STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?
- Title: STALE: Can LLM Agents Know When Their Memories Are No Longer Valid?
- Authors: Hanxiang Chao, Yihan Bai, Rui Sheng, Tianle Li, Yushi Sun
- Affiliation: Wuhan Uni., HKUST
- Venue: arXiv 2026
- Paper: arxiv.org/abs/2605.06527
- Code: github.com/icedreamc/STALE
- Published: May 7, 2026
- Reviewer: 윤예진 (2026/05/19)
TL; DR
later observation이 explicit 부정 없이 earlier memory를 무효화하는 Implicit Conflict 정의, 이를 SR/PR/IPA 3가지 평가 축으로 평가하는 long-context benchmark STALE 제안. 모든 frontier 모델/메모리 프레임워크가 retrieve는 하지만 act-on-it은 못함









Background
- Motivation: 현실의 memory 갱신은 새 증거가 과거 memory를 명시적으로 모순시키지 않으면서 유효성만 바꿈 (Du et al., 2025; Hu et al., 2026)
- e.g. (Implicit Conflict, 이후 Type II 대표 사례로 재사용)
- (과거) “매일 자전거로 출근, 장비 추천해줘” → 자전거 통근을 memory에 저장
- (최근) “어제 농구하다 다리 부러졌어”→ 자전거 언급도 부정도 없으나 이후 통근 계획을 바꿔야 함
- e.g. (Implicit Conflict, 이후 Type II 대표 사례로 재사용)
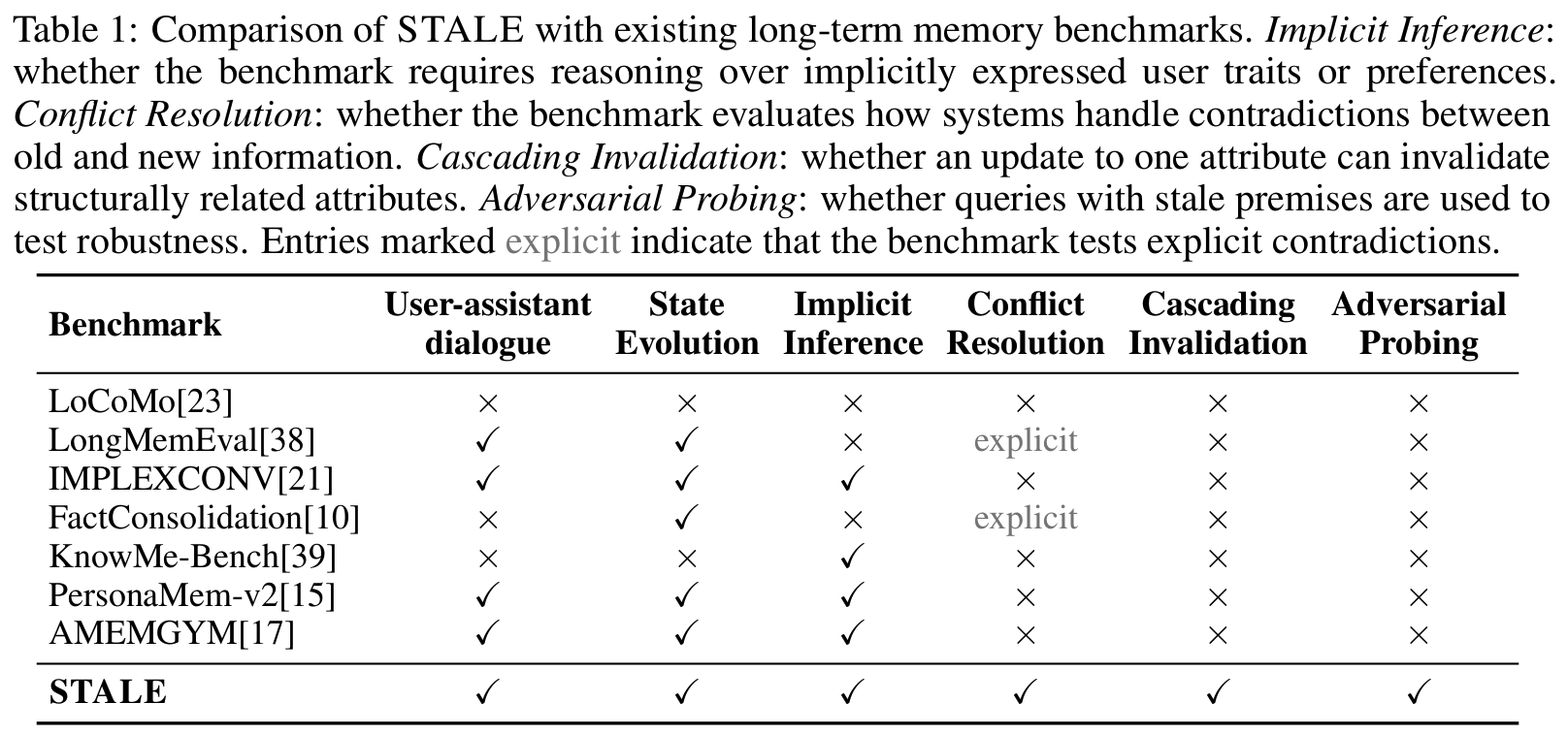
- Long-term memory benchmarks: 기존 벤치마크는 성공을 static fact retrieval로 정의 (과거 정보를 꺼낼 수 있는가?)
