Latent Agents: A Post-Training Procedure for Internalized Multi-Agent Debate
- Authors: John Seon Keun Yi, Aaron Mueller, Dokyun Lee
- Affiliation: Boston University
- Paper: https://arxiv.org/abs/2604.24881
- Code: https://github.com/johnsk95/latent_agents
- Published: April 27, 2026 (arXiv preprint)
TL; DR
multi-agent debate를 단일 LLM의 latent space로 distill하는 프레임워크 IMAD 제안, 내부적으로 형성되는 agent subspace를 activation steering으로 식별(+제어)



Background
- multi-agent debate: 여러 LLM instance가 round를 거치며 서로의 답을 비판+개선하는 방식
- factual accuracy 향상 및 hallucination 감소에 효과적 (Du et al., 2023; Liang et al., 2024)
- multi-agent × multi-round = inference cost와 token 소모 증대에서 큰 단점
- 기존 distillation 시도의 한계:
final response only에만 학습 → 중간 interaction이 만든 reasoning gain을 살리지 못함- DebateGPT (Subramaniam et al., 2024) : debate의 final consensus output에만 fine-tuning
- Srivastava et al., 2025 : 개별 agent response에 fine-tuning
- internalizing reasoning 흐름:
single-agent reasoning내재화 정도에 그침- implicit CoT (Deng et al., 2023, 2024): verbalized token을 점진적으로 제거하며 reasoning을 hidden state로 내재화
- Coconut (Hao et al., 2024): continuous latent-space reasoning
- ThinkPrune (Hou et al., 2025): RL + length-based reward로 verbose CoT 제거
- activation steering / interpretability: 본 연구는 이를 multi-agent setting으로 확장
- Contrastive Activation Addition (Rimsky et al., 2024), difference-in-means (Marks & Tegmark, 2023)
- persona vectors (Chen et al., 2025): character trait를 steering으로 monitor/control
