[log-00] 연구 개요 + 실험 설계
Kanana-o Modality Gap Study
Kanana-o(카카오 한국어 특화 omnimodal LLM)에서 입력 모달리티에 따른 성능 갭을 분석하는 소규모 실험 프로젝트.
연구 배경
카카오 옴니모델 kanana-o beta tester로 선정되어, 제한된 일일 API call을 제공받게 되었습니다.
4월 컨텐츠 주제로 이 api 사용 후기를 공유하기로 했는데, 이왕 해보는 거 연구 질문으로 확장해서 국내 학회 제출 가능한 수준의 short paper를 작성해보는 것을 목표로 작은 실험 프로젝트를 수행해보고자 합니다.
Modality Gap 이라는 주제는 물론 제가 현재 연구에 참여하고 있는 방향과도 align 되는 부분이 있기 때문에 익숙하기도 하지만, 무엇보다 4월 2일 진행된 온라인 밋업에서 모델 개발자께서도 관련 개념을 언급하시면서 아직 challenging한 부분이라고 말씀주셨던 게 기억나서 이 방향의 분석이 유익할 것이라고 생각해보게 되었습니다. Chowers et al. (2026)이 “modality gap은 bug”라고 프레이밍한 것도 영향을 줬는데, CLIP 계열에서의 분석이었지만 generative omni 모델에서도 입력 모달리티에 따른 성능 갭이 체계적으로 존재하는지는 아직 실증이 부족한 질문이다.
모델 개요: Kanana-1.5-o-9.8B
| 항목 | 내용 |
|---|---|
| 개발 | Kakao Multimodal Model Training team |
| 파라미터 | 11.6B (LLM base: kanana-1.5-9.8B) |
| 릴리스 | 2026년 2월 |
| 지식 커트오프 | 2024년 6월 30일 |
| 지원 언어 | 한국어, 영어 |
| 컨텍스트 길이 | 16K tokens |
| 라이선스 | kanana-license |
아키텍처
- 입력: Text / Image / Audio (모든 조합)
- 출력: Text / Audio
- 이미지 인코더 + 오디오 인코더 + 모달리티별 C-abstractor → LLM core → 음성 토큰 디코더
- C-abstractor(Convolutional Abstractor)는 Kakao의 Honeybee(Cha et al., CVPR 2024 Highlight)에서 제안된 모달리티 프로젝터로, 합성곱 레이어와 adaptive average pooling을 사용해 인코더 출력을 LLM이 처리할 수 있는 토큰 시퀀스로 압축하면서 공간적 지역성(locality)을 보존한다. 3월 13일 오프라인 밋업에서도 모델 개발자분이 이 논문을 언급하셨다.
주요 강점
- 한국어 특화: KoNet 벤치마크(CSAT 기반) 89.44점. 동급 모델 중 최고, GPT-4o(79.81)보다 우위
- 한국어 ASR: KsponSpeech CER 6.45(clean) / 6.99(other). 타 모델 대비 압도적
- 감정 표현 음성: 병렬언어학적 큐(운율, 강세, 억양) 해석 및 생성 특화
- 완전한 omni I/O: 텍스트/이미지/오디오 입력 → 텍스트/오디오 출력 모든 조합 지원
벤치마크 비교 (이미지 이해)
| 모델 | 파라미터 | KoNet | General VQA | STEM |
|---|---|---|---|---|
| Kanana-1.5-o | 11.6B | 89.44 | 75.01 | 47.72 |
| Qwen2.5-Omni | 11B | 57.47 | 70.08 | 43.14 |
| HCX-SEED-Omni | 8B | 75.39 | 53.44 | 32.82 |
| GPT-4o | - | 79.81 | 72.83 | 50.11 |
| Gemini-2.5-pro | - | 96.17 | 83.59 | 68.36 |
연구 질문 (Research Question)
RQ1
Kanana-o는 입력 모달리티(텍스트/이미지/오디오)에 따라 성능 갭이 존재하는가?
→ 지식 실험으로 검증. 동일한 명제적 정보를 3가지 모달리티로 제시했을 때의 정답률 및 불일치율 측정.