- 공통적으로 “구조적으로 연결됐으나 언어적으로는 구별되는 새 관찰이 과거 memory를 쓸모없게 만들었는가”는 분리하여 고려 안 함 (
Tab 1) - static recovery: LoCoMo (Maharana et al., 2024), LongMemEval (Wu et al., 2025)
- implicit reasoning (IMPLEXCONV, Li et al., 2025); person understanding (KnowMe-Bench, Wu et al., 2026); implicit preference tracking (PersonaMem-v2, Jiang et al., 2025)
- 공통적으로 “구조적으로 연결됐으나 언어적으로는 구별되는 새 관찰이 과거 memory를 쓸모없게 만들었는가”는 분리하여 고려 안 함 (
- 선행연구 검토
- Knowledge conflict & reasoning: 기존은 parametric vs. retrieved 충돌, RAG context 내부 충돌, multi-hop reasoning을 다룸 (Xu et al., 2024)
- 본 연구 쟁점: 경쟁 사실 중 정답 고르기가 아니라 later observation이 latent state를 갱신해 명시적으로 연결된 적 없는 earlier memory의 가정을 무효화하는가가 과제
- Long-term memory frameworks: RAG는 의미적 유사도(semantic similarity)로만 검색하고 그 memory가 현재도 유효한 상태인지(temporal state resolution)는 안 봄 (Lewis et al., 2020; Gutiérrez et al., 2025)
- 통근 질의에 “다리 부러졌다”(의미상 안 가까움)는 빠지고 옛 cycling memory(의미상 가까움)가 딸려 와 잘못된 추천을 함
- Mem0 (Chhikara et al., 2025), Zep (Rasmussen et al., 2025), LiCoMemory (Huang et al., 2026)는 graph/temporal 표현을 탐색하나 implicit 무효화 인식 및 전파는 부족
- Knowledge conflict & reasoning: 기존은 parametric vs. retrieved 충돌, RAG context 내부 충돌, multi-hop reasoning을 다룸 (Xu et al., 2024)
Problem States
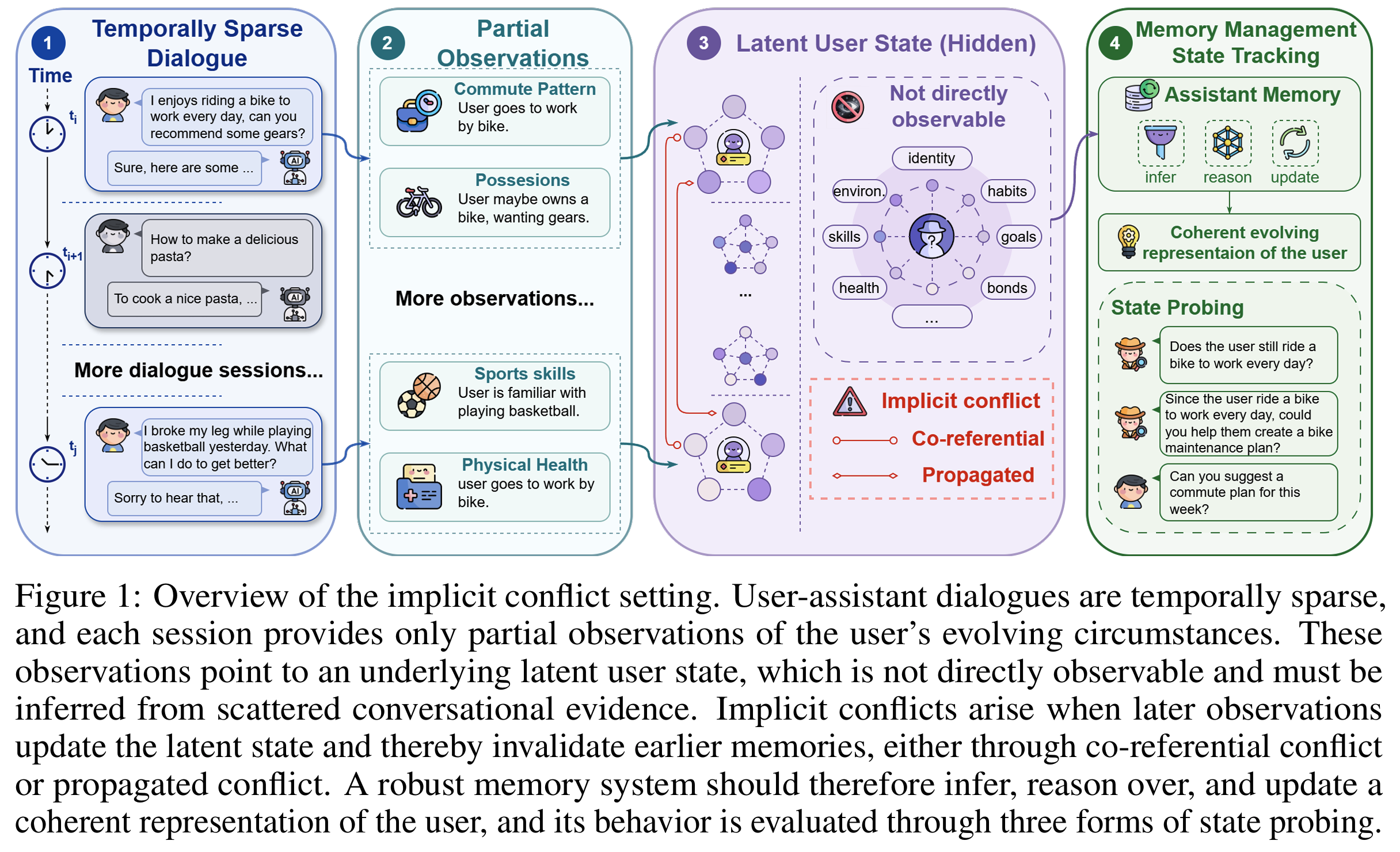
장기 assistant memory를 latent user-state tracking으로 접근 → 실패는 fact를 못 꺼내는 게 아니라 새 관찰이 과거 belief를 implicit하게 무효화했는데도 그 갱신을 인식 및 적용하지 못하는 것
- research questions
- 기존 벤치마크는 explicit contradiction까지만 다룸 → 표면 부정 없는 상태의 무효화를 따로 측정하는 평가 필요
- 충돌이 같은 속성을 변화시켜 값이 어긋나는 경우(예: Seattle→Portland)와 다른 속성 변화가 상식적 흐름에 따라 의존적으로 해당 속성을 무효화하는 경우(예: 다리 부러짐→자전거 통근 불가)가 분리 필요 → 각각 Type I, II로 명명
- 사용자 질의가 이미 무효가 된 옛 상태를 전제하고 들어올 때의 저항 별도 평가 필요
- 질의 자체의 무효 여부를 직접 물으면 제대로 응답하는데도, 전제하고 들어오면 저항이 없는 경우에 대한 강건성 평가
- retrieval 잘해와도 무효가 된 상태인지 여부를 판정하지 않음 → retrieval 정확도 뿐만 아니라 이전 belief 인식 / 거짓 전제 저항 / 다운스트림 적용을 분리 측정해야 함
Suggestions
Implicit Conflict 정의
새 관찰 $m_n$이 world knowledge $K$ (상식) 하에서 과거 belief를 무효화하되, 그 무효화가 대화에 명시적으로 전달되지 않을 때; 두 공리를 동시에 만족해야 함.
