[log-01] 지식 — 벤치마크 선택 (KMMLU, 12/60)
지식 실험 벤치마크 선정 + 1일차 결과 (12문제).
벤치마크 선택: KMMLU
log-00에서 설계한 지식 실험(정보 대칭 과제)을 실행하려면 정답이 명확한 한국어 특화 task가 필요하다. 직접 시나리오를 만들면 이전 실험의 전철을 밟는 거라, 이미 검증된 벤치마크를 쓰기로 했다.
한국어 객관식 QA 벤치마크 중 KMMLU와 CLIcK을 검토했다. 둘 다 정답이 하나로 정해져 있어 평가가 binary(맞거나, 틀리거나)로 단순하고, 모달리티 갭 측정에 적합하다.
- CLIcK (Cultural and Linguistic Intelligence in Korean; Kim et al., 2024): 한국 문화·언어 특화 벤치마크. 1,995문항으로 한국 고유의 문화적 맥락(속담, 역사, 법률, 정치, 경제, 대중문화 등)을 이해하는지 평가한다.
- KMMLU (Korean Massive Multitask Language Understanding; Son et al., 2024): 영어 MMLU의 한국어 대응 벤치마크. 인문·사회·과학·공학·의료 등 45개 서브셋, 35,030문항으로 구성되어 한국어 전문 지식 이해를 광범위하게 평가한다. 한국어 LLM 평가의 사실상 표준이다.
이번 실험에서는 KMMLU를 사용하고자 한다. CLIcK이 평가하려는 한국 문화·역사·법률 지식은 KMMLU의 Korean-History, Law 서브셋에도 포함되어 있고, KMMLU는 문항 수가 많아 시드 기반 샘플링이 용이하다. 또한 마더모델인 텍스트 전용 kanana-1.5-8B의 KMMLU 수치가 공개되어 있어(base 48.94), omni 모델과 같은 벤치마크로 비교할 수 있다는 점도 고려했다. 모델 카드에는 KoNet(이미지), KsponSpeech(음성) 등 멀티모달 벤치마크만 보고되어 있고, omni 모델의 KMMLU 공개 수치는 아직 없다. 공개된 baseline이 없으므로 텍스트 조건 결과 자체가 새로운 참고 자료가 될 것이라고 판단했다. CLIcK은 콜이 남으면 후속으로 시도해보려고 한다.
사용할 수 있는 call 수는 제한적이기 때문에, KMMLU에서도 전체를 다 사용하지 않고, 서브셋으로 Korean-History와 Law 두 도메인으로 좁혔다. CLIcK이 커버하는 역사·법률 영역과 겹치는 도메인이면서, 텍스트 추론 기반 질문이라 이미지/음성 변환해도 정보 손실이 적고, 긴 수식이나 기호가 없어서 렌더링도 깔끔할 것이라고 예상된다.
- Korean-History: 맥락 서술이 길고 시대-인물-사건 간 관계 추론이 필요함. 음성으로 들었을 때 자연스러운 흐름이 이해를 도울 수 있어 audio 조건에서의 갭 패턴이 흥미로울 것으로 예상됨.
- Law: 조문 번호, 항목 구조, 요건-효과 대응 등 시각적 구조에 의존하는 정보가 많음. 텍스트/이미지 조건이 유리하고 audio 조건이 불리할 것으로 예상됨.
각 30개씩 총 60문제, 고정 시드(seed=42)로 추출하고자 한다. 일일 API 쿼터 제약이라 문제당 3콜(텍스트/이미지/오디오), 며칠에 걸쳐 분할 진행하고자 한다.
세팅 확인
이미지 입력이 API에서 실제로 되는지 1콜 써서 테스트했다. OpenAI 호환 포맷으로 base64 PNG를 넣으면 읽는다. log-00의 렌더링 방식(Pillow PNG, macOS Yuna TTS → 16kHz WAV)을 그대로 적용한다.
오늘 결과 (12문제)
| ID | text | image | audio | 정답 |
|---|---|---|---|---|
| Law-352 | 3 ❌ | 2 ❌ | 2 ❌ | 1 |
| Korean-History-081 | 4 ✅ | 3 ❌ | 3 ❌ | 4 |
| Law-432 | 2 ❌ | 3 ❌ | 2 ❌ | 4 |
| Korean-History-053 | 4 ✅ | 2 ❌ | 4 ✅ | 4 |
| Korean-History-093 | 3 ✅ | 3 ✅ | 3 ✅ | 3 |
| Korean-History-097 | 3 ✅ | 3 ✅ | 3 ✅ | 3 |
| Law-344 | 4 ✅ | 4 ✅ | 3 ❌ | 4 |
| Korean-History-084 | 2 ❌ | 2 ❌ | 1 ❌ | 3 |
| Korean-History-011 | 3 ❌ | 3 ❌ | 4 ✅ | 4 |
| Korean-History-057 | 4 ❌ | 3 ❌ | 3 ❌ | 2 |
| Korean-History-086 | 4 ❌ | 3 ❌ | 3 ❌ | 2 |
| Korean-History-094 | 3 ✅ | 2 ❌ | 3 ✅ | 3 |
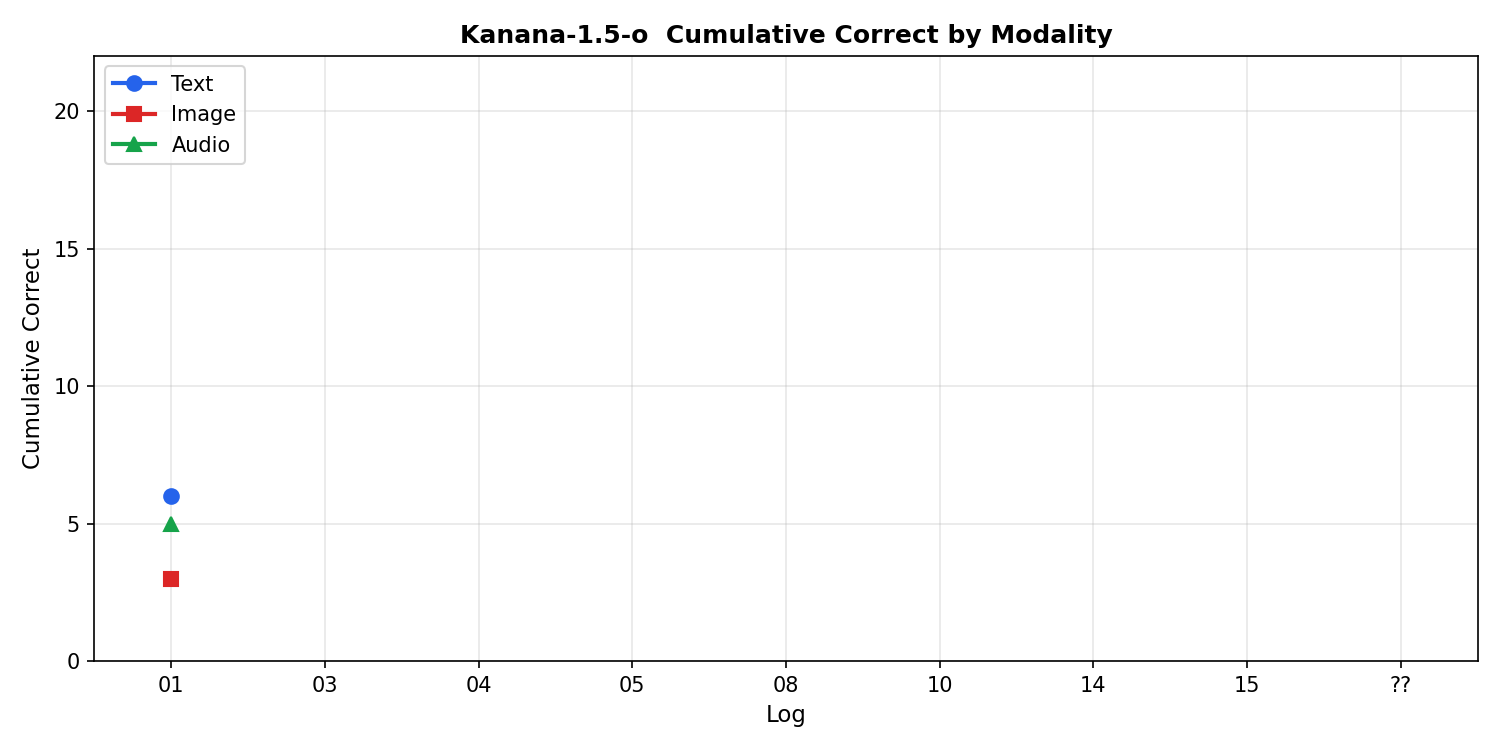
| 모달리티 | 정답률 |
|---|---|
| 텍스트 | 6/12 = 50.0% |
| 음성 | 5/12 = 41.7% |
| 이미지 | 3/12 = 25.0% |
12개라 숫자 자체를 믿기는 이르겠지만, 이미지 모달리티에서 어려움이 느껴진다. 텍스트는 정답을 맞췄는데 이미지로는 틀리는 케이스가 2회 발생했다.
불일치율쪽이 더 흥미로운데, 완전히 같은 내용으로 통제된 상황에서도 12문제 중 10문제(83%)에서 세 모달리티의 답이 달랐다. 매우 초기의 결과지만, kanana-o 모델 역시 모달리티에 따른 성능 갭은 확실히 존재할 것으로 예상된다.
누적 추이
References
- Son et al. (2024) KMMLU: Measuring Massive Multitask Language Understanding in Korean: 45개 서브셋 35,030문항의 한국어 전문 지식 벤치마크
- Kim et al. (2024) CLIcK: A Benchmark Dataset of Cultural and Linguistic Intelligence in Korean: 한국 문화·언어 특화 1,995문항 벤치마크
- 기술 리포트: Kanana-1.5-o, Kanana-1.5-8B
- Yoo & Kim et al. (2025) Kanana: Compute-efficient Bilingual Language Models