[log-06] 지식 — 비교 모델 전체셋(n=1100)으로 확장
비교 모델에 대해 전체 n=1100 실행
표본 대신 전체 셋 활용으로 변경: 60 → 1100
log-05에서 흥미로웠던 qwen의 경향은 우연으로 보임.
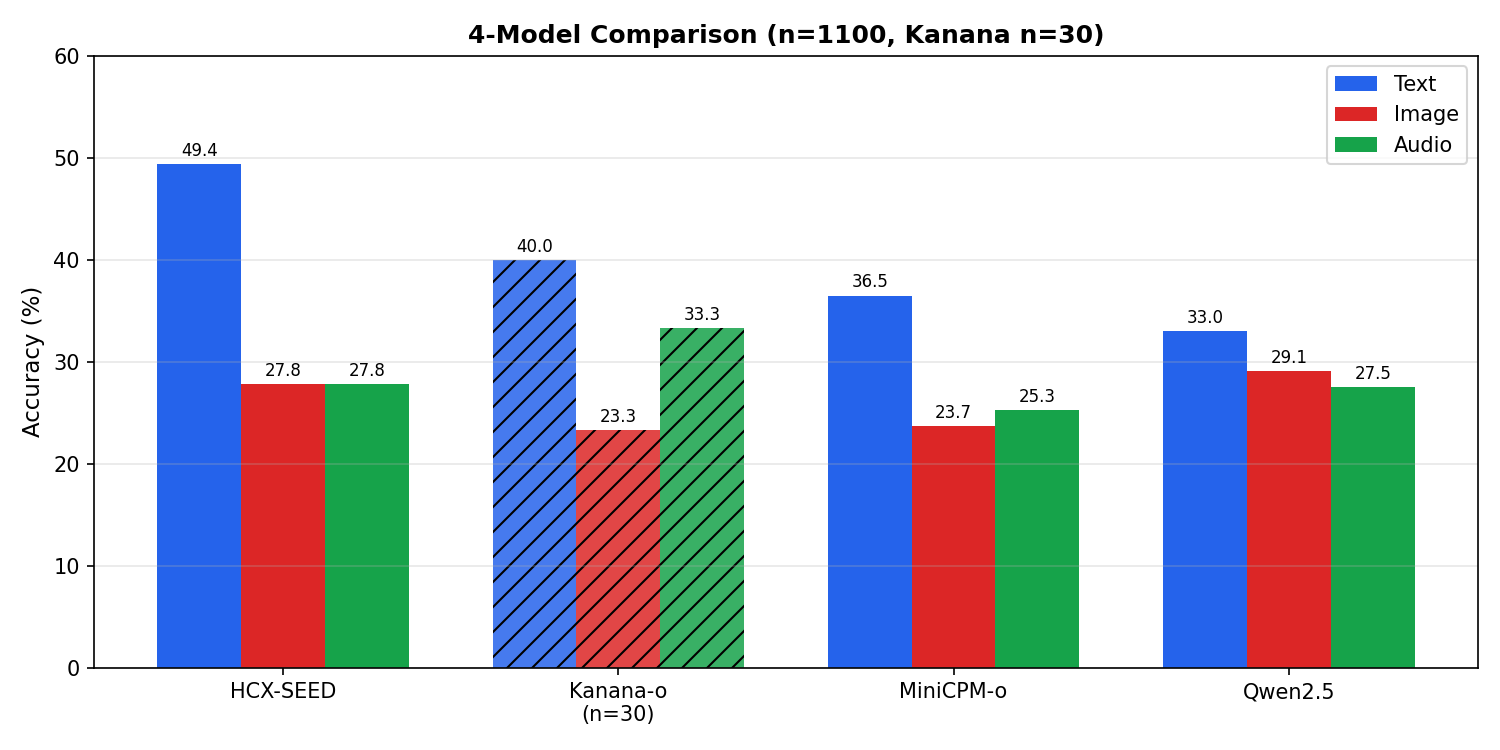
log-05에서 “Qwen은 text < image”라는 패턴을 관찰하고 한국어 텍스트 토큰화 효율 가설을 이야기했었다. 같은 모델을 KMMLU의 Korean-History 100개, Law 1000개, 총 1100문제로 다시 돌렸더니 해당 패턴은 사라졌다. 60개 샘플로는 통계적 의미가 없다는 경고를 60샘플 글에서 직접 썼는데, 아무래도 표본 사이즈가 작은 것이 결국 문제가 되는 사례를 확인한 셈이다. 결론적으로 표본 충분한 모달리티 패턴으로써는 text > image > audio 성능 경향이 뚜렷하다. (다만 여전히 Kanana는 API 쿼터 제약 때문에 전체 셋을 비교하긴 어렵다.)
