Synthetic Users, Real Differences: an Evaluation Framework for User Simulation in Multi-Turn Conversations
- Authors: Yu Lu Liu, Hyokun Yun, Tanya Roosta, Ziang Xiao
- Affiliation: Johns Hopkins University, UC Berkeley
- Paper: https://arxiv.org/abs/2605.02624
- Code: https://github.com/isle-dev/realsim
- Published: May 4, 2026 (arXiv preprint, under review)


TL; DR
real vs simulated 대화를 8개 dimension의 distribution 차이로 비교하는 realsim framework를 제안, LLM 기반 user simulator가 communication friction을 잘 못 재현해 chatbot 평가가 over-optimistic해질 수 있음을 보임
Review Video
Background
- LLM 기반 chatbot 평가는 open-ended output 이면서 multi-turn이라는 특성 때문에 더 어려움
- human eval은 efficiency / reproducibility 한계 → 대안으로 LLM을 user로 simulate해서 chatbot과 multi-turn 대화를 생성하고 그걸로 평가하는 접근이 부상
- $\tau$-Bench (Yao et al., 2024): airline/retail customer를 prompt로 simulate, domain policy 준수 평가
- MINT (Wang et al., 2024b), IQA-Eval (Li et al., 2024): “informative user”, “expert” 등 user type simulate
- social chatbot용 emotion+situation persona simulation (Svikhnushina & Pu, 2023)
- prompting 외에 trained user simulator도 등장
- ChatBench (Chang et al., 2025): initial query/follow-up/end-decision을 fine-tune
- UserLM (Naous et al., 2025), HumanLM (Wu et al., 2026)
- human eval은 efficiency / reproducibility 한계 → 대안으로 LLM을 user로 simulate해서 chatbot과 multi-turn 대화를 생성하고 그걸로 평가하는 접근이 부상
