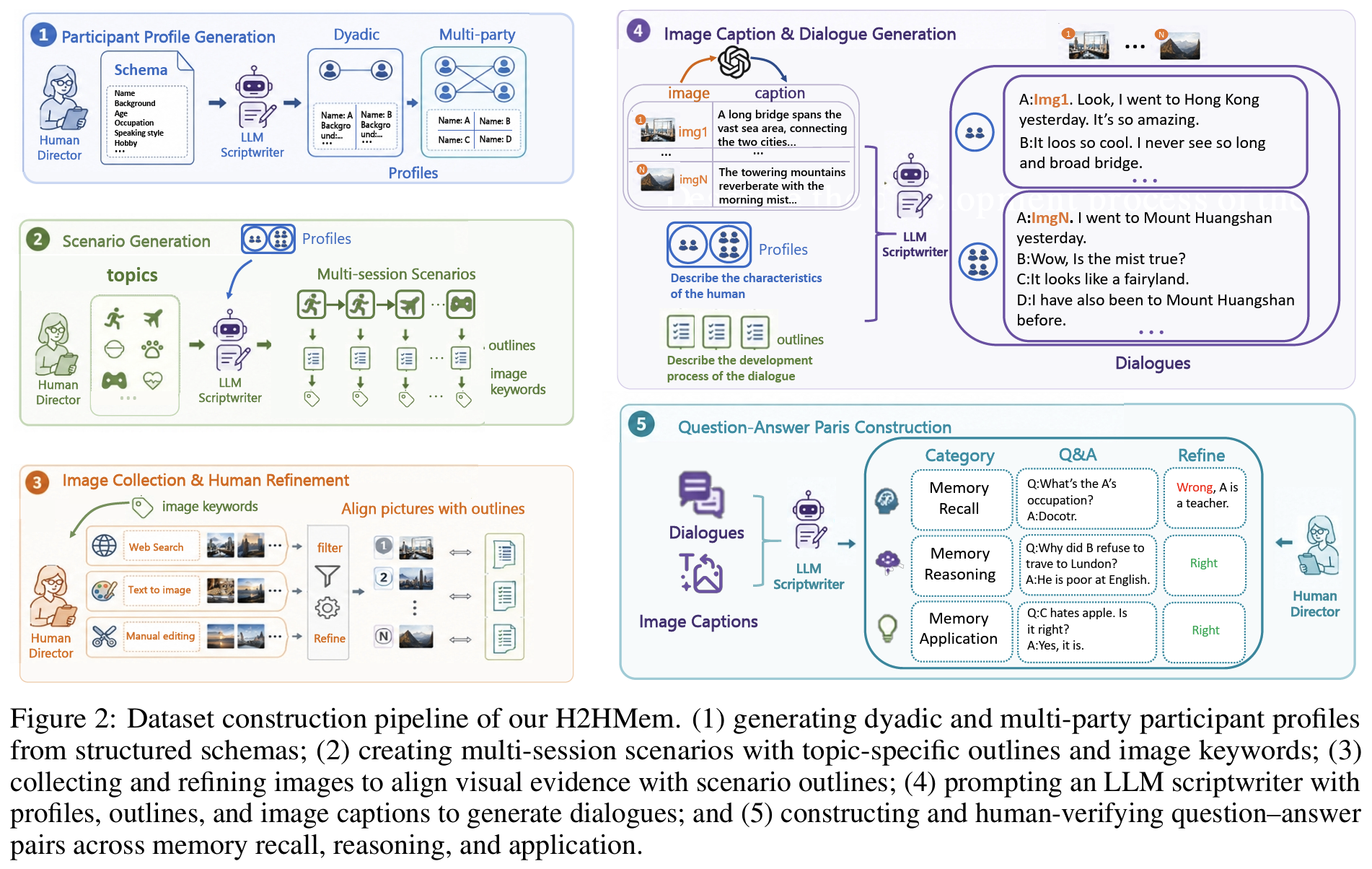
데이터 구축: human-in-the-loop 5-stage (Fig 2)
- 역할 분리:
- 인간: director (시나리오 일관성, visual grounding, 품질 관리)
- LLM: scriptwriter (대화, 시나리오, QA 생성)
- online conversational setting 채택: 메시징 플랫폼식 비동기 메시지 교환 환경
- ecological validity, 구조화된 정보 흐름, 다양한 토픽과 다양한 참여자 수용의 절충점
- [Stage 1] participant profile 생성: 구조화된 schema (성격, 배경, 말투 등) 기반
- DeepSeek-V3가 profile 생성
- dyadic은 2인, multi-party는 4~6인 profile
- [Stage 2] scenario 구성: 11개 공통 토픽에서 sampling
- 토픽별 session-level outline과 image keyword 생성
- outline이 temporally ordered되어 multi-session scenario $S$를 형성
- [Stage 3] 이미지 수집과 human refinement: 웹 검색 + text-to-image 생성 + 수작업 편집
