Memory Transfer Learning: How Memories are Transferred Across Domains in Coding Agents
Meta info.
- Authors: Kangsan Kim, Minki Kang, Taeil Kim, Yanlai Yang, Mengye Ren, Sung Ju Hwang
- Paper: https://arxiv.org/abs/2604.14004
- Project: https://memorytransfer.github.io/
- Affiliation: KAIST, New York University, DeepAuto.ai
- Published: April 15, 2026



TL; DR
Coding agent의 self-evolving memory를 domain 내부 말고도 그 밖에 있는 domain 간 transfer 하자; 추상도가 높은 Insight 형태의 meta-knowledge가 cross-domain에서 일관된 성능 향상을 만든다.
Review Video




Background
- self-evolution: LLM이 inference 결과를 스스로 활용해 발전하는 흐름, 학습 데이터 스케일링의 한계를 보완하는 대안으로 부상
- memory가 핵심: 과거 성공 패턴을 재사용하거나 실패 action을 회피하는 역할
- e.g. coding agent’s memory: code snippet, planning/debugging trace, programming principle 등
- 기존 memory-augmented coding agent의 한계
- memory 생성/검색을 동일 domain(대개 동일 benchmark) 안에서만 수행
- e.g. SWE memory → SWE task only, ML/AI memory → MLE task only
- 현실의 coding agent는 runtime env (Linux shell), 언어, dependency stack 같은 공통 infrastructure를 공유하며 이종 task를 모두 다뤄야 함
- heterogeneous domain 간에 shared foundation이 존재하고
- memory도 그 위에서 cross-domain으로 전이될 수 있어야
- 선행연구
- ReasoningBank (Ouyang et al., 2025): trajectory로부터 insight 추출, test-time scaling으로 memory 활용
- AWM (Wang et al., 2024c): web agent에서 reusable workflow 수집
- Dynamic Cheatsheet (Suzgun et al., 2025): 진화하는 cheatsheet 형태 memory
- AgentKB (Tang et al., 2025): 이종 domain에 걸친 unified memory pool을 제시했지만, transfer mechanism에 대한 mechanistic analysis는 결여
