Pushing the Limits of LLM Tool Calling via Experiential Knowledge Integration and Activation
Meta info.
- Authors: Yupu Hao, Zhuoran Jin, Huanxuan Liao, Kang Liu, Jun Zhao
- Affiliation: Institute of Automation, Chinese Academy of Sciences (CASIA); University of Chinese Academy of Sciences
- Paper: https://arxiv.org/abs/2606.10875
- Code: https://github.com/hypasd-art/KATE
- Published: June 9, 2026 (arXiv preprint)
TL; DR
Tool-use에서 experiential knowledge를 획득·활성화·내재화 전 단계에 걸쳐 분석하고, instance-level trajectory + reasoning-width 확장(parallel sampling) + knowledge-aware training을 통합한 KATE를 제안
Background
- tool-use 연구의 문제 환원 방식: (전제) 모델이 이미 충분한 experiential knowledge를 가지고 있다
- prompt design 문제 (Shinn et al., 2023)
- API documentation specification 문제 (Qu et al., 2025)
- supervised/unsupervised alignment 문제 (Liu et al., 2025b, ToolACE)
- tool-use 실패: reasoning 부족이 아닌 concrete, executable experience의 부재에서 비롯
- 실행 수준의 지식 결핍: parameter constraint, scenario-specific operation pattern, error recovery strategy 등
- tool-use의 knowledge를 다룬 선행 연구: (experiential knowledge / procedural memory) 대부분 특정 knowledge 표현 구성과 fine-grained retrieval 설계에 집중