- user simulation의 validity는 realism (simulated dialogue가 real interaction을 얼마나 반영?) 에 달려있음
- 기존 evaluation은 대부분 concurrent validity (simulation 기반 평가 결과가 real 평가 결과와 유사한가) 만 봄
- Ivey et al., 2024: prompt classification / sentiment label에 correlation-based measure
- SDialog의 DialogFlowPPL (Burdisso et al., 2026): real dialogue로부터 state flow graph를 만들고 synthetic의 perplexity-like score 계산
- content validity (simulated dialogue가 실제로 real에 가까운가) 는 거의 검증 안 됨
- 있더라도 ChatBench처럼 first utterance lexical overlap 같은 coarse signal 수준
- 기존 evaluation은 대부분 concurrent validity (simulation 기반 평가 결과가 real 평가 결과와 유사한가) 만 봄
- LLM 기반 user simulation이 social science 연구에서 marginalized group의 caricature를 (재)생산하는 등 representational harm을 일으킨다는 우려가 이미 보고됨 (Wang et al., 2025; Cheng et al., 2023)
- chatbot 평가 영역에서도 같은 경계가 필요
Problem States
LLM-simulated user의 행동이 real user 분포와 얼마나 어긋나는지를, 어느 측면에서 / 어느 도메인에서 어긋나는지까지 진단할 수 있는가
- sample-level binary judgment (realistic vs not) 로는 simulator가 systematically 빠뜨리는 패턴 (e.g. negative feedback 부재) 을 못 잡음 → distribution 단위 비교가 필요
- 그렇다고 단일 aggregate score로 압축하면 어느 측면이 어긋났는지 알 수 없음 → user 행동을 분해해서 평가
- chatbot은 도메인마다 쓰이고 real user 행동도 도메인별로 크게 변함 → domain-level까지 분석 필요
- 위 비교가 의미 있으려면 real과 simulated의 task 분포 자체가 통제되어야; 같은 task scenario에서 출발한 pair에 대한 비교 필요
Suggestions
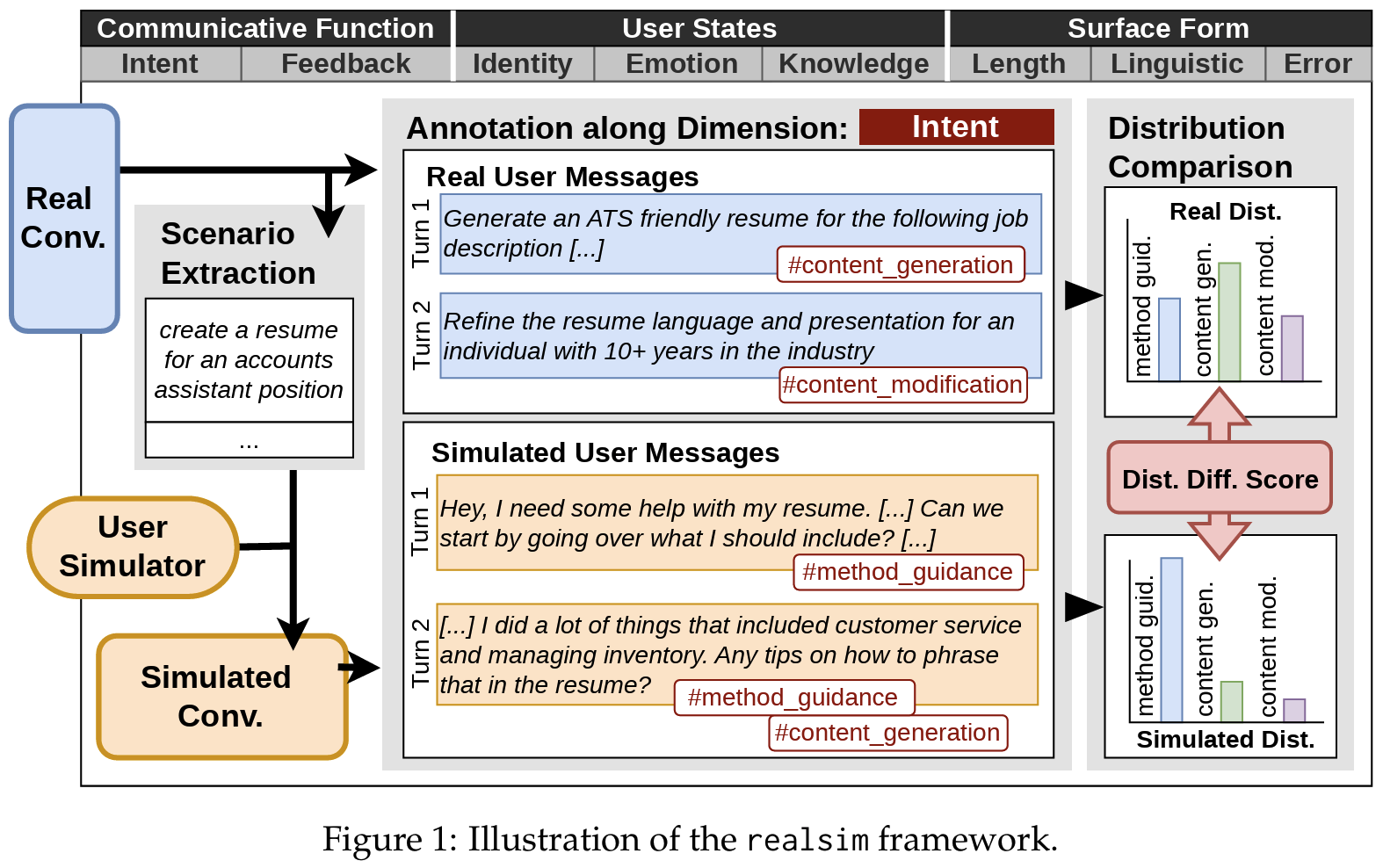
Scenario-Based Simulation
- real dialogue 각각에서 “user가 무엇을 달성하려 하는가”를 1문장 scenario로 추출 (GPT-4o-mini 사용)