- ReMe (Cao et al., 2025), MemEvolve (Zhang et al., 2025): memory refinement / meta-evolution 관점의 연구
Problem States
self-evolving coding agent의 memory utilization을 “동일 domain” silo에서 “다른 domain” transfer로 확장할 수 있는가, 그리고 그 원리는 무엇인가?
- research question
- RQ1. 이종 domain memory가 coding agent 성능을 실제로 향상시키는가?
- RQ2. transferred memory가 cross-domain에서 이득을 주는 이유는 무엇인가?
- RQ3. transfer 효과를 결정짓는 핵심 요인은 무엇인가? (memory 형식, pool size, domain 다양성, model 간 transfer 등)
- 실용적 관점의 공백
- 어떤 형태(trajectory / workflow / summary / insight)가 cross-domain에서 잘 transfer되는지 불분명
- negative transfer가 언제 발생하는지에 대한 체계적 분석 부재
- memory pool size, domain 수, source/target model이 다를 때 어떤 영향이 있는지 알려지지 않음
Suggestions
- Memory source 정의 (입력)
- 각 benchmark에서 agent를 inference하고 inference history
$H = (t, [(r_i, a_i, o_i)]_{i=1..n})$수집- t: task, r: reasoning, a: action (bash command / code), o: observation
- LLM judge로 성공/실패를 판별, 성공/실패별로 memory 생성 prompt를 분리
- 각 benchmark에서 agent를 inference하고 inference history
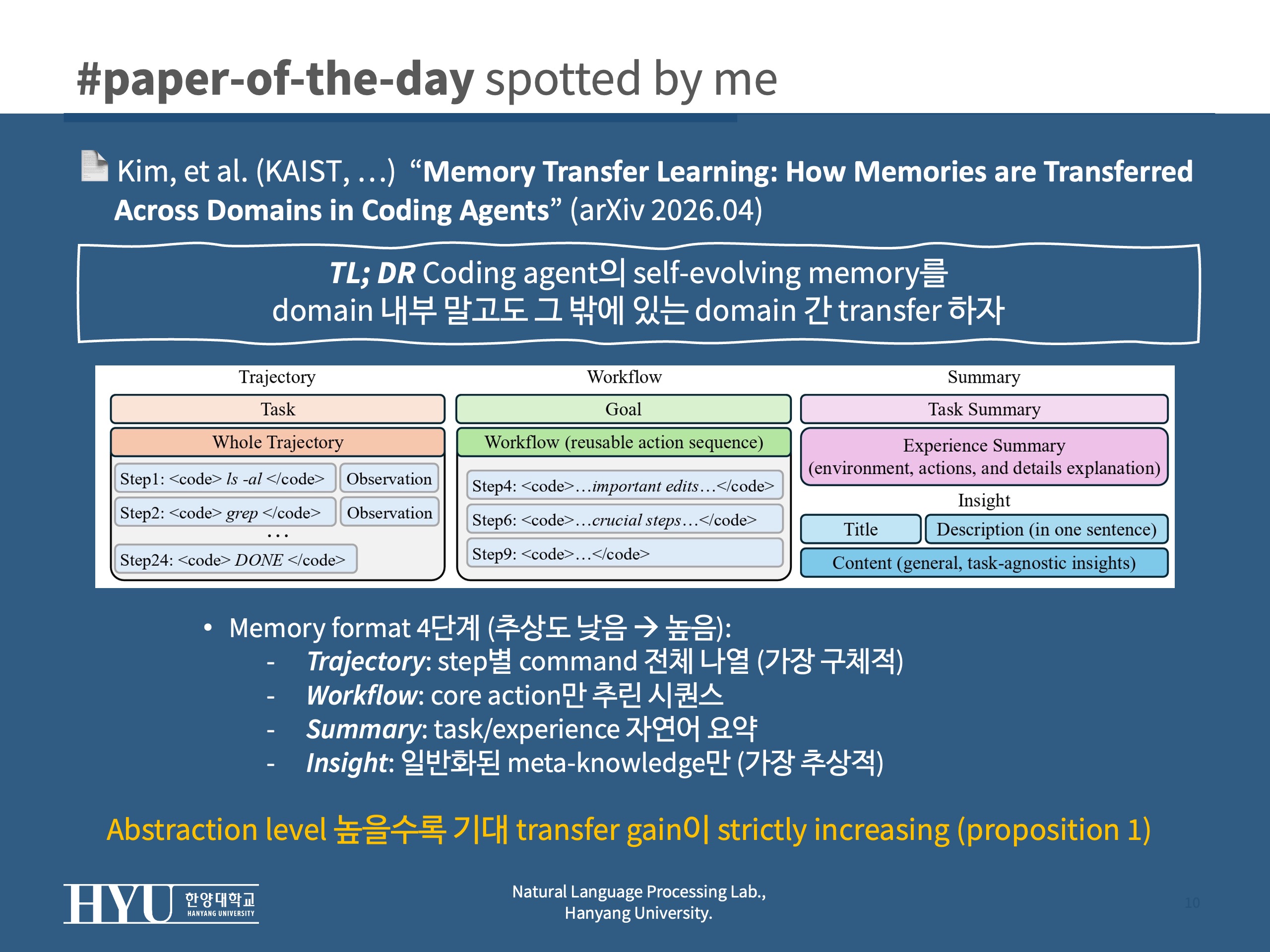
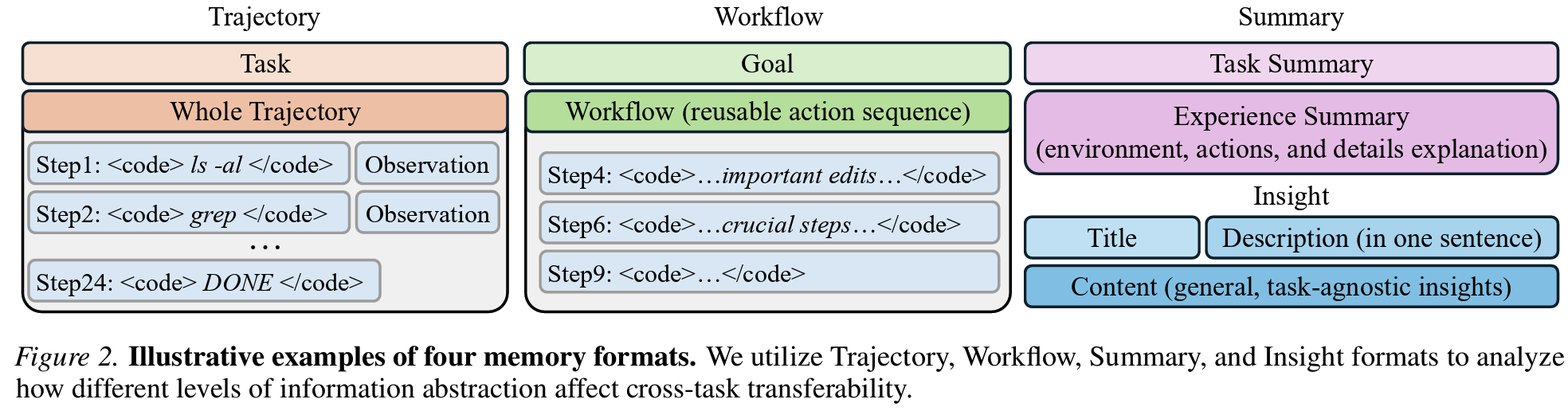
- memory format (Figure 2)
- Trajectory
$M_T = (t, [(a_1, o_1), ..., (a_n, o_n)])$: step 단위 command 나열- reasoning만 제거하고 command/observation 전체를 그대로 저장
- 가장 구체적(=추상도 최저), task-specific detail이 많이 남음
- Workflow
$M_W = (g, [a_i, a_j, ..., a_k])$: core action만 추린 시퀀스- H를 LLM에 넘겨 workflow goal g와 의미 있는 action subset을 추출
- reusable action sequence 형태, Trajectory보다 짧고 distraction이 적음
- Summary
$M_S = (s_t, s_e)$: task/experience 두 문단- task summary s_t + experience summary s_e (환경/동작/성패 원인 분석 포함)