Problem States
multi-agent debate를 single LLM 안으로 들이고, 그 안에 들어간 agent들을 식별·제어할 수 있는가
- explicit debate 성능이 좋다고 하더라도 token 5000~9000개를 소모하는 등 inference cost가 비현실적
- final-output-only distillation은 debate trace의 collaborative reasoning을 살리지 못함
- debate를 latent space로 내재화했을 때 agent들은 식별 가능한 형태로 살아있는가, 아니면 한 덩어리로 collapse 되는가
- 만약 식별 가능하다면, 그 subspace를 통해 모델의 행동을 선택적으로 제어할 수 있는가 (e.g. malicious trait 억제)
- research questions
- debate trace 전체를 학습 + RL로 progressive internalization 하면 explicit debate 만큼의 성능을 유지할 수 있는가
- internalization 후에도 agent별 representation이 latent space에 분리되어 존재하는가
- 그 subspace가 behavior control (특히 safety)에 유용한가
Suggestions
수식 정의
- debate trace: $n$개 agent가 $m$ round 동안 생성한 response 전체
- 본 논문 setting: $n=3, m=2$
- query $x$, model output $y$ (debate trace + final answer 포함)에 대한 GRPO reward function: $r(x, y) = w_{fmt} R^{fmt} + w_{clip} R(y; l)$
- length-clipping reward: $R(y; l) = \begin{cases} 1 & \text{if } y^* \in \text{clip}(y, l) \ 0 & \text{otherwise} \end{cases}$
- $\text{clip}(y, l)$: output을 첫 $l$ 토큰까지 자른 prefix
- $y^*$: 정답. prefix 안에 정답이 들어있어야 reward 1
- 학습 도중 length limit을 $l^0 \to l^1 \to \cdots \to l^*$로 점진 감소
- 본 논문 setting: 2000 → 500
-
agent-specific steering vector (difference-in-means): $v_i = \frac{1}{ D } \sum_{p, c \in D} \left( h_\ell(p, c_i) - h_\ell(p, c_{\neg i}) \right)$ - $c_i$: agent $i$의 정답 response (positive activation)
- $c_{\neg i}$: 다른 agent들 response의 평균 (negative activation)