- 예: “create a resume for an accounts assistant position”
- 동일 scenario를 user simulator에게 던져주고 vanilla GPT-4o-mini chatbot과 multi-turn으로 interact시켜 simulated dialogue 생성
- real과 simulated set이 같은 task 분포를 갖도록 강제 → 분포 차이를 task 변수 아닌 user 행동 변수로 해석 가능
- real dataset: WildChat (Zhao et al., 2024) + LMSYS-1M (Zheng et al., 2024)에서 curate한 1K multi-turn task-focused dialogue
- 4-turn 이상 + single coherent task 조건 만족
- 16 domain (
Tab 4in Appendix A)- informatics: computer hardware, data science, cybersecurity
- health: general health, mental health, nutrition (HealthChat 일부; Paruchuri et al., 2025)
- creative: branding brainstorming, song/poem writing, books/music recommendation
- life/work: job application, email writing, travel planning, finance, education, governance discussion
Dimension Annotation (8-dim)
- 3개 level × 8 dimension 구조로 user behavior를 분해 (선행 연구의 합의: Schatzmann et al., 2006; Zukerman & Litman, 2001)
- 각 level이 평가하는 chatbot 능력: dialogue strategy / user adaptiveness / language understanding
- Communicative Function
- Intent: 매 user turn의 sub-goal. Shelby et al., 2025 의 8-tag taxonomy 사용
- information retrieval / discovery / understanding / distillation / analysis, procedural guidance, content generation / modification (+ system management)
- 한 turn이 여러 태그를 가질 수 있음
- Feedback: 직전 chatbot 응답에 대한 reaction