- Memp (Fang et al., 2025): 과거 trajectory를 재사용 가능한 skill로 변환하는 procedural memory 관리
- Agent Workflow Memory (Wang et al., 2025), Agent KB (Tang et al., 2025), Mem0 (Chhikara et al., 2025), Memento (Zhou et al., 2025)
- 한계: knowledge가 tool-use 파이프라인 전반(획득 → 활성화 → 내재화)에서 어떻게 작동하는지에 대한 원리 이해 공백
- 본 연구 제안: (1) Knowledge Acquisition & Integration, (2) Knowledge Activation & Utilization
Problem States
tool execution에서 experiential knowledge의 역할을 단계별로 분리
- 어떤 형태/granularity의 knowledge가 tool use에 가장 효과적인가 → Knowledge Acquisition & Integration
- 확보된 knowledge를 inference 시 어떻게 activate해야 하는가 → Inference-Time Activation
- knowledge를 parameter에 internalize(training)하면 retrieval만으로 얻는 것 이상의 추가 이득이 있는가 → Training-Time Activation
Suggestions
Definition
- multi-turn tool use를 MDP로 정의
- step $t$에서 LLM $P$는 tool set $\mathcal{T}$, system prompt $S$, dialogue history $H_t$를 조건으로 다음 action $o_{t+1}$을 예측
- $o_{t+1}$: tool 호출 $c_{t+1}$ or 최종 자연어 응답 $a_{t+1}$ (binary)
- 환경은 feedback $r_{t+1}$ 반환: tool 실행 결과 $r^{env}{t+1}$ 또는 user 발화 $r^{user}{t+1}$
- history는 다음과 같이 갱신되어 Markovian loop를 완성
