Beyond Text-Dominance: Understanding Modality Preference of Omni-modal Large Language Models
- Authors: Xinru Yan, Boxi Cao, Yaojie Lu, Hongyu Lin, Weixiang Zhou, Le Sun, Xianpei Han
- Paper: https://arxiv.org/abs/2604.16902
- Code: https://github.com/icip-cas/OmniPreference
- Affiliation: University of Chinese Academy of Sciences / Chinese Information Processing Laboratory, Institute of Software, Chinese Academy of Sciences
- Published: April 18, 2026
TL; DR
OLLM은 기존 VLM의 text-dominance와 달리 vision을 선호하고 audio를 체계적으로 무시하며, 이 modality preference는 mid-to-late layer에서 emergent하게 형성되고, 이를 layer-wise linear probe로 추적해 cross-modal hallucination 진단까지 가능


Background
- multi-modal LLM이 pipeline 기반 vision-language model(VLM)에서 native omni-modal LLM(OLLM)으로 진화하는 중
- VLM 계열: LLaVA, BLIP-2, InternVL 등, vision encoder를 LLM에 붙이는 구조
- OLLM 계열: GPT-5, Gemini 3, Qwen2.5-Omni, MiniCPM-o, Ming-Omni, OmniVinci 등, text/image/audio/video를 modality-specific encoder로 받아 unified latent space에 정렬
- 핵심 차이: modality 통합이 pipeline 후처리가 아니라 native 표현 단계에서 이루어지도록
- modality preference: 입력 multi-modal 신호 사이에 implicit하게 weight가 불균등하게 부여되는 현상
- 기존 VLM에서는 일관되게 text-dominance가 보고
- 모델이 visual evidence를 무시하고 text cue에 과도하게 의존
- cross-modal hallucination(다른 modality 정보를 무시하고 선호 modality 기준으로 답변을 지어내는 현상)의 주요 원인 중 하나
- OLLM은 modality 자체가 더 많고 표현 공간도 통합되어 있어, 같은 결론이 적용될지 불분명
- 기존 modality preference 연구는 거의 image-text bi-modal에 한정
- audio를 포함한 tri-modal 환경에서 OLLM이 어떻게 행동하는지는 unexplored
- 기존 VLM에서는 일관되게 text-dominance가 보고
Problem States
- Research Questions
- RQ1: 서로 다른 OLLM의 modality preference를 어떻게 정량화할 수 있고, 어떤 패턴이 나타나는가?
- RQ2: OLLM 내부에서 modality preference는 어떤 메커니즘으로 형성되는가?
- RQ3: 이 mechanism에서 얻은 통찰을 downstream task의 신뢰성 향상에 어떻게 활용할 수 있는가?
- 핵심 challenge
- bi-modal conflict로는 audio를 포함한 OLLM의 진짜 선호 구조를 드러낼 수 없음
- preference가 layer 어디서 어떻게 emergent하는지 밝혀야 단순 행동 관찰을 넘어 mechanistic 설명 가능
- preference 신호가 hallucination과 실제로 인과적/예측적 관계를 갖는지 검증 필요
Suggestions
수식 정의 → tri-modal conflict framework → layer-wise probing → hallucination 진단 순으로 구성
Modality Preference Formulation
- 입력 query q가 세 modality 입력 ${m_{txt}, m_{vis}, m_{aud}}$로 구성되고, 임의의 두 modality $(m_i, m_j)$는 서로 모순되는 의미를 담음
- 세 modality가 서로 다른 정답을 가리킴 → 모델 출력이 정확히 하나의 modality와 정렬됨
-
modality $m_i$에 대한 선호는 conditional probability로 정의
\[P\left(\hat{y} \sim m_i \mid \text{conflict}(m_{txt}, m_{vis}, m_{aud})\right)\]- 값이 클수록 conflict 상황에서 modality $m_i$에 의존하는 경향이 강함
Modality Selection Rate (MSR)
-
preference를 측정하는 primary metric
\[\text{MSR}(m) = \frac{1}{N} \sum_{i=1}^{N} \mathbb{1}[\hat{y}_i = \text{opt}(m)]\]- opt(m): modality m에 대응되는 candidate option
- $\hat{y}_i$: i번째 sample에서 모델 선택
-
$ M $ modality conflict에서 uniform baseline은 1/ M ; MSR(m) > 1/ M 이면 m을 선호
Tri-Modal Conflict Dataset (RQ1)
- XModBench Perception subset에서 시작
- 각 sample은 의미적으로 일치하는 $(x^T, x^I, x^A)$ triplet (text/image/audio) ; 같은 ground-truth label
- 6개 semantic category로 묶음: Animals, Human Activities, Musical Instruments/Music, Home Appliances/Machinery, Vehicles/Traffic, Nature/Environmental Sounds
- conflict 구성: $(x_i^T, x_j^I, x_k^A)$에서 $c_i \neq c_j \neq c_k$가 되도록 서로 다른 category에서 sampling
- 6 choose 3 = 20개 valid triplet 모두 enumerate, balanced sampling
- text는 ground-truth label을 fixed template으로 자연어 statement화(e.g.”bird squawking” → “the bird is squawking”)
- 질문은 modality-agnostic하게 고정: “Which option best describes what this example is mainly about?”