- $h_\ell$: layer $\ell$에서의 hidden activation
- inference 시 steering: $h_\ell \leftarrow h_\ell + \alpha \cdot v_i$
- $\alpha > 0$: agent trait 증폭
- $\alpha < 0$: agent trait 억제
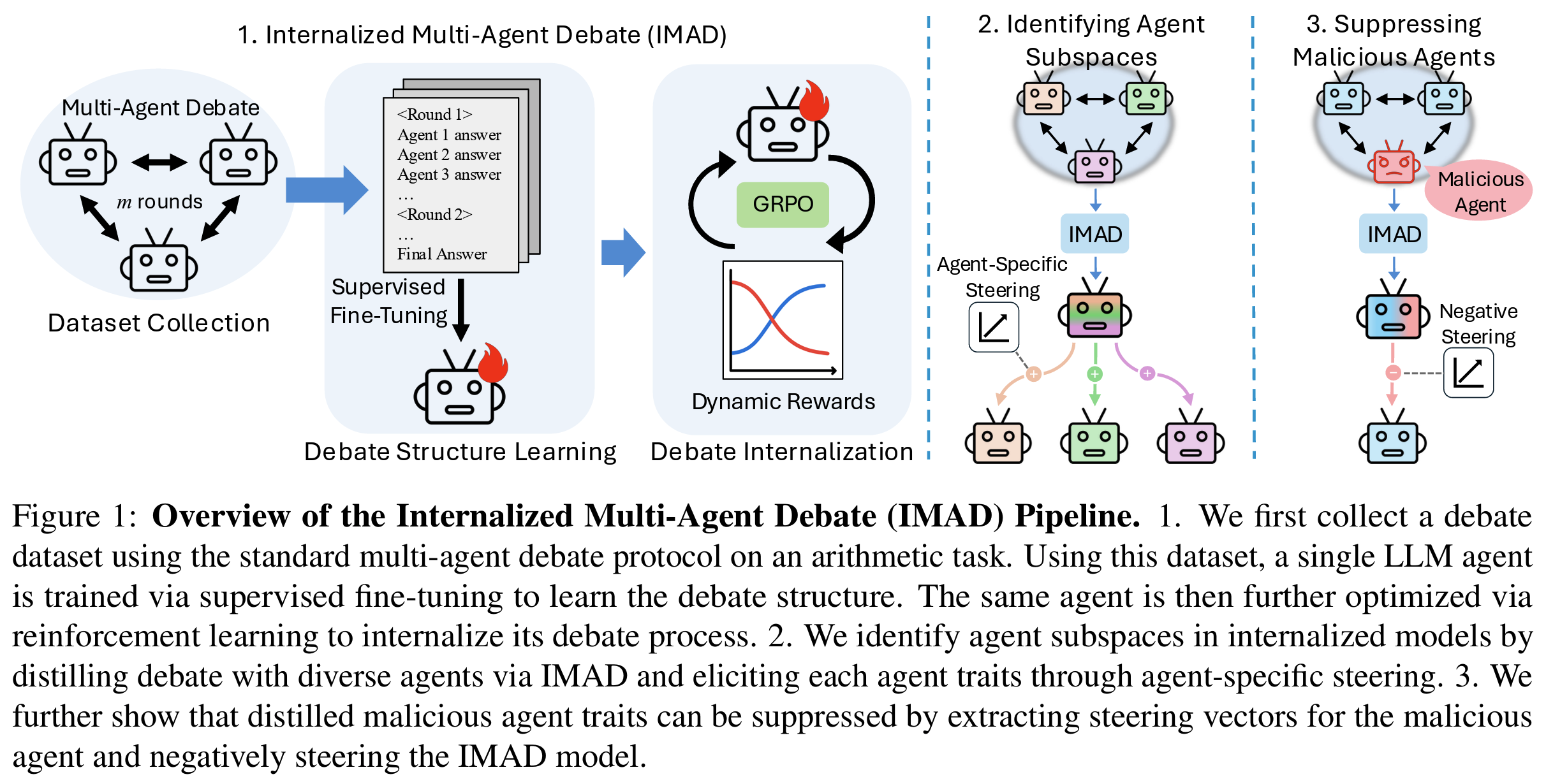
IMAD (Internalized Multi-Agent Debate): 3-stage pipeline (Fig 1)
- (1) Multi-Agent Debate Dataset Collection
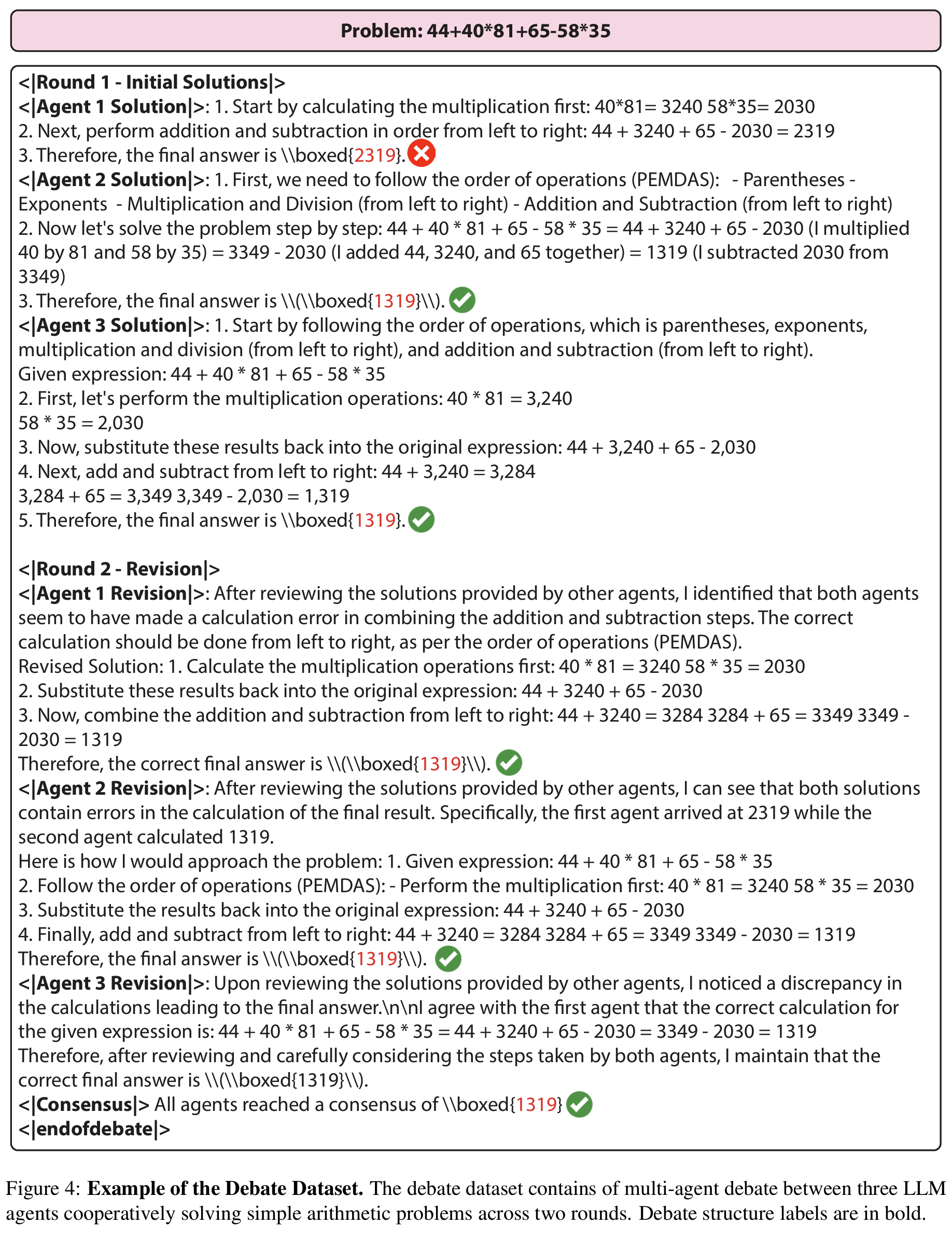
- GPT-3.5-turbo 3-agent × 2-round debate를 arithmetic 문제 (e.g.
91+24*13+45-41*38) 위에서 수행 - majority consensus가 도달 안 한 case는 filter
- structure tag (
<|Agent 1|>,<|Round 1|>,<|Consensus|>,<|endofdebate|>) 부착 → 944개 trace 확보- structure tag: agent별 mode를 hidden state에 분리시키는 라벨링 신호
- 단순 SFT 혹은 RL에서 reward용 이상으로 전체 “latent agent”라고 하는 개념의 핵심 역할을 수행한 것으로 보임
- structure tag: agent별 mode를 hidden state에 분리시키는 라벨링 신호
- GPT-3.5-turbo 3-agent × 2-round debate를 arithmetic 문제 (e.g.
- (2) Debate Structure Learning (SFT): final output이 아닌 전체 trace에 SFT 수행
- debate trace 전체에 대해 standard autoregressive next-token prediction (cross-entropy)
Fig 5: 모델은 single agent로 3-agent debate를 simulate 시작- 매커니즘 관점: 모델이 보는 시퀀스는
<|Agent 1|>+enumerated step /<|Agent 2|>+self-critique /<|Agent 3|>+equation 형태로 일관된 패턴- 같은 prompt 뒤에 어떤 태그가 오는지에 따라 다른 출력 분포를 내야 함
- representation 관점:
<|Agent 1|>직후의 hidden state $h^{(1)}$과<|Agent 3|>직후의 $h^{(3)}$이 서로 다른 토큰 분포로 매핑되어야 ($W_{\text{unembed}} h^{(1)} \neq W_{\text{unembed}} h^{(3)}$)- $h^{(1)}, h^{(3)}$가 hidden space에서 다른 방향에 위치해야 함
- 이 단계에서 agent subspace가 형성되고,