- knowledge base $\mathcal{K}$에서의 retrieval: query $Q$와 stored knowledge 간 similarity가 threshold $p$ 이상인 entry 중 top-$K$ 선택
- $Q$: user query $r^{user}{t+1}$(instance-level) 또는 추론된 intent $I{t+1}$(intent-level)
- intent-level은 $K=1$로 가장 유사한 한 건만 사용
- user query가 관측되면 retrieved knowledge를 해당 turn에 concat해서 augmented history로 진행
Knowledge Acquisition & Integration
- experiential knowledge를 granularity 기준으로 instance-level과 intent-level로 나누고, 각 level에서 두 형태씩 총 4종을 구성
- Instance-level: 구체적, example-specific guidance
- Scenario Trajectory Knowledge (ST): 비슷한 과거 예시 sequence를 통째로 제공
- ground-truth tool 실행 trajectory를 그대로 input으로 제공 (step-by-step 명시적 가이드)
- Experience Summary Knowledge (ES): 해당 sequence를 LLM으로 요약해서 제공
- query와 ground-truth trajectory 쌍을 LLM(GPT-4o)에 넣어 textual operational guideline으로 요약
- Scenario Trajectory Knowledge (ST): 비슷한 과거 예시 sequence를 통째로 제공
- Intent-level: task 목표/결정 패턴의 추상화
- Script-Style Intent Clustering Knowledge (SIC): 비슷한 query를 의도별로 묶어서 조건분기가 있는 JSON SOP로 일반화
- query intent를 생성 → K-Means clustering → 각 cluster를 conditional logic + step sequence를 담은 JSON SOP script로 induction