- 3개 후보 option(=각 modality category) randomized order로 제시 → 모델이 어느 modality에 가장 큰 weight를 두었는지가 직접 드러남
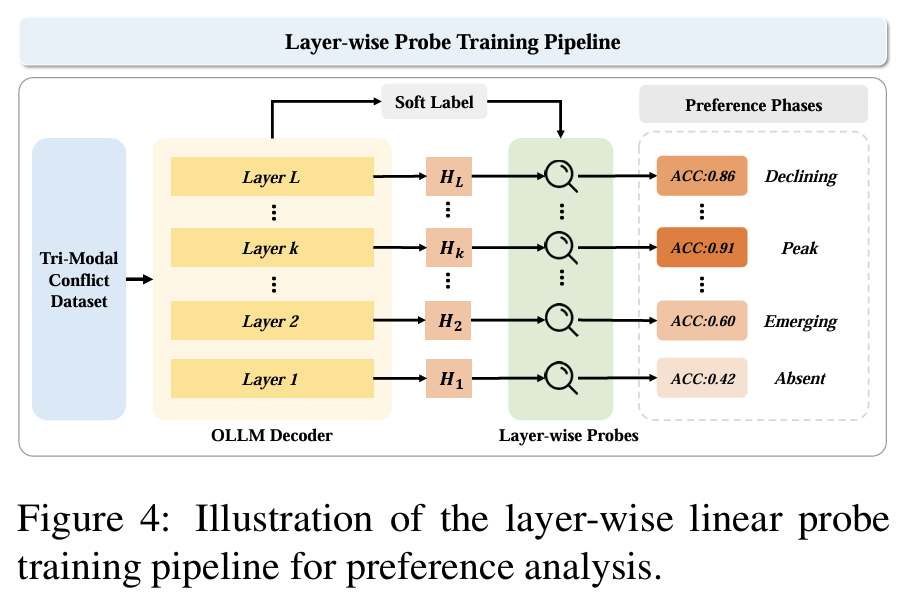
Layer-wise Probing (RQ2)
- decoder layer ℓ별로 single-layer MLP linear probe를 학습해서 modality preference 정보가 어떻게 진화하는지 추적
- input sample i에 대해 layer ℓ의 hidden state $h_i^{(\ell)} \in \mathbb{R}^d$를 last token position에서 추출
- decoder-only causal attention이라 last token에 전체 context가 집약됨
-
L2 normalization으로 magnitude 영향 제거
\[\tilde{h}_i^{(\ell)} = h_i^{(\ell)} / \|h_i^{(\ell)}\|_2\] - soft label 구성: 모델 final prompt token의 full-vocab softmax에서 3개 option token에 해당하는 확률만 뽑아 3차원 벡터 $y_i \in \mathbb{R}^C$ ; 단순 hard label보다 풍부한 supervisory signal (Hinton-style distillation 아이디어)
-
probe 출력 및 loss