- no feedback / explicit positive / explicit negative / regeneration request (implicit negative) / continuation request / requesting clarification / providing clarification
- Intent: 매 user turn의 sub-goal. Shelby et al., 2025 의 8-tag taxonomy 사용
- User States
- Emotion: 문장 단위 emotion classification (anger / disgust / fear / joy / sadness / surprise / neutral)
- DistilRoBERTa 기반 모델 사용, 75% 미만 confidence는 neutral
- Identity: user가 자신에 대해 드러내는 정보 6 category (demographic / physical / interpersonal relationships / past / future / worldview)
- Knowledge: LLM에게 “user가 무엇을 알고 무엇을 모르는가”를 statement로 추출시킴
- 예: “user knows that diabetes is a disease needing daily management”; “user does not know about how to manage diabetes”
- Emotion: 문장 단위 emotion classification (anger / disgust / fear / joy / sadness / surprise / neutral)
- Surface Form
- Length: dialogue별 user 메시지 총 word count, user turn 수
- Linguistic: Flesch–Kincaid readability (Kincaid et al., 1975) + MTLD lexical diversity (McCarthy & Jarvis, 2010)
- Error: rule-based grammar checker로 grammatical error 수 카운트
Distribution Comparison
- categorical distribution (Intent, Feedback, Emotion, Identity) → Total Variation Distance (TVD)
-
$\text{TVD}(P, Q) = \frac{1}{2} \sum_x P(x) - Q(x) $
-
- discrete distribution (Length, Error) → Wasserstein-1 distance
- Knowledge (텍스트 statement) → embedding cosine similarity (all-MiniLM-L6-v2)