- Textual-Style Intent Clustering Knowledge (TIC): 해당 SOP를 자연어로 제공
- SIC의 refined pattern을 자연어 서술로 다시 풀어쓴 형태
- Script-Style Intent Clustering Knowledge (SIC): 비슷한 query를 의도별로 묶어서 조건분기가 있는 JSON SOP로 일반화
- Instance-level: 구체적, example-specific guidance
- knowledge base 구축: instance-level은 user query를 인코딩 저장
- intent-level은 raw query가 아니라 추론된 intent $I$를 인코딩해 저장
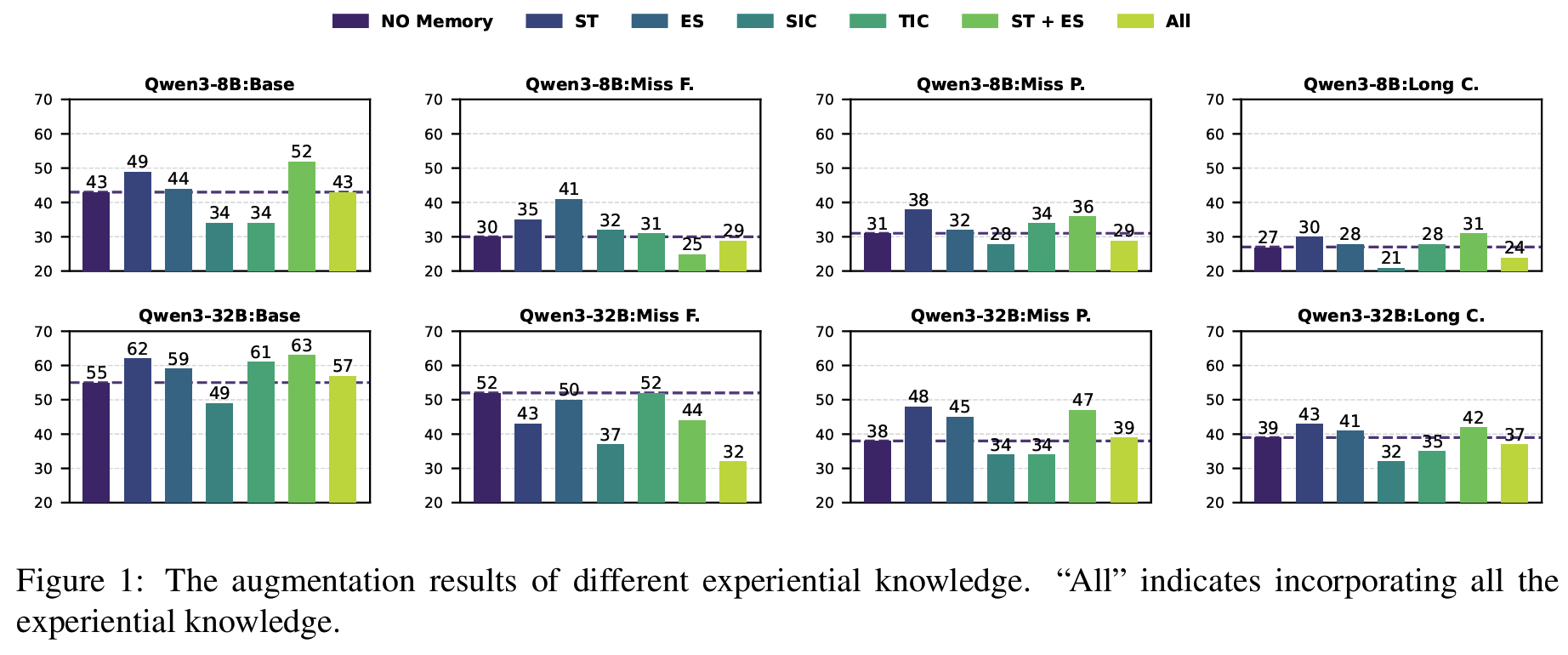
Fig 1Qwen3-8B/32B × BFCL-V3 벤치마크 시나리오(Base/Miss Func/Miss Param/Long Context)- instance-level이 intent-level보다 일관되게 큰 성능 향상
- instance-level: trajectory가 directly executable한 fine-grained 가이드로 작용
- ST와 ES는 전반적으로 비슷; 어떤 쪽이 우세한지는 task/backbone에 따라 달라짐
- intent-level: query에서부터 intent를 맞히고 → 그 추상 패턴을 현재에 다시 구체화하므로, 앞선 단계에 오류가 있으면 누적
- instance-level: trajectory가 directly executable한 fine-grained 가이드로 작용
- 여러 knowledge를 단순히 다 쌓는다고(ST+ES+SIC+TIC) 추가 이득이 보장되지 않음
- redundancy/interference가 생겨 오히려 loss
- 양보다 selective integration이 중요
- instance-level이 intent-level보다 일관되게 큰 성능 향상
Knowledge Activation: Inference-Time
- 고정된 knowledge 하에서, 모델의 tool-use 능력을 어떻게 더 잘 끌어낼지를 (1) reasoning depth와 (2) reasoning width 두 축으로 탐구