- annotator가 utterance-이미지 정합, 해상도, 토픽 적합성 기준으로 filter/refine (80 person-hours)
- [Stage 4] captioning과 대화 생성
- GPT-4o가 caption 생성, DeepSeek-V3가 profile + outline + caption 조건부로 대화 생성
- DeepSeek-V3는 이미지를 직접 처리하지 못하므로 caption이 매개
- [Stage 5] QA 구성과 검증
- DeepSeek-V3가 9개 task type별 QA 생성
- human annotator가 유일성/명확성/난이도 검증 (40 person-hours)
- inter-annotator agreement: 이미지 refinement Fleiss $\kappa = 0.83$, QA 검증 $\kappa = 0.79$
- 최종 규모
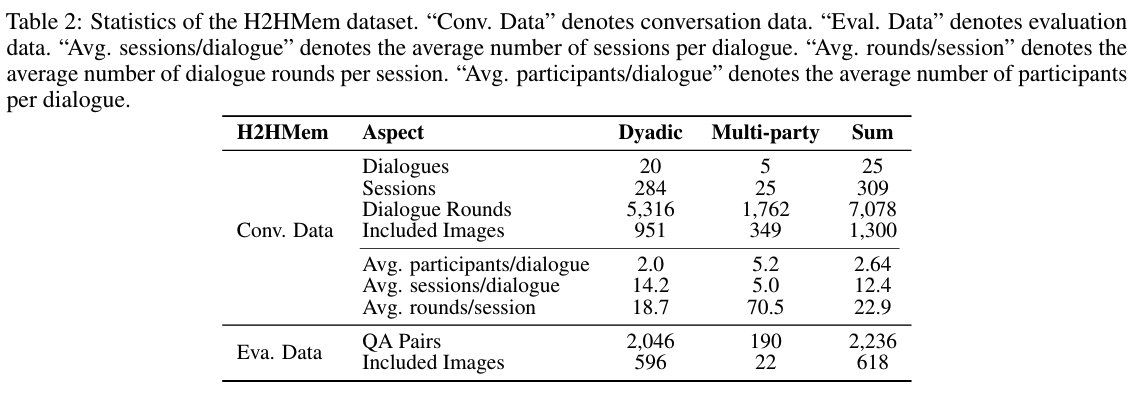
Tab 2- 25 dialogues (dyadic 20 / multi-party 5), 309 sessions, 7,078 rounds, 1,300 images, 2,236 QA pairs
- dyadic: 평균 14.2 sessions, session당 18.7 rounds로 긴 horizon, 낮은 밀도
- multi-party: 평균 5.0 sessions, session당 70.5 rounds로 짧은 horizon, 높은 밀도