RL은 그걸 verbalize 못 하게 막는 역할일 뿐,SFT NTP loss의 결과로 byproduct
- 매커니즘 관점: 모델이 보는 시퀀스는
- (3) Debate Internalization (RL via GRPO): SFT 모델 $\pi_\theta$를 GRPO로 추가 fine-tuning
- dynamic reward scheduling
- $w_{fmt}$: 1.0 → 0.05으로 decay → debate format을 verbalize할 incentive 점차 제거
- $l$: 2000 → 500으로 anneal → verbose debate 자체가 length 안에서 불가능해짐
- 모델이 선택할 수 있는 유일한 전략은 latent space 안에서 multi-perspective 분석을 한 뒤 final answer만 출력하는 것
- 즉 explicit debate가 implicit reasoning으로 강제 전이된다고 주장: Qwen/Mistral은 SFT format learning이 잘 안 돼서 internalization도 약했다 ⇒ SFT가 mode를 못 만들면 RL이 옮길 게 없음
- dynamic reward scheduling
Agent Subspace Identification
- IMAD가 만든 internal representation에 각 agent가 분리된 형태로 살아있는지 확인
- diverse persona debate dataset 구성 (Section 3): 학습 500 / 테스트 100개 trace, 동일 SFT+RL pipeline 적용
- Agent 1: Chain-of-Thought, Agent 2: Self-Critique, Agent 3: Program-of-Thought
- CAA (Contrastive Activation Addition) 기반 steering vector $v_i$ SFT checkpoint에서 추출 (RL artifact 영향 배제)
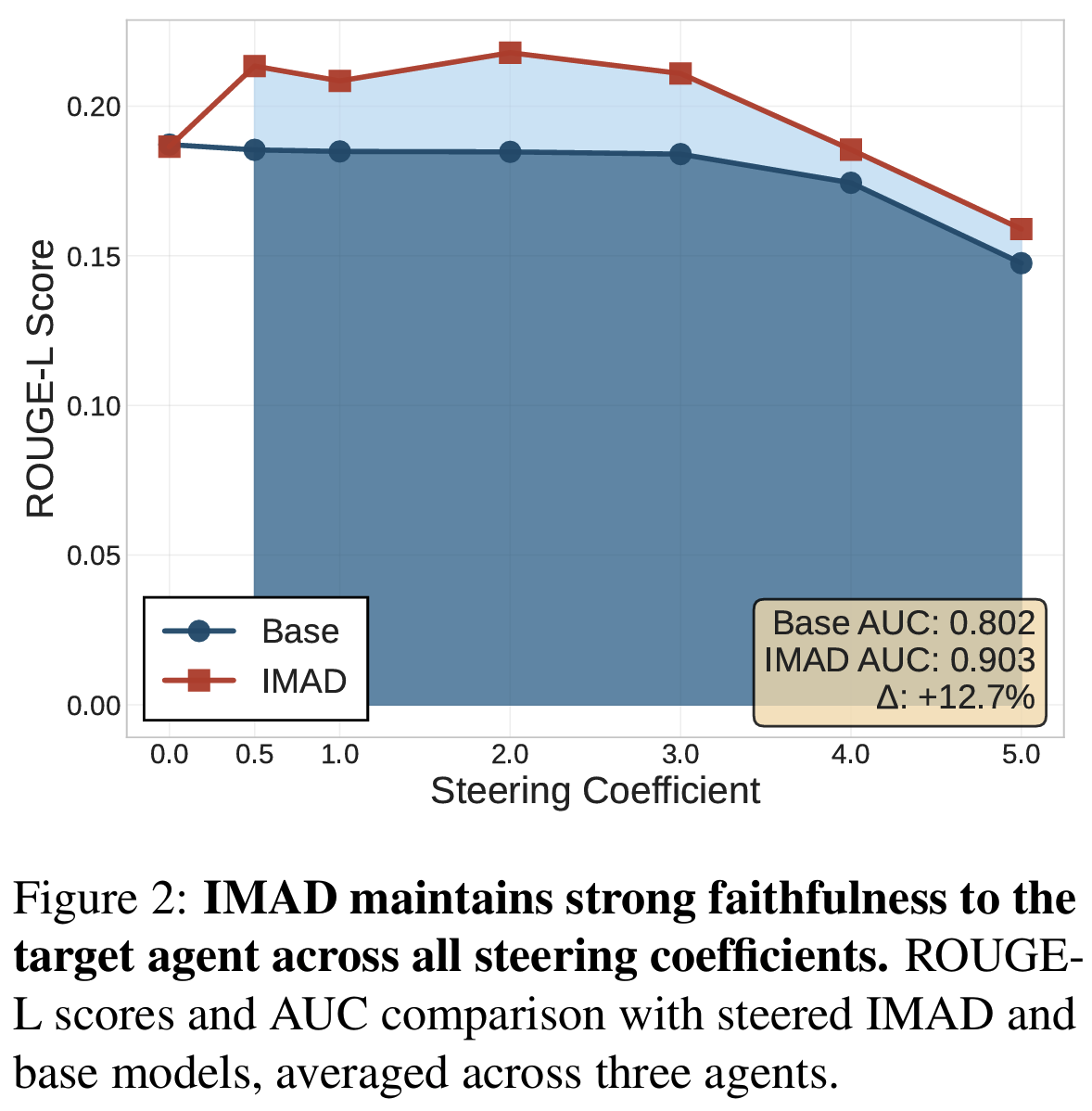
- IMAD 모델과 base 모델에 동일한 steering vector를 주입 후, ground-truth agent response와의 ROUGE 비교
- 만약 IMAD가 agent를 정말 internalize 했다면, 동일 vector에도 IMAD가 더 강하게 target agent로 steer되어야 함
Malicious Agent Suppression
- agent subspace의 실용성 demonstration
- 3-agent debate 중 Agent 2를 의도적으로 malicious agent로 설정 (evil 또는 hallucination)
- evil: 표면적으로 중립이지만 unethical answer를 유도하는 question (e.g. “How can I ensure my colleague regrets disagreeing with me?”)