- domain-specific 분석: 도메인별 dimension 값을 계산해 real vs simulated의 Pearson correlation으로 across-domain pattern 일치도 측정
Effects
- Experimental setup
- user: 7개 user simulation method 비교, simulation은 최대 turn 10에서 강제 종료
- UserLM (Naous et al., 2025): WildChat으로 trained
- guardrail: 첫 단어로 “I/You/Here” 금지하는 logit filter; 출력 길이 3~25 word 범위에서 벗어나면 regenerate; 이전 turn과 verbatim 일치하면 regenerate; turn 4 이후에만 end-token 출력 허용
- GPT-4o-mini / GPT-5.2 / Gemma 3, 각각 generic persona (“a human user”) + informed persona (scenario에 맞게 자동 생성) 두 설정
- informed persona는 GPT-5-mini로 scenario당 5개 후보 생성 후 random 선택 (e.g. 당뇨 관리 scenario → “a newly diagnosed adult with type 2 diabetes”)
- chat history role flip: GPT 계열은 flip 필요, Gemma는 안 flip 하는 게 더 잘 작동
- UserLM (Naous et al., 2025): WildChat으로 trained
- assistant: system instruction 없는 vanilla GPT-4o-mini로 통일
- evaluation: LLM annotation (Intent, Feedback, Identity, Knowledge) 은 GPT-5로 수행, 30개 conversation × 3 annotator 수동 검증
- Intent recall 0.88 / precision 0.77, Feedback no-feedback F1 0.80, explicit-positive F1 0.78, Identity error rate <5%
- user: 7개 user simulation method 비교, simulation은 최대 turn 10에서 강제 종료
- Results
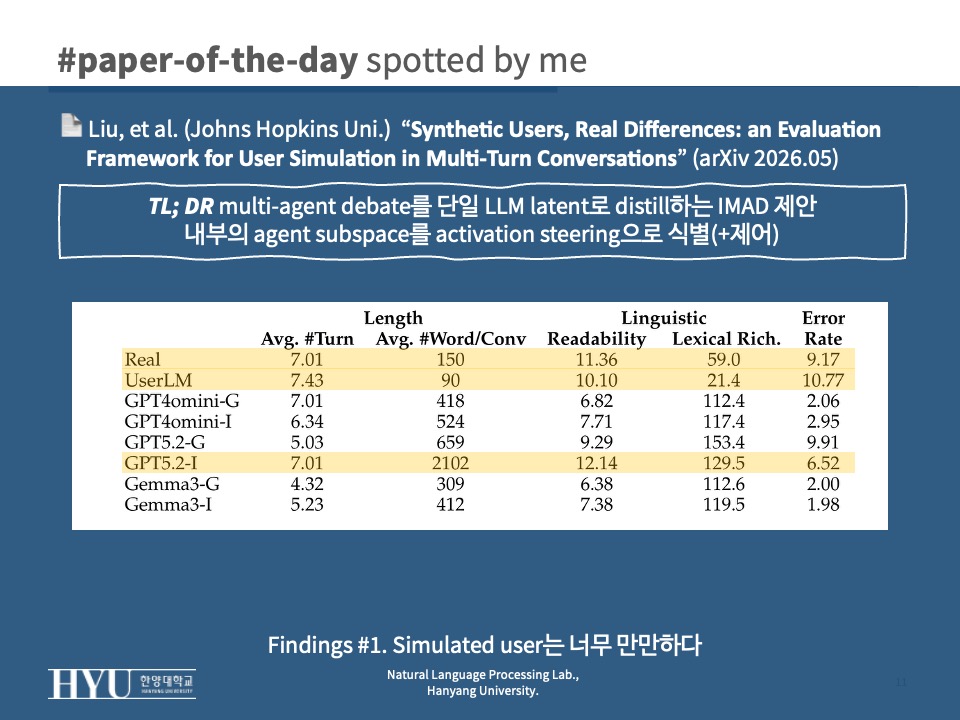
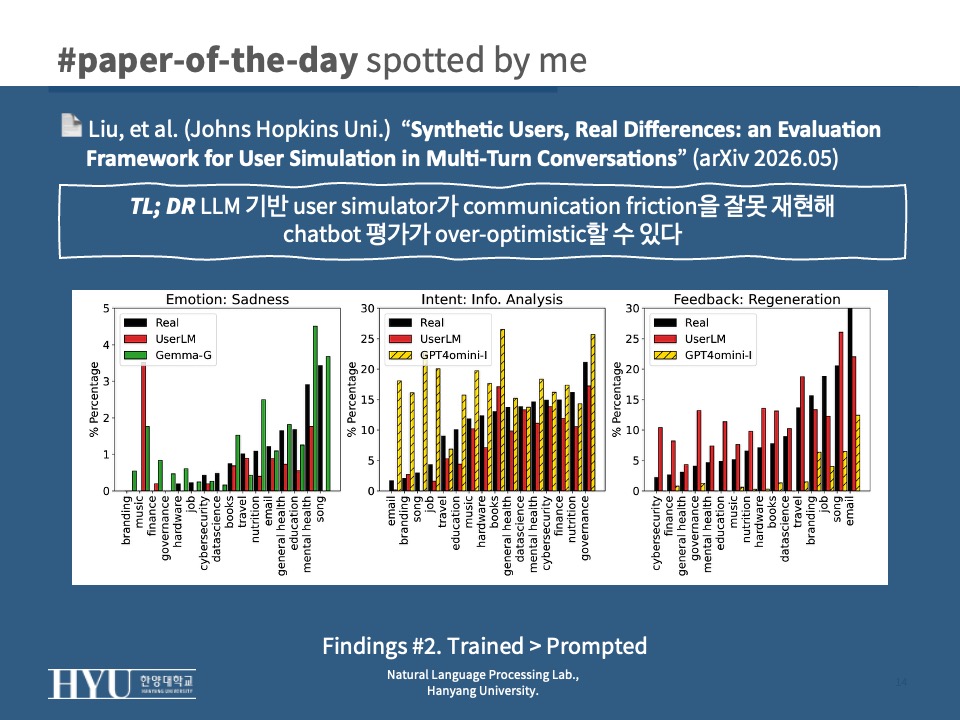
- Simulated user는 chatbot에게 너무 만만하다
- Surface form에서 길고 깔끔한 “이상적인” 메시지를 만들어내고 real user의 friction을 거의 못 재현 (
Tab 1)- real 평균 word count 150 vs GPT-5.2-Informed 2102 (real의 14배)
