[log-05] 지식 — 베이스라인 첫 측정 (Kanana 30/60)
누적 30/60. 비교 모델 3개 실험 수행, 첫 4모델 비교.
오늘 결과 (6문제)
| ID | text | image | audio | 정답 |
|---|---|---|---|---|
| Korean-History-013 | 4 ❌ | 2 ❌ | 3 ✅ | 3 |
| Law-826 | 4 ✅ | 2 ❌ | 4 ✅ | 4 |
| Law-094 | 4 ❌ | 3 ✅ | 1 ❌ | 3 |
| Law-389 | 4 ❌ | 4 ❌ | 4 ❌ | 3 |
| Korean-History-017 | 3 ❌ | 3 ❌ | 3 ❌ | 4 |
| Law-044 | 3 ❌ | 3 ❌ | 3 ❌ | 1 |
| 모달리티 | 정답률 |
|---|---|
| 텍스트 | 1/6 = 16.7% |
| 음성 | 2/6 = 33.3% |
| 이미지 | 1/6 = 16.7% |
오늘도 전반적으로 낮은 스코어를 보인다. 세 모달리티가 모두 같은 답을 택한 케이스가 3회(Law-389, Korean-History-017, Law-044)있었는데, 3회 모두 오답이다. log-03에서 Law-825 케이스(3모달 합의, 전부 틀림)랑 같은 패턴으로, 모달리티와 무관하게 모델이 강하게 확신하는 방향이 있는데 그게 오답인 경우이다.
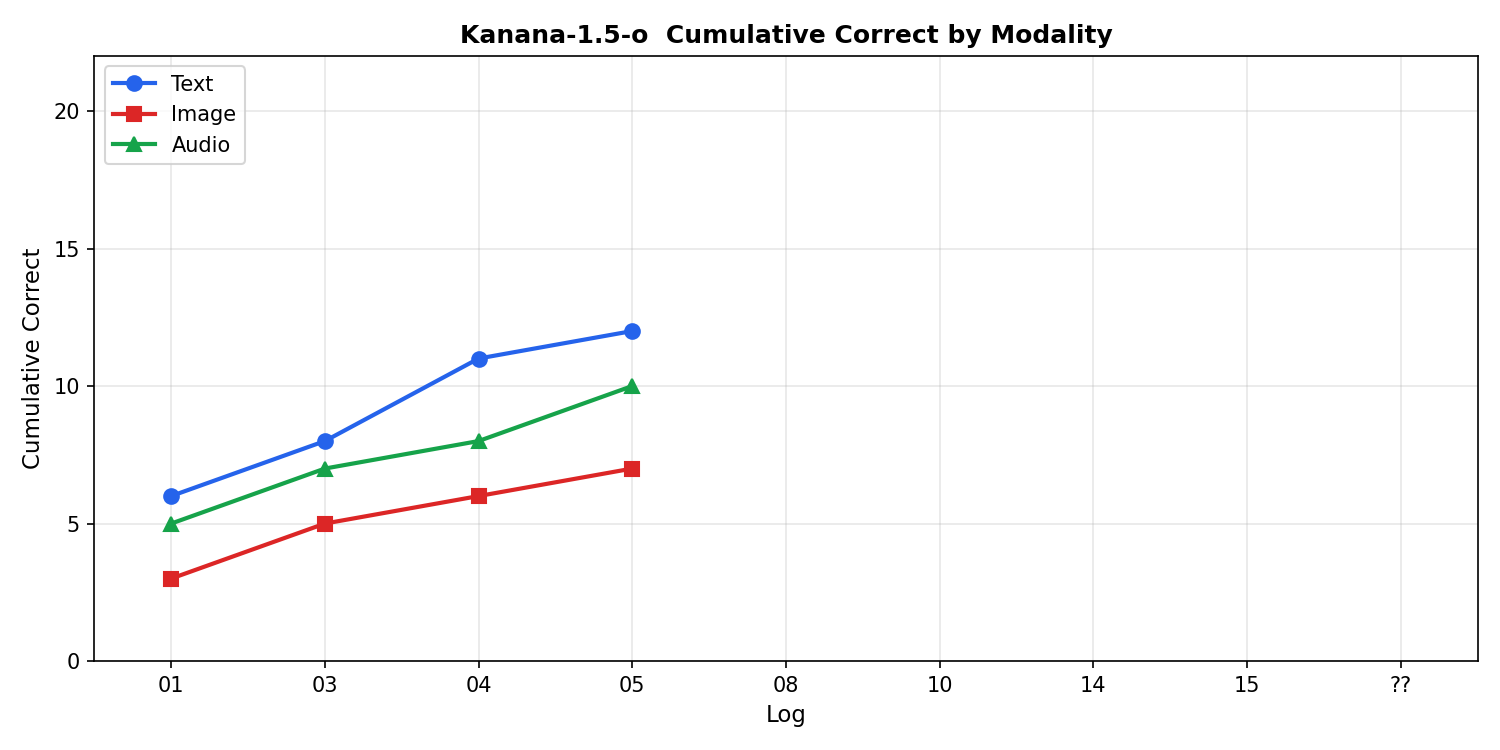
누적
| 모달리티 | 정답률 |
|---|---|
| 텍스트 | 12/30 = 40.0% |
| 음성 | 10/30 = 33.3% |
| 이미지 | 7/30 = 23.3% |
- 3모달 불일치율: 23/30 = 76.7%
- text > audio > image 순서는 5일 내내 유지되고 있다
비교 모델 실험 수행
이번 주 서버에서 HyperCLOVA X SEED Omni(8B), Qwen2.5-Omni(7B), MiniCPM-o 2.6(8B) 세 모델을 60샘플 전체에 돌렸다. 카나나는 API 쿼터 제약 때문에 분할 진행이라 아직 30/60이지만, 공통 30샘플 기준으로 첫 비교가 가능해졌다.