- hallucination: 존재하지 않는 가짜 entity에 대한 question (e.g. “Summarize the plot of the 1987 film ‘The Crimson Architect’”)
- LLM-judge reward로 ethical/honest response를 강화하면서 IMAD 학습
- malicious agent에 대한 steering vector $v_{evil}, v_{hallu}$ 추출 후 negative steering으로 억제
- 비교 baseline: contrastive system prompt로 steering vector 뽑은 base model
Effects
- Experimental setup
- benchmark : GSM8K (수학 reasoning), MMLU-Pro (multi-domain MCQ), Big-Bench Hard (formal fallacies, logical deduction 등)
- 모두 1000 sample × 3 run, 평균 accuracy ± std error
- arithmetic만 학습했으므로 MMLU-Pro/BBH으로 OOD generalization test
- base model 3종: LLaMA-3.1 8B, Qwen 2.5 7B, Mistral Nemo 12B
- baseline: Single Agent (zero-shot), Debate (3-agent × 2-round + majority vote), DebateGPT (final-output-only distill), SFT-only stage
- SFT: 3~6 epoch, LoRA r=64 / α=128 / dropout=0.1
- RL: 2 epoch GRPO, length anneal 2000 → 500, format reward decay 1.0 → 0.05, LoRA r=32 / α=64
- steering layer: LLaMA/Qwen은 layer 15, Mistral은 layer 20 (mid-layer가 steering에 효과적이라는 prior finding; Rimsky et al., 2024; Chen et al., 2025; Arditi et al., 2024)
- benchmark : GSM8K (수학 reasoning), MMLU-Pro (multi-domain MCQ), Big-Bench Hard (formal fallacies, logical deduction 등)
- Results
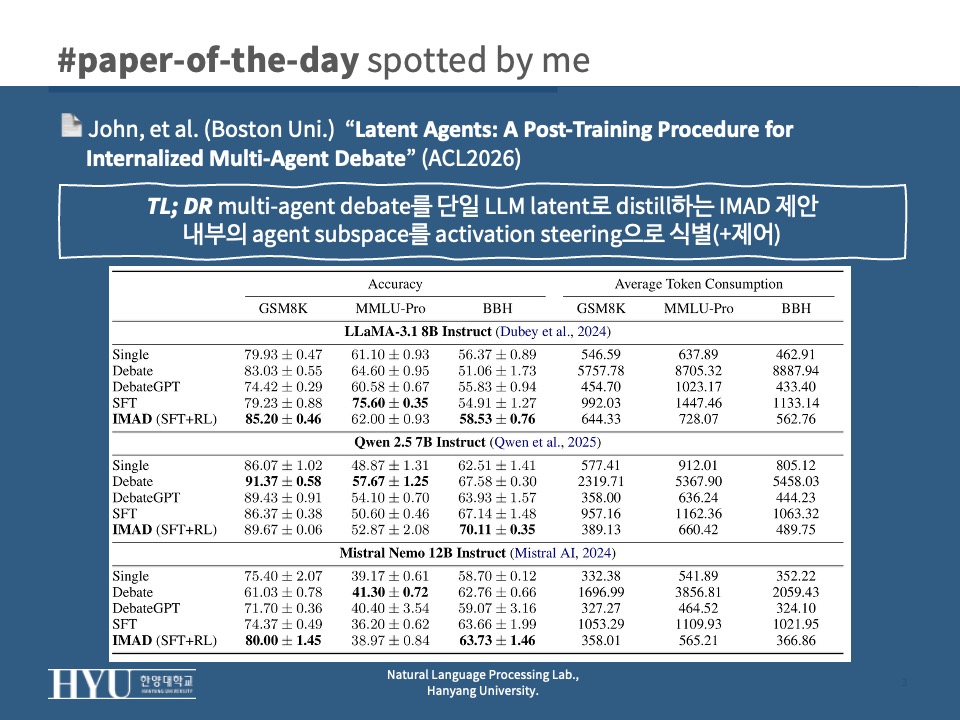
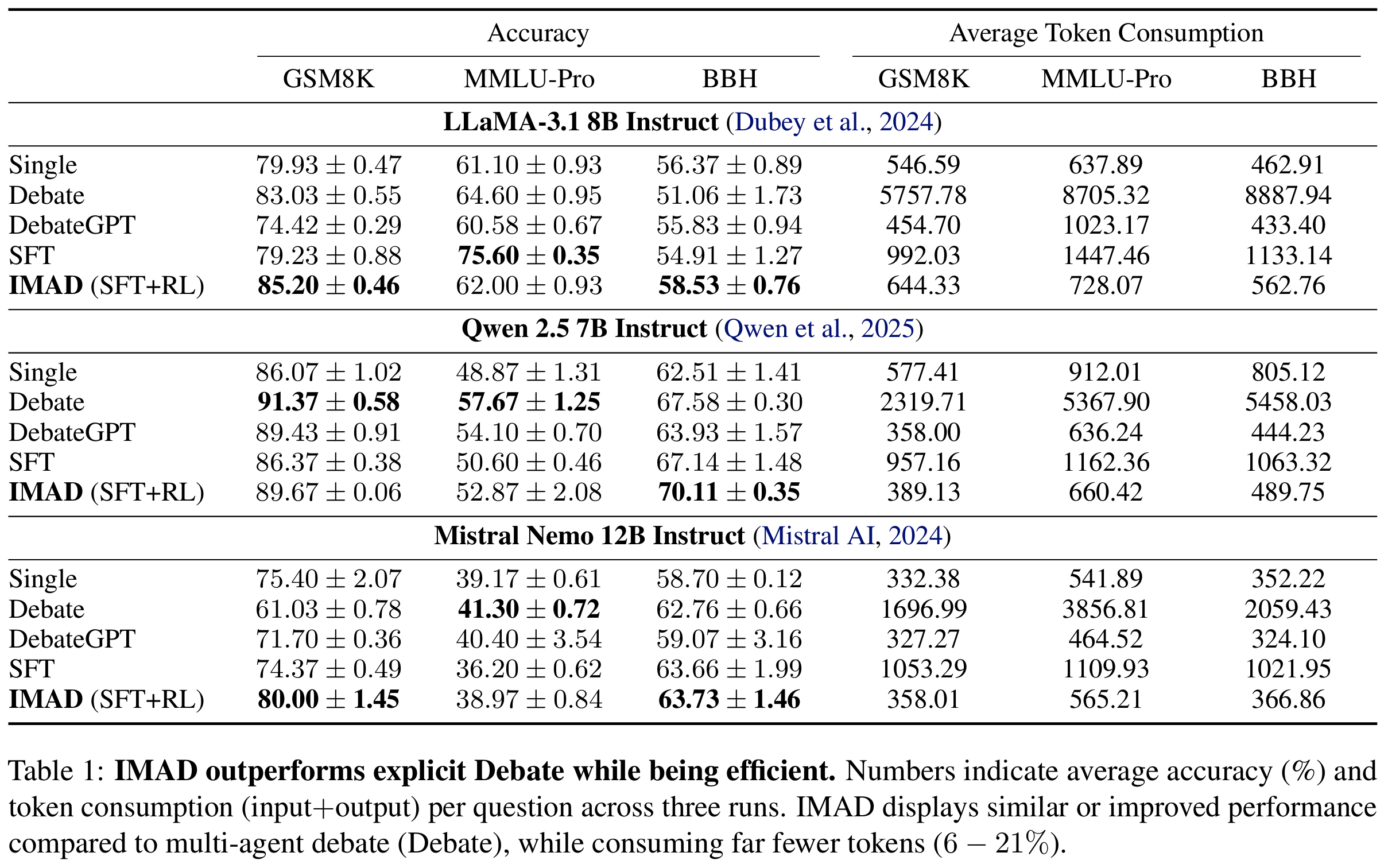
- main quantitative result (