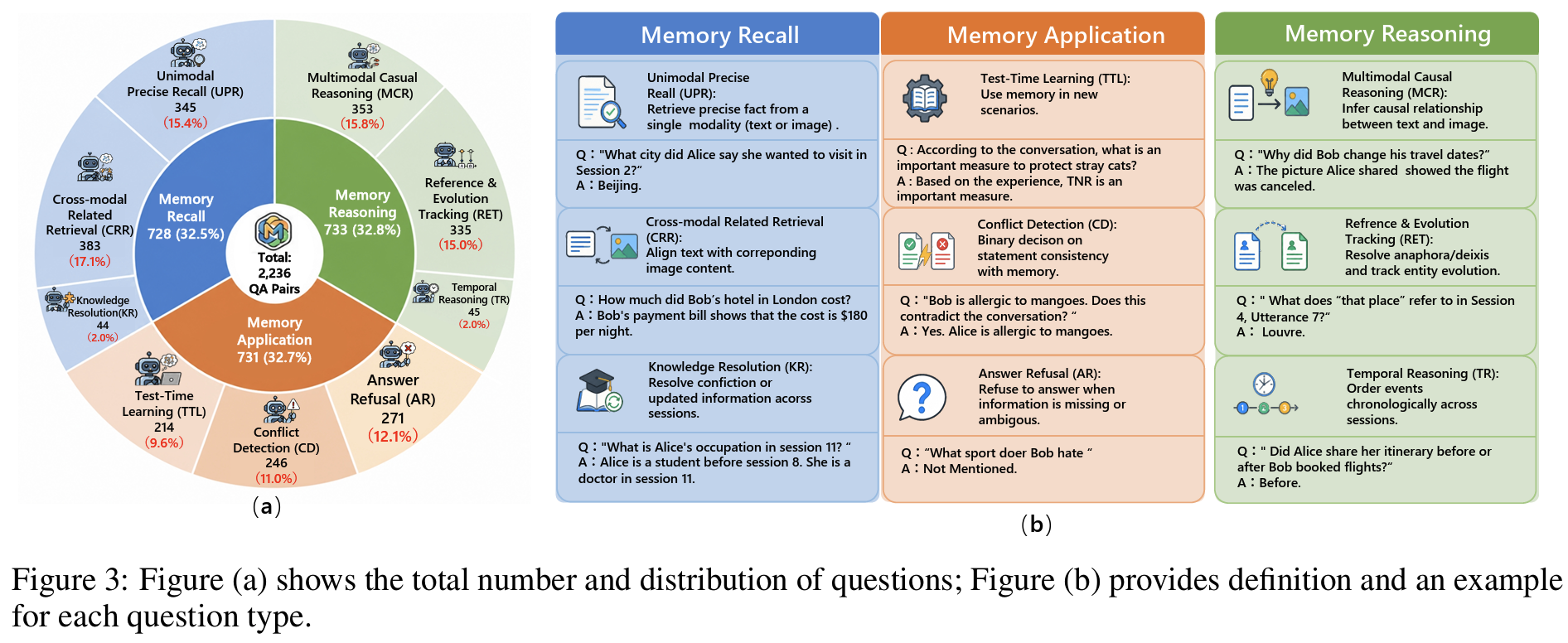
Task taxonomy: 3개 범주 9개 task (Fig 3)
- Memory Recall: 명시적으로 제시된 multimodal 정보의 retrieval 평가
- Unimodal Precise Recall (UPR): 단일 modality에서 정확한 사실 회수
- Cross-modal Related Retrieval (CRR): text와 image 간 정렬된 내용의 cross-modal 검색
- Knowledge Resolution (KR): session 간 갱신된 지식에서 현재 시점의 올바른 값 해소
- Memory Reasoning: 시간과 참여자를 가로지르는 상위 추론 평가
- Multimodal Causal Reasoning (MCR): text와 image 사이의 인과 관계 추론
- Reference & Evolution Tracking (RET): anaphora/deixis 해소와 entity 변화 추적
- Temporal Reasoning (TR): timestamp와 발화 위치 기반 사건 순서 추론
- Memory Application: 동적 상황에서의 메모리 활용 평가
- Test-Time Learning (TTL): 메모리를 새 시나리오에 적용