\[\hat{y}_i^{(\ell)} = \text{softmax}(\theta^{(\ell)\top} \tilde{h}_i^{(\ell)} + b^{(\ell)})\] \[\mathcal{J}(\theta^{(\ell)}) = -\frac{1}{n} \sum_{i=1}^{n} \sum_{c=1}^{C} y_{i,c} \log \hat{y}_{i,c}^{(\ell)}\] - 학습 details: 3,000 sample (modality category별 1,000), 8:1:1 split, 200 epoch, Adam lr=1e-3, batch=256
Fig 4학습 pipeline 시각화: Tri-Modal Conflict Dataset → 각 layer hidden state → layer별 probe → accuracy 측정 → preference phase 분석으로 이어짐
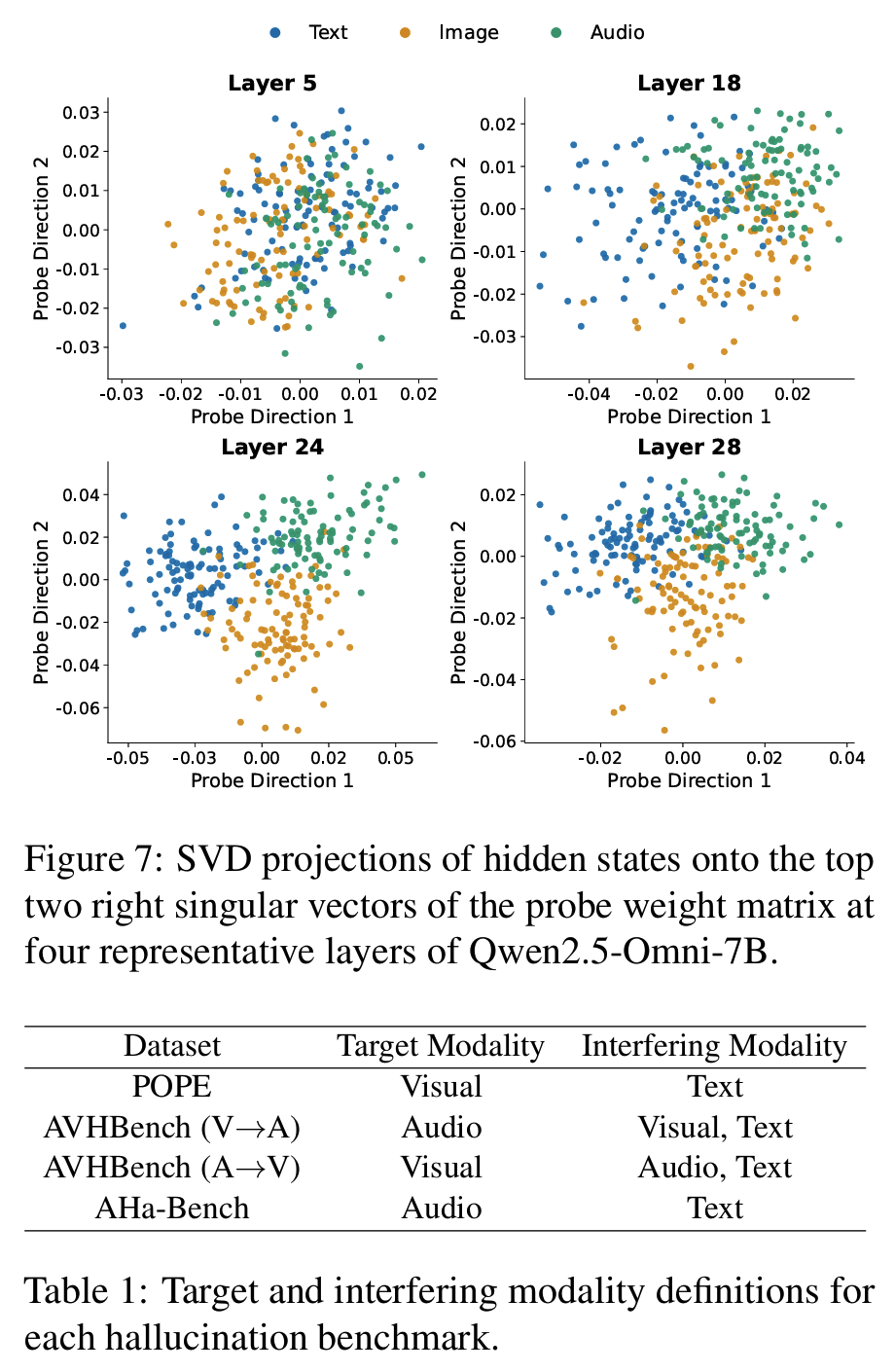
4-Phase Decomposition
- preference emergence를 4 phase로 정량 정의
- Absent: probe accuracy가 chance level ; preference 신호 미형성
- Emerging: accuracy 급격 상승 시작
- onset point 정의: 첫 40% layer의 layer-wise accuracy diff에서 median + 3·MAD를 threshold로 잡고, 이 threshold를 처음 넘는 layer
- Peak: accuracy가 max의 95% 이상 ; preference가 가장 뚜렷
- Declining: peak에서 2% 이상 떨어지면서 최소 두 layer 연속 감소
Hallucination 진단 (RQ3)
- modality preference probe를 hallucination detector로 사용