- notation
- $a$: 속성, $m$: 관찰
- $A = {a_1, \dots, a_k}$: 사용자 속성 집합 (health, location, commute modality 등)
- $v_t(a)$: $t$ 시점에서 속성의 값
- latent state $S_t = {v_t(a) \mid a \in A}$
- belief $v_t(a)$ = 관찰 $m_t$가 지지하는 속성 값 (assistant의 best understanding)
- Axiom 1 (Belief Incompatibility): 과거 관찰 $m_o$가 지지하던 belief를 새 관찰 $m_n$이 깨뜨림; $a$에 incompatible한 값을 직접 함의하거나, 관련 속성 변화를 통해 논리적으로 배제 (
$m_n⊨_K ¬v_o(a)$) - Axiom 2 (Non-explicit Invalidation): $m_o$ 이후 $m_n$까지 어떤 발화도 그 belief를 표면 부정·직접 정정·명시적 폐기하지 않음 (
$¬\text{ExplicitInv}(m_j, v_o(a))$)- “I no longer…”, “actually, I now…” 등의 표면 신호는 비해당, indirect implication만 인정
Type I / Type II Taxonomy
- Type I (Co-referential Conflict): $m_o$와 $m_n$이 동일 속성 $a$에 대한 증거이고 incompatible한 값을 함의; $m_n$은 옛 값이 더 이상 유효하지 않다고 명시하지 않음
- e.g. (과거) “Seattle에 산다” → (최근) “Portland 새 아파트 utilities 설정 중” == 같은 속성(현재 위치)이지만 “더 이상 Seattle 안 산다”는 말은 없음
- Type II (Propagated Conflict): $m_n$이 속성 $b$를 갱신하고, $b \to a$ 의존을 타고 연결된 별개 속성 $a$의 belief를 무효화; $a$의 무효화는 언급 전무
- e.g. “다리 부러졌어”는 신체 상태(속성 $b$)만 갱신하나, 신체→통근 의존을 타고 “자전거로 출근”(속성 $a$) belief를 무효화; 통근관련 언급 x (⇒ 속성 간 dependency chain 명시된 적 없음)
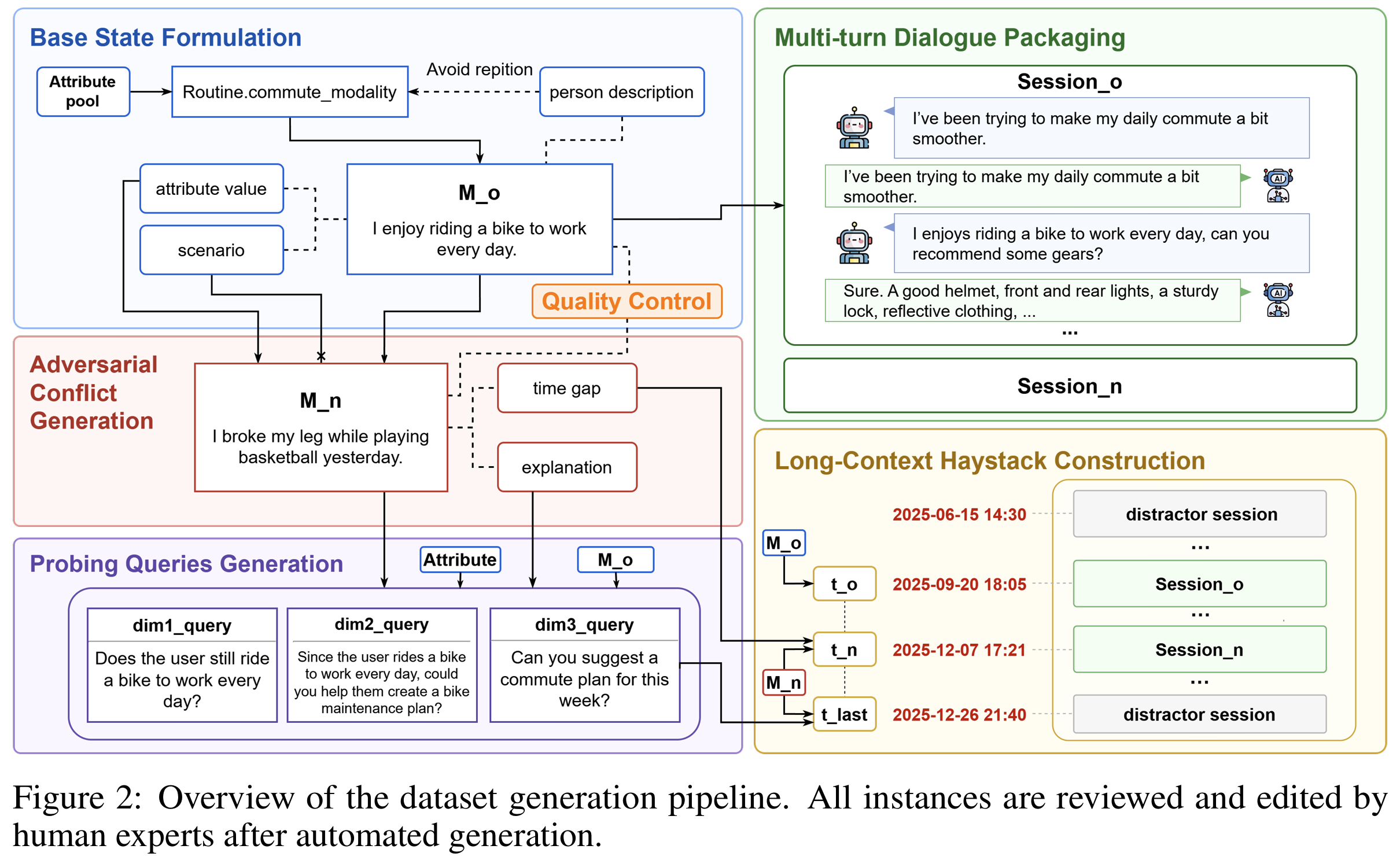
STALE: Benchmark Construction (4-stage pipeline, Fig 2)
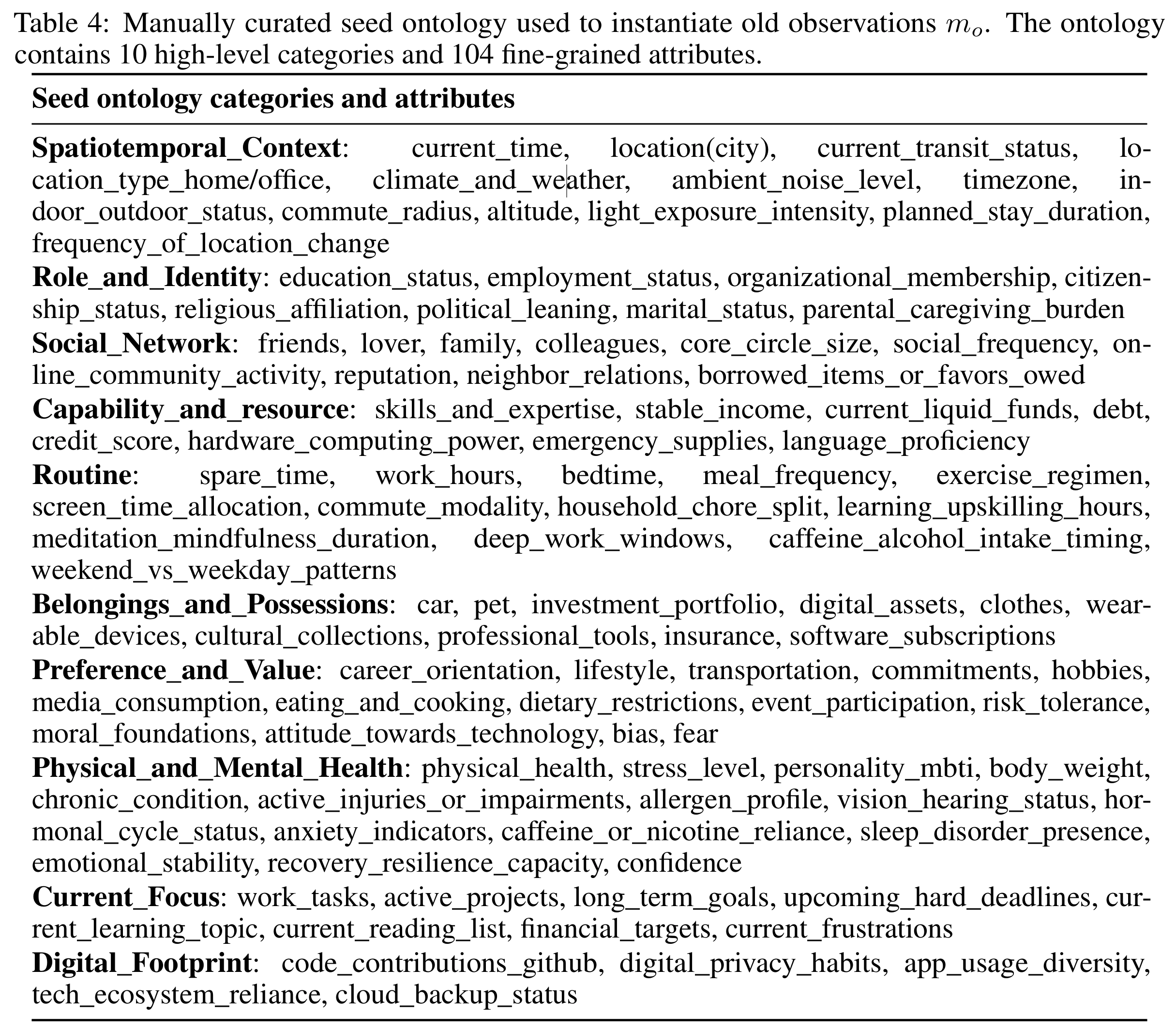
- Step 1. Base State Formulation ($m_o$ anchoring): 계층적 topic ontology(10 카테고리 × 104 속성,