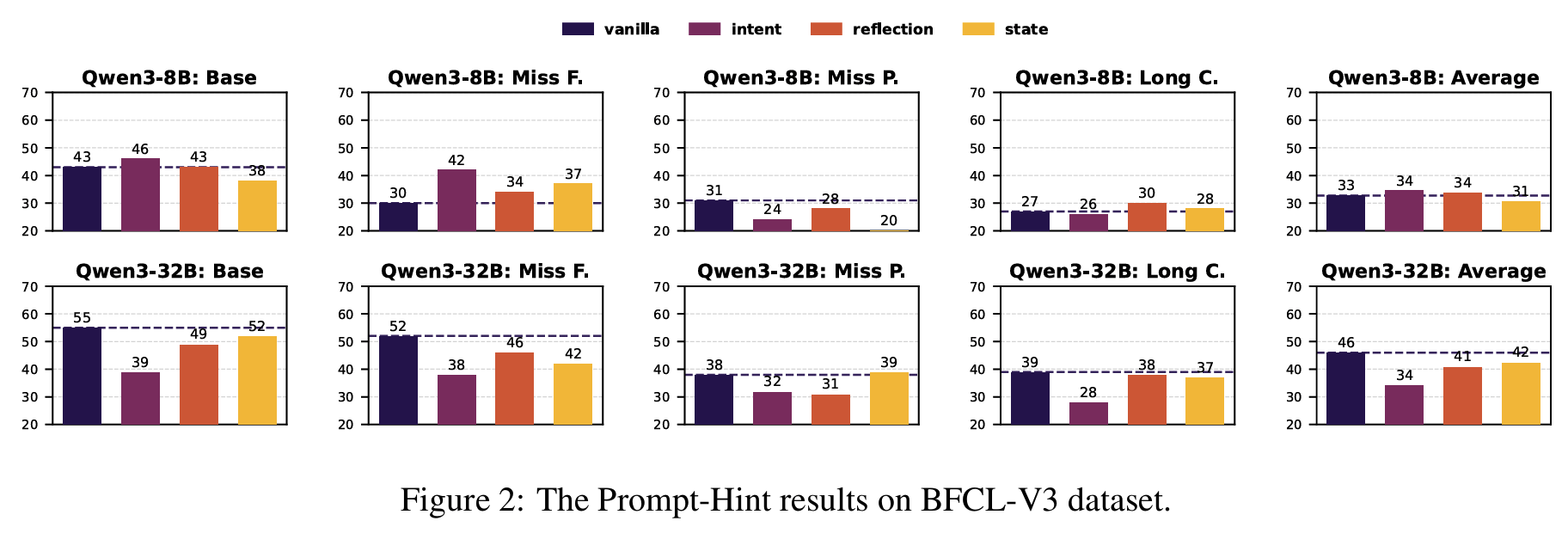
- Depth-based Prompt-Hint Activation: 각 tool 실행 뒤 user-role hint를 삽입 (더 깊고 구조화된 추론 유도)
- intent/reflection/state 세 관점의 hint를 BFCL의 common failure mode에 맞춰 설계 (Prompt 3-5)
Fig 2일부 시나리오에서만 향상- 전반적으로는 gain에 제한, 오히려 정확도 하락하기도
- 추론을 미리 정한 관점으로 강제하면 모델의 유연성이 줄어 다른 핵심 정보를 놓친다고 해석 가능
- Width-based Parallel Sampling with Aggregation: 전체 sequence를 한 번에 생성하지 않고, 매 step마다 $N$개 candidate action을 독립적으로 샘플
- 모든 candidate가 일치하면 그대로 실행; 불일치하면 aggregation function $\mathcal{A}(\cdot)$으로 최종 결정 (Algorithm 1)
- aggregation 전략
- Self-consistency: parallel candidate 간 majority vote/consensus
- LLM-based aggregation: 여러 candidate를 모델에 다시 넣어 최적 action을 고르게 함 (Prompt 1)
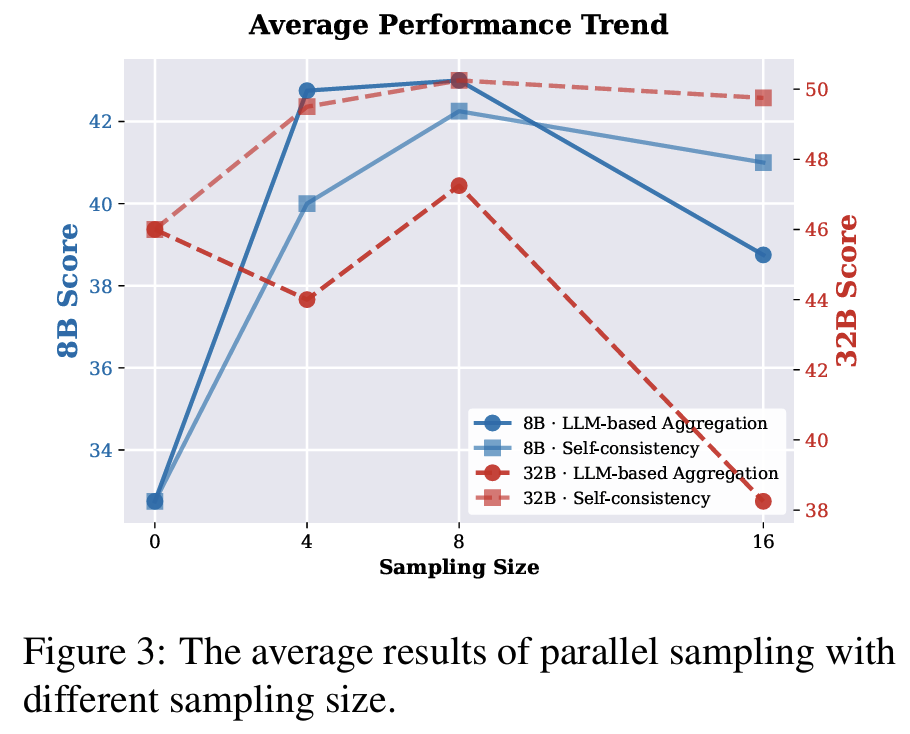
Fig 3reasoning width 확장이 depth 확장보다 효과적- parallel sampling이 정확도를 크게 끌어올림
- temperature 0 (greedy decoding)은 모델 내부 지식을 충분히 못 씀
- 샘플링 온도를 올리면 관련 지식이 더 자주, 더 잘 발현
- self-consistency가 더 안정적, sampling scale에 둔감
- 다만 구조화나 다양한 응답이 필요한 code-based agent에는 덜 적합
- LLM-based aggregation은 추가 향상이 가능하나 sample 수에 monotonic하지 않음
- 긴 context 내 다수 candidate 추론의 한계
- parallel sampling이 정확도를 크게 끌어올림