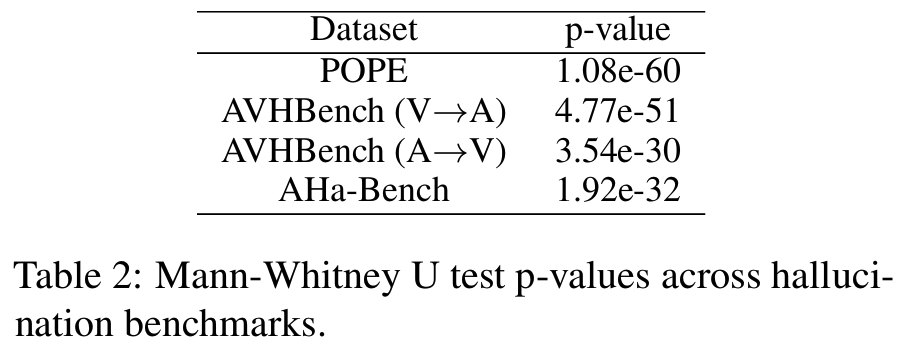
- 각 benchmark에서 target modality(정답을 위해 봐야 할 modality)와 interfering modality(모델을 속일 수 있는 modality)를 정의
- 가장 preference 신호가 강한 layer의 probe로 interfering modality 확률을 계산해서 hallucination risk score로 사용
- evaluation set은 정답이 “no”인 sample만 사용 → 모델이 “yes”라고 답하면 hallucination
- LLM의 affirmative bias 회피용으로 yes/no 질문을 binary multiple-choice로 변환, option 순서도 무작위화 (position bias 회피)
Effects
- Experimental setup
- OLLM: open-source 6종 (Qwen3-Omni-30B-A3B-Instruct, Qwen2.5-Omni-3B/7B, Ming-Lite-Omni 1.5, MiniCPM-o 2.6, OmniVinci) + closed-source 4종 (Gemini 2.5 Flash/Pro, Gemini 3 Flash, Gemini 3.1 Pro)
- inference: open-source는 T=0, closed는 official API default
- audio는 16kHz mono로 resample
- tri-modal conflict 1,000 sample 평가, bi-modal은 text+image / image+audio / text+audio 3가지