RQ2
RQ1에서 관찰된 갭 패턴이 Kanana-o 한국어 특화 때문인가, omni 모델 공통 현상인가?
- 지식 실험에서 비교 모델(HCX/Qwen/MiniCPM)을 Kanana와 동일 샘플로 적용해 패턴을 대조함
- 한국어 omni: HyperCLOVA X SEED 8B Omni (NAVER, 8B, 오픈소스)
- 비한국어 omni: Qwen2.5-Omni (7B), MiniCPM-o 2.6 (8B)
- 참조: EXAONE 4.5 (LG, 33B, 텍스트+이미지만, 사이즈 미스매치), GPT-4o (upper-bound)
RQ3
모달리티 갭 패턴은 과제 유형에 따라 달라지는가?
정보 구조 관점의 두 과제를 대비:
- 정보 대칭 과제 (지식 실험): 어떤 모달리티로 제시해도 동일한 정보. 갭이 있다면 인코딩 품질 문제
- 모달리티 고유 정보 과제 (감정 실험): 오디오에 텍스트에 없는 신호(운율, 감정)가 존재. 갭이 좁혀지거나 역전될 가능성
Kanana-o의 명시된 강점(감정/운율 인식)이 감정 실험에서 드러나는지 확인.
실험 설계
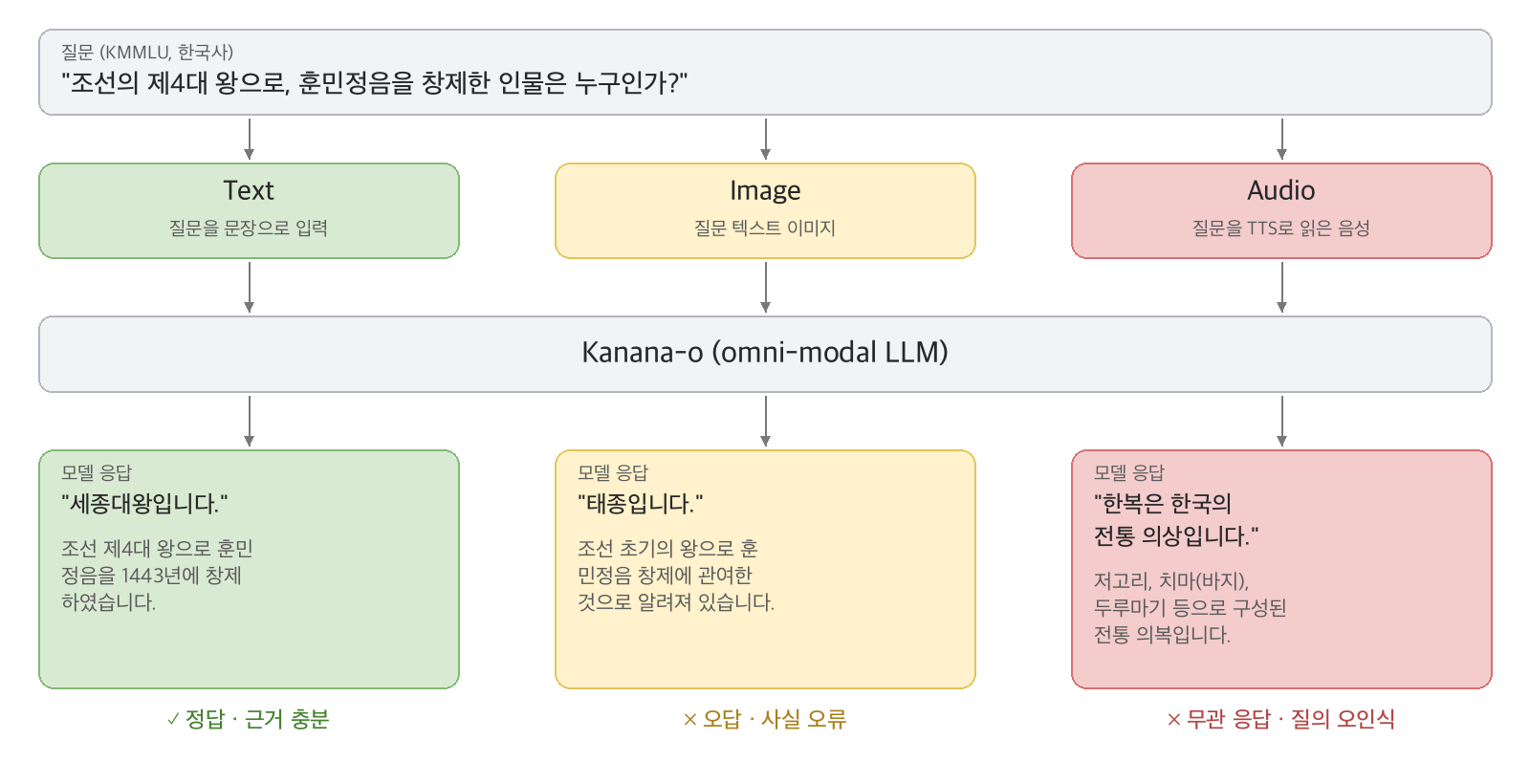
지식 실험 — KMMLU 지식 QA (진행 중)
- 데이터: KMMLU (Korean-History, Law), 60샘플 (서브셋당 30개)
- 방법: 동일 문제를 텍스트 / 텍스트→이미지 렌더링 / 텍스트→TTS 오디오 로 제시
- 측정: 모달리티별 정답률, 3모달 불일치율, Kendall’s tau(모달리티 쌍별 정오답 상관), 서브셋 분석(Korean-History vs Law)
- 한계: 이미지 조건은 자연 이미지가 아닌 텍스트 렌더링 → “이미지 이해”가 아닌 OCR 능력 측정에 가까움 (명시적 한계)
