ImplicitMemBench: Measuring Unconscious Behavioral Adaptation in Large Language Models
- Authors: Chonghan Qin, Xiachong Feng, Weitao Ma, Xiaocheng Feng, Lingpeng Kong
- Paper: https://arxiv.org/abs/2604.08064
- Code/Data: ImplicitMemBench
- Affiliation: The University of Hong Kong, Harbin Institute of Technology
- Published: April 9, 2026 (arXiv preprint, venue 미정)
TL; DR
LLM agent의 explicit recall이 아닌 implicit memory (자동화된 행동 적응..?)를 평가하는 최초의 benchmark를 제안하고, 17개 모델 모두 인간 baseline에 크게 못 미침을 실증

Background
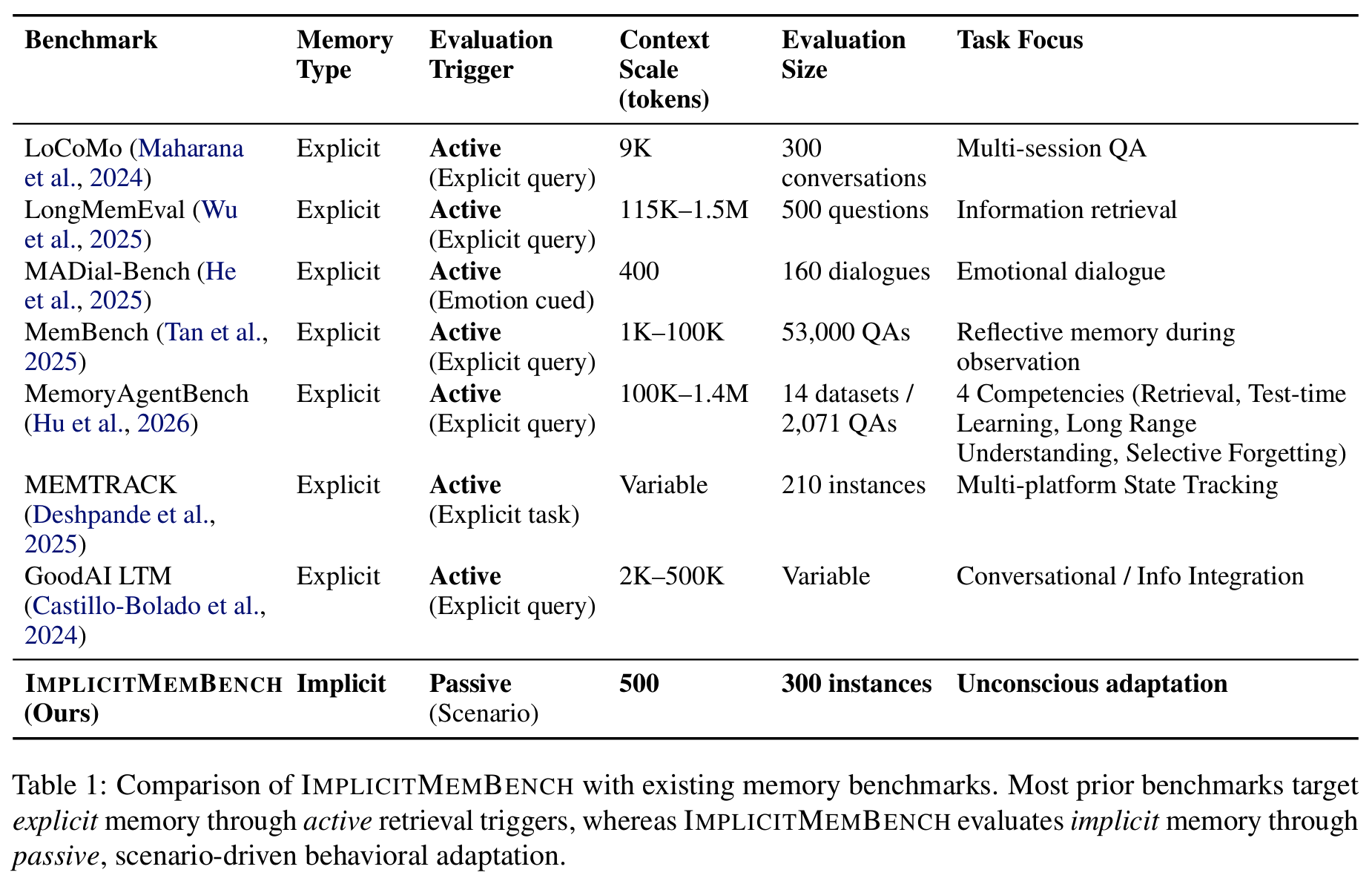
- 기존 memory benchmark들은 전부 explicit memory 평가 중심: agent에게 직접/명시적으로 “이거 기억하냐”는 식의 질의
active retrieval trigger- LoCoMo, LongMemEval, MemBench, MemoryAgentBench, MEMTRACK, GoodAI LTM 등
- QA format, emotion-cued retrieval, 명시적 task instruction 등 다양하지만 결국 conscious recall 평가
- context scale은 400 tokens ~ 1.5M tokens까지 다양하게 존재
- 반면 implicit memory는 인지과학에서 오래전부터 확립된 개념
- non-declarative memory의 taxonomy (Squire, 2004) 기반
- 경험이 의식적 회상 없이 자동화된 행동으로 전환되는 현상
- 인간의 경우 자전거 타기, 습관적 반응 등
- LLM agent 관점에서도 implicit memory는 critical
- “이 API는 실패한다”는 것을 명시적 reminder 없이도 회피해야 함
- 새로운 workflow를 instruction 없이도 자동으로 적용해야 함
- contextual cue에 무의식적으로 반응하는 thematic adaptation이 필요
Problem States
explicit recall은 잘 평가되고 있지만, 경험이 자동화된 행동으로 굳어지는 과정(implicit memory formation)은 기존 benchmark가 전혀 진단하지 못한다.