- hallucination benchmark: POPE (image-text), AVHBench V→A 및 A→V (audio-visual), AHa-Bench (audio-text)
- 비교 baseline: Random / Early Probe (Layer 1 probe)
- metric: MSR (preference), AUROC / AUPRC / Optimal F1 (hallucination detection)
- Results
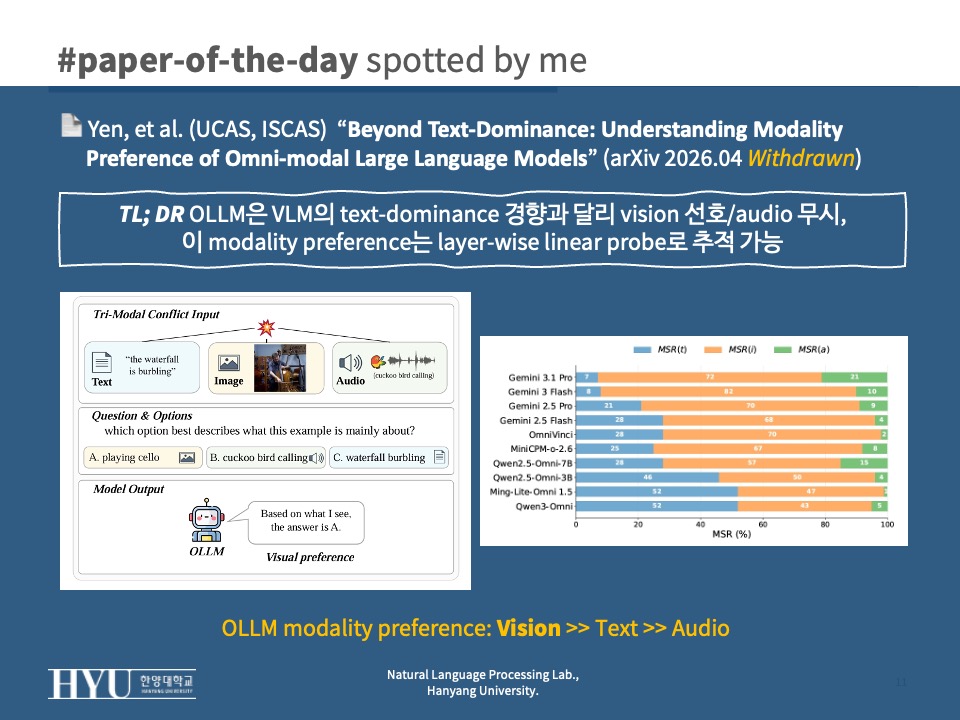
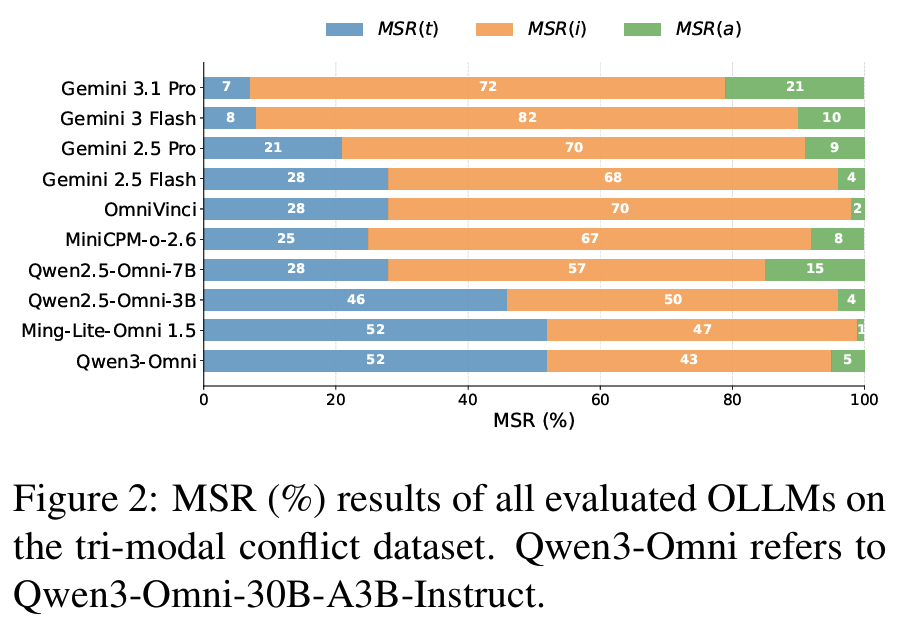
- Finding 1: Vision preference + Audio neglect
Fig 2,Fig 3- tri-modal conflict에서 10개 OLLM 중 8개가 image MSR > 50%, Gemini 3 Flash는 82%까지
- Gemini 3.1 Pro는 visual MSR 72%, text MSR은 7%에 불과
- audio MSR은 모든 모델에서 21% 이하, 대부분 10% 이하 ; Ming-Lite-Omni 1.5는 audio MSR 1%
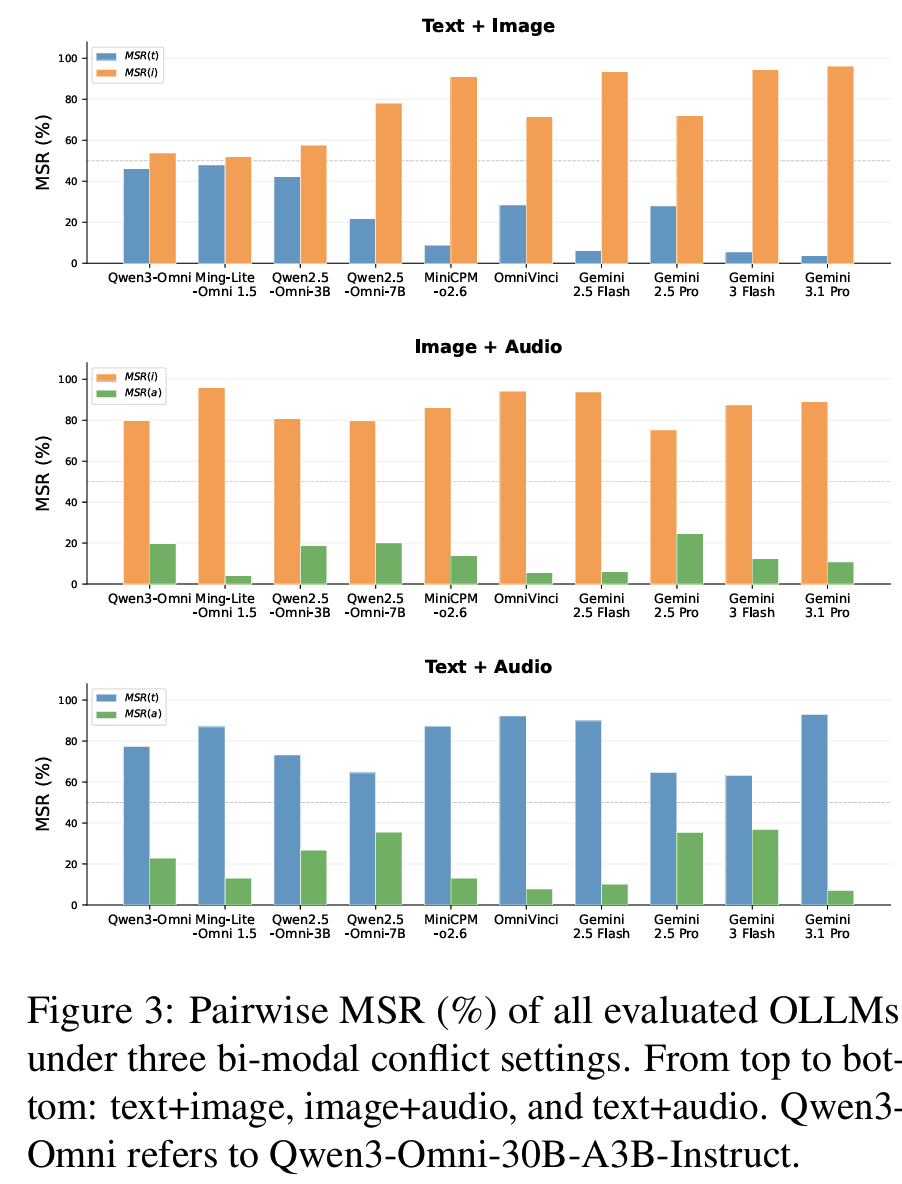
- bi-modal에서도 일관: text+image / image+audio에서는 image, text+audio에서는 text가 일관되게 우세
- 즉 OLLM은 omni-modal design에도 불구하고 균형 잡힌 통합에 도달하지 못함
- Finding 2: Mid-to-late layer에서 emergent