- 적용 모델: Kanana + 비교 모델 (HCX-SEED-Omni, Qwen2.5-Omni, MiniCPM-o 2.6)
- 모델 간 비교: 비교 모델은 Kanana와 동일 샘플로 실행해 갭 패턴이 Kanana 고유인지 omni 공통인지 대조. 비교 모델 60샘플 전체 완료, Kanana 60개 완료 후 최종 비교 집계.
렌더링 방식 (재현성 설계)
입력 파일은 실험 전 1회 일괄 생성해서 고정한다. 실험 실행 시에는 저장된 파일을 그대로 읽어 API에 전송한다.
| 모달리티 | 렌더링 방법 | 결과물 |
|---|---|---|
| 이미지 | Pillow, 흰 배경, AppleSDGothicNeo 폰트 26pt, 패딩 40px | PNG |
| 오디오 | macOS say -v Yuna → AIFF → ffmpeg 16kHz mono WAV |
WAV |
렌더링 파라미터를 고정하고 파일을 버전 관리함으로써, 다른 모델에 동일 실험을 적용할 때 입력이 완전히 동일함을 보장한다.
예시: Korean-History-003
같은 KMMLU 문항을 세 모달리티로 변환한 모습이다. 세 조건 모두 명제적 정보는 동일하지만, 모델 입장에서는 서로 다른 토큰 시퀀스로 들어간다. 정답은 ③.
text 조건 — KMMLU 원문을 그대로 API에 전달
(가)에 대한 설명으로 옳은 것은? 신돈이 (가)을/를 설치하자고 요청하자 , …(중략) …이 제 도감이 설치되었다 . …(중략)… 명령이 나가자 권세가 중에 전민을 빼앗은 자들이 그 주인에게 많이 돌려주었으며 , 전국에서 기 뻐하였다 .-고려사-
① 시 전의 물가를 감독하는 임무를 담당하였다 .
② 국가재정의 출납과 회계 업무를 총괄하였다 .
③ 불법적으로 점유된 토지와 노비를 조사하였다 .