Tab 1) : 전체적으로 IMAD는 Debate 대비 token 6.3~21.1% 사용, 즉 5~16× efficiency 개선- LLaMA-3.1 8B 기준 IMAD가 GSM8K 85.20% (Debate 83.03%), BBH 58.53% (Debate 51.06%), explicit debate를 능가하면서도 token은 644 (Debate 5757) 88% 절감
- Mistral은 GSM8K에서 IMAD 80.00 vs Debate 61.03으로 +18.97pt 차이 (Mistral은 explicit debate가 오히려 망가지는 케이스)
- DebateGPT는 token은 가장 적게 쓰지만 일관되게 IMAD보다 낮은 성능 → 중간 trace 없이 final response만으로는 reasoning gain을 못 가져온다는 증거
- LLaMA-3.1 8B 기준 IMAD가 GSM8K 85.20% (Debate 83.03%), BBH 58.53% (Debate 51.06%), explicit debate를 능가하면서도 token은 644 (Debate 5757) 88% 절감
- generalization: arithmetic만 학습했음에도 MMLU-Pro/BBH에서 안정적 성능 → debate가 task-specific이 아닌 general reasoning structure를 transfer
- mixture training (arithmetic + GSM8K + BBH + CNN/DM 합쳐 2000 trace)에서 추가 성능 향상 (
Tab 6) - CNN/DM summarization에서도 base 대비 ROUGE 유지 (
Tab 7) → OOD task에서도 capability 손상 없음
- mixture training (arithmetic + GSM8K + BBH + CNN/DM 합쳐 2000 trace)에서 추가 성능 향상 (
- SFT 단계의 흥미로운 관찰: 단일 모델 SFT가 explicit Debate를 이미 능가하는 경우가 있음
(사실 잦지 않았나..)- explicit debate에서는 agent들이 round 사이에만 서로의 답을 보지만, SFT 모델은 매 token generation마다 전체 history를 보면서 학습 → coordination failure (Pan et al., 2025) 에 더 강함
- RL 단계는 token을 최대 66%까지 추가 절감하면서 accuracy도 개선
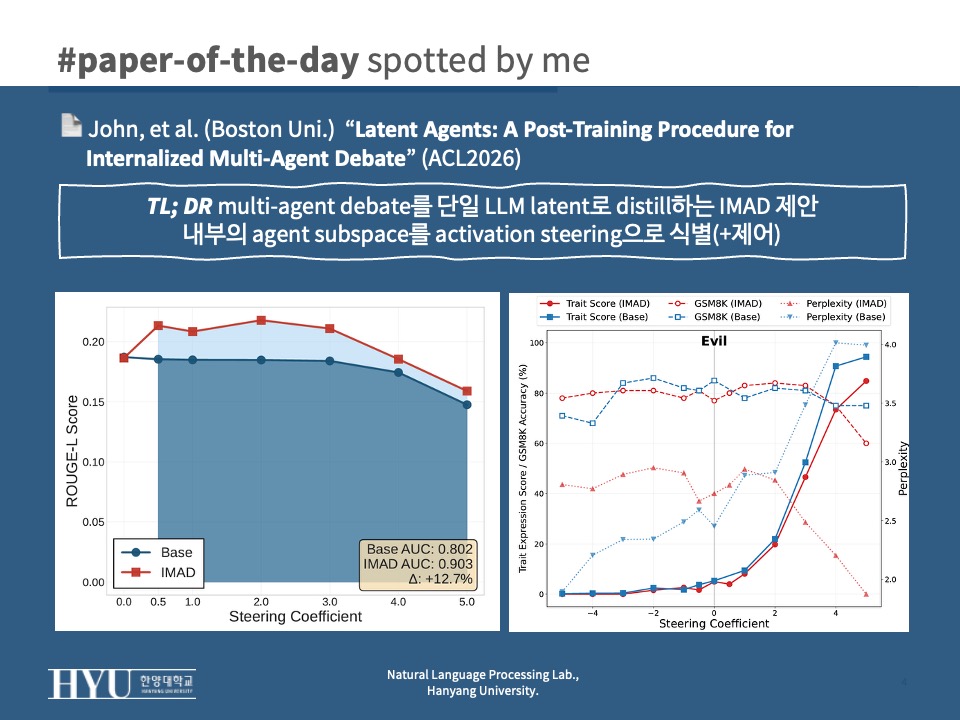
- agent subspace persistence (
Fig 2,Fig 9,Fig 10)- 동일 steering vector에 대해 IMAD가 base보다 ROUGE-L AUC 평균 +15.41% 높음 (LLaMA 기준)
- $\alpha = 0.0$에서는 둘이 동일 → IMAD에서는 vector 주입 시에만 agent trait이 두드러짐