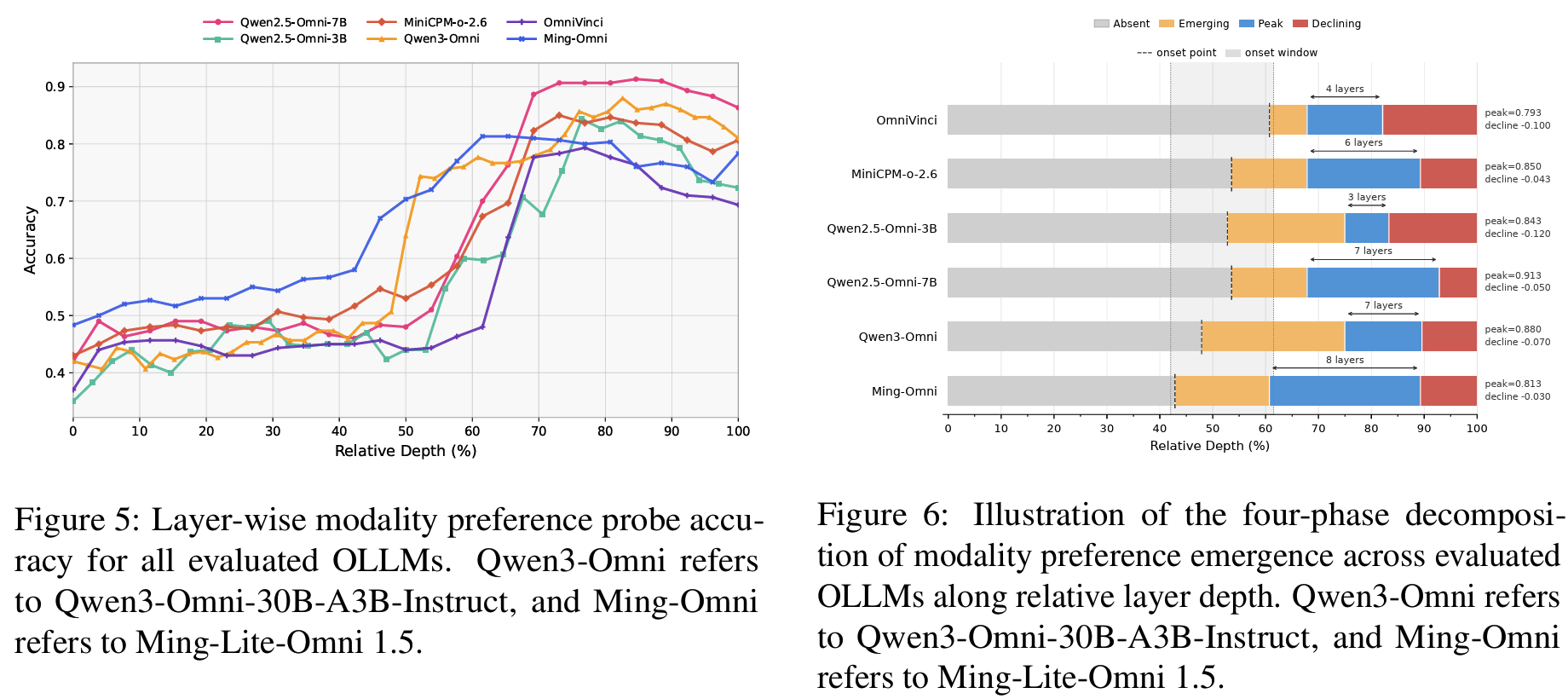
Fig 5,Fig 6- 첫 30% layer까지 probe accuracy ~0.30–0.55 (chance level) → preference 신호 부재
- 40–70% depth 구간에서 모든 모델 accuracy가 급상승: Qwen2.5-Omni-7B는 0.50→0.90, MiniCPM-o-2.6은 0.50→0.80
- 80% 이후 일부 declining (final layer가 task-specific output distribution에 압축되며 modality 신호 attenuate ; 기존 layer-wise representation 연구와 일관)
- 모델 크기 효과: Qwen3-Omni-30B/Ming-Lite-Omni 1.5처럼 큰 모델은 onset이 더 얕은 relative depth에서 발생하고 declining도 완만(−0.030 정도), Qwen2.5-Omni-3B 같은 작은 모델은 declining이 −0.120로 가파름
- Representation-level 분석
Fig 7- Qwen2.5-Omni-7B의 probe weight matrix를 SVD해서 hidden state를 top 2 right singular vector에 projection
- Layer 5: 세 modality가 완전히 섞여 cluster 구분 불가
- Layer 18: 부분적 분리, overlap 많음
- Layer 24: 가장 명확하게 3개 cluster 분리
- Layer 28: 다시 cluster 경계가 흐려짐 ; declining phase와 일관
- Finding 3: Hallucination 진단 효과