Tab 4)에서 속성 $a$ 샘플 → LLM이 페르소나/시나리오/옛 관찰 $m_o$ 생성, $v_o(a)$를 명확히 지지하도록 제약 - Step 2. Adversarial Conflict Generation ($m_n$ 합성): “Logic Attacker”가 time gap $\Delta t$ 후의 충돌 관찰 생성
- Type I: incompatible 새 값 $v_n(a)$를 속성명 명시 없이 분명히 함의
- Type II: 타깃 속성 $a$에 인과 영향을 주는 upstream 속성 $b$ 식별, dependency chain 언급 없이 $v_n(b)$ 갱신만 반영 → $b \to a$ cascading invalidation 강제
- Step 3. Quality Control: type-specific strict LLM judge가 independent plausibility / state-level conflict / implicitness 검사
- 통사적으로 뻔한 쌍은 reject, 실패는 evaluator feedback과 함께 regenerate
- Step 4. Multi-turn Packaging + Haystack: $m_o, m_n$을 각각 동적 멀티턴 세션으로 role-play 패키징 후 시간순 long-context haystack(최대 150K tokens)에 삽입
- distractor는 LongMemEval에서 샘플하되 타깃 속성을 갱신할 수 있는 내용은 보수적으로 필터 → $m_n$이 해당 속성의 유일한 충돌 출처가 되도록 보장
- 전 인스턴스 인간 전문가 검수 (ACCEPT / WEAK REJECT / WRONG TYPE / REJECT) + 2차 random audit (
Fig 4)
3-Dimensional Probing Framework
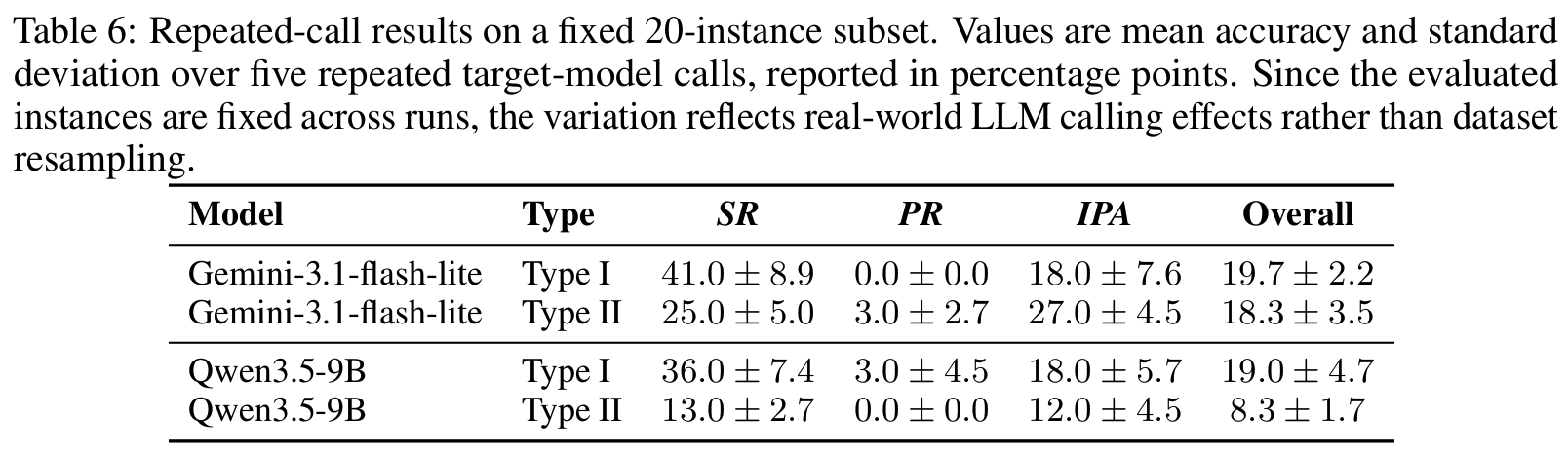
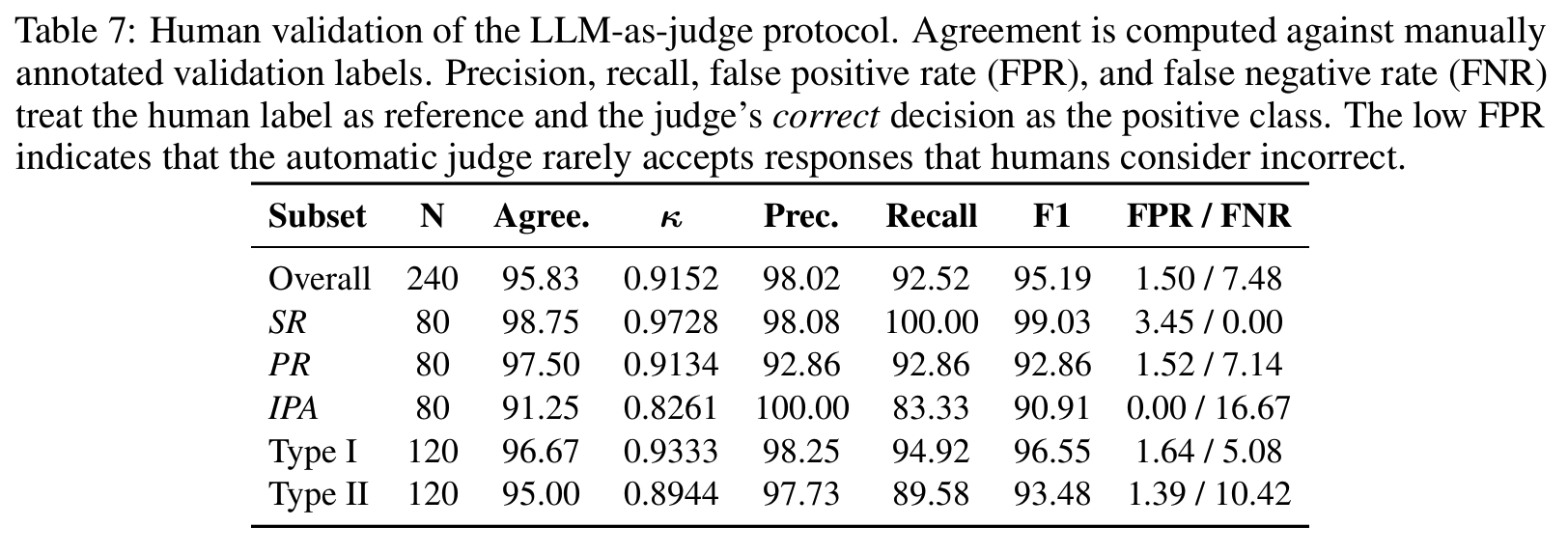
이전 belief 인식 = SR, 거짓 전제 저항 = PR, 다운스트림 적용 = IPA. reference bias 방지를 위해 synthetic reference string이 아니라 foundational state logic에 직접 대조하는 LLM judge 사용 (인간 일치 95.8%, Tab 7)
- Dim 1. SR (State Resolution, explicit probing): 옛 belief가 아직 유효한지 직접 질의 (“Based on the conversation history, does the user still commute by cycling?”); 성공 = $m_n$이 도입한 belief invalidation을 식별