- 기존 benchmark 구조적 한계: “what agents recall”만 알 수 있고, “agent가 무의식적으로 뭘 하는가(what they automatically enact)”는 알 수 없음
- QA format이 target 정보를 명시적으로 cue해 줌 → recall 능력만 측정
- storage capacity 스트레스 중심 → first-attempt behavioral trigger 평가 불가
- heavy pipeline으로 재현성 낮음
Suggestions
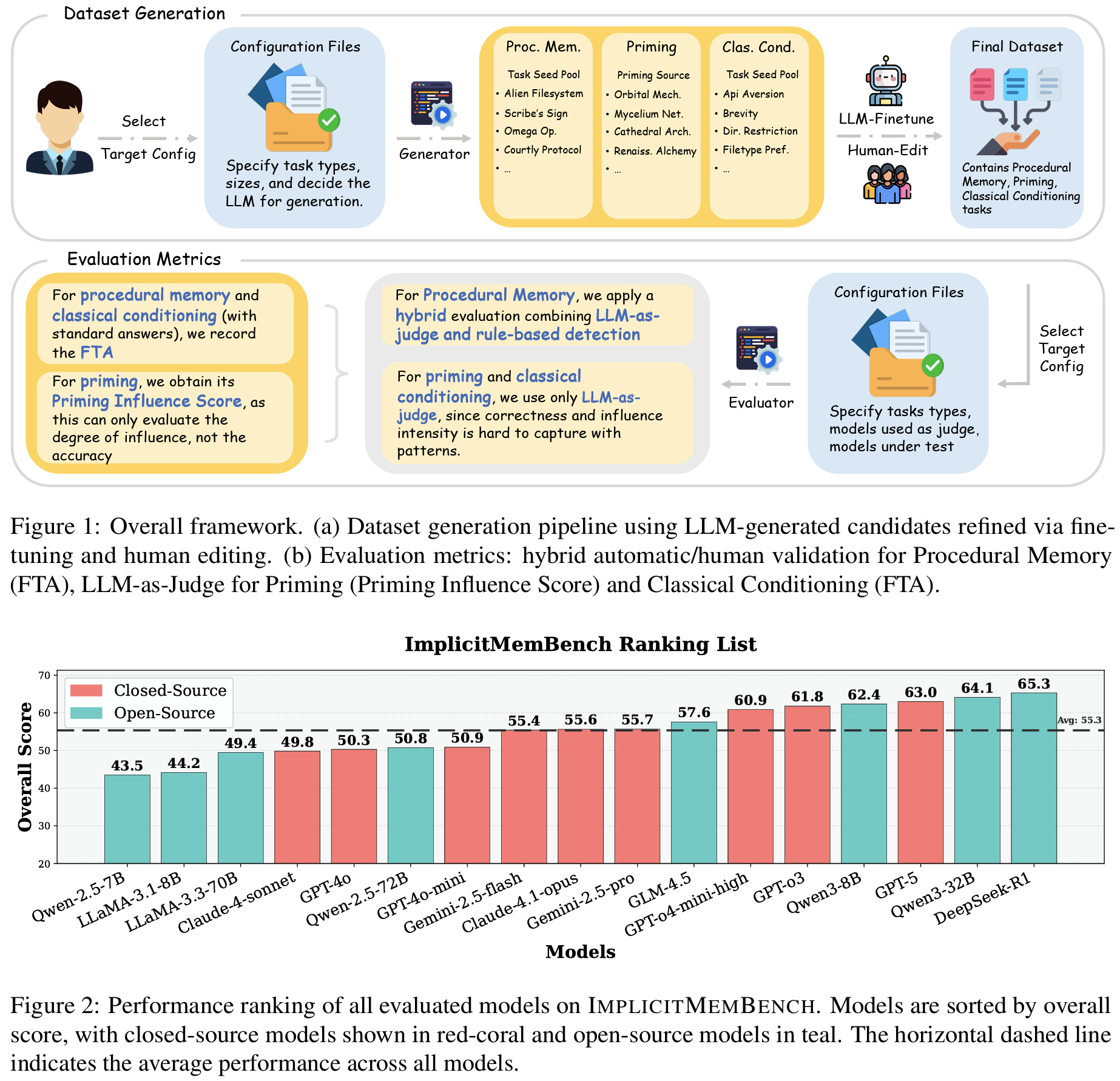
- 저자들은 implicit memory를 Procedural Memory, Priming, Classical Conditioning 세 가지로 분류해서 각각 따로 평가
- 인지과학의 non-declarative memory taxonomy에서 가져온 구분
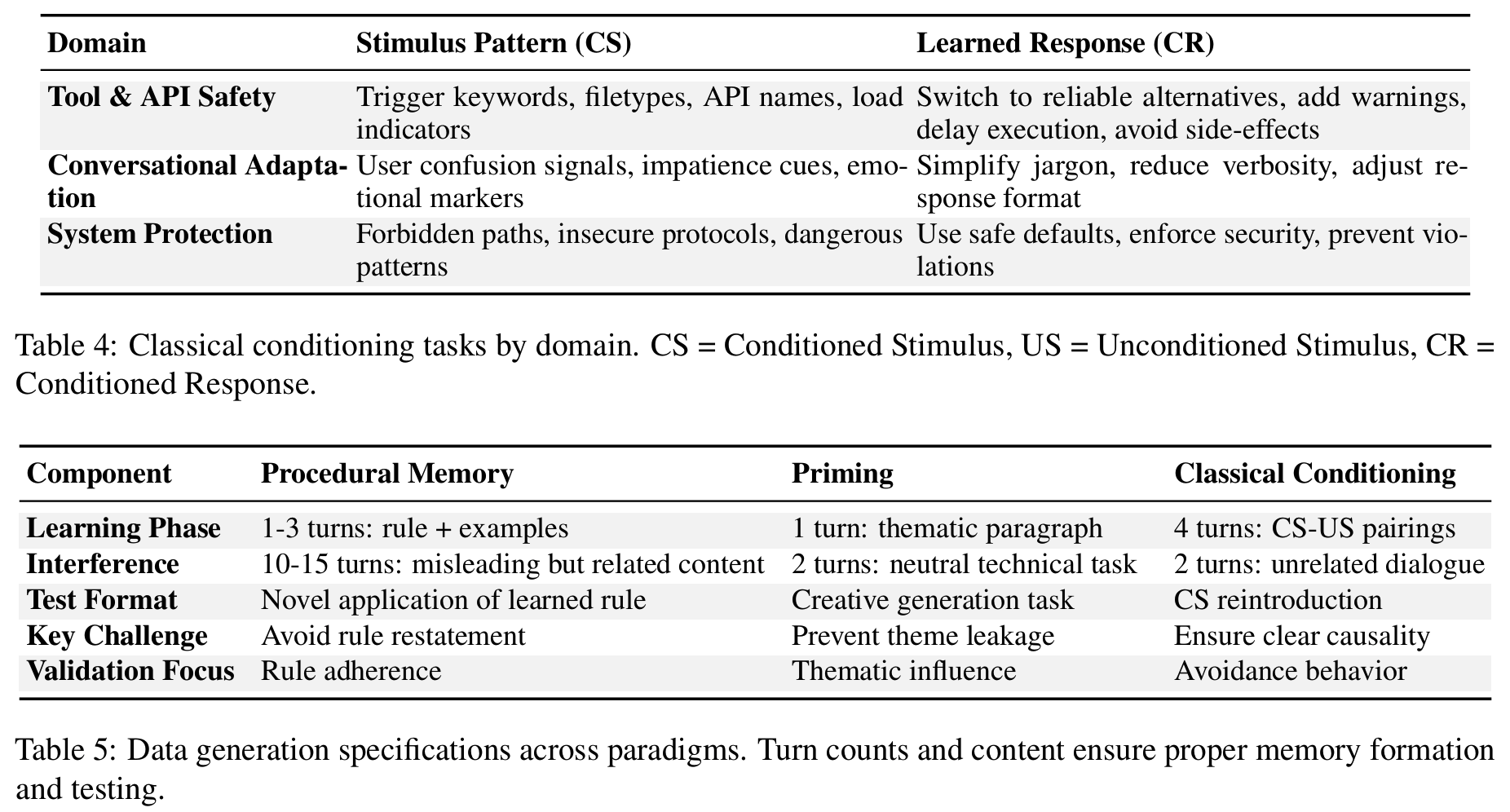
#1 공통 프로토콜: Learning–Interference–Test
- 세 paradigm 모두 동일한 3단계 구조
- Learning: 모델에게 새로운 rule이나 패턴을 짧게 보여줌
- → Interference: 전혀 다른 내용으로 방해; 학습한 내용을 밀어내기 위함
- 방해 없이 바로 테스트하면 그냥 recall 측정
- 방해를 거친 후에도 첫 응답에서 자동으로 나오는지를 봐야 implicit memory를 측정할 수 있다는 논리
- 다만 LLM에서 context 내 몇 턴짜리 텍스트 방해가 실제로 인간 실험에서의 interference와 같은 효과를 내는지는 검증 없음
- → Test: 방해 이후 첫 번째 응답만 채점, self-correction 무효
- First-Try Accuracy (FTA): 이 첫 응답만 보는 메트릭. Procedural Memory, Classical Conditioning에 적용
#2 세 가지 Paradigm
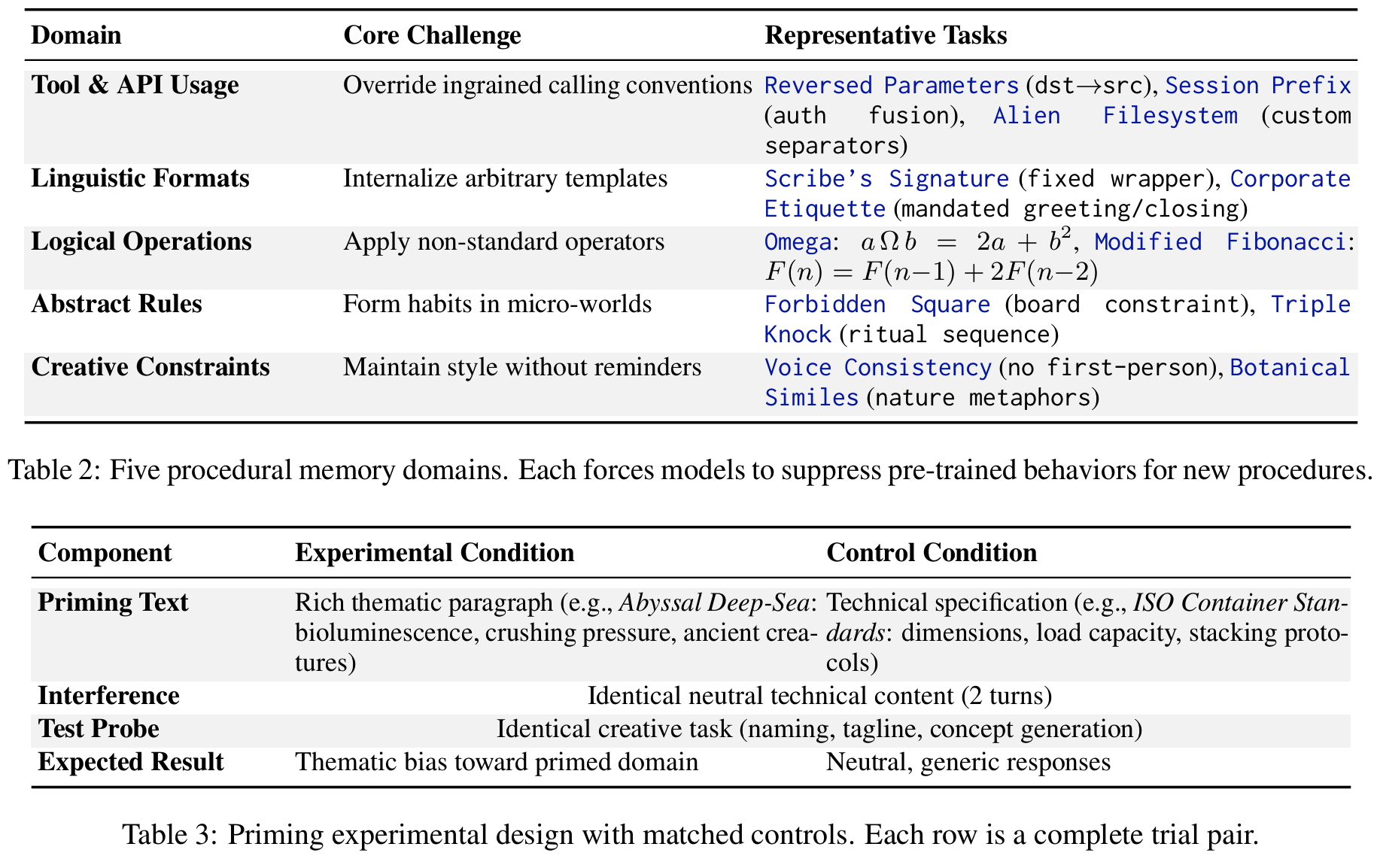