Knowledge Activation: Training-Time
- post-training 추가: knowledge를 모델 parameter에 내재화 시도
- 학습 데이터는 inference 때 쓰던 입력을 그대로 재사용: 원래 instruction에 검색된 knowledge $R(Q)$를 이어붙인 입력을 학습 샘플로 사용
- 직관(hint-assisted RL): knowledge를 미리 끼워주면 정답 reasoning trajectory가 샘플될 확률이 올라가 학습이 효율적으로 수렴
- post-training은 SFT와 RL(GRPO) 둘 다 적용 → RL이 SFT보다 더 큰 향상
KATE
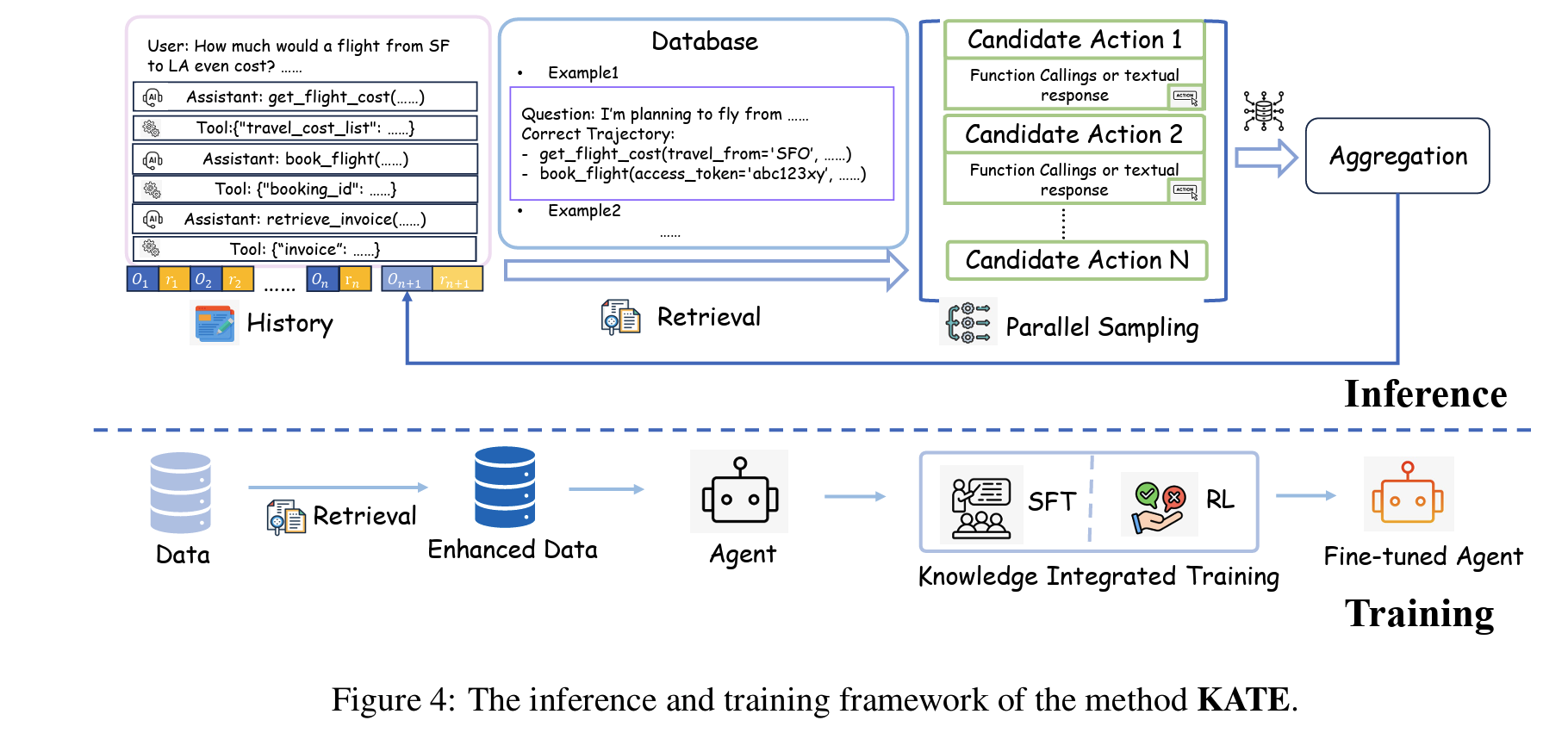
acquisition → activation → training을 하나로 묶은 framework Fig 4 Algorithm 2
- acquisition: ST 채택(가장 단순한 trajectory 지식만으로도 충분히 효과적)
- activation: parallel sampling + LLM-based aggregation으로 latent knowledge 발현
- training: 위 knowledge-usage 틀 위에서 post-training으로 추가 내재화
- training-free 설정과 training-based 설정 양쪽에서 state-of-the-art 달성을 목표로 함
Effects
- Experimental setup
- datasets
- BFCL-V3: multi-turn tool-use
- Base / Miss Func / Miss Param / Long Context
- AppWorld: interactive coding agent
- state 기반 평가
- BFCL-V3: multi-turn tool-use
- models: Qwen3-8B, Qwen3-32B + (appendix) Llama3.2-3B-Instruct
- baselines
- BFCL-V3: Function Calling(FC), Prompt(BFCL 제공 기본 프롬프트), Memp(static non-updating 버전)
- AppWorld: ReAct, ReAct+ST, Memp