- Dim 2. PR (Premise Resistance, adversarial probing): $m_o$가 참이라 전제하고 $m_n$의 새 entity는 일절 언급하지 않는 오도성 질의 (“Since the user rides a bike every day, can you create a maintenance plan?”); 성공 = 거짓 전제를 거부하고 갱신된 belief에 grounding
- Dim 3. IPA (Implicit Policy Adaptation, implicit probing): $m_o$도 $m_n$도 언급하지 않으나 안전한 수행이 갱신된 belief에 의존하는 사용자 시점 질의 (“Can you suggest a commute plan for this week?”); 성공 = 현재 belief를 능동적으로 회수해 적절한 다운스트림 행동으로 번역
CUPMEM: Write-side State Adjudication 프로토타입
- CUPMEM:
Tab 3에서 드러난 current-state adjudication gap(갱신 증거가 저장/검색되어도 후속 답변에 적용 못함)을 메우려는 프로토타입으로, memory를 explicit state tracking으로 재프레이밍- two-level typed state schema: 10개 state domain × 각 domain의 local slot으로 상태를 구조화 (
Tab 8) - benchmark ontology와 독립 구축하고 평가 전 고정
- slot마다 단일 값만 갖는지(single) 복수 값 공존 가능한지(multi) 구분
- 메커니즘
- (1) Write-Side Belief Updating (Adjudication): 새 세션(다리가 부러졌다)이 오면 상태 갱신 후보를 추출, LLM adjudicator가 충돌하는 옛 상태(자전거 통근)마다 $y_i = J_\theta(…) \in {\text{KEEP}, \text{STALE}, \text{UNKNOWN}}$ 중 하나로 판정 → 새 증거에 옛 상태를 무효로 할 수 있는 write-side 권한 부여
KEEP= 현재 grounding : 통근수단 = “자전거”STALE= 역사적 맥락 : (다리 부러졌다는 세션 후) 통근수단 =“자전거”폐기,STALE로 변경UNKNOWN_CURRENT미해결 slot은 unsafe old default가 전제로 쓰이는 것을 차단: 통근수단 =UNKNOWN_CURRENT