- Conflict Detection (CD): 새 진술이 메모리와 모순되는지 binary 판단
- Answer Refusal (AR): 메모리에 없거나 추론 불가한 질문에 답변 거부
- QA 분포: 세 범주가 각 32~33%로 균등하나, KR (44개, 2.0%)과 TR (45개, 2.0%)은 표본이 작음
Effects
- Experimental setup
- 메모리 방법 6종을 두 계열로 비교
- text-based: Full Memory (Text), NaiveRAG, A-Mem
- 이미지는 GPT-4o caption (256 token 제한)으로 변환해 저장
- multimodal: Full Memory (MM), MuRAG, NGM
- raw image를 224×224로 저장 및 검색
- text-based: Full Memory (Text), NaiveRAG, A-Mem
- backbone MLLM 3종: Qwen2.5-VL-3B/7B-Instruct, GPT-4.1-Nano (temperature 0.1)
- retriever: text용 all-MiniLM-L6-v2, multimodal용 GME-Qwen2-VL-7B-Instruct, 기본 top-K=5
- 평가: GPT-4o-mini LLM-as-Judge (0/0.25/0.5/0.75/1 rubric, 200-sample human agreement Cohen’s $\kappa = 0.84$) + lexical metric (Precision/Recall/F1/BLEU-1)