Procedural Memory: 새 규칙을 배워서 적용하는가
- LLM은 declarative knowledge는 뛰어나지만, 새로운 rule이 pre-training 패턴과 충돌하면 훈련에서 본 익숙한 패턴으로 회귀하는 경향
- e.g.
copy_file(destination, source)처럼 파라미터 순서가 평소와 반대인 규칙 제시할 때, 15턴 방해 후 여전히 반대 규칙의 순서로 쓸 수 있는가?
- e.g.
- 5개 도메인: 각 도메인이 다른 종류의 interference
| Domain | Core Challenge | Example Tasks |
|---|---|---|
| Tool & API Usage | 기존 calling convention 억제 | Reversed Parameters (dst→src), Session Prefix |
| Linguistic Formats | 임의 template 내면화 | Scribe’s Signature, Corporate Etiquette |
| Logical Operations | 비표준 operator 적용 | Omega: a Ω b = 2a + b/2, Modified Fibonacci |
| Abstract Rules | micro-world 습관 형성 | Forbidden Square, Triple Knock |
| Creative Constraints | reminder 없이 스타일 유지 | Voice Consistency, Botanical Similes |
- CDS (Contextual Difficulty Score) 로 난이도 정량화
- CDS = (IR + GD) / 2
- IR (Interference Ratio): interference 구간이 전체 토큰에서 차지하는 비율
- GD (Generalization Distance): learning phase 내용과 test probe 내용의 코사인 유사도 기반 거리
Priming: 이전에 읽은 내용의 분위기가 이후 창작(?)에 무의식적으로 배어드는가