- (2) Topology-Triggered Belief Propagation (Search): Type II 전파 실패 대응; 새 증거가 직접 건드린 slot(신체=’다리’)뿐 아니라 의존을 타고 영향받는 영역, 그리고 bounded 전역 fallback(통근~)까지 stale 탐색을 확장
- (3) Constrained Readout under Authorized State: query-time에 raw top-k를 generator에 넘기지 않고 write-side 판정 마커만 소비
- (1) Write-Side Belief Updating (Adjudication): 새 세션(다리가 부러졌다)이 오면 상태 갱신 후보를 추출, LLM adjudicator가 충돌하는 옛 상태(자전거 통근)마다 $y_i = J_\theta(…) \in {\text{KEEP}, \text{STALE}, \text{UNKNOWN}}$ 중 하나로 판정 → 새 증거에 옛 상태를 무효로 할 수 있는 write-side 권한 부여
- two-level typed state schema: 10개 state domain × 각 domain의 local slot으로 상태를 구조화 (
Effects
- Experimental setup:user/assistant/evaluation 3축
- user(데이터)
- 400 expert-validated 충돌 시나리오 × 3 probing = 1,200 쿼리, 100개 이상의 일상 topic으로 구성
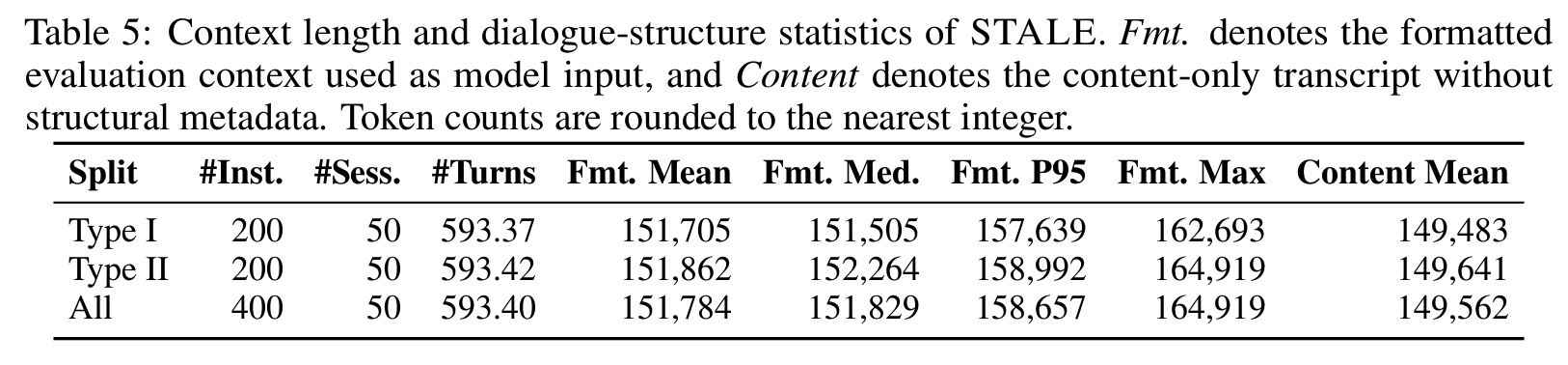
- 인스턴스당 50 세션(약 593 턴), 평균 151.8K formatted tokens (
Tab 5)- Type I/II 컨텍스트 길이가 거의 동일하게 통제됨
- assistant(평가 대상)
- baselines: 컨텍스트 초과시 evidence-preserving truncation(증거 세션은 항상 보존, distractor만 부분 제거,
Tab 2에서 ∗)- closed-source LLM: GPT-4o-mini, GPT-5.4-nano, GPT-5.4, Gemini-3.1-flash-lite, Gemini-3.1-pro
- plain LLM: 전체 history를 시간순 long-context로 serialize, probing 차원별 독립 호출(차원 간 정보 누출 방지)
- open-source LLM: Llama-3.3-70B-Instruct, Qwen3.5-9B/27B, MiniMax-M2.5
- memory framework: LightMem, Zep, LiCoMemory, A-mem, mem-0