- 메모리 방법 6종을 두 계열로 비교
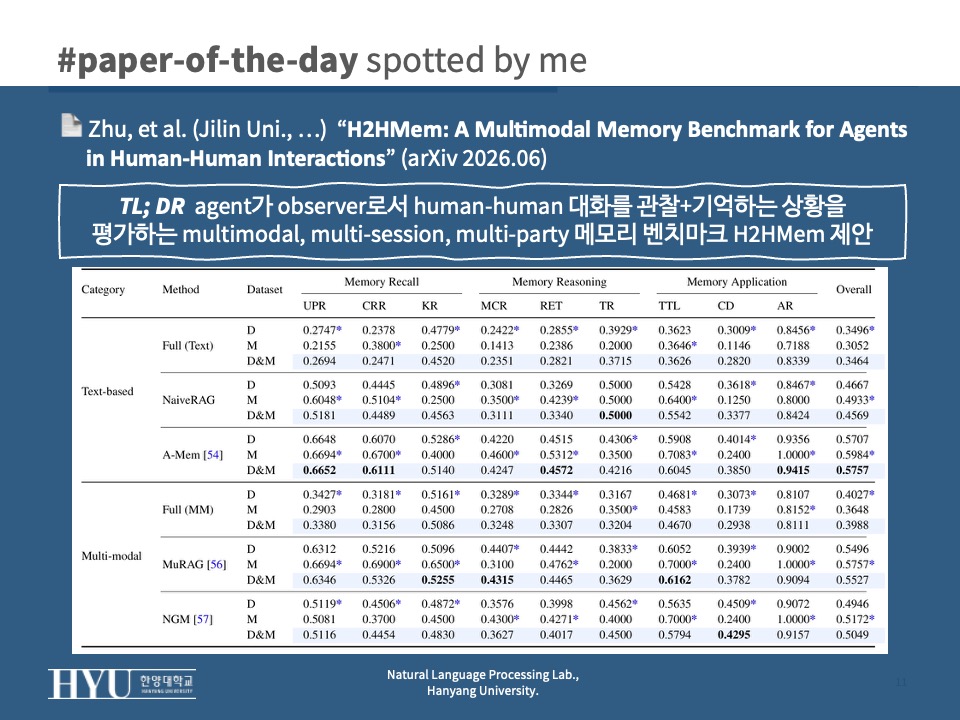
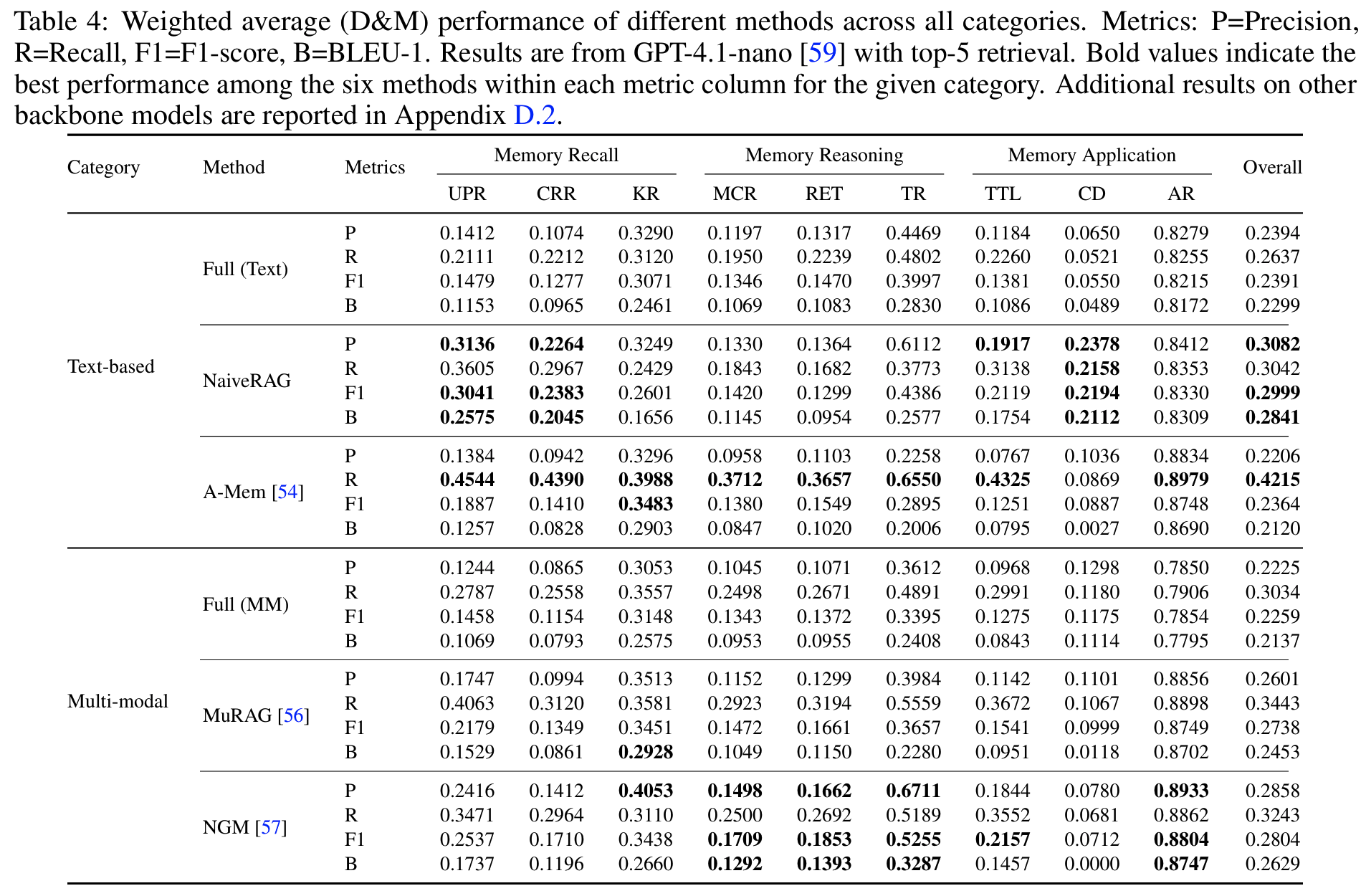
- Results
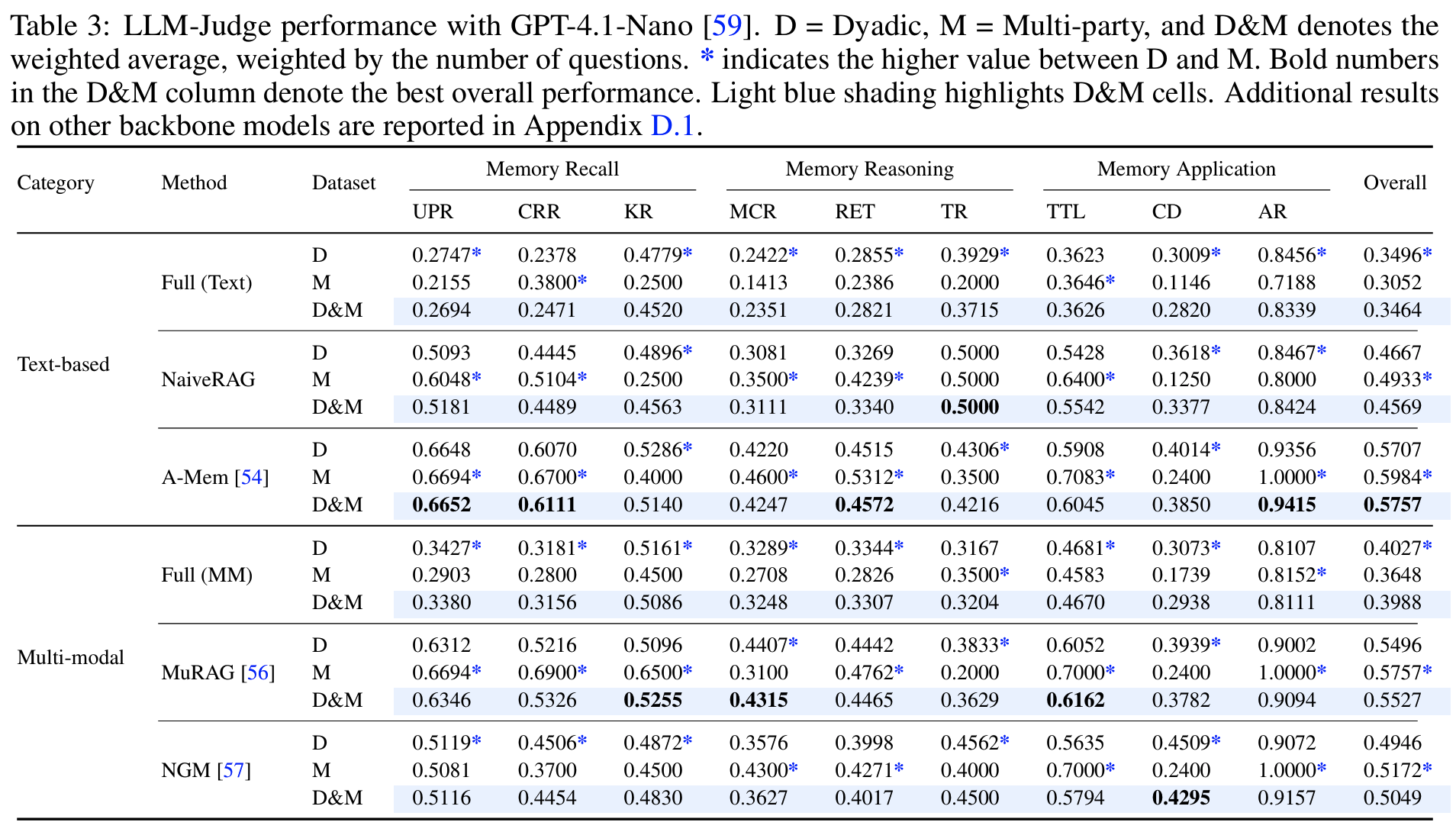
- 전반적으로 낮은 성능: 최고가 A-Mem의 weighted average 0.5757 (
Tab 3); backbone을 바꿔도 0.6을 넘는 방법 없음 Tab 3,4- cross-modal alignment: UPR 대비 CRR이 일관되게 낮음
- MuRAG 기준 0.6346 → 0.5326, lexical recall도 0.4063 → 0.3120
- distractor filtering 약함: recall은 높으나 precision이 낮음
- A-Mem recall 0.4215 vs precision 0.2206: 관련 history는 찾지만 multi-participant noise를 거르지 못함
- reasoning task 최저점: MCR, RET가 모든 방법에서 가장 낮고, BLEU-1 near-zero
- 분산된 증거를 잇는 정확한 factual phrasing을 재현하지 못하며, 인간의 implicit reference 관행에 취약