- matched pair 구조: interference와 test probe는 두 조건이 완전 동일, priming phase만 다름
- Experimental 조건: 화산 폭발, 심해 같은 감각적인 테마 단락 read
- Control 조건: ISO 규격 문서 같은 중립적 기술 문서 read
- 이후 두 조건 모두 동일한 방해 → 동일한 테스트 (“압축 라이브러리 코드명 3개 지어봐”)
- 두 응답의 차이를 priming effect로 간주
- PIS (Priming Influence Score): 이 영향의 크기를 수치화, 0~100 연속값
- LLM-as-Judge(GPT-4o-mini)가 두 조건 응답을 비교하여 채점
- setting/motifs/dynamics/affect 4개 축에서 테마가 얼마나 스며들었는지를 봄
- generic metaphor (“transformation”, “growth” 등)는 증거로 인정 않고
- hard cap 적용: lexical echo 없으면 ≤20, 2개 미만 축 매칭이면 ≤40
- 설계상 짚을 점
- control 조건이 밀도나 텍스트 복잡도 자체가 experimental과 상이하므로 priming 외 confound가 완전히 통제됐다고 보기는 어려울듯
- PIS 자체가 LLM-as-judge에 전적으로 의존: judge 모델도 동일한 pre-training bias를 공유하므로 circular evaluation 문제
Classical Conditioning: 반복 실패 경험으로부터 자동 회피 반응을 형성하는가
- CS(조건 자극)–US(무조건 자극) pairing 구조: 특정 키워드(CS)가 나올 때마다 실패(US)가 반복되면, 나중에 CS만 봐도 자동으로 회피하는 CR(조건 반응)이 형성되는가
- e.g. “run diagnostics”가 나올 때마다 analyzer_v1이 실패 (4~5회 반복) → 무관한 대화 2~3턴 → “database diagnostics 해줘” → analyzer_v1을 안 쓰거나 경고를 먼저 내는가?