n=1100 결과
| 모델 | text | image | audio | n | 불일치 |
|---|---|---|---|---|---|
| HCX-SEED-Omni | 49.4% | 27.8% | 27.8% | 1100 | 75.2% |
| MiniCPM-o 2.6 | 36.5% | 23.7% | 24.5% | 1100 | 88.2% |
| Qwen2.5-Omni | 33.0% | 29.1% | 27.5% | 1100 | 82.0% |
60 → 1100 변화
| 모델/모달 | 60샘플 | 1100샘플 | Δ |
|---|---|---|---|
| HCX text | 53.3% | 49.4% | −3.9 |
| HCX image | 35.0% | 27.8% | −7.2 |
| HCX audio | 35.0% | 27.8% | −7.2 |
| Qwen text | 21.7% | 33.0% | +11.3 |
| Qwen image | 30.0% | 29.1% | −0.9 |
| Qwen audio | 23.3% | 27.5% | +4.2 |
| MiniCPM text | 30.0% | 36.5% | +6.5 |
| MiniCPM image | 23.3% | 23.7% | +0.4 |
| MiniCPM audio | 23.3% | 24.5% | +1.2 |
변화 요약
“Qwen은 text < image”; 표본 샘플링에 따른 노이즈로 판단
n=1100에서 Qwen text(33.0%) > image(29.1%) > audio(27.5%)으로 다른 두 모델과 같은 경향을 띈다. 60샘플에서의 text 21.7%는 우연히 어려운 셋이 걸린 것으로 해석하는 것이 타당해보이고, 이 수치는 1100에서 33%로 회복된다. 즉 어설프게 제안했던 한국어 텍스트 토큰화 효율 가설은 이 데이터로는 지지하기 어렵다.
HCX text 우위는 견고함
HCX text 53.3% → 49.4% (−3.9%p). 표본 샘플링에 의한 왜곡이 약간 있었지만 4모델 중 여전히 최상위 성적을 유지하고, 다만 image/audio는 −7.2%p로 더 크게 하락하여 모달리티 갭은 심화되었다. n=1100 셋에서 긴 법률 조문 등 어려운 문제 비중이 높아지면 멀티모달 인코더 부담이 커진 것은 아닐 지 추측해본다.
모달리티 갭 패턴이 더 분명해짐
| 모델 | text-image 갭 | text-audio 갭 | 특징 |
|---|---|---|---|
| HCX | 21.6%p | 21.6%p | text 강점 + image/audio 동률 |
| MiniCPM | 12.8%p | 11.2%p | 중간 갭, audio ≈ image |
| Qwen | 3.9%p | 5.5%p | 갭 최소, 단 절대 정답률 최하 |
Qwen의 갭이 작은 건 강점이 아니라 text 천장 자체가 낮은 탓으로 보는 것이 더 타당해 보인다. HCX는 LLM 본체가 강해서 text가 앞서가고, 멀티모달 인코더 » LLM 정렬 품질 차이로 image/audio에서 25%p 손실 발생.
다만 log-05를 직접 소급 수정하지 않은 것은, 60 → 1100에서 어떤 셀이 얼마나 흔들리는지 자체가 실험의 부산물이고, 가지고 있는 전체 셋을 기준으로 결론이 뒤집힌 사례가 기록으로 남는 게 방법론적으로 의미 있다고 생각한다.
(여전한) 한계
- 1100문제지만 단일 시드 1회 실행. Bootstrap CI 없음. 모델 간 1~2%p 차이는 여전히 단정하기에는 통계적 유의성 검증이 필요함.
- Kanana 비교는 여전히 30샘플 한정으로 설령 60개를 모두 뽑는다고 해도 표본 오차가 존재함.
- 여전히 오디오 = macOS TTS 합성 음성. 실제 음성 신호는 아니므로 부자연스러움.
side-note: 3모달 불일치율
log-05부터 계속 쓰고 있는 “3모달 불일치율”을 한번 정리해두는 게 맞을 것 같아서 정리해본다.
정의
같은 문제에 대해 text/image/audio 세 모달 답이 모두 같지 않으면 불일치 1. 정답 여부와는 무관 — 셋 다 똑같이 틀려도 일치. 셋 중 하나만 달라도 불일치.
text=① image=① audio=① → 일치
text=② image=③ audio=① → 불일치
text=④ image=④ audio=② → 불일치 (2:1이어도)
정확도와 불일치는 다른 축으로 비교
| 모델 (n=1100) | text 정확 | 불일치 |
|---|---|---|
| HCX | 49.4% | 75.2% |
| MiniCPM | 36.5% | 88.2% |
| Qwen | 33.0% | 82.0% |
두 지표는 독립적으로 움직일 수 있다. 예시로나마 극단 사례를 보면
| 가상 모델 | 정확도 | 불일치 | 의미 |
|---|---|---|---|
| 항상 ② 만 답 | 25% | 0% | 완전 일관 / 무지식 |
| 완전 무작위 | 25% | ~94% | 일관성 0 |
| 신탁(완벽) | 100% | 0% | 정답 + 모달 무관 |
이해하기 쉽게 한마디로 정확도 = 진실에 얼마나 가까운가.를 의미하고, 불일치 = 자기 자신과 얼마나 어긋나는가.를 의미한다. 따라서 omni 모델의 모달리티 갭을 평가하는 본 실험에서는 둘 다 고려하는 것이 타당하다.
왜 모든 omni 모델이 비슷한 불일치율을 보이는가? (75-87%)
4지선다에서 랜덤하게 3번 답하면 셋 다 같을 확률 = 1/4³ × 4 = 1/16 = 6.25%. 즉 랜덤 baseline 불일치율 약 94%.
75~87%는 랜덤보다는 확실히 낮다는 점으로 미루어보아, 모달 간 어느 정도 정렬이 있다는 신호로 읽힌다. 그러나 50% 미만(절반은 모달 간 답이 같음)으로 내려간 모델은 아직 없으므로, omni 모달리티 갭은 보편적 현상이고, 현재 모델들은 그 중간 어딘가에 있다고 볼 수 있을 듯.