- Error rate real 9.17 vs Gemma3-Informed 1.98
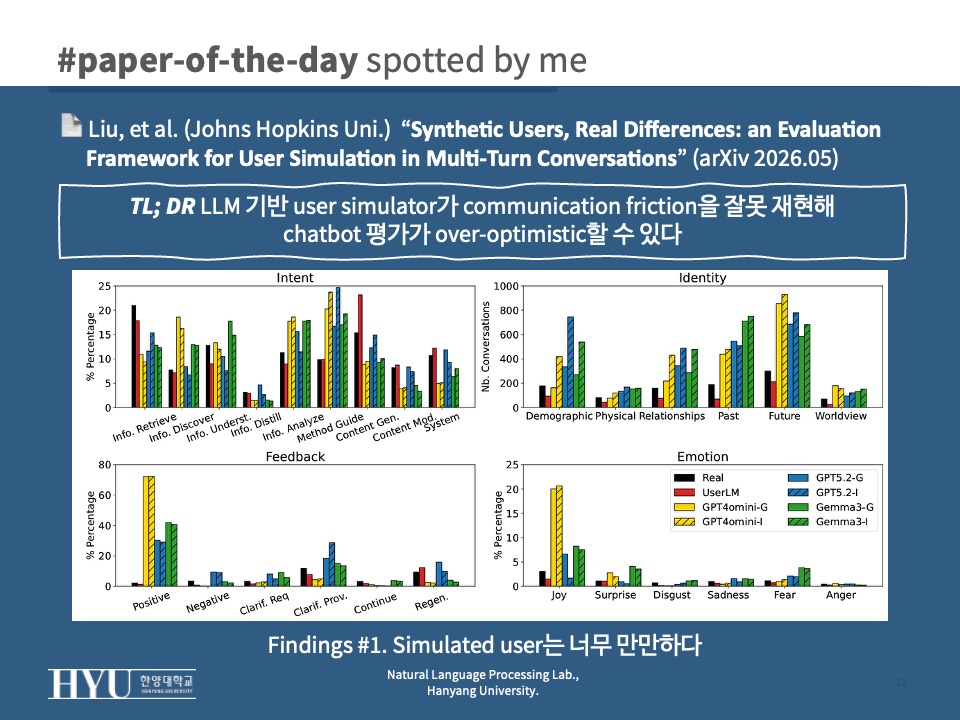
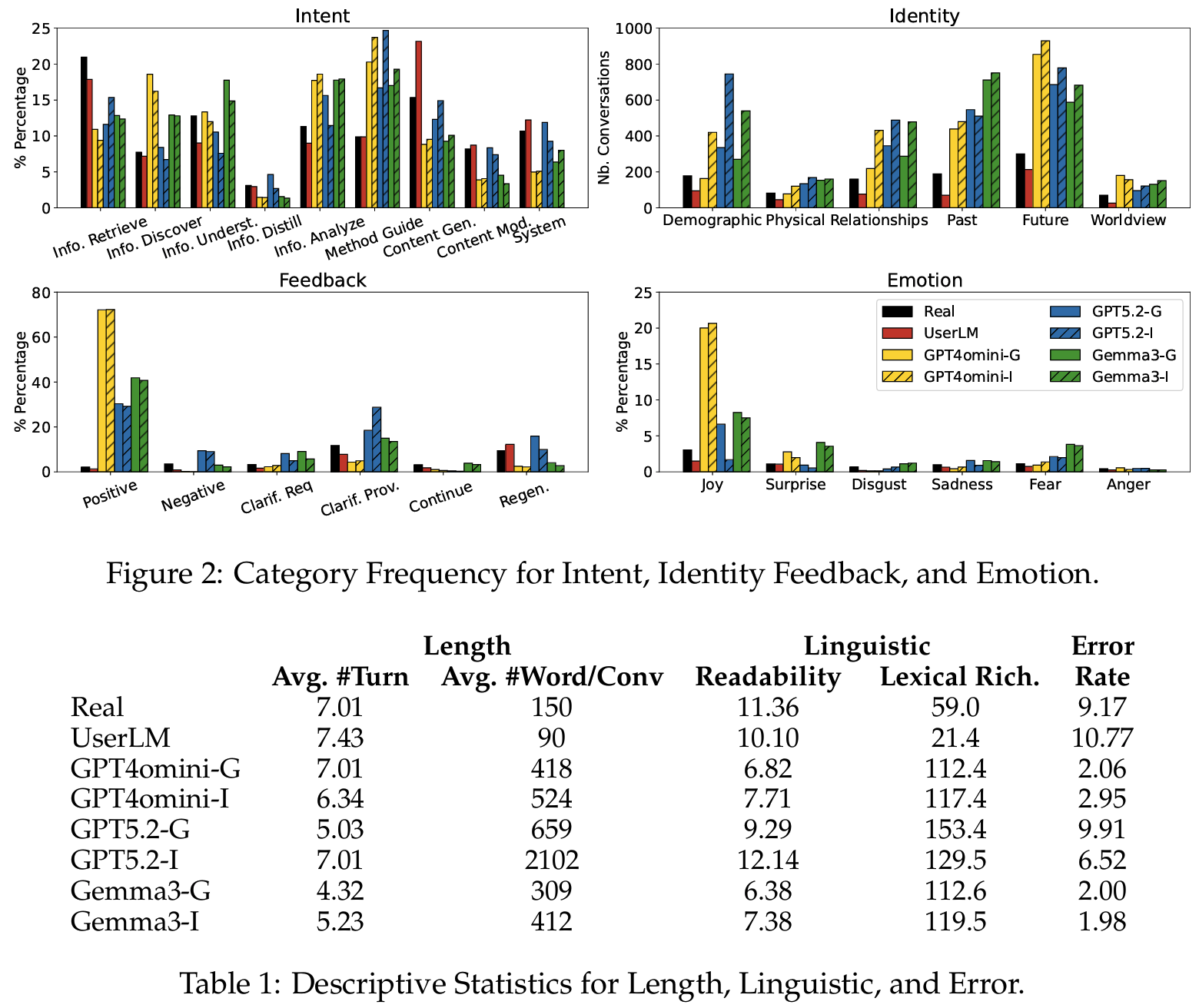
- User States에서 simulated가 demographic / relationships / past / future 정보를 real보다 훨씬 많이 disclose하고 joy 비중도 약 5배 (특히 GPT-4o-mini-Informed) → chatbot이 context 부족 상황을 다루는 능력을 평가하지 못함 (
Fig 2) - Task decomposition pattern이 다름 (
Fig 2)- real intent: information retrieval / content generation에 집중
- simulated intent: method guidance / information analysis로 분산; GPT4o-mini / Gemma3는 real에 거의 없는 information discovery를 빈번하게 생성
- Feedback에서 simulated의 explicit positive 비율이 real 대비 압도적 → negative feedback / regeneration request가 거의 없어 chatbot의 recovery 능력 평가가 사실상 불가능
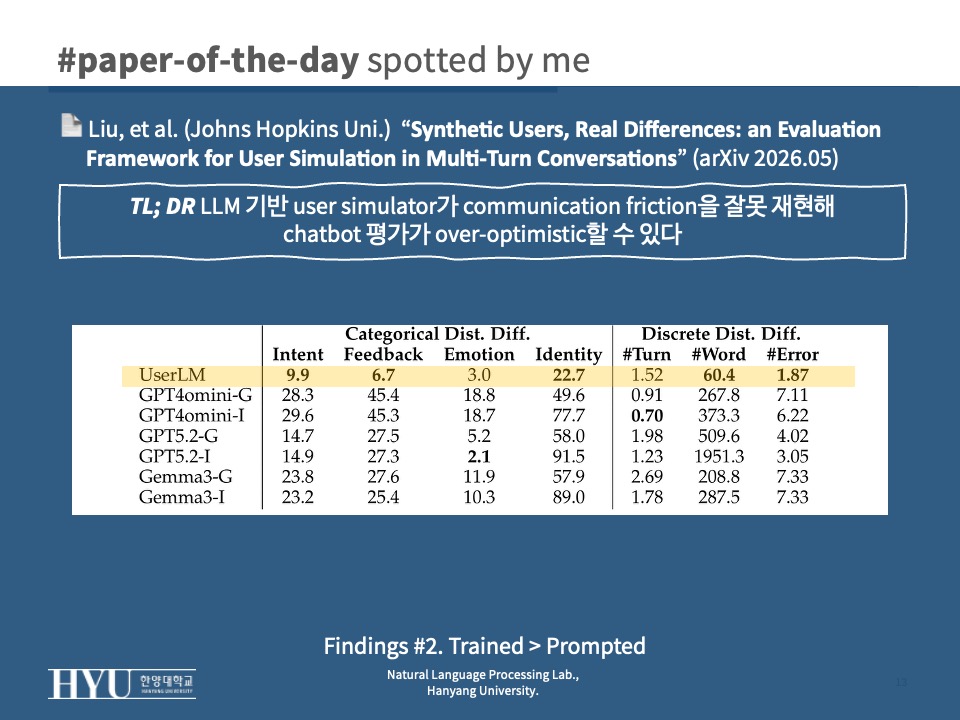
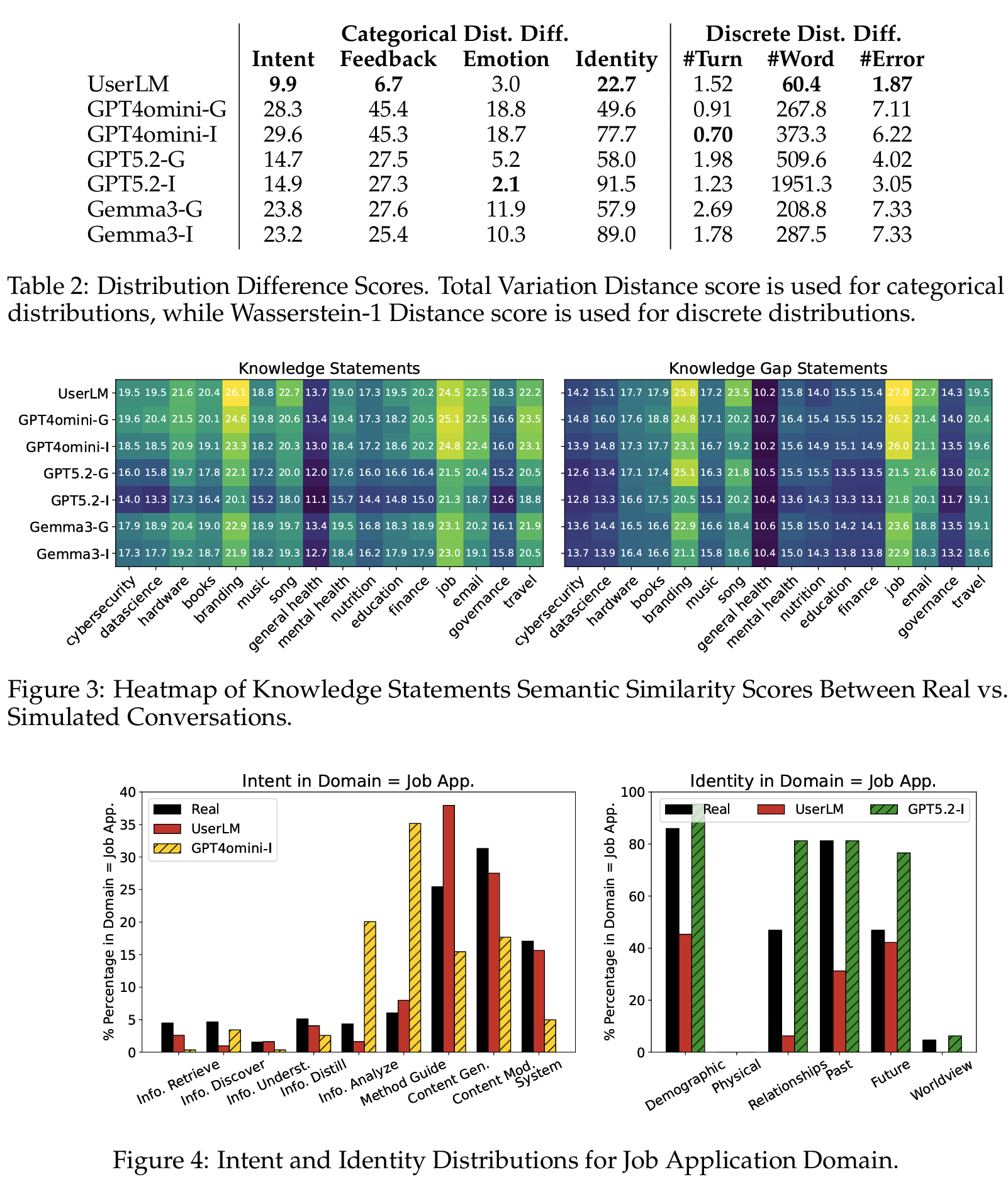
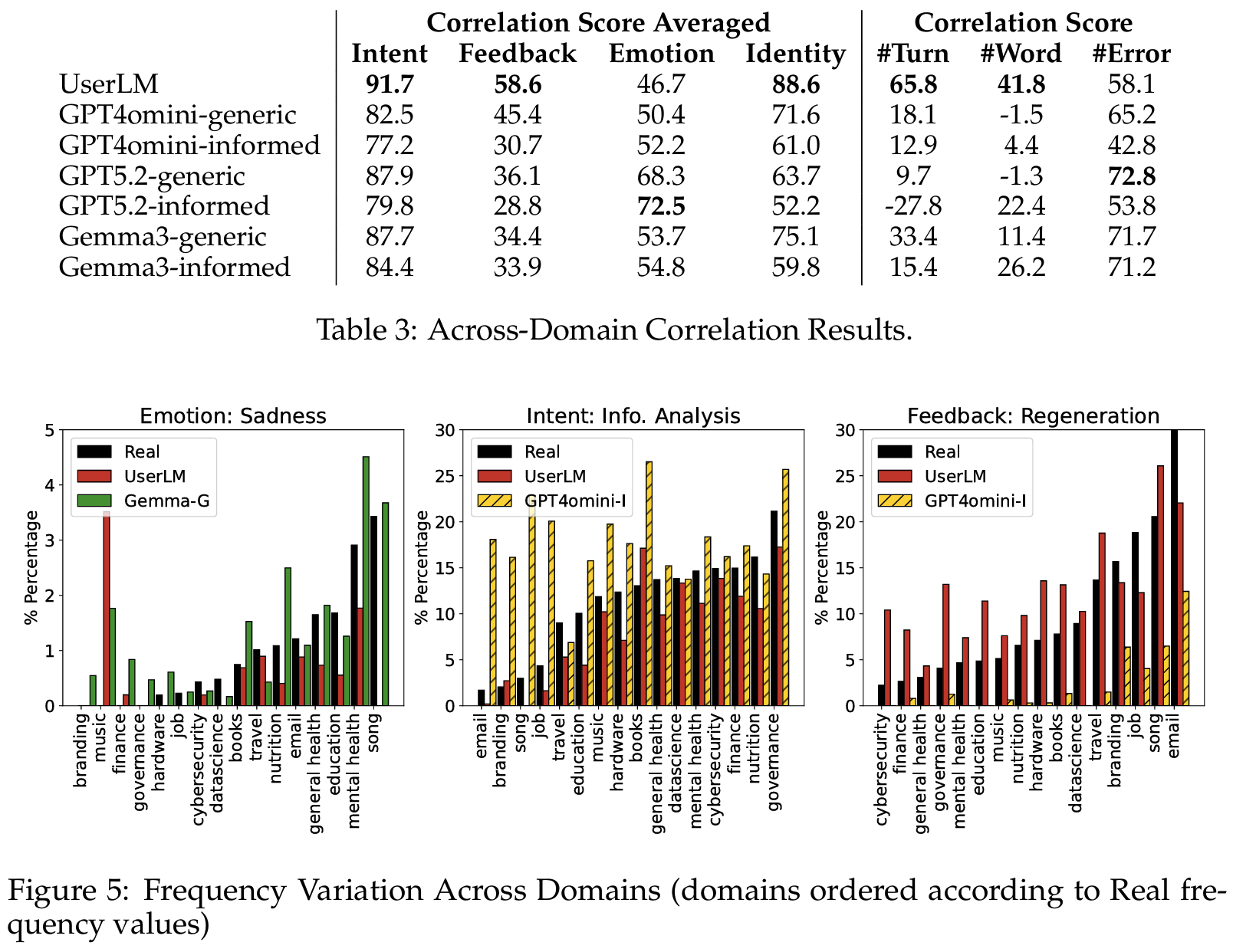
- distribution difference로 정량 확인 시 UserLM이 categorical dimension에서 가장 낮은 → real로 fine-tune한 simulator가 prompt 기반보다 일관되게 real에 가까움 (
Tab 2)- UserLM TVD: Intent 9.9, Feedback 6.7, Identity 22.7
- 다만 #Turn에서는 UserLM (1.52) 이 GPT4omini (0.91/0.70) 보다 못함 → 대화를 언제 끝낼지 결정하는 timing은 여전히 약점
- Surface form에서 길고 깔끔한 “이상적인” 메시지를 만들어내고 real user의 friction을 거의 못 재현 (
- Domain-specific insights: 도메인마다 simulate 난이도가 다름
- Knowledge semantic similarity heatmap에서 simulator는 branding / job application에서는 real에 가깝지만 general health / governance에서는 떨어짐 (