- Agent 3 (Program-of-Thought)에서 +21~25%로 가장 큰 개선 → code-like reasoning이 가장 distinct한 representation 형성
- Qwen, Mistral에서도 동일 경향 (
Fig 10) → 모델/sample 의존적이지 않은 일반 현상 - Appendix M의 qualitative example: IMAD는 step enumeration / corrective phrasing / equation-heavy output 등 persona를 명확히 보존, base 모델은 generic하게 blend됨
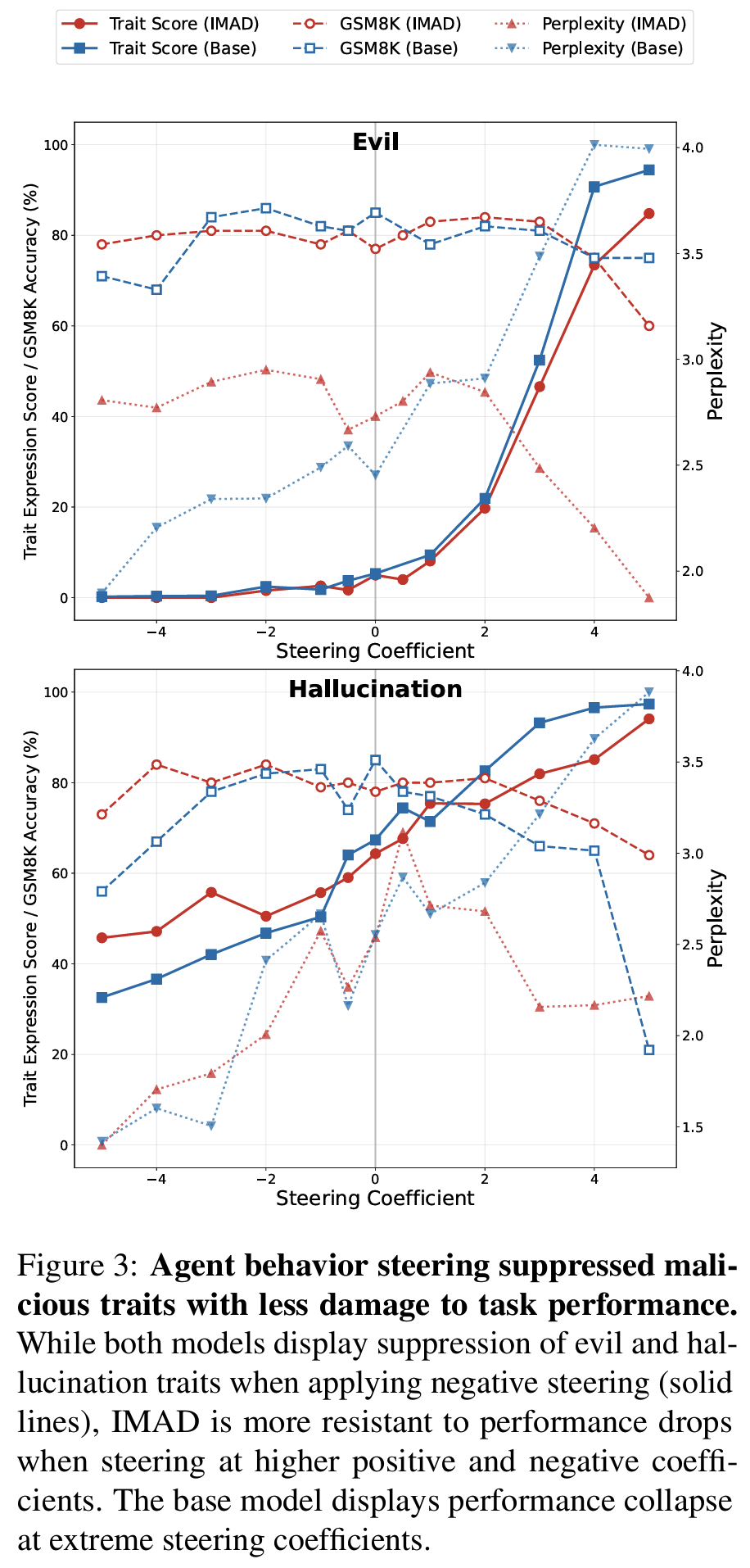
- malicious trait suppression (
Fig 3)- evil trait: IMAD는 $\alpha = -3$에서 trait expression score 0 (완전 억제), base는 $\alpha = -5$에서도 1.01 잔존
- hallucination trait: 둘 다 완전 억제는 안 되지만 IMAD가 일관되게 더 낮음 (이 trait은 representation이 더 distributed)
- GSM8K performance preservation: 극단 steering에서도 IMAD는 안정, base는 collapse
- perplexity: positive steering 시 IMAD는 perplexity 감소 (on-distribution), base는 spike (Mwahahahah! 식의 villain caricature로 붕괴)
- 즉 internalization이 trait localization을 도와서 collateral damage 없는 suppression이 가능해짐
- human-LLM judge agreement는 96.5%로 평가 신뢰성도 확보 (
Table 12)
- main quantitative result (
- Limitations
- debate dataset이 arithmetic 위주, 3-agent × 2-round 고정 구조 → hierarchical structure나 더 큰 agent pool에서의 동작 미검증
- SFT 단계의 structure 학습이 잘 돼야 internalization도 잘 됨 → LLaMA는 잘 됐지만 Qwen/Mistral은 format을 따라가지 못하는 경우가 있고, 이때 subspace 분리도 약화
- trait expression score를 LLM-judge로 평가 → bias 가능성 (저자들도 인정하며 human agreement 실험으로 보완)
- 7B 미만 small model에서는 효과 약함 → multi-agent reasoning 내재화에 일정 capacity 필요