실험 구성
KMMLU(Korean-History 30 + Law 30, seed=42) 60문제를 텍스트/이미지/오디오 3가지 모달리티로 제시. 공통 지시문: “정답 번호(①②③④ 중 하나)만 말해줘.”
| 모달 | 생성 방식 |
|---|---|
| text | 문제 텍스트 그대로 |
| image | PIL 렌더링 PNG (한국어 시스템 폰트, 흰 배경) |
| audio | macOS say Yuna 음성 → ffmpeg 16kHz mono WAV |
| 모델 | 파라미터 | 한국어 특화 | 실행 환경 |
|---|---|---|---|
| Kanana-1.5-o | 11.6B | ✅ | API (제한된 쿼터) |
| HCX-SEED-Omni | 8B | ✅ | 로컬 4×RTX 3090 fp16 |
| Qwen2.5-Omni | 7B | ❌ | 로컬 |
| MiniCPM-o 2.6 | 8B | ❌ | 로컬 |
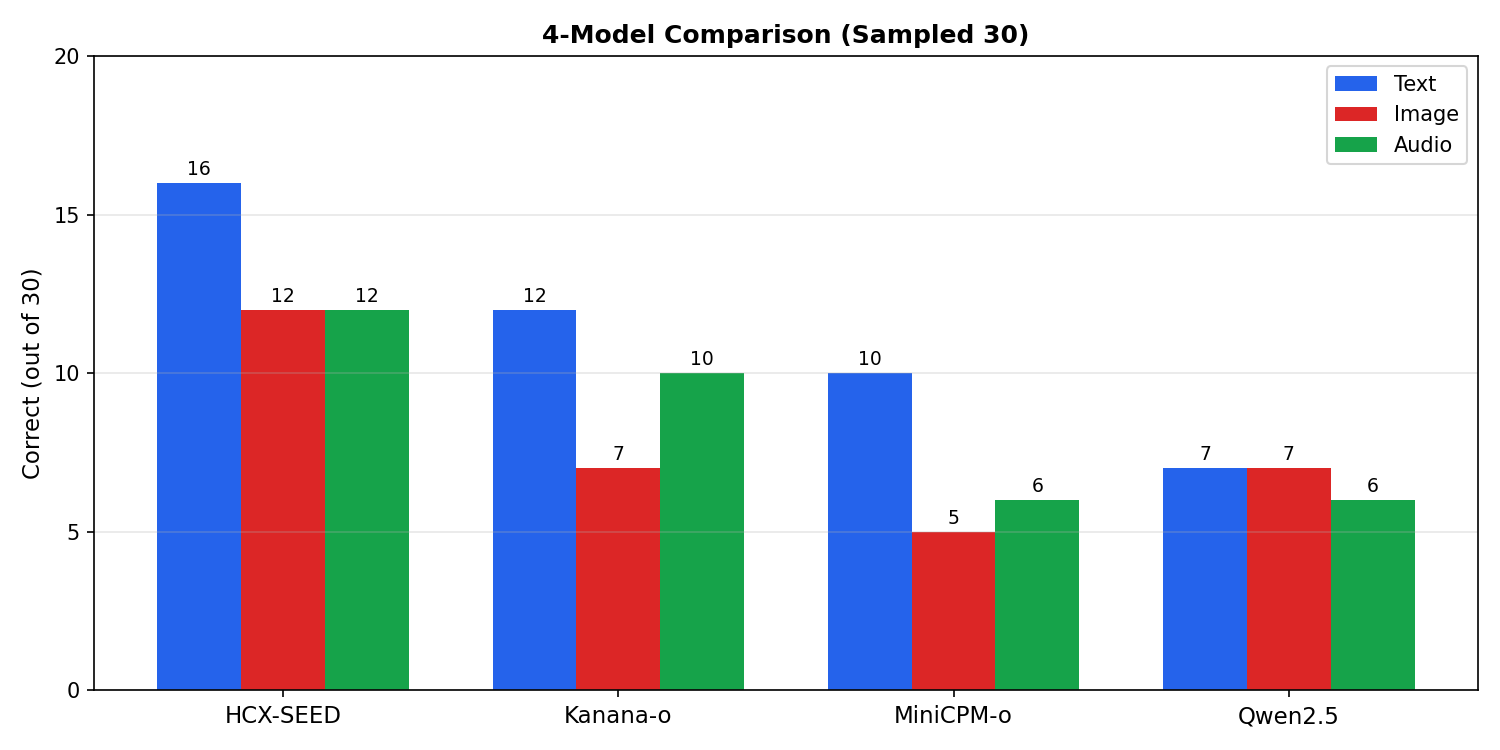
샘플링셋 비교 (공통 30문제)
| 모델 | text | image | audio | n | 불일치 |
|---|---|---|---|---|---|
| HCX-SEED-Omni | 53.3% | 40.0% | 40.0% | 30 | 66.7% |
| Kanana-1.5-o | 40.0% | 23.3% | 33.3% | 30 | 76.7% |
| MiniCPM-o 2.6 | 33.3% | 16.7% | 20.0% | 30 | 90.0% |
| Qwen2.5-Omni | 23.3% | 25.0% | 20.0% | 30 | 73.3% |
전체셋 비교
| 모델 | text | image | audio | n |
|---|---|---|---|---|
| HCX | 53.3% | 35.0% | 35.0% | 60 |
| Kanana | 40.0% | 23.3% | 33.3% | 30 |
| MiniCPM | 30.0% | 23.3% | 23.3% | 60 |
| Qwen | 21.7% | 30.0% | 23.3% | 60 |
패턴
한국어 특화 두 모델(HCX/Kanana)이 비특화(Qwen/MiniCPM)보다 모든 모달리티에서 앞선다. 한국어 지식 QA에서 모달리티를 바꿔도 이 우위는 유지. 단, 같은 한국어 특화끼리도 HCX > Kanana. KoNet 기준 공식 홍보에서는 Kanana가 앞서는데 KMMLU 지식 QA에서 역전된 양상을 보인다. (과제 유형 차이나 짧은 답변 즉응성 차이 가능성)