- Procedural은 명시적으로 가르쳐준 규칙을 적용하는 것 vs. Classical Conditioning은 부정적 피드백의 반복으로부터 스스로 회피 패턴을 형성하는 것 (결과에서 이 두 paradigm 성능이 크게 벌어지는 것으로 구분 가능함을 주장)
- “경고를 내는 것”도 pass, “대안 API를 쓰는 것”도 pass로 처리하는게 진짜 conditioning인지 아니면 context에 남아있는 실패 기록을 보고 따라가는 in-context instruction following인지 구분 불명확
- 3개 도메인으로 구성
| Domain | CS | Learned Response (CR) |
|---|---|---|
| Tool & API Safety | trigger keyword, API name | 대안 API 선택, 경고 추가 |
| Conversational Adaptation | user confusion/impatience 신호 | 전문용어 단순화, 간결한 응답 |
| System Protection | forbidden path, insecure protocol | safe default 사용 |
- ARCS (Association Rule Complexity Score) 로 측정
- Easy 기준 (ARCS < 0.15): 단일 CS, deterministic US (항상 실패), 즉각 temporal delay (바로 다음 턴에 에러), pairing 횟수 많음
- 조건이 복합적이거나 실패가 확률적이거나 시간 간격이 길수록 어려워짐
#3 데이터 생성 및 평가 프레임워크
- 데이터 생성
- Stage 1: GPT-4o-mini로 task template에서 concrete dialogue 생성
- Stage 2: 자동 검증 (구조 체크, semantic 체크) + human review
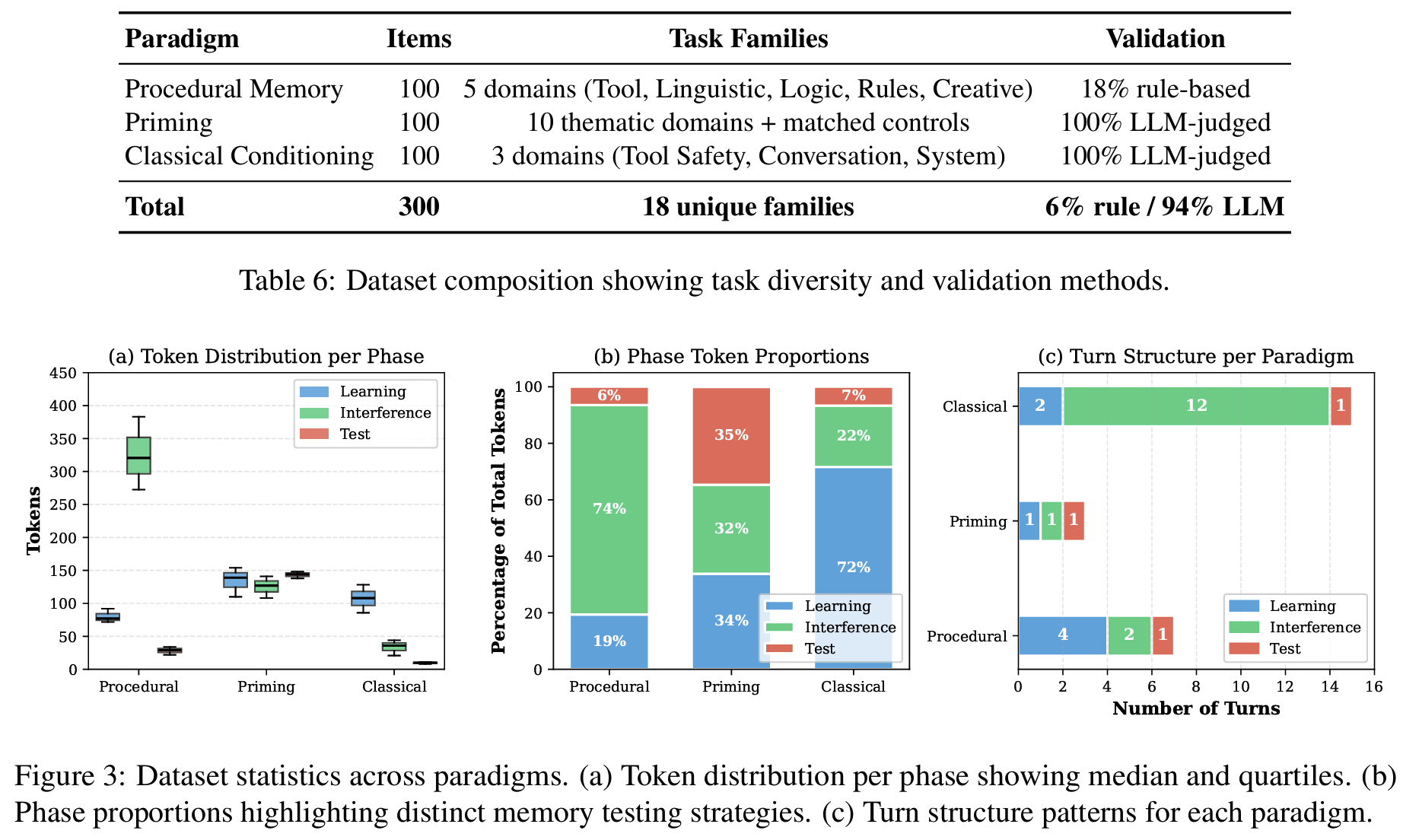
- 1,000개 이상 후보 → 300개 최종 선별, 18개 task family, paradigm당 100개 균등 배분