④ 부족한 녹봉을 보충하고자 관료에게 녹과 전을 지급하였다 .
image 조건 — 위 원문을 Pillow로 렌더링한 PNG

audio 조건 — 위 원문을 say -v Yuna로 합성한 30초 분량 TTS WAV
변환 과정에서 생기는 격차
세 조건이 “같은 정보”라고 했지만 실제 비교는 그렇게 단순하지 않다. 이미지 조건은 폰트·글자 크기·줄바꿈 위치·여백 같은 시각적 파라미터가 모두 결과에 영향을 주며, 특히 한국어처럼 자모 조합이 많은 언어에서는 렌더링 설정에 따라 OCR 품질이 달라진다. 본 실험의 이미지 조건이 “이미지 이해”보다 “OCR 능력 측정”에 가깝다는 한계도 여기서 비롯된다. 오디오 조건 역시 macOS say 합성음이라 자연 발화가 아니며 억양과 휴지가 기계적이다. 실제 한국어 음성의 운율·감정 정보를 담지 못하므로, 지식 실험에서 관측되는 audio 조건 성능은 TTS 품질이라는 상한에 묶여 있다고 봐야 한다. 이 한계들은 전 모델에 공통 적용되므로 모델 간 비교의 공정성은 유지되지만, “audio 조건 정답률이 낮다”는 결론을 “audio 모달리티 자체가 약하다”로 확장하기 전에 이 변환 경로를 먼저 의심할 필요가 있다.
감정 실험 — KoED 공감 대화 (RQ3, 설계 예정)
- 데이터: 공개 한국어 감정 음성 데이터셋 활용 예정 (KEMDy20, K-EmoCon 등)
- 방법: 동일 발화를 ① 텍스트 서술 ② 중립 TTS ③ 감정 오디오 로 제시
- 과제: 감정 분류 (기쁨/슬픔/분노/중립 등)
- 가설: 지식 실험과 달리 오디오 조건에서 갭 축소 또는 역전. 특히 한국어 특화 모델에서
- 적용 모델: 전체 비교 모델군 공통 (오디오 미지원 모델은 텍스트+이미지 조건만)
[추후 정리, 2026-04-28] 본 4-03 설계의 “감정 분류” 단일 task는 이후 log-14에서 분류 + 응답 두 task로 확장됨 (감정분류 + 감정응답). 또한 옛 ‘Exp A/B/C’ 레이블은 task 본질 레이블(지식 실험 / 감정 실험 / 감정분류 / 감정응답)로 재정비됨 — 옛 ‘Exp B(모델 간 비교)’는 새 ‘지식 실험’에 흡수되어 본 글에서 ‘지식 실험 — 모델 간 비교’로 통합됨.
문헌 조사 대상
- Liang et al. (2022) Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning: 멀티모달 표현 공간의 modality gap 개념
- OmniBench (ICLR 2025): omni-modal LLM 평가 벤치마크, 대부분 50% 미만
- Xiang et al. (2025) Unveiling the Modality-Bridging Dilemma in Large Speech-Language Models (EMNLP): LSLM에서의 speech-text alignment gap 메커니즘
- Chowers et al. (2025) The Modality Gap is a Bug, Not a Feature (ACL Findings): 오픈소스 OLLM vision-audio gap
- Cha et al. (2024) Honeybee: Locality-enhanced Projector for Multimodal LLM (CVPR 2024 Highlight): C-abstractor 제안. Kanana 아키텍처의 모달리티 프로젝터
- 기술 리포트: Kanana-1.5-o, HCX-SEED-Omni, Qwen2.5-Omni, MiniCPM-o 2.6
- 감정 데이터셋: KEMDy20 (ETRI), K-EmoCon
Personal note. 간략한 구상이지만, API 호출 제한과 소규모 샘플이라는 현실적 제약 속에서도 실험 설계>실행>분석의 사이클을 수행해보려고 한다. 국내 학회 short paper 수준까지 다듬을 수 있다면 더할 나위 없겠지만, kanana-o가 완전히 공개된 모델도 아니고 베타버전이기 때문에 연구 프로젝트로 정리한다는 자체에 의의를 두려 한다. 사실 워낙 모델 발전속도가 빨라 한국어 omni 모델이 아직 많지 않은 지금 시점에서야 직접 비교해볼 수 있다고도 생각한다.