- split
- BFCL: Base에서 100 sample만 training, 나머지는 testing
- knowledge는 Base training split에서만 추출
- AppWorld: training 인스턴스 90개에서 GPT-4o로 정답 풀이 절차를 distill → 그중 실제로 맞은 81개로 knowledge base 구성
- BFCL: Base에서 100 sample만 training, 나머지는 testing
- retriever: all-MiniLM-L6-v2
- toolset(class)로 search space hard-constraint → cosine similarity threshold $p=0.5$
- inference: inference temperature 0, parallel sampling temperature 1, sampling size 4; A800/A100; 단일 run 보고(appendix에서 multi-seed 보강)
- datasets
- Results
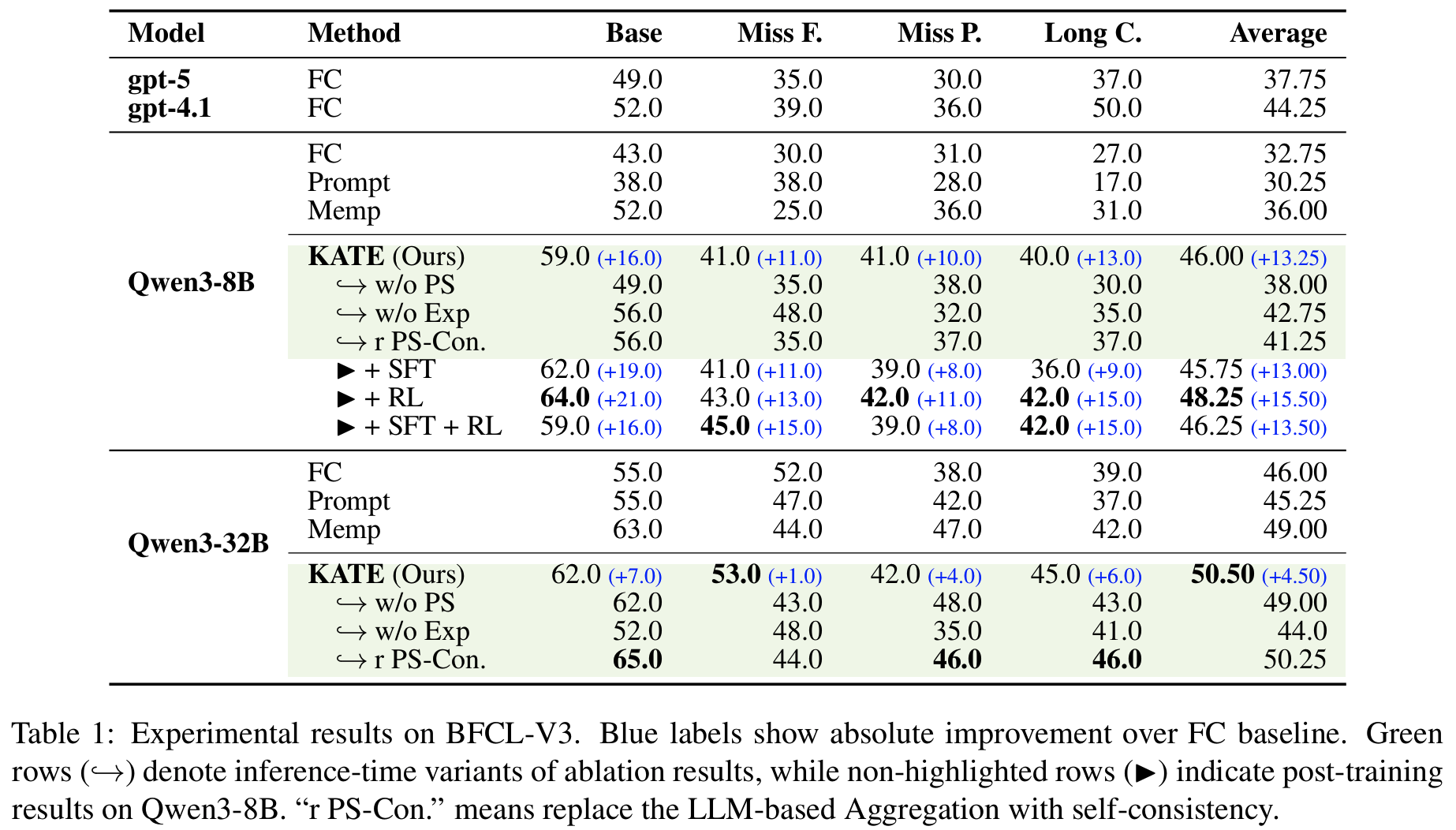
Tab 1main BFCL-V3- Qwen3-8B: Direct RL > SFT+RL
- FC 32.75 → KATE(SFT+RL) 46.00 (+13.25) → Direct RL 48.25 (+15.50)
- Qwen3-32B: +4.50로 스케일업에서 향상 폭 작아짐
- KATE 적용한 Qwen3가 특정 tool-use 시나리오에서 GPT-4.1, GPT-5 상회
- fine-tuning이 context 주입보다 추가 gain; inference-time 활성화만으로는 상한
- ablation: baseline < w/o PS(parallel sampling 제거) < full KATE
- Qwen3-8B: Direct RL > SFT+RL
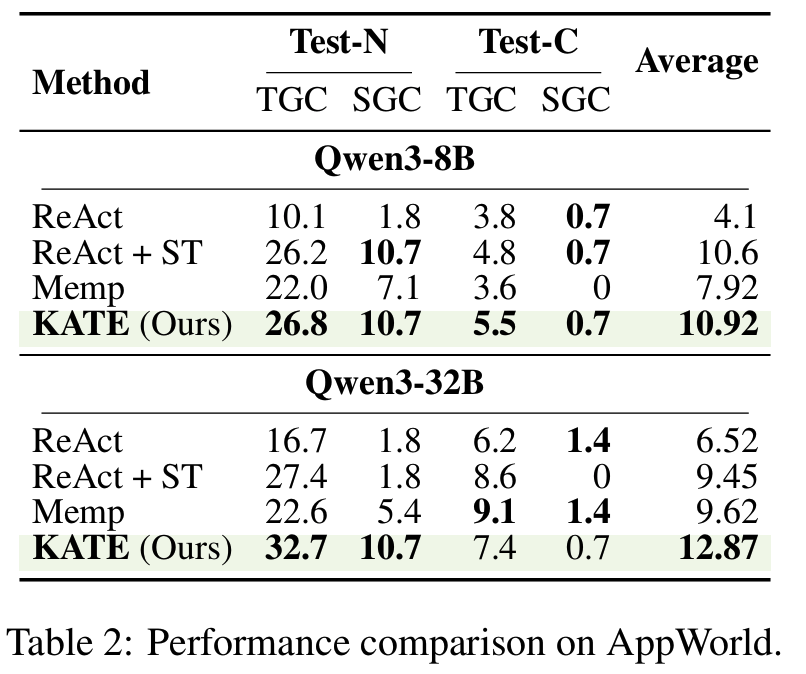
Tab 2AppWorld- KATE > ReAct, ReAct+ST
- reasoning width와 task complexity 사이의 trade-off: Test-C(hallenge)에서 일부 지표가 Memp에 근소하게 밀림