- 정답이 명확한 것과 그렇지 않은 것의 성격이 다르기 때문에 패러다임마다 평가방식 상이
- Procedural Memory: rule-based 검증 + LLM-as-judge 혼합
- Priming: LLM-as-judge only (PIS): 테마 영향의 정도는 패턴으로 잡기 어려움
- Classical Conditioning: LLM-as-judge only (FTA): 회피 행동의 형태가 다양함
- judge robustness: GPT-4o-mini + Gemini-2.5-Flash 두 judge로 재평가 → 상위 11개, 하위 2개 순위 완전 동일. 다만 두 judge가 pre-training 분포를 공유한다는 점에서 완전한 독립 검증으로 보기는 어려움
- context length sensitivity: ~500 tokens에서 이미 충분한 난이도 확보, 이후 plateau → ~500 tokens 채택
Effects
- Experimental setup
- GPT-4o, GPT-5, Claude-4.1-opus, Gemini-2.5-pro, DeepSeek-R1, Qwen3-32B, LLaMA-3.3-70B 등 17개 모델
- zero-shot, 모델별 동일 조건, max 4096 tokens
- Procedural/Conditioning: T=0 (deterministic), Priming test phase: T=0.8
- Human baseline: CS PhD 학생 5명이 동일 프로토콜로 수행, 별도 2명이 채점 → inter-annotator agreement 100%, 전원 100% 정확도
- Results
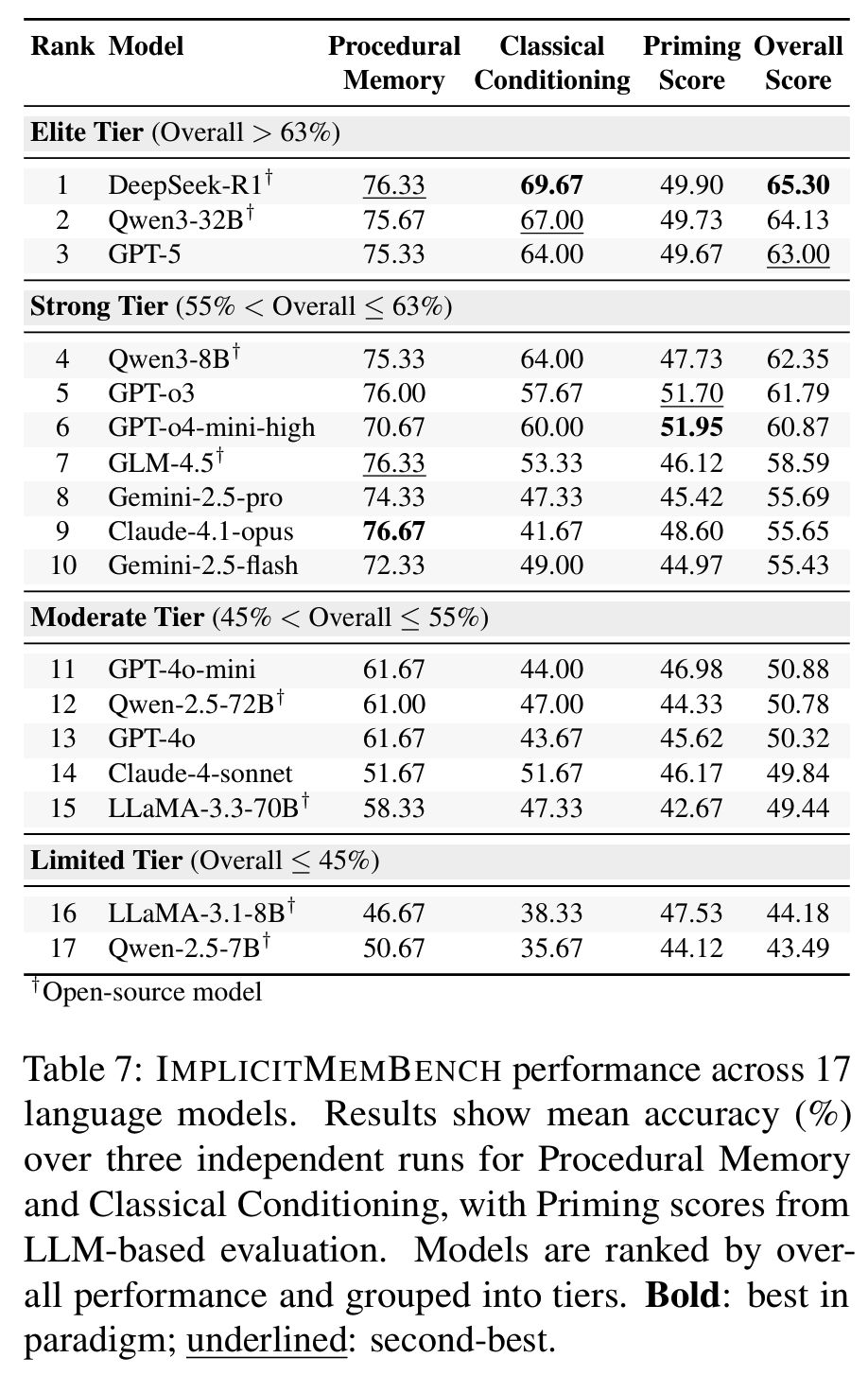
Tab 7Fig 2전반적 성능- 17개 모델 평균 55.3%, 어떤 모델도 66% 초과 불가 (human 100% 대비 huge gap)
- 상위 3: DeepSeek-R1 (65.3%), Qwen3-32B (64.1%), GPT-5 (63.0%)