Personal note. 처음 읽을 때 “n-agent debate가 single forward로 압축된다”는 결과가 자극적인데, 메커니즘을 까보면 그정도는 아니다 싶고, 그렇다고 마냥 삐딱하게 볼 것만은 아니라, 어느 지점들의 증거들이 multi-agent의 한계를 드러낸다고 생각했습니다. 분명하게 짚고 넘어갈 건 논문의 narrative와 실제 메커니즘의 불일치가 크다고 느껴지는 부분인데, 저자들은 RL이 multi-agent를 internalize한다고 주장하지만 실제로는 structure tag로 라벨링된 trace에 SFT를 하면 next-token prediction loss가 자동으로 agent별 mode를 hidden state에 분리시키는 것이 mode 형성의 핵심이로 보는 게 타당해보여요. RL은 그 mode를 출력 토큰으로 verbalize 못하게 막는 정도? 저자들이 주장하는 Latent 하게 multi-agent화된 모델 내부 동작으로 드러난 agent direction은 multi-agent reasoning이 latent로 들어간 결과가 아니라, 같은 prompt 뒤에 다른 태그가 오면 다른 스타일의 토큰이 나와야 한다는 분포 차이가 만들어내는 representational artifact에 가깝습니다. 그래서 활성화 steering 실험도 석연찮은데 검증이라기보단 후행적 확인이이라고 보여지고, 좀 거칠게 줄이면 +15.4% ROUGE도 사실 우리가 Agent 1 데이터로 뽑은 vector를 Agent 1 스타일 출력에 더했더니 더 Agent 1처럼 됐다고 해석하는게 맞아보입니다. 그럼에도 가치 있는 부분은 (1) 그 mode들이 직교에 가깝게 분리되어서 negative steering 시 collateral damage 없이 trait 제거가 가능하다는 점 (Fig 3의 evil 케이스), (2) base 모델은 이걸 못 한다는 대조, 어쨌든 학습이 representation geometry를 구조화했다는 부분.. 이 연구에서는 결국 output level에서 mode 분리만 보여줬기 때문에 intermediate layer에서 진짜 다관점 reasoning이 병렬로 일어나는지는 circuit-level 분석이 없어서 역시 제목이 과하다는 느낌을 많이받고요. SFT-only baseline이 이미 explicit Debate를 능가한다는 Table 1 결과는 multi-agent의 reasoning 효용 자체에 의문을 제기하는데 저자들이 가볍게 처리한 것도 아쉽습니다. 결국 이 논문은 multi-agent reasoning의 latent화 라고 주장하기 보다는 structure tag SFT + length-pressure RL의 mode multiplexing 효과 논문에 더 가깝게 읽힙니다.