- LLM이 자연어로 왜 됐고 왜 실패했는지를 한 문단으로 정리
- Insight
$M_I = (i_t, i_d, i_c)$title/description/content의 generalized 형태- ReasoningBank 형식. 구체 파일/구현은 제외하고, 일반화된 insight만 담도록 prompt
- 가장 추상적(=추상도 최고), task-agnostic
- Trajectory
- Memory pool 구축과 retrieval
- 이종 domain memory pool:
$P_τ(B_i) = {M_τ^{(k)} | t^{(k)} \notin B_i}$- target benchmark $B_i$에 속하지 않는 memory만 모음 (in-domain 정보 누출 방지)
- 각 memory를 textual embedding으로 indexing
- 2개 경로로 검색 구분
- Trajectory: task 필드가 있으니 현재 task와 직접 cosine similarity
- Workflow/Summary/Insight: task 필드가 없으니, 현재 task에 대한 4~5문장짜리 coding plan을 LLM으로 생성해 그 plan을 query로 사용
- top-N retrieval (default N=3) 후 coding agent의 system prompt 서두에 주입
- 이종 domain memory pool:
- Formal modeling: Abstraction–Transfer Tradeoff (Appendix C, 이론적 정당화)
- memory embedding을 domain-invariant 성분과 domain-specific 성분으로 분해
- e(m) = z_inv(m) + z_sp(m)
- Abstraction level
-
A = z_inv(m) ² / ( z_inv(m) ² + z_sp(m) ² ) - 높을수록 transferable meta-knowledge의 비중이 큼
-
- retrieval utility
- U(x, m) ∝ <e(x), z_inv(m)> - <e(x), z_sp(m)>
- transferable guidance에서 domain mismatch penalty를 뺀 형태
- Proposition 1 (bounded capacity 가정 하)
- 기대 transfer gain은 A에 대해 strictly increasing
- 직관: 추상도가 올라가면 구체 detail이 meta-knowledge로 교체되고, unseen task 기준으로 misaligned noise가 줄어들어 유용성이 증가
- memory embedding을 domain-invariant 성분과 domain-specific 성분으로 분해
- Memory Transfer Learning (MTL): 다른 coding domain에서 생성된 memory들을 공통 memory pool로 묶어, target task inference 시 retrieval로 활용하는 framework
- 전체 파이프라인:
memory generation (offline) → memory pool 구축 → memory retrieval → coding agent inference
- 전체 파이프라인:
- memory source 정의
- 각 benchmark에서 agent를 inference하고 inference history
$H = (t, [(r_i, a_i, o_i)]_{i=1..n})$수집- t: task, r: reasoning, a: action (bash command / code), o: observation
- LLM judge로 성공/실패를 판별, 성공/실패별로 memory 생성 prompt를 분리
- 각 benchmark에서 agent를 inference하고 inference history
- Memory pool 구축과 retrieval
- 이종 domain memory pool:
$P_τ(B_i) = {M_τ^{(k)} | t^{(k)} \notin B_i}$; target benchmark $B_i$에 속하지 않는 memory만 모음 (in-domain 정보 누출 방지) - 각 memory를 textual embedding으로 indexing
- 검색은 두 경로로 구분
- Trajectory는 task 필드가 있으니 현재 task와 직접 cosine similarity
- Workflow/Summary/Insight는 task 필드가 없으니, 현재 task에 대한 4~5문장짜리 coding plan을 LLM으로 생성해 그 plan을 query로 사용
- top-N retrieval (default N=3) 후 coding agent의 system prompt 서두에 주입
- 이종 domain memory pool:
- Formal modeling: Abstraction–Transfer Tradeoff (Appendix C)
- memory embedding을 domain-invariant 성분과 domain-specific 성분으로 분해:
$e(m) = z_inv(m) + z_sp(m)$ - Abstraction level
$A = ||z_inv(m)||² / (||z_inv(m)||² + ||z_sp(m)||²)$; 높을수록 transferable meta-knowledge 비중이 큼 - retrieval utility
$U(x, m) ∝ <e(x), z_inv(m)> - <e(x), z_sp(m)>$; transferable guidance에서 domain mismatch penalty를 뺀 형태 - bounded capacity 가정 하에 Proposition 1: 기대 transfer gain은 A에 대해 strictly increasing
- 직관: 추상도가 올라가면 구체 detail이 meta-knowledge로 교체되고, unseen task 기준으로 misaligned noise가 줄어들어 유용성이 증가
- memory embedding을 domain-invariant 성분과 domain-specific 성분으로 분해:
Effects
- Experimental setup
- base model: gpt-5-mini (memory 생성 / LLM judge / coding agent base 모두 공통), cross-model 실험엔 DeepSeek V3.2와 Qwen3-Coder-480B-A35B-Instruct 추가
- coding agent framework: mini-swe-agent, 평가 플랫폼: harbor
- text embedding: OpenAI text-embedding-3-small, retrieval top-N=3
- coding benchmark (6개)
- competitive / function-level: LiveCodeBenchv6, Aider-Polyglot
- repository-level: SWE-Bench Verified, Terminal-Bench2
- domain-specific: ReplicationBench (과학 논문 코드 재현), MLGym-Bench (ML 연구 task)
- 평가: 각 benchmark에서 최대 100 task sampling, Pass@3 기준 리포트 (Appendix A에 Pass@1 결과 별도 제공)
- 비교 대상: zero-shot, MTL (T/W/S/I 네 format), self-evolving baseline으로 ReasoningBank와 AgentKB
- 추가 분석 축: memory pool size scaling, source domain 수 scaling, cross-model transfer, retrieval 방식 비교 (LLM reranking / adaptive rewriting), negative transfer 사례 연구
- Results
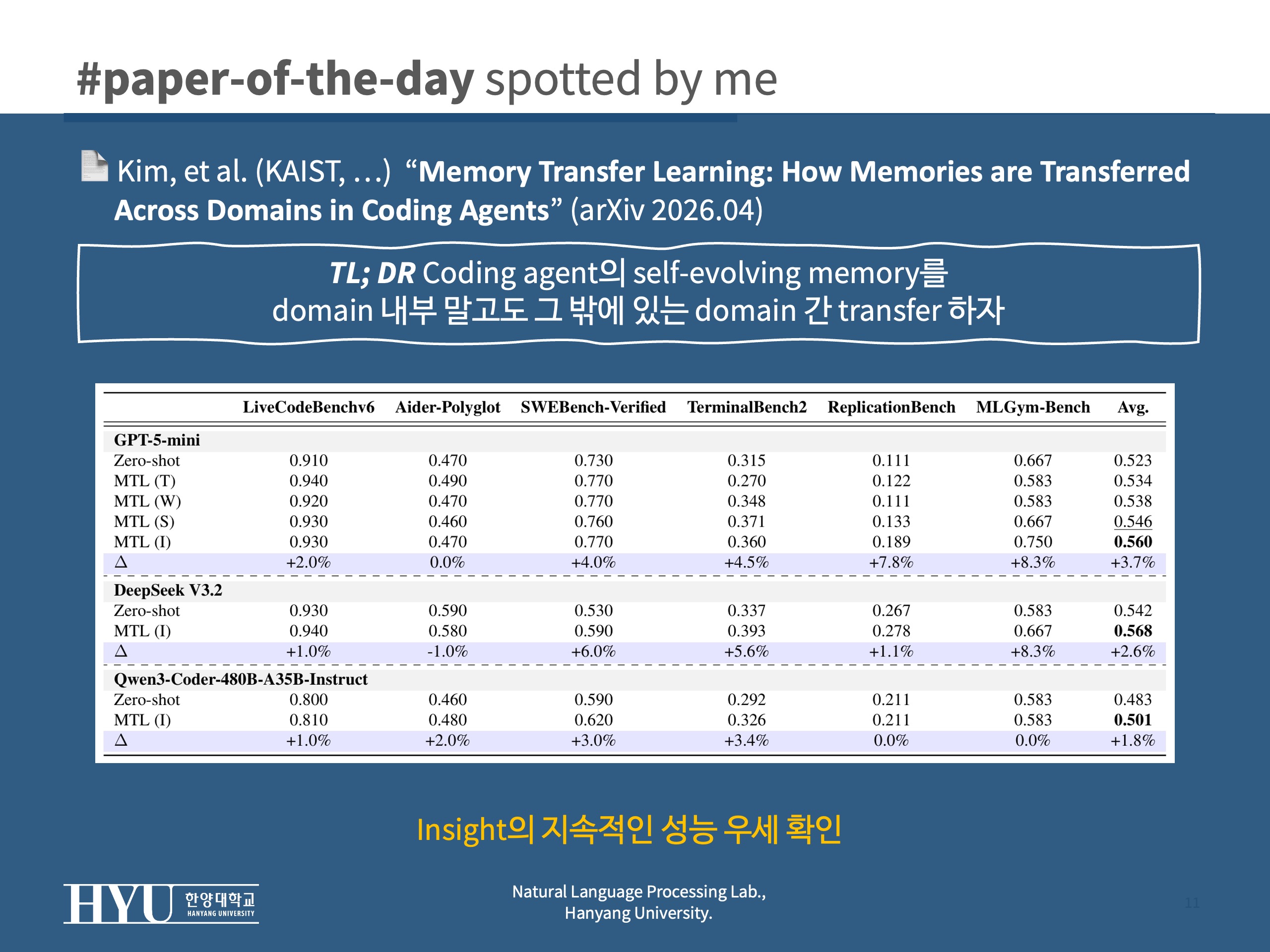
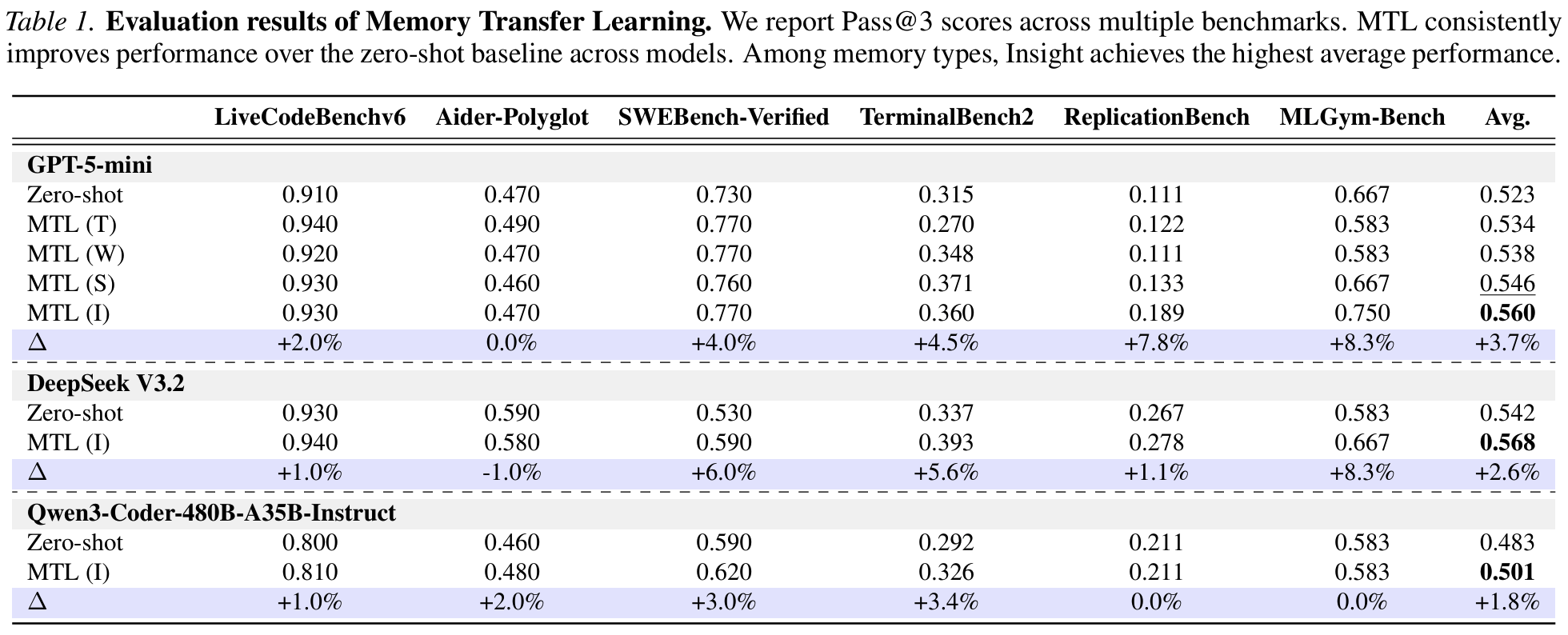
- Table 1: MTL(I)가 6개 benchmark 평균에서 zero-shot 대비 +3.7% 개선 (GPT-5-mini 기준 0.523 → 0.560)
- Insight > Summary > Workflow > Trajectory 순으로 성능; 추상도 축과 정확히 일치
- DeepSeek V3.2, Qwen3-Coder 등 open-source model에서도 각각 +2.6%, +1.8% 향상 ; model 계열에 의존하지 않는 일반성
- benchmark 별로는 MLGym-Bench(+8.3%), ReplicationBench(+7.8%) 같이 domain-specific task에서 특히 큰 폭 개선
- Insight > Summary > Workflow > Trajectory 순으로 성능; 추상도 축과 정확히 일치
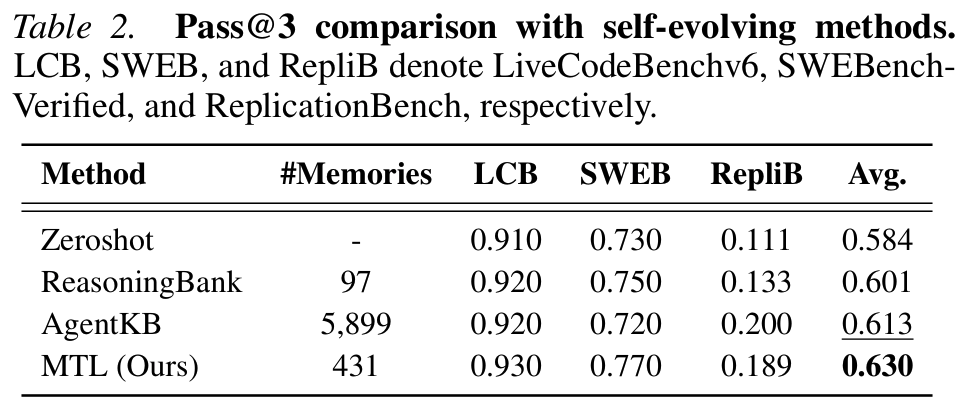
- Table 2: MTL(I)가 베이스라인대비 소폭 상승
- AgentKB가 5,899개 memory를 쓰는데도 MTL은 431개로 더 높은 평균 → 효과 및 효율 모두 잡았다고 강조.