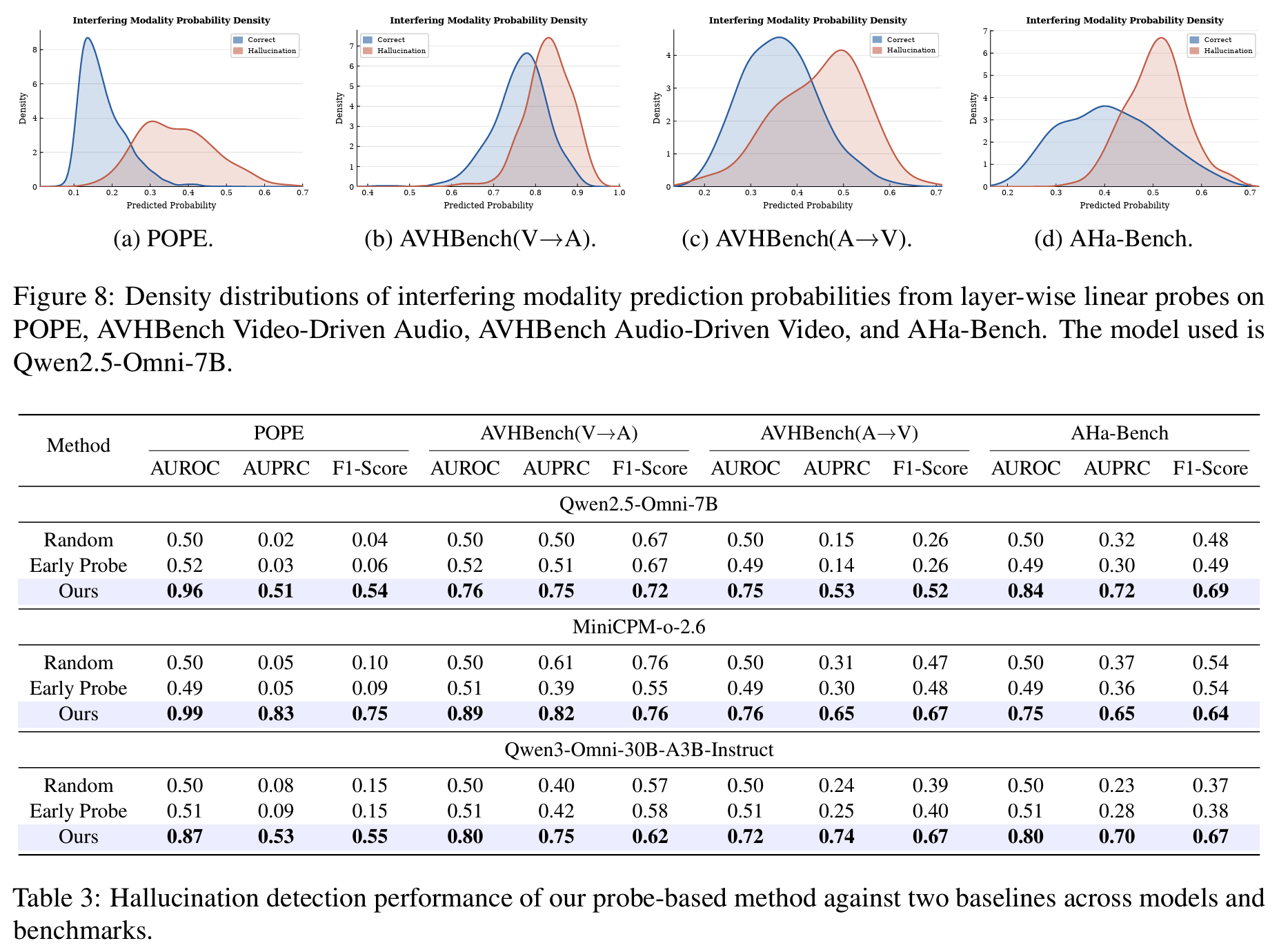
Fig 8,Fig 9,Table 3- hallucination 발생 시 interfering modality 확률 분포가 correct sample 대비 유의미하게 high value쪽으로 shift
- Mann-Whitney U test p-value: POPE 1.08e-60, AVHBench(V→A) 4.77e-51, AVHBench(A→V) 3.54e-30, AHa-Bench 1.92e-32 → 모두 매우 유의
- probe-based detection 성능 (
Table 3):- POPE 평균 AUROC 0.94 (random/early probe ~0.50)
- Qwen2.5-Omni-7B에서 POPE AUROC 0.96 / AUPRC 0.51 / F1 0.54
- MiniCPM-o-2.6는 POPE AUROC 0.99 / AUPRC 0.83 / F1 0.75
- AVHBench는 AUROC 0.72 이상, AHa-Bench는 0.75–0.84
- case study (
Fig 9): POPE에서 visual(target) 0.81 → 0.21로 떨어지고 동시에 text(interfering) 0.17 → 0.76으로 급등하면 정확히 hallucination이 발생; AVHBench V→A에서도 audio(target)이 0.61→0.32로 떨어지면 두 interfering modality 합산이 target을 초과 - task-specific data 없이 frozen probe만으로 hallucination detector로 작동한다는 점이 핵심