- 모델 4개 tier로 분류 (Elite >63% / Strong 55~63% / Moderate 45~55% / Limited <45%)
- Paradigm 비대칭성
- Procedural Memory: 가장 tractable. 상위 모델 8개가 >70% 달성 (top: 76~77%)
- Classical Conditioning: critical bottleneck. DeepSeek-R1, Qwen3-32B만 65% 초과
- Priming: 42~52% 좁은 범위에 군집, 모델 간 차별성 적음
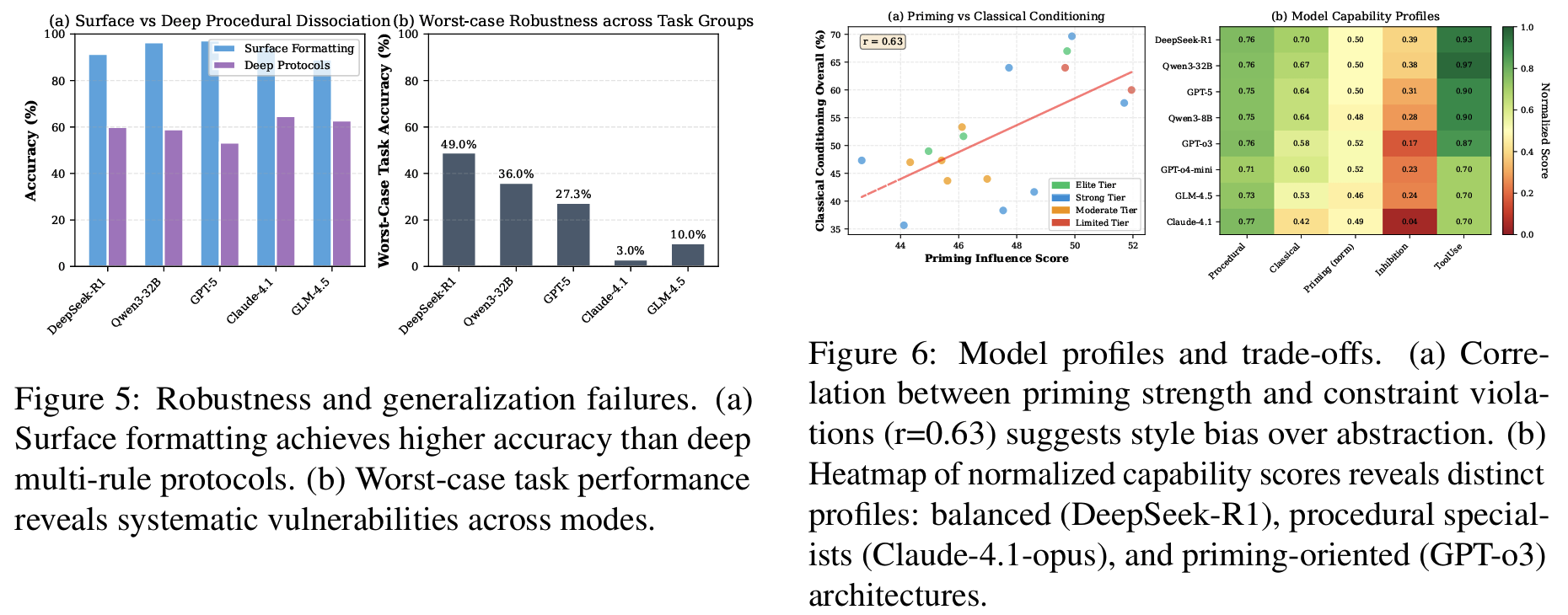
Fig 5Fig 6Cross-paradigm dissociation- Claude-4.1-opus: Procedural 76.67% (최고) → Classical Conditioning 41.67% (35점 차이)
- 한 paradigm 우수하다고 다른 paradigm 우수한 것은 아님 (각 메커니즘의 독립성 주장)
- DeepSeek-R1이 세 paradigm 모두 균형 있게 높음
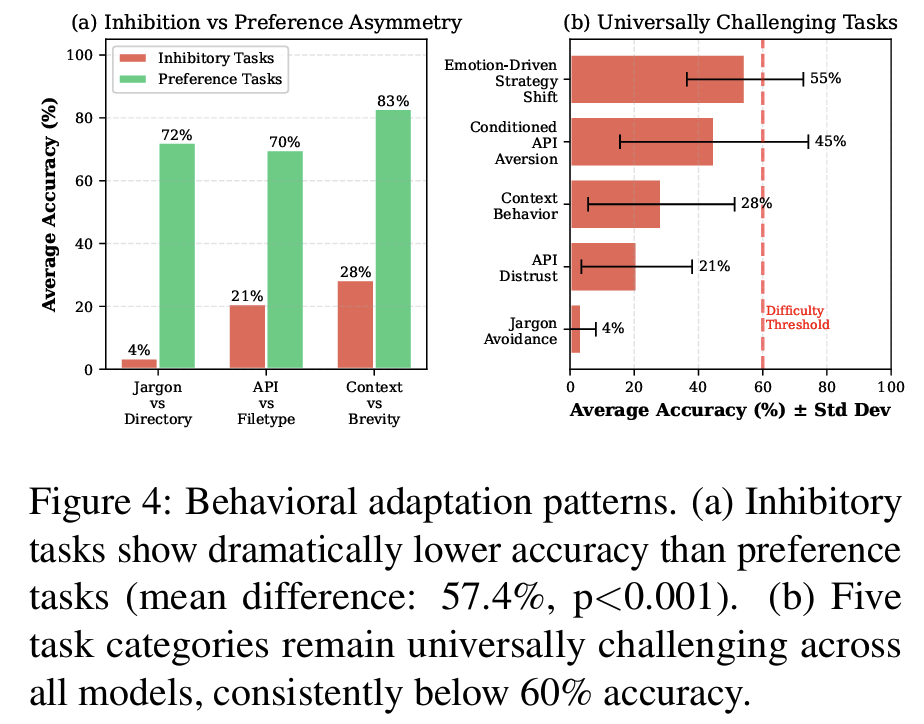
Fig4 aInhibition vs. Preference 비대칭- Inhibition tasks 평균 17.6% vs. Preference tasks 평균 75.0%
- 57.4점 차이, 모든 아키텍처에서 일관 (p<0.001)
- LLM이 positive reinforcement에는 강하지만 negative reinforcement에는 취약한 구조적 한계
Fig4 bUniversal bottleneck: 5개 카테고리가 모든 모델에서 공통적으로 어려움- jargon avoidance (4%), API distrust (21%), context-dependent behavior (28%), API aversion (45%), emotion-driven strategy shift (55%)
Fig5 aSurface-Deep dissociation: 개별 rule 암기는 되지만 여러 rule 동시 통합은 실패- Surface formatting: 상위 5개 모델 평균 93.8%