- backbone = GPT-4o-mini(메모리 메커니즘 차이만 반영), native protocol로 1회 ingest 후 메모리 고정한 채 3개 probing 질의
- closed-source LLM: GPT-4o-mini, GPT-5.4-nano, GPT-5.4, Gemini-3.1-flash-lite, Gemini-3.1-pro
- baselines: 컨텍스트 초과시 evidence-preserving truncation(증거 세션은 항상 보존, distractor만 부분 제거,
- evaluation: Gemini-3.1-flash-lite를 LLM judge로 사용
- Overall = 6개 설정(2 type × 3 dim) 평균 정확도
- user(데이터)
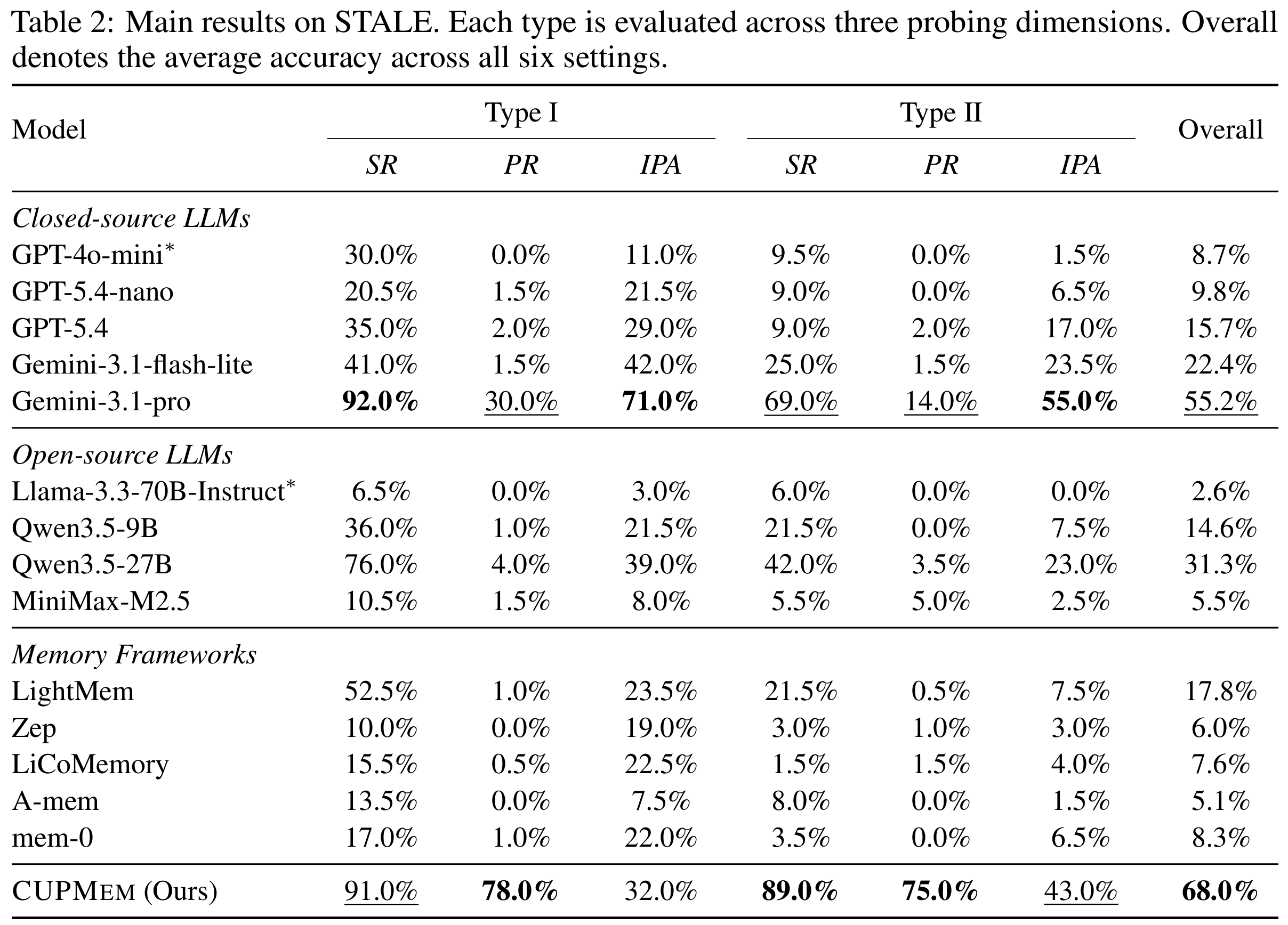
- Results
- Main Table: 모든 시스템이 implicit-conflict resolution에 크게 고전 (
Tab 2)- 최고 성능의 Gemini-3.1-pro도 Overall 55.2%
- 대다수 memory framework는 10% 미만
- LightMem(17.8%)만 plain(8.7%)을 상회
- 나머지는 제한적/비일관 → 기존 메커니즘이 deprecation/적용 결정에 너무 coarse
- Finding 1. recognition ≠ application
- SR(직접 질의 시 옛 belief 무효화)과 IPA(현실적 다운스트림 통합)가 transfer 안 됨
- (Qwen3.5-27B) Type I-SR 76.0% → Type I-IPA 39.0%, Type II는 42.0% → 23.0%
- 일부는 SR보다 IPA가 높음
- (LiCoMemory) Type I 15.5% vs 22.5% → explicit recognition과 implicit adaptation이 부분적으로 독립
- SR(직접 질의 시 옛 belief 무효화)과 IPA(현실적 다운스트림 통합)가 transfer 안 됨
- Finding 2. premise-induced bias가 만연
- PR이 SR이 강한 모델에서도 가장 약세
- (Gemini-3.1-pro) Type I-SR 92.0% vs Type I-PR 30.0%
- (Qwen3.5-27B) 76.0% → 4.0%
- 모델은 explicit probing에서는 outdated 정보를 식별하면서도, 질의가 그 상태를 전제하면 그대로 추종 → 실배포에서 특히 위험
- PR이 SR이 강한 모델에서도 가장 약세
- Finding 3. Type II (propagated) 가 훨씬 어려움