- Table 3 (case study): zero-shot이 실패한 SWE-Bench 인스턴스에서, LiveCodeBench로부터 전이된 “inline Python here-doc으로 빠른 self-contained test 작성” Insight가 성공을 견인
- memory 내용이 SWE task와 직접 관련 없는 procedural guidance인데도 효과를 낸다는 것이 핵심
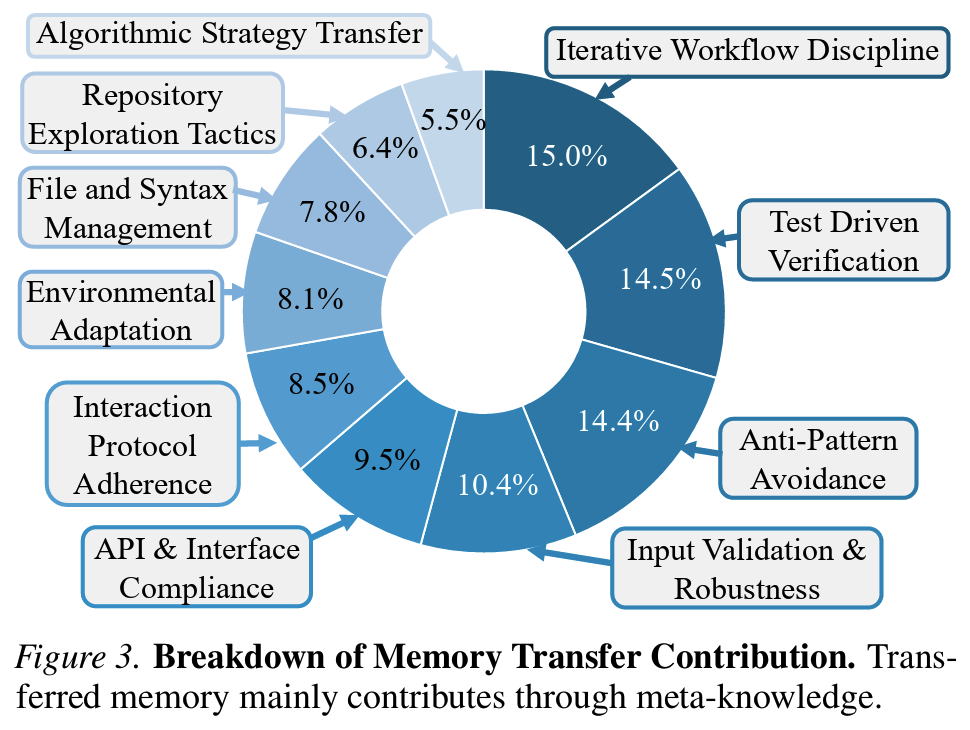
- Figure 3 (contribution breakdown): GPT-5를 judge로 failure→success 사례를 범주화
- Iterative Workflow Discipline 15.0%, Test Driven Verification 14.5%, Anti-Pattern Avoidance 14.4% 등 meta-knowledge 계열이 상위
- Algorithmic Strategy Transfer는 5.5%에 그침 == 직접적 algorithmic 지식 전이의 비중은 작음
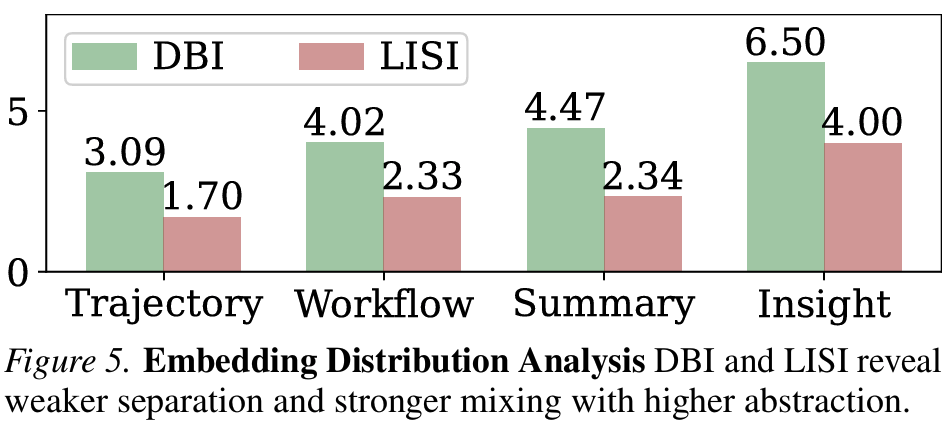
- Figure 4 + Figure 5 (abstraction의 embedding-level 증거): 추상도가 높을수록 task-agnostic해진다는 점을 quantitative하게 뒷받침
- DBI (Davies–Bouldin Index)는 T(3.09)→W(4.02)→S(4.47)→I(6.50)로 증가
- cluster 분리가 약해짐
- LISI (Local Inverse Simpson’s Index)는 1.70→2.33→2.34→4.00으로 증가
- 국소적으로 benchmark가 섞임
- DBI (Davies–Bouldin Index)는 T(3.09)→W(4.02)→S(4.47)→I(6.50)로 증가
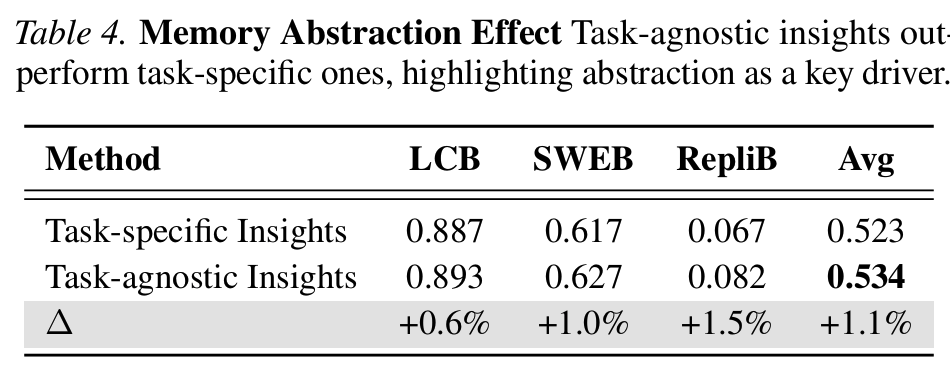
- Table 4 (abstraction isolation): 같은 Insight format 안에서도 task-agnostic top 30%가 task-specific bottom 30%보다 평균 +1.1% 우위