- conflict 처리 붕괴: CD가 lexical 기준 near-zero (A-Mem CD recall 0.0869)
- cross-modal alignment: UPR 대비 CRR이 일관되게 낮음
- interaction 구조 효과: dyadic vs multi-party가 task별로 역전 (
Tab 3)- 일관성 지향 task (KR, CD)는 다중 화자의 상충 신호로 multi-party에서 급락
- NaiveRAG KR 0.4896 (dyadic) → 0.2500 (multi-party)
- 집중된 맥락이 유리한 task (CRR, TTL)는 multi-party에서 비슷하거나 더 높음
Tab 10, 113B → 7B scaling으로도 이 gap이 해소되지 않음- CRR, MCR, CD의 개선폭 최소
- 일관성 지향 task (KR, CD)는 다중 화자의 상충 신호로 multi-party에서 급락
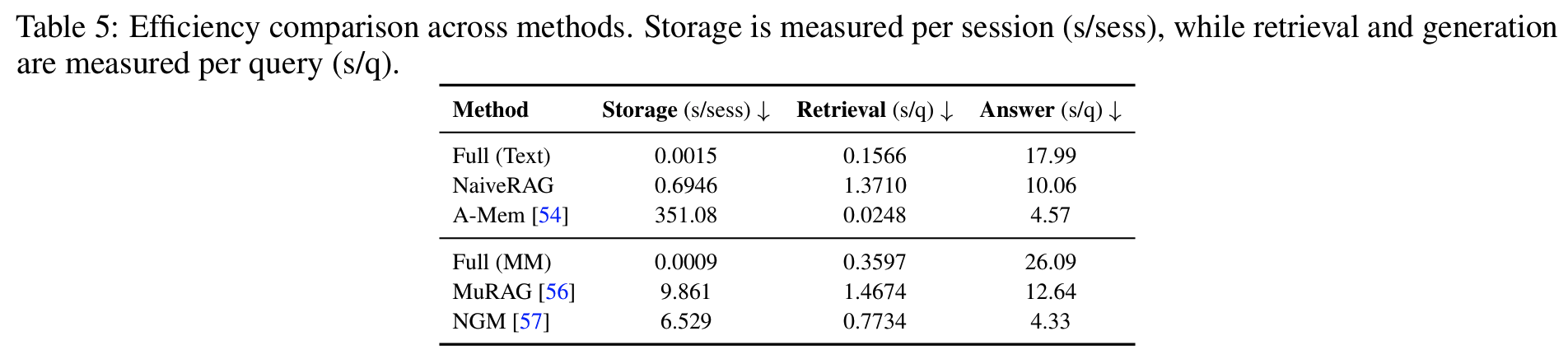
Tab 5효율 trade-off: storage와 inference latency의 명확한 교환 관계- full memory 계열: 저장 비용 최소이나 latency 큼 (Full Text 17.99 s/q, Full MM 26.09 s/q)