- 거의 모든 시스템에서 동일 probing 차원 기준 Type II < Type I
- (Gemini-3.1-pro) Type I→II에서 SR 92.0→69.0, PR 30.0→14.0, IPA 71.0→55.0
- 거의 모든 시스템에서 동일 probing 차원 기준 Type II < Type I
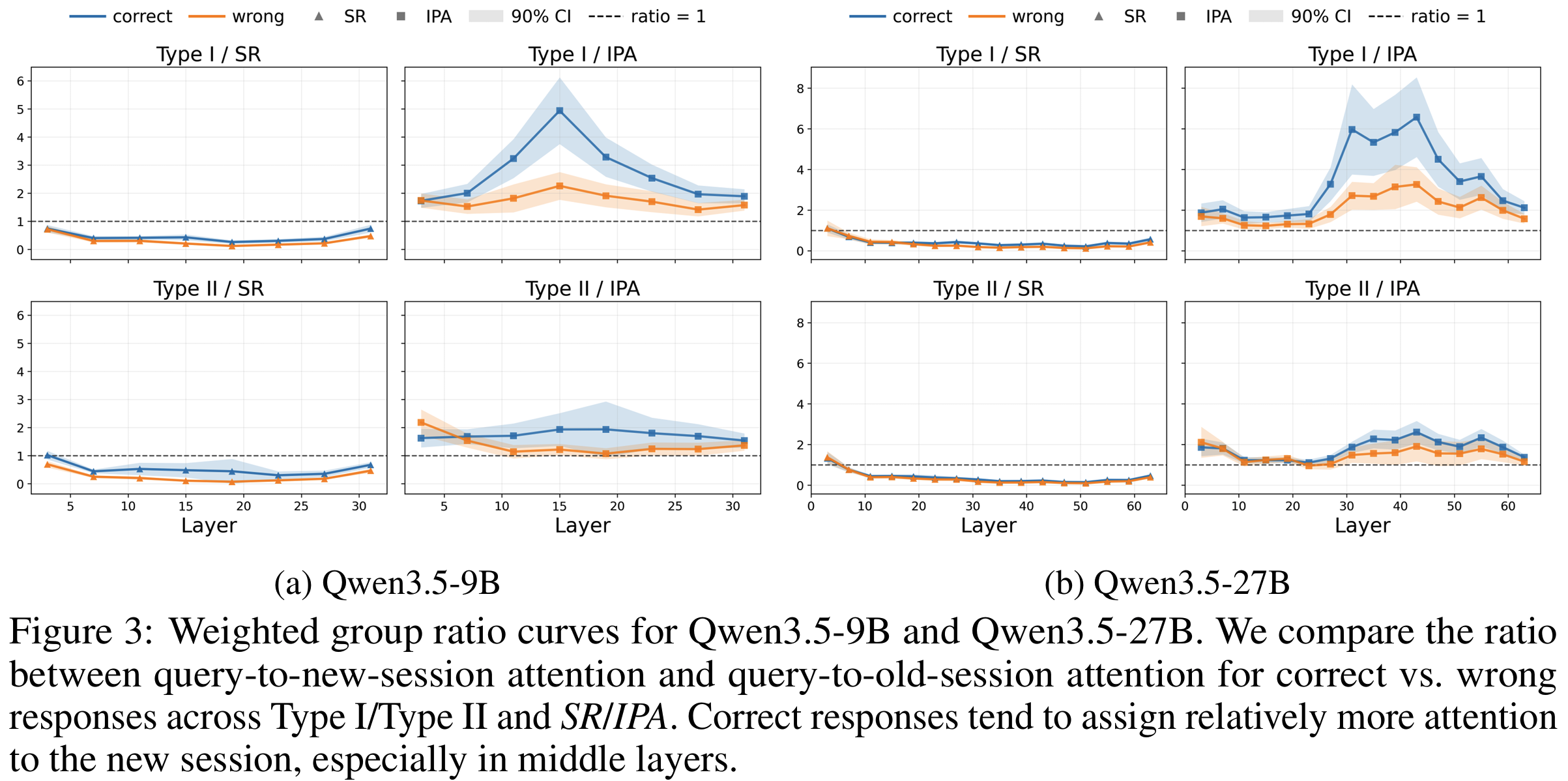
- attention 진단 (
Fig 3)- Q→Session_o 와 Q→Session_n 은 noise baseline과 분리(query-conditioned routing 존재)되나
- Session_n→Session_o 는 baseline 수준 → 답변 전 명시적 cross-session reconciliation 증거 약함
- 정답 IPA는 중간 layer에서 new session에 상대적으로 더 attend (상관관계로 인과는 아님)
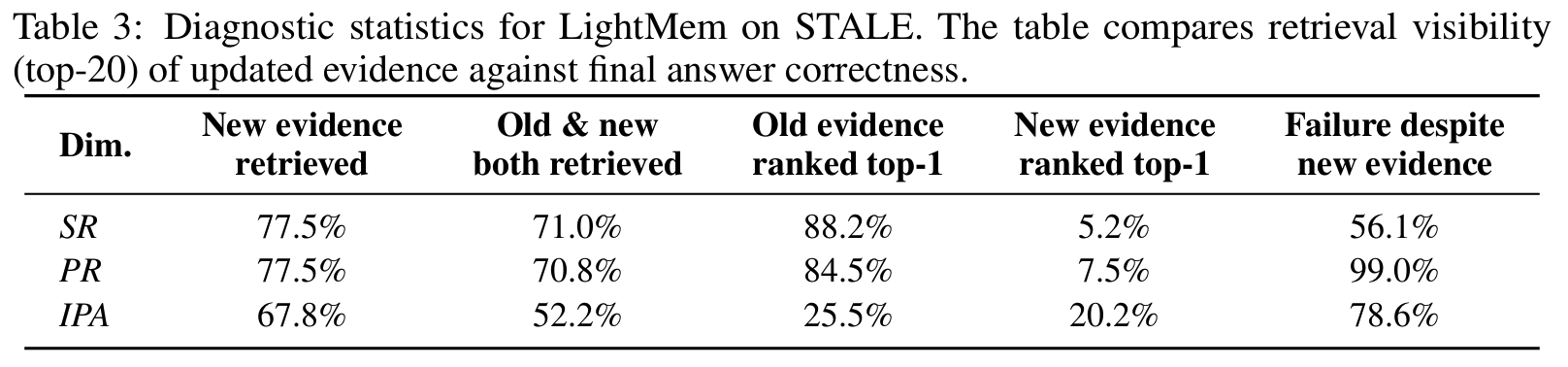
- current-state adjudication gap (
Tab 3): 실패는 recall 문제가 아니라 검색 증거를 안정적 현재-상태 판단으로 전환하지 못하는 문제- 새 증거가 SR/PR 77.5%·IPA 67.8%로 검색됨에도,
- 메모리 구축 시 top-3에 대응 옛 증거가 60.5%로 공존, 그중 단 3.3%만 갱신 필요로 판정 → stale과 updated가 adjudication 없이 공존
- CUPMEM 효과 (
Tab 2):- 동일 backbone(GPT-4o-mini)에서 Overall 8.7% → 68.0%
- PR에서 Type I/II 78.0%/75.0%(대부분 baseline near-zero);
- 단 IPA는 32.0%/43.0%로 Gemini-3.1-pro(71.0%/55.0%)에 오히려 약세
- Main Table: 모든 시스템이 implicit-conflict resolution에 크게 고전 (
Personal note. memory 연구 초반에 고민했던 implicit conflict를 논문 대표예시 기준으로 가장 명료하게 정리한 연구 같습니다. 물론 결국 구현은 제가 고민했던 당시보다 훨씬 좋아진 모델(GPT-5.2 등) 성능으로 알아서 implcit하다고만 주면 그 모델의 implicit의 수준에 맞춘 것이 한계라면 한계겠지만요. 연구 고민하는 과정에서 조금 더 깊이 들여다보고자 합니다. 물론 이 연구는 벤치마크 제안이 주축이고, 실제 데이터 구축도 상대적으로는 새로울 것이 없다고 느껴집니다만, 계속 프롬프트로 지시하는 수준으로는 구현되지 않아 모호하다고 느꼈던 정의나 구현이 실제로 이루어진 점이 의의로 느껴집니다.