- format을 고정하고 abstraction만 바꿨을 때도 gain
- Table 5 (Trajectory vs Insight case study): MLGym에서 전이된 Trajectory가 C++ 환경에서 R 언어 파일 쓰기 패턴을 맹목적으로 따라 runtime error 유발
- 같은 source의 Insight는 “evaluation criteria 먼저 확인 후 data 병합/전처리 strategy를 적용”이라는 고수준 원칙만 전달 → 성공
- low-abstraction memory가 brittle anchor로 작동해 negative transfer를 일으킨다는 직관적 근거
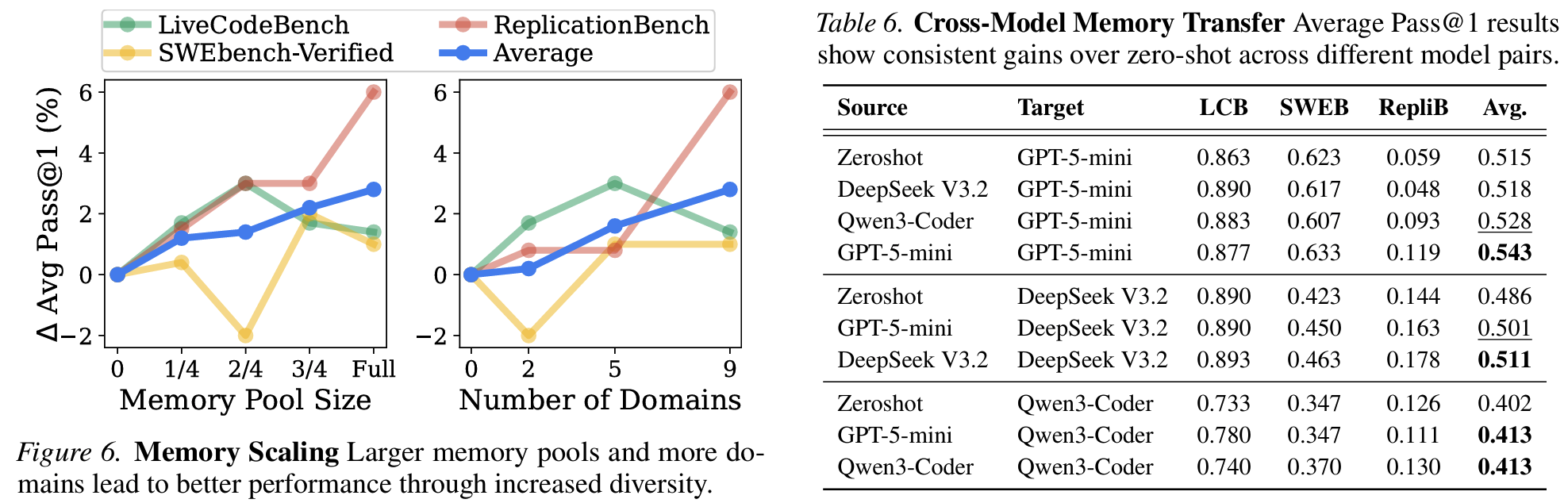
- Figure 6 (scaling): memory pool size를 1/4 → Full로 키우면 평균 성능 단조 증가, source domain 수를 0 → 9로 늘리면 역시 단조 증가
- 다양한 domain에서 온 memory일수록 retrieval 적중률과 meta-knowledge 커버리지가 올라감
- Table 6 (cross-model transfer): GPT-5-mini memory를 DeepSeek / Qwen3-Coder에 주거나 그 반대로 해도 zero-shot 대비 일관 개선
- 단, self-generated memory가 항상 최고 ; model-specific bias는 남아있음
- meta-knowledge가 model-agnostic한 환경/일반 coding guideline 수준에 걸쳐 있음을 시사
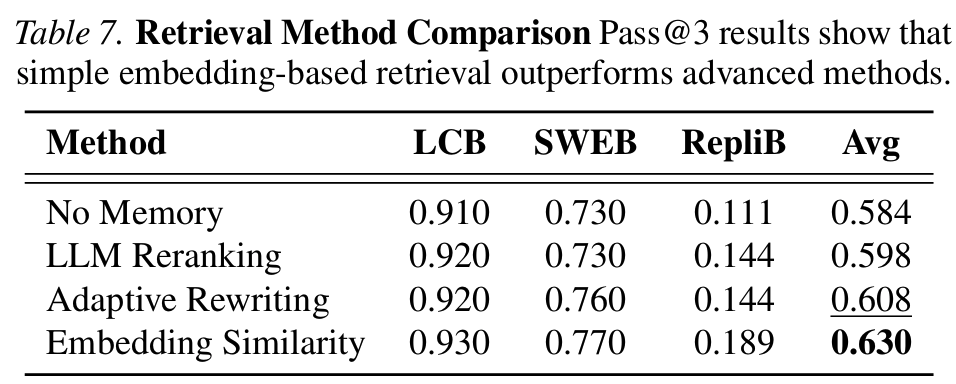
- Table 7 (retrieval ablation): LLM Reranking(0.598), Adaptive Rewriting(0.608) 모두 단순 Embedding Similarity(0.630)보다 낮음
- 정적인 retrieval 고도화는 dynamic multi-step agent setting에서 generalization이 잘 안 됨 → domain routing, step-wise retrieval 등 agentic retrieval 연구의 필요성