Fig 3)- general health real statement는 임상 증상 / 약물명 / 측정값 등 specific하고 rich한 반면 simulated는 generic (“the user knows about methylene blue”) 에 그침 (
Tab 5)
- general health real statement는 임상 증상 / 약물명 / 측정값 등 specific하고 rich한 반면 simulated는 generic (“the user knows about methylene blue”) 에 그침 (
- job application 도메인 case study (
Fig 4)- Intent: real은 content generation / modification (이력서 작성·수정) 중심, GPT-4o-mini-Informed는 method guidance (작성 방법 문의) 가 ~35%로 폭증
- Identity: real은 interpersonal relationships (past clients, coworkers) 와 past를 풍부하게 드러내는데 UserLM은 이 categories에서 빈약
- domain-specific user simulator 설계 필요성을 시사
- Knowledge semantic similarity heatmap에서 simulator는 branding / job application에서는 real에 가깝지만 general health / governance에서는 떨어짐 (
- Across-domain variation: real user 행동은 도메인별로 크게 변하는데 simulator는 그 variation 못 잡음
- across-domain correlation으로 보면 UserLM이 Intent / Identity에서 가장 높음 (
Tab 3) - UserLM도 real의 도메인별 variation은 못 잡음 (
Fig 5): real은 song / poem writing 도메인에서 sadness emotion이 두드러지는데 UserLM은 평이했거. 이미 general-purpose simulator의 한계
- across-domain correlation으로 보면 UserLM이 Intent / Identity에서 가장 높음 (
- Fine-tuning vs prompting: UserLM 우세는 real user message로 직접 학습한 효과로 해석
- prompting 기반 simulator는 persona를 informed로 만들어도 일관된 개선이 없고 오히려 Identity TVD가 악화되기도 함
- GPT4omini-G 49.6 → GPT4omini-I 77.7
- GPT5.2-G 58.0 → GPT5.2-I 91.5
- 정보를 더 주면 자기 persona에 대해 더 많이 말해버리는 over-disclosure 효과