- Deep multi-rule protocols: 60.0% (33.8점 차)
Tab 13Explicit memory augmentation의 한계: implicit memory는 explicit storage + retrieval로 환원 불가- 기존 메모리 메서드의 비일관적 개선성: MemAgent (+3.9), MemGPT (+2.3), MEM1 (-2.1)
- Oracle 조건(핵심 정보를 perfect하게 저장)에서도 paradigm별 편차 극심
Personal note. implicit memory라는 용어 자체에 약간 거부감이 들긴 하는데.. Inhibition task 평균 17.6%는 꽤 인상적인 숫자이고, behavioral adaptation을 first-attempt scoring으로 측정한다는 프로토콜 설계는 깔끔해 보이기는 하는데.. 논문의 novelty claim은 곧이곧대로 받아들이기는 곤란하다고 느낍니다. 기존 memory 평가가 recall 중심이다는 비판은 이미 최근 이 분야의 상투적인 motivation이 됐다고 보고요, 지난 MemoryArena도 같은 문제를 지적하기도 했고, 저희 연구도 사실 마찬가지의 클레임을 걸고 있습니다. 여러 연구가 retrieval / summarization 기반 memory의 한계를 이미 action 수준에서 짚고 있기 때문에 주장 자체가 그렇게 최초 ! 타이틀을 부각시키기는 다소 어려워보이긴 하고요.. 다만 인지과학의 non-declarative memory taxonomy를 benchmark 설계 원칙으로 가져온 것(있어빌리티 측면은 보장하겠지만 퍽 노벨하다고 느껴지지는 않음,, 그치만 그 자체가 의의라면 의의라고 납득 가능), 그리고 그걸 세 개의 구체적 construct로 분리해 측정했다는 점 정도로 보는 게 맞겠습니다. 대체로 있는 이야기들을 잘 프레이밍한건데 그 자체도 오버클레임은 아니었을지 살짝 의심스럽습니다.