- Table 1: MTL(I)가 6개 benchmark 평균에서 zero-shot 대비 +3.7% 개선 (GPT-5-mini 기준 0.523 → 0.560)
- Negative transfer 분석 (Finding 4)
- Domain-mismatched anchoring: 표면 유사성만 있는 memory가 잘못된 가정을 주입
- False validation confidence: 검증 memory가 “대충 봐도 맞겠지”식 self-confirming loop를 만듦
- Misapplied best-practice transfer: 성공 패턴을 무차별 이식해 task-specific 요구를 위반
- 언급된 Limitation
- coding domain 한정
- static retrieval의 cross-domain 일반화 한계
- negative transfer 대응 모듈은 범위 밖
Personal note. KAIST에서 연구로, memory의 역할을 “기억력”이 아니라 “무엇이 전이 가능한지“로 재정의합니다. PRefine 연구와 연결성도 당연히 높습니다. preference가 abstract latent constraint여야 한다는 논지와 거의 같은 주장을 coding domain에서 하고 있다는 느낌입니다만.. retrieval ablation에서 rewriting/reranking이 embedding-only보다 나빴다는 점은 조금 의아한데, coding agent의 dynamic multi-step 특성 때문이라고 하지만..? preference/tool-calling 영역에서는 오히려 retrieval 시점의 조건화가 결정적일 수 있어서 해당 결론을 그대로 일반화하기는 어렵겠습니다. 그밖에 저는 baseline이 불공평한 것 같은데, coding 사이드와 general reasoning 사이드 비교가 정당한건지 잘 모르겠어요. coding 문제에서는 coding memory가 유리할것이니.. 벤치마크간 gain도 상당부분 일부에 몰려있어서 성능치에 살짝 의문..