- A-Mem: latency 4.57 s/q로 빠르지만 메모리 구축에 351.08 s/session
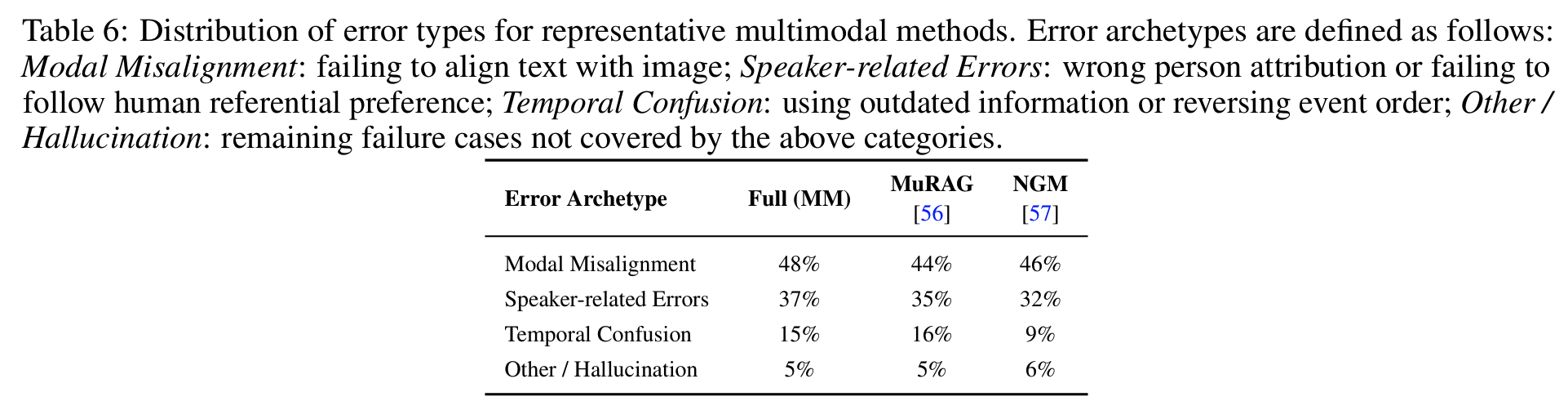
Tab 6error 분석: 실패 100건 수동 분류 결과 두 archetype에 집중- modal misalignment 44~46%: 텍스트를 visual evidence에 grounding하지 못함
- speaker-related error 32~35%: 화자 오귀속, 인간 referential 관행 추적 실패
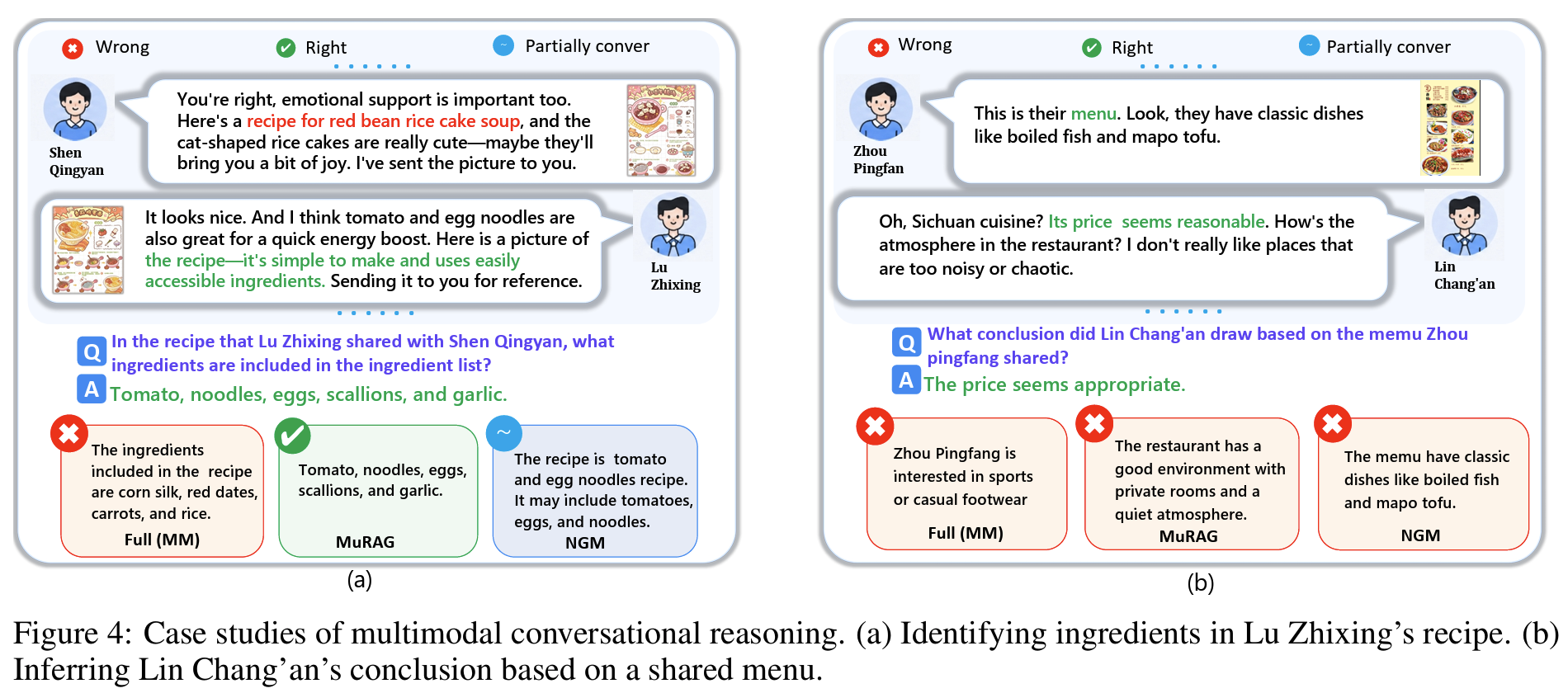
Fig 4case study: recipe 이미지의 재료 식별에서 이미지 무시(NGM)와 화자 오귀속(Full MM), 메뉴 기반 결론 추론에서 결론의 화자 오귀속(NGM)이 그대로 재현
- retriever top-K 분석 (
Tab 14): K 증가가 비단조적 효과- A-Mem, NGM은 K=15에서 정점 후 하락; MuRAG는 K=10 정점 → recall 향상과 noise 누적의 trade-off <!–
- 전반적으로 낮은 성능: 최고가 A-Mem의 weighted average 0.5757 (
- Limitations
- 대화와 QA가 모두 LLM-generated (DeepSeek-V3): 합성 분포가 실제 human-human 대화의 discourse 특성을 얼마나 보존하는지 미검증
- 생성과 평가의 순환: 대화 생성, caption, QA 생성, judge가 전부 LLM이고 human 검증은 사후 filter 수준
- multi-party 표본 빈약: 5 dialogues, 190 QA로 multi-party 결과의 분산이 큼 (AR 1.0000 같은 포화 수치)
- task 불균형: 핵심 주장에 쓰이는 KR, TR이 각 2% 수준
- CD를 lexical metric으로 측정하는 것은 binary task와 metric의 mismatch
- text-based 방법에 GPT-4o caption을 제공하는 설계는 caption의 정보 우위와 raw image 처리 난이도를 분리하지 못함
- 영어 single-language, 최대 1년 time span으로 제한 –>
Personal note. 전에 교수님께 언급만 드렸던,, 대화 밖에 존재하는 agent를 observer로 하여 이 observer의 관점에서 memory에 대해 논의하고 있습니다. 벤치마크 논문으로서 multimodal 과 multi-party matrix 는 깔끔히 채웠고, task 난이도가 interaction 구조에 따라 역전됨을 보인 게 좋아보입니다. 주요 실패중에 speaker를 잘 못맞춘다는 건 되게 고전 task 같긴 한데 여전한 문제라고는 하는게 클래식은 영원한가 싶고요.