- task 난도가 모델의 본질적 추론 한계를 넘어서면 parallel sampling이 valid trajectory 생성 불가, 다수 후보가 noise로 작용
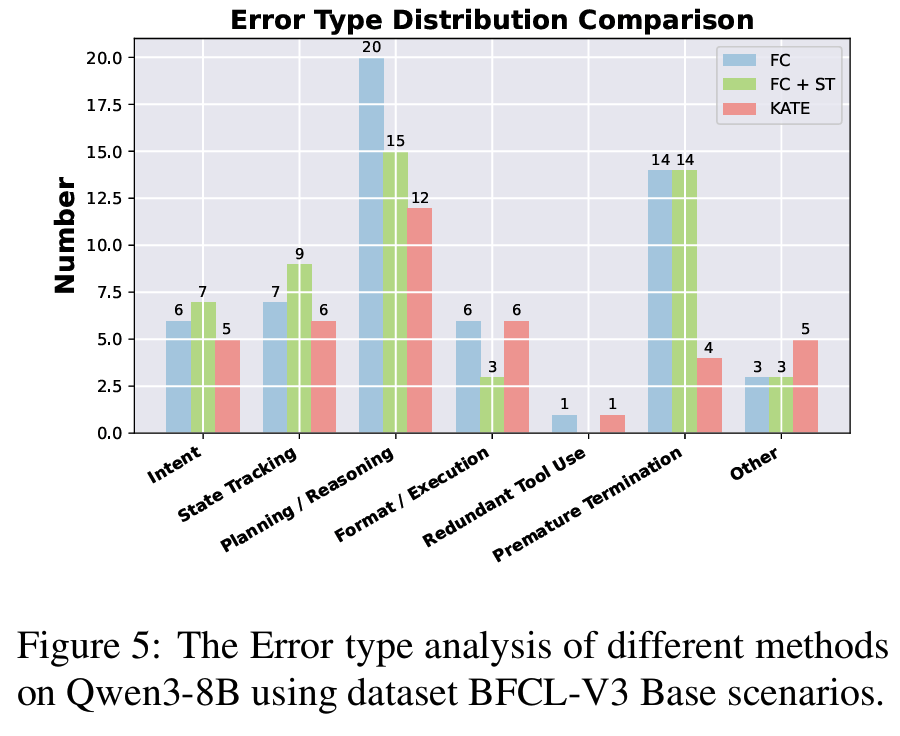
Fig 5error type 분석 (gpt-5-mini로 분류)- planning/reasoning error가 모든 방법에서 주요한 실패
- 모델이 무슨 tool을 어떤 순서로 불러야 하는지 그 계획/추론 자체를 틀린 경우
- ST로 크게 줄고 parallel sampling으로 추가 감소
- premature termination(작업이 안 끝났는데 모델이 조기 종료하는 오류)도 parallel sampling이 유의하게 완화; long-horizon 실행의 robustness 향상
- planning/reasoning error가 모든 방법에서 주요한 실패
Fig 6training 분석: knowledge internalization에서 RL이 SFT보다 효과적- SFT+RL도 유효하나 Direct RL이 수렴 품질과 최종 정확도에서 우위
Tab 3efficiency: parallel 4-way + aggregation에도 비용이 선형 증가하지 않음- Qwen3-32B 기준 token 1.29배 수준
- 정확도 향상이 불필요한 추론 step을 줄여 상쇄
- self-consistency로 바꾸면 token 소모가 거의 같거나 오히려 감소
- Qwen3-32B 기준 token 1.29배 수준
Personal note. 동일 저자(Yupu Hao) 라인의 ETAPP 차기 연구라고 읽으면 결이 있는 것 같기도 하고요. 개인적으로 흥미로운건 instance-level trajectory가 intent-level abstraction보다 낫다는 결과인데, personalization 관점에서는 당연히 abstraction이 유익할 수 있지만, 정확성을 낮출 수 있다는 측면은 동의되기는 합니다. 즉 정면 반례라기보단 abstraction이 언제 어떻게 쓰일건지를 다시 고민해봄직 하다고 정리할 수 있겠습니다. fig3에서 self-consistency가 LLM-based aggregation보다 더 안정적이라는건 역시 모델 응답의 confidence가 낮다는 소리 같고요.