- Finding 1: Vision preference + Audio neglect
Personal note. modality gap 관련해서 살펴보면서, 기존 VLM에서 text-dominance가 워낙 잘 알려져 있어서 OLLM도 그럴 거라고 막연히 생각했는데, vision으로 무게중심이 통째로 옮겨갔다는 결과. 흠.. 확실한건 audio MSR이 한 자릿수까지 떨어지는 걸 보면 omni라는 이름값을 의심해야 할 정도인데, 이건 사전학습 corpus 비율과 alignment objective의 비대칭에서 기인하는 구조적 문제일 가능성이 다분하고, layer-wise probing에서 mid-to-late layer 40–70%에서 preference가 abrupt하게 emergent한다는 관찰은, mechanistic interpretability 관점에서 modality routing이 specific representation stage에 localize되어 있다고도 보여집니다. 아무튼 마저 확인해볼 여지는 있어보이네요… 제가 하고자 했던 연구 질문 일부를 커버하는듯 하기도 하고 비워진 부분도 여전히 있고.. 오히려 논문의 실험 setup은 의도적으로 task-neutral하게 짜여진 게 제가 하려던 과제를 바꿔두는 것보다 타당하다고 느껴지기도 하네요. 또 지금 생각해보니 이 페이퍼처럼 layerwise 하게 분석해보는게 의미는 있는게 맞는데 그렇게 되면 출력 모달리티를 변경하게 될 경우 음성출력이나 이미지 출력에 대해서 텍스트와 같은 층위로 분석이 가능한건지도 잘 모르겠습니다. 흠.. 지금 이 페이퍼는 arxiv에서 withdraw 되어있습니다.