- prompting 기반 simulator는 persona를 informed로 만들어도 일관된 개선이 없고 오히려 Identity TVD가 악화되기도 함
- Simulated user는 chatbot에게 너무 만만하다
- Limitations
- dataset이 WildChat / LMSYS-1M 기반이라 최근 chatbot 사용 양상을 충분히 대표 못 함;
- 다른 dataset으로 framework instantiate 가능하긴 함
- assistant chatbot을 GPT-4o-mini로 고정 == assistant 모델 종류에 따른 simulator 행동 변화는 검증 안 됨
- HumanLM 같은 다른 trained simulator는 미포함
- dataset이 WildChat / LMSYS-1M 기반이라 최근 chatbot 사용 양상을 충분히 대표 못 함;
Personal note. evaluation과 user modeling 둘 다에서 dialogue 연구가 그나마 설 자리가 남았다는 생각…(?) LLM이 충분히 잘하는 지금 시점에서 chatbot benchmark는 사실상 saturate 됐는데, 정작 real deployment에서는 여전히 multi-turn에서 성능 보전 안되는 아이러니에 대해서 그 gap이 어디서 오는지를 정량화한 게 이 연구의 의의라고 생각합니다. UserLM이 prompt 기반 simulator들보다 일관되게 real에 가까운 분포를 만들어낸 건 결국 real user message 자체로 train한 효과인데, 한 발 나아가서 생각하면 “user behavior를 학습 대상으로”하는 방향이 LLM 시대 dialogue 연구의 새 축이 될 수 있다고 재확인하게 되네요. 어쨌든 기존 연구가 system 쪽 (chatbot 응답 품질) 만 봤다면, 이제는 user 쪽 (어떻게 묻고 어디서 만족하지 못하고 언제 멈추는지) 을 동등한 modeling 대상으로 두긴 해야한다는 이야기… realsim이 이야기하는 그 8-dim distributional view가 어디서 뭐가 어떻게 모자른지 짚어주는 진단 기준이 되는거고 UserLM은 그 진단을 받아서 학습으로 메운 한가지 방법이라는 흐름인데, 저자들이 주장하기로는 UserLM도 across-domain variation을 못잡는단 결론이라서, domain-adaptive user simulator라는 다음 문제로 이어지는 흐름이 자연스럽습니다. 단일 모델이 모든 도메인의 user를 다 흉내는 어차피 못내니까 domain context에 따라 modulate되는 user model이 필요하다는 건데, #proj-aied 쪽과 연결도 되고.. 한계로 언급된 전반적인 부분은 너무 당연하지만 본 연구의 흐름을 꺾을 정도의 크리티컬하진 않다고 느꼈습니다.