Qwen은 샘플링셋 기준 text(23.3%) < image(25.0%)로 다른 모델과 반대의 경향을 띈다. 한국어 텍스트 토큰화 효율이 낮아 이미지 렌더링이 LLM 한국어 약점을 일부 우회한다는 가설이 가능하지만, 60샘플로는 표본이 작아 확신하긴 어렵다.
불일치율은 전 모델 67~90%. 랜덤 baseline이 약 94%이니 “모달 간 어느 정도 편차는 있다”는 수준이지, 결코 낮지 않다. 즉, omni-LLM의 모달리티 갭은 보편 현상으로 보는 것이 타당해 보인다.
인프라 메모
비교 모델 3개를 로컬 서버에서 돌리면서 런타임 조합 맞추는 데 시간이 상당히 들었다.
확정 버전: torch 2.5.1+cu124 / transformers 4.52.4 / flash-attn 2.7.3 prebuilt wheel.
- torch ≥ 2.5 필요: transformers 4.52의
ALL_PARALLEL_STYLES초기화가 2.4에서 None → TypeError - transformers 4.52.4: Qwen2_5OmniForConditionalGeneration 포함(4.51 미포함) × HCX
no_init_weights호환(5.x 제거). 유일한 공통 버전 - flash-attn: 런타임 이미지에 nvcc 없어 소스 빌드 불가, prebuilt wheel URL 직접 핀
모델별 미세 조정:
- Qwen: transformers 4.52 + torch<2.6에서 CVE-2025-32434 보안 게이트가
torch.load차단. Thinker 서브클래스(Qwen2_5OmniThinkerForConditionalGeneration) 직접 사용으로 우회. - MiniCPM: transformers 4.52
smart_apply가 모든 서브모듈에_initialize_weights요구. Resampler(plain nn.Module)에 no-op 주입. - HCX: chat template이 OpenAI 포맷 요구.
skip_reasoning=True로<think>...</think>reasoning 건너뛰고 직답 유도.
한계
- 60문제(샘플링셋 30) 단일 시드 1회 실행. 각 셀 표준오차 ±6%p 수준.
- 이미지 = 텍스트 렌더링 PNG, OCR에 가깝다는 지적 가능. 자연 이미지 이해는 아니므로. (정보량을 통제한 의도이긴 했지만…)
- 오디오 = macOS TTS 합성 음성. 실제 사람 억양/배경음 없음에 대한 부자연스러움.
- 카나나 이미지 버전 스플릿: 첫 30샘플은 줄 바꿈 없는 PNG(
artifacts_nowrap/), 남은 30샘플은 900px 줄 바꿈 적용 PNG(artifacts/)를 보게 됨. - KMMLU Korean-History에
(중략)표기와 OCR 공백이 있어 TTS가 그대로 